
基于核的L2,1范数非负矩阵分解在图像聚类中的应用
2019-05-25 03:57余江兰李向利董晓亮
数学杂志 2019年3期
余江兰,李向利,董晓亮
(1.桂林电子科技大学数学与计算科学学院;广西密码学与信息安全重点实验室;广西自动检测技术与仪器重点实验室,广西桂林 541004)
(2.北方民族大学数学与信息科学学院,宁夏银川 750021)
1 前言
非负矩阵分解(Non-negative Matrix Factorization,简写为NMF)[1,2]是继PCA(主成分分析)[3]、ICA(独立成分分析)[4]、VQ(矢量量化)[5]等矩阵分解方法之后提出的一种新的矩阵分解方法.近年来,NMF算法引起了各个领域中科研人员的重视,因为NMF的思想为人类处理大规模数据提出了一种新方法,且该方法相较于一些传统的方法而言,具有实现简便、易于存储、分解结果可解释的优点.NMF是在一般的矩阵分解的基础上对矩阵添加了非负的限制,其基本思想可简单概括为:给定一个非负数据矩阵,试图找到两个非负低秩矩阵,使得它们的乘积能够无限逼近原始非负数据矩阵.标准NMF[6]是将Frobenius范数(简记为F范数)作为目标函数,计算起来很方便快捷,但是它不能有效地处理存在于数据中的噪音值和异常值点.因此,急需找到一个能够改善这些问题的非负矩阵分解新版本.
此前,源于其对事物的局部特性有很好的解释,NMF已经被广泛应用于很多领域.比如,图像分析、文本数据和数据挖掘、语音处理、机器人控制、生物医学工程和化学工程,此外,NMF算法在环境数据处理、信号分析与复杂对象的识别方面都有着很好的应用.扩展的NMF[7]也在不断适应着各种各样的目标函数,从而能够涉入不同的数据分析问题,包括分类、协同过滤和聚类等等.
聚类是特征学习和计算机视觉的最重要且具有挑战性的任务之一.在过去的几十年里,研究学者们为各种应用程序设计了许多聚类方法,包括图像注释[8]、图像检索[9]、图像分类[10]、图像分割[11]、数据挖掘[12]和图像索引[13].然而,对于图像聚类任务来说,一个非常重要的步骤是找到原始数据的有效表示.为此,不同的研究人员做了大量的工作,他们通常强调挖掘原始数据的内在结构信息,并使新的表示更具辨别性.传统的聚类已经比较成功的解决了低维数据的聚类问题.但是由于实际应用中数据的复杂性和冗余性,在处理许多问题时,现有的算法经常失效,特别是对于高维数据和大型数据的情况.因为传统聚类方法在高维数据集中进行聚类时,主要遇到两个问题[14]:(1)高维数据集中存在一些与聚类无关的维度,从而在对数据降维处理中带来一定的挑战;(2)高维空间中数据比低维空间中数据分布更稀疏和零散,常存在数据点之间的距离几乎相等的情况,而传统聚类方法是基于距离进行聚类的,因此在高维空间中无法基于距离来构建簇.
而NMF作为一种处理大规模数据的矩阵分解方法,它已逐渐成为图像、文本聚类与数据挖掘等领域最受欢迎的工具之一.实践证明,利用NMF对文本、图像等高维数据进行处理时,比传统的矩阵分解处理方法速度更快、更便捷,被认为是对非负数据进行处理的一种有效途径,已经引起了国内外许多科学家和研究人员的广泛关注.
近年来,为了不断改善已有的NMF方法存在的问题,很多扩展版NMF被提出.为了提高原始NMF的稀疏性,通过将局部约束整合到标准的NMF中,Li等人[15]提出了LNMF(局部非负矩阵分解).这种方法不仅可以学习对象的稀疏表示,而且可以表明局部特征.之后,为了确保对象的稀疏性,Hoyer等人[16]将L1-范数约束强加在编码矩阵上,提出了NSC(非负稀疏编码).虽然他们没有考虑数据的内在结构信息,但从某种程度上说,NSC和LNMF从不同角度改善了NMF的稀疏性.Barman等人[17]提出了基于文本聚类的非负矩阵分解,包括特征的提取和分类.杨等人[18]提出了非负矩阵分解的投影算法,并将该算法人脸图像的处理中,实验效果较好;蔡等人试图涉及几何数据空间的信息提出了GNMF(图正则非负矩阵分解[7]),它是通过构建K-近邻(KNN)图结构来编码几何结构.由于简单图中的一个边可以连接两个顶点,所以GNMF只考虑两个样本之间的关系,忽略了多个样本之间的关系.为了探索多个样本间的高阶关系,通过创建一个超图来编码多个样本间的关系,由于超图可以连接两个以上的顶点,故HNMF(超图正则化非负矩阵分解)能找到数据的高阶关系.Zeng等人[19]提出了HNMF.虽然GNMF和HNMF运用了样本内在的流形结构,但没有考虑带判别信息的因素.为了结合带判别力的信息,李等人[20]通过合并局部流行图正则和带判别力的标签信息,提出了GDNMF(基于图带标签判别力的非负矩阵分解).为了将NMF延伸到子空间聚类中,Dijana等人[21]借助核技巧[22,23]来揭示流形的非线性性质,并将数据固有的局部几何性质都考虑在内,提出了非线性正交非负矩阵分解,使得聚类性能得以提升.
可以看出,以上列举的NMF方法都是在不断从不同角度揭示了充分利用原始数据内在的流行几何结构,但没有揭示其稀疏性和鲁棒性.基于此,本文在保留原始数据的内在流行几何结构和运用核技巧来揭示流形的非线性性质的基础上,添加了L2,1/2矩阵伪范数[24]作为额外的稀疏约束.由于稀疏约束能够选择有判别力的稀疏特征来改善算法的有效性,所以它吸引了很多研究学者的极大关注.稀疏约束旨在借助一个有效的稀疏模型来实现原始数据的稀疏表示.虽然非负矩阵分解对原始的数据矩阵可以起到降维的作用,但对于高维数据来说,它的计算仍然是很复杂的.因此,如果能改善基矩阵和系数矩阵的稀疏性,那么将降低计算的复杂度.此外,本文的目标模型中,没有使用常用的欧氏距离作为残差项,而是用L2,1范数[25]来替代标准NMF中的F范数.引入L2,1范数有三点原因[25]:(1)在众多的实际数据中,都包含了很多模糊的噪音值和异常值点等,而L2,1范数可以有效地处理原始数据中存在的这些问题;(2)能提供一个有效的更新规则,进而能有效提高算法的稀疏性和鲁棒性;(3)以它为损失函数所需的计算成本和标准的NMF几乎差不多,并且能提高算法的性能.
本文的其余部分结构组织如下.第二部分主要介绍了标准的非负矩阵分解及相关理论部分,第三部分是本文的重要组成部分,包括本文目标模型的构建、更新迭代规则的推导、新算法的提出以及收敛性分析,第四部分是本文的数值实验展示实验结果分析,第五部分是对本文的总结和概括.本文中Ai矩阵A的第i列,Ai表示A矩阵的第i行.
2 标准的非负矩阵分解
NMF是目前国际上新的矩阵分解方法.它已广泛应用于诸多领域,如图像处理、生物医学、文本聚类和语音信号处理等.标准的NMF问题可描述如下.
换句话说,即解决极小化残差矩阵
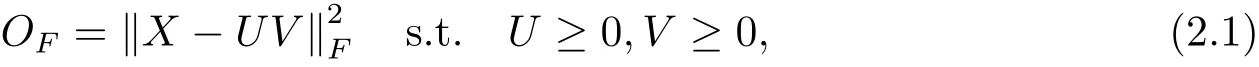
其中k·kF矩阵的表示Frobenius范数,通过计算F范数的平方从而得到两个矩阵的欧式距离.Lee等人[2,6]给出了极小化问题(2.1)的更新迭代规则,并证明了其收敛性,迭代规则如下
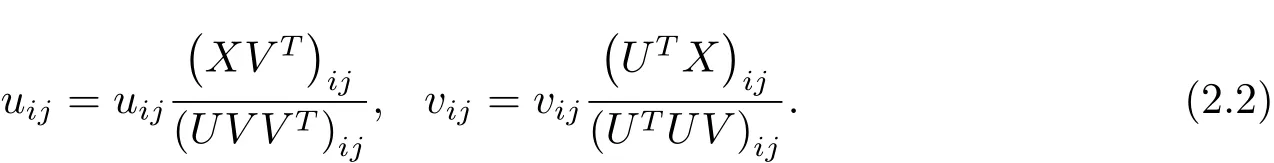
3 基于核的L2,1范数非负矩阵分解
3.1 目标函数
在文献[21]中,Dijana等人考虑一个非线性映射,将数据点映射到高位数据空间:xi→ Φ(xi),或者X → Φ(X)=(Φ(x1),Φ(x2),···,Φ(xn))∈ Rd×n,其中xi表示原始数据空间X的第i样本点.非线性非负矩阵分解旨在找到两个非负低秩矩阵,使得它们的乘积可以无限逼近原始矩阵的映射Φ(X).基于此,Dijana等人[21]提出了基于核的图正则正交非负矩阵分解模型,即
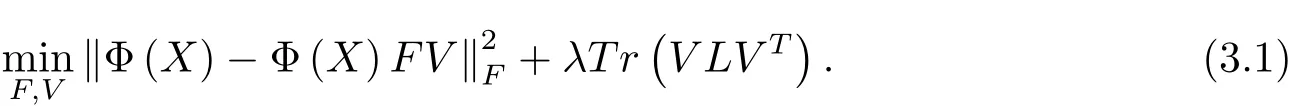
此模型的优势在于,基于内核的非负光谱聚类算法,引入了一个图正则化项,通过图正则项来捕获非线性特征空间中固有的局部几何结构,从而使得因子分解方法具有更强的识别能力,可以从更高维度环境空间的子流形中提取数据点.
但Dijana等人却忽视了原始数据间的稀疏性和鲁棒性.为了充分利用原始数据的内在信息和提高算法的稀疏性及鲁棒性,基于L2,1范数能够处理原始数据中的异常点和极端值点的作用,本文用L2,1范数对原有的Frobenius范数进行改进,并引入混合L2,1/2矩阵伪范数,结合范数算子和非负约束保证了投影矩阵的稀疏性.构建新的目标函数如下
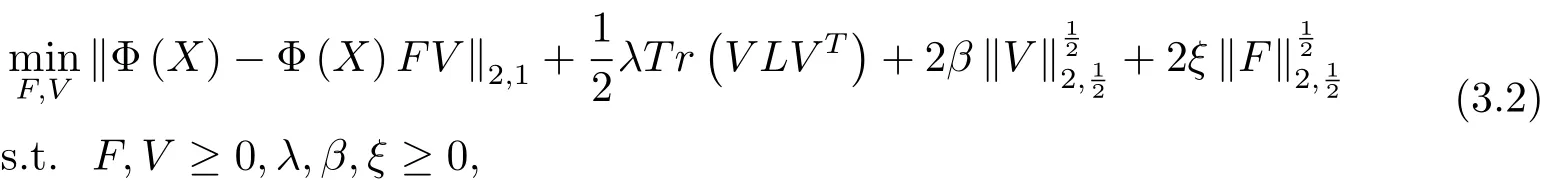
其中λ,β,ξ是平衡因子,L=D−W 为拉普拉斯矩阵,D是一个对角矩阵
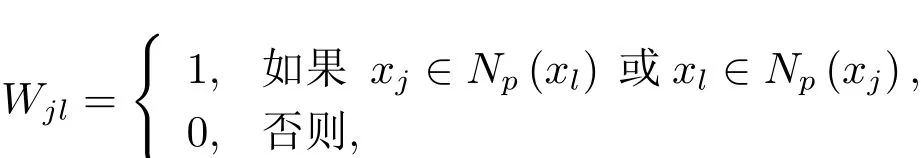
这里的Np(xl)表示xl的p个近邻集合[26].对于(3.2)式,算法只能保证其局部极小化收敛性.其中,该目标函数的第一项是原始数据矩阵和低秩逼近矩阵乘积间的残差项,也是改进算法鲁棒性的重要根据;第二项是图正则项,为了保证其数据的几何结构和控制样本数据点间的局部几何结构的度;第三项和第四项分别是控制对应变量的稀疏性.
3.2 更新规则
记目标函数为
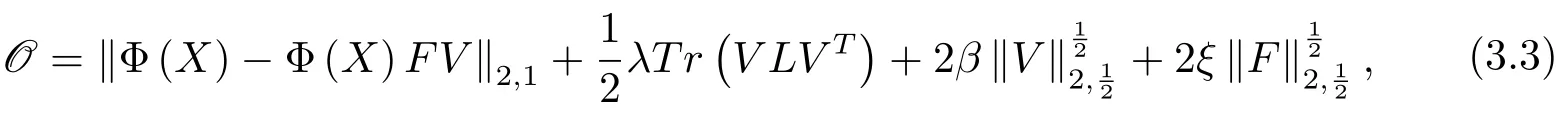
其中


其中G和Q都是对角矩阵,对角元素分别为
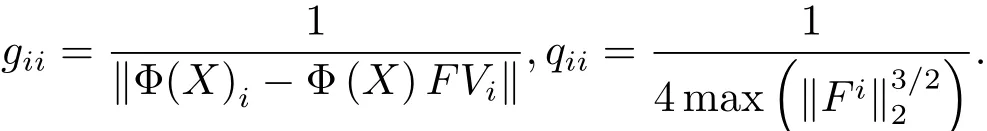
为了避免它们的分母为0的情况,分别添加两个足够小的正常数ε1和ε2在矩阵G,Q的定义中,则它们的元素重新表示为
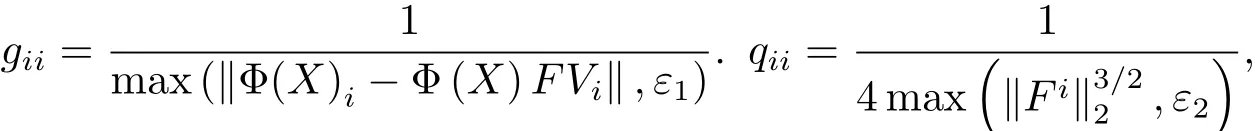
这里的K 是核矩阵[2,3],定义为K≡Φ(X)TΦ(X),其中Φ(X)是在非线性无限维特征空间的特征矩阵.
对F运用Karush-Kuhn-Tucker最优条件(简记为KKT条件)=0,∀j,k,得到

进行简单的代数推导变换即可得到F的更新迭代规则为

现在对目标函数关于V求偏导数,有
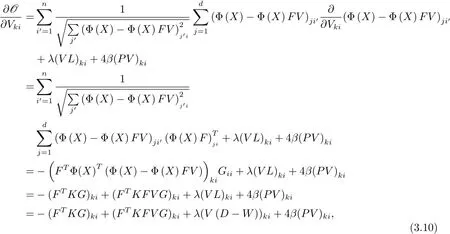
其中P是对角矩阵,其对角元素为
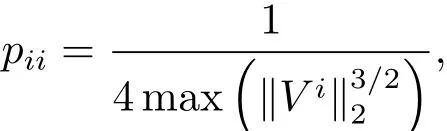
为了避免分母为0的情况,添加一个足够小的正常数ε3在矩阵Q的定义中,即
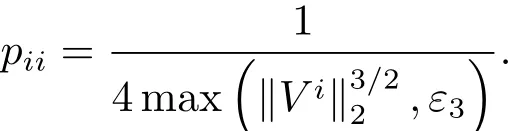
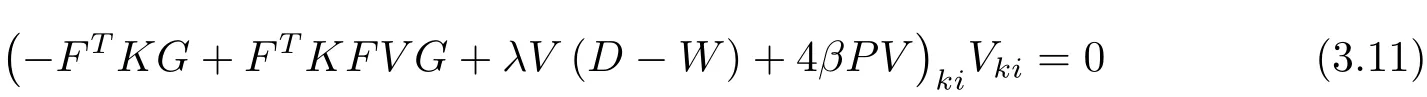
成立.对其进行简单的代数变换即可得到V的更新迭代规则为
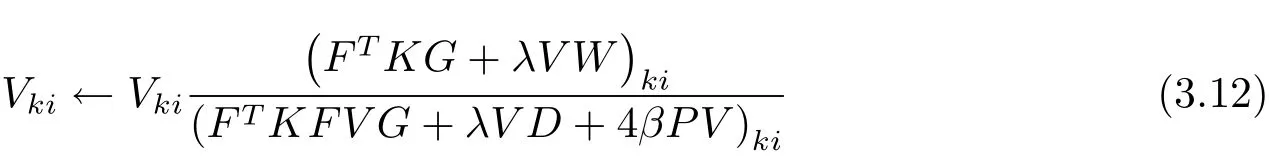
关于迭代更新规则(3.9)和(3.12),有定理1成立.
定理1目标函数(3.1)在迭代更新规则(3.9)和(3.12)下是非增长的.
类似于文献[21],下面给出本文的新算法.

算法:KRSNMF输入:X ∈Rm×n+ ,1≤ k ≤ min{m,n},λ =0.05,ξ=0.1;β =3.5,σ =0.22;输出:U ∈Rd×k+ ,V ∈ Rk×n+ ,F ∈ Rn×k+ .步骤1:随机初始化U,V,F使得它们的取值0到1之间.重复步骤2:更新V根据(3.12);更新F根据(3.9);更新U根据U=Φ(X)F;直到满足停止条件.
3.3 收敛性分析
定义1 如果Z(v,v0)和J(v)之间满足Z(v,v0)≥J(v),Z(v,v)=J(v),那么Z(v,v0)是J(v)的辅助函数.
欲证明Z(v,v0)是J(v)的辅助函数,首先给出引理1.
引理1如果Z是J的辅助函数,则在更新规则

下,J是非增长的,其中右上角的t表示数值计算中的某一步,t+1表示t的下一步.
证
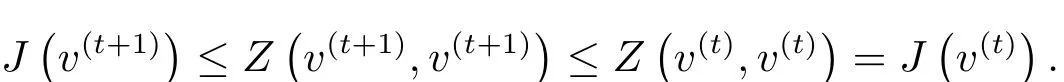
换句话说,只要辅助函数Z(v,v0)达到极小值,函数J(v)也会达到极小值.
对于目标函数(3.1),考虑到矩阵V中的元素Vab,记Jab为目标函数中与Vab相关的部分,对其关于Vab求偏导数,有
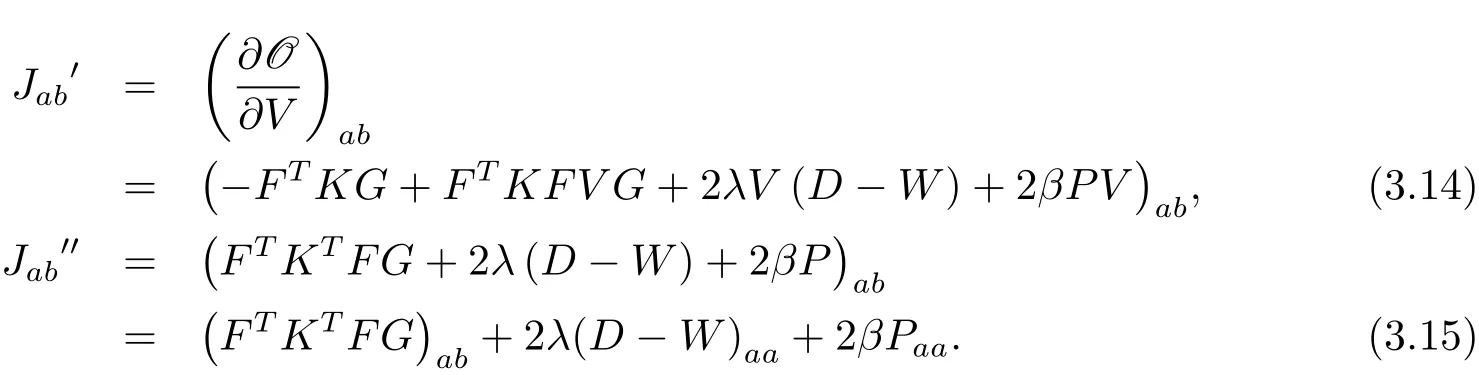
引理2函数
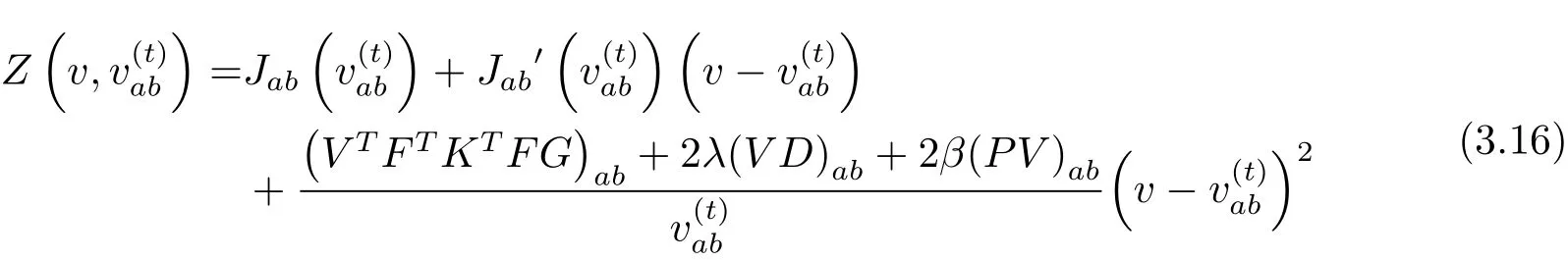
是Jab的辅助函数.
证‡ 显然·有Z(v,v)=Jab(v)成立.要证明的辅助函数,只需要证即可.因为
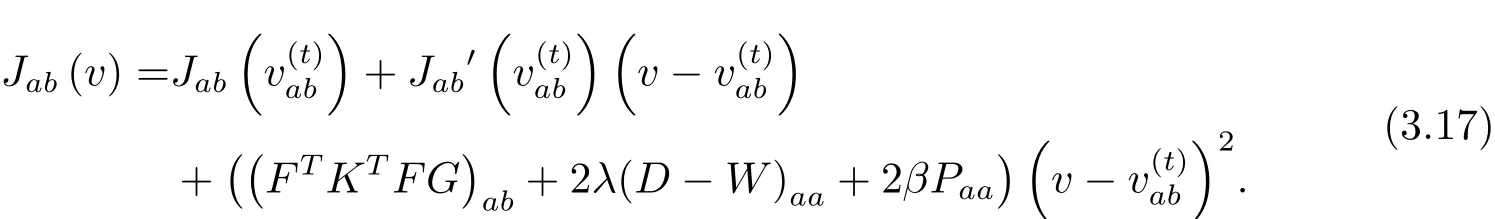

又因为
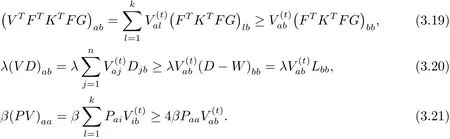
定理1的证明用(3.16)中的替换(3.13)中的有如下的更新规则
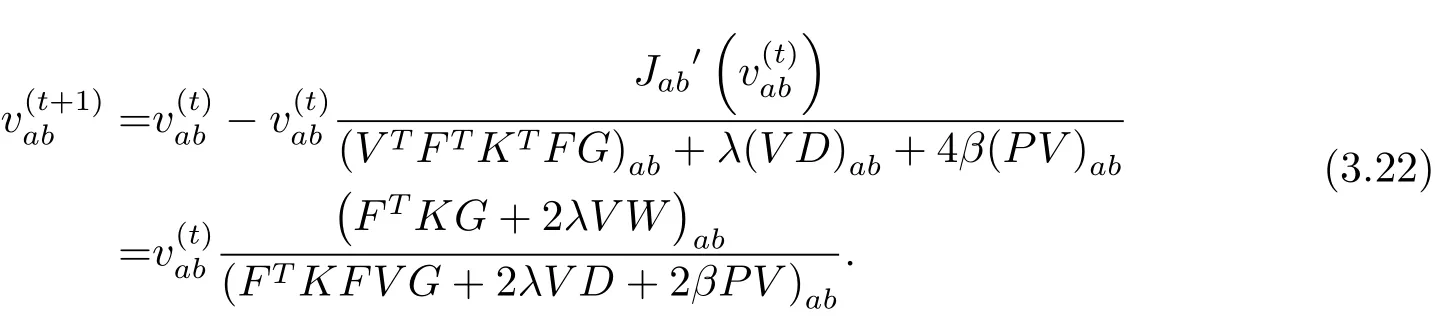
因此Jab在此更新迭代规则下是非增长的.故定理1得证.
4 数值实验
这部分主要介绍了本文在图片聚类中的数值实验的相关内容.聚类是在无类别标记信息的情况下将对象自动分组,换句话说,它旨在将具有相似性质的对象分到同一簇中,根据不同的算法,聚类得到的结果也不尽相同.如图1,2,3所示.图片相关的信息来源于http://www.cad.zju.edu.cn/home/dengcai/Data/data.html.图4是本文用到的KRSNMF算法借助幂指数核得到的聚类图.
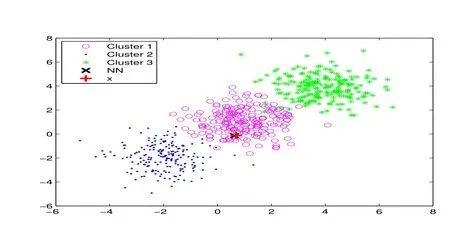
图1 :快速近邻法聚类效果图
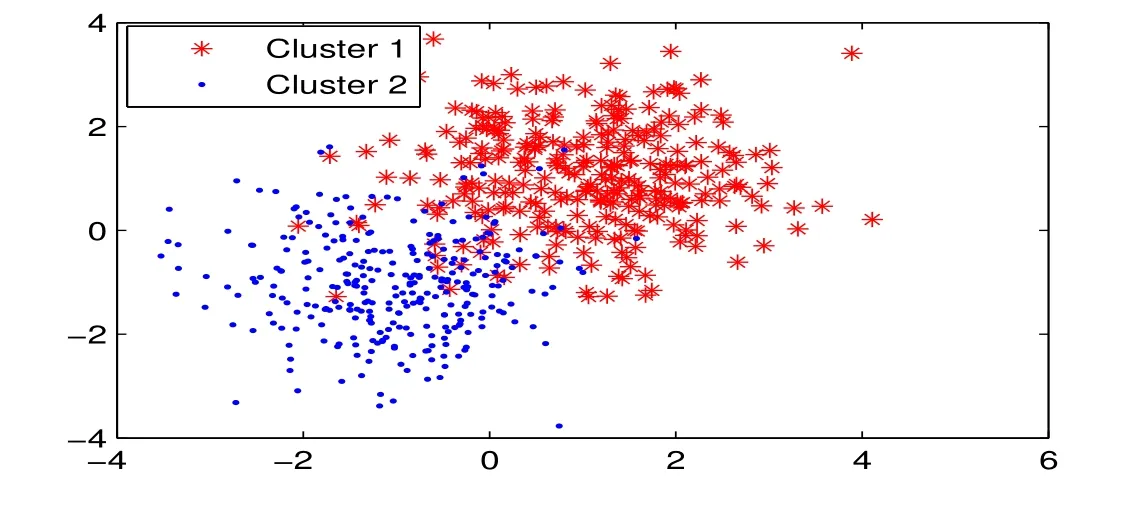
图2 :压缩剪辑近邻算法(Condensing)初始样本分布图
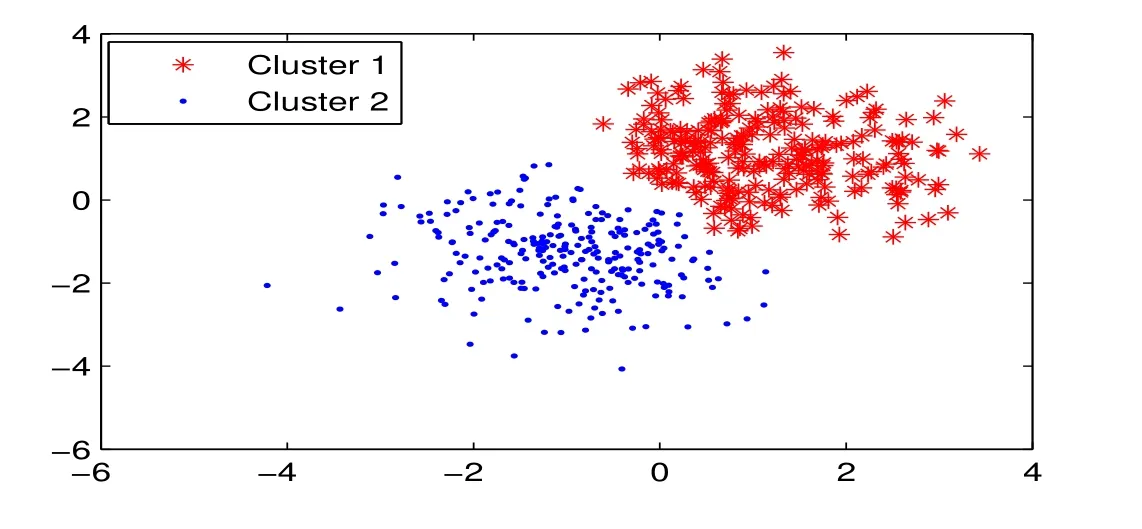
图3 :压缩剪辑近邻算法(Condensing)剪辑后样本分布图
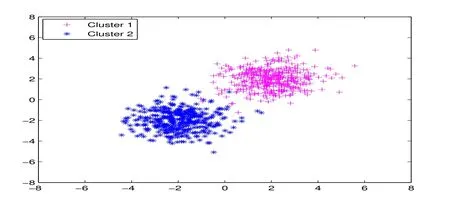
图4 :KRSNMF算法聚类图
本文中选用的数据集都是常用的标准数据集,即
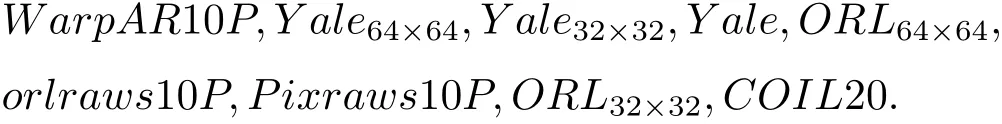
文中所有的数值计算都是在处理器为Intel(R)Core(TM)i5-6500 CPU@3.20 GHz 3.19 GHz,内存为8.00 GB的64位操作系统上进行的,算法代码用MATLAB R2014a进行编写.本文分别选取了三种核技巧在这九个数据集上进行实验,即高斯核技巧、幂指数核技巧和拉普拉斯核技巧.它们的计算方式分别为
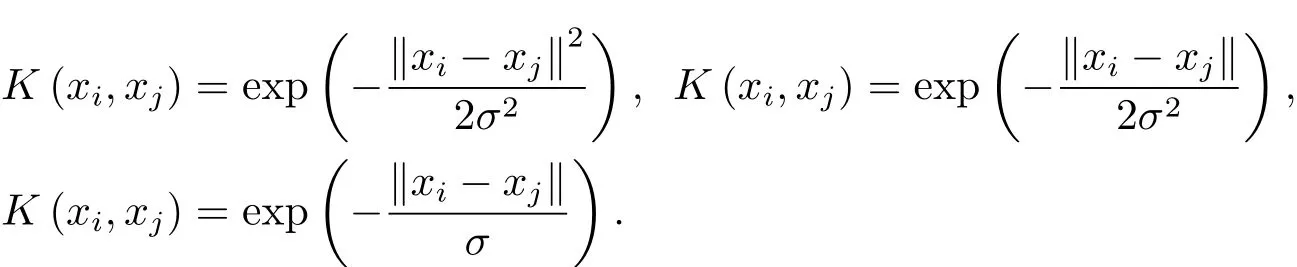
实验中的参数选取如下λ=0.05,ξ=0.1;β=3.5,σ=0.22.
4.1 评价指标
精度(Accuracy,ACC)和归一化互信息(Normalized Mutual Information,NMI)是被广泛应用于不同聚类方法的评价聚类性能的指标.如果xi表示原始数据空间给定的数据点,li是根据某一个聚类算法由数据点xi计算得到的类标签,gi是真实的类标签.map(·)是从li到gi的最佳映射函数,可以由Hungarian算法[27]计算得到.因此聚类精度被定义如下:
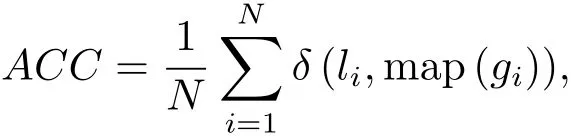
这里的N 是总数据点个数,δ(x,y)是一个delta函数.计算规则:如果x=y,则δ(x,y)=1;否则δ(x,y)=0.
如果用C来表示真实类标集,S表示从某一个算法得到的类标集,则它们的互信息MI(C,S)定义如下:
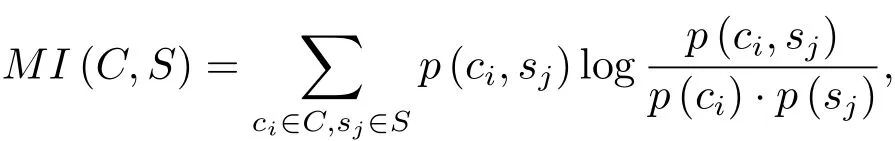
其中p(ci)和p(sj)分别是原始数据集中的任意样本点属于ci和sj的概率,p(ci,sj)是任意样本同时属于ci和sj的联合概率.在实验中,归一化互信息的计算方式为
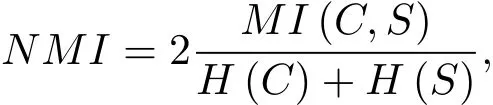
这里的H(C)和H(S)分别是C和S的信息熵,且NMI的值在从0到1内.如果两个聚类集合是同一的,那么NMI=1;如果两个集合是相互独立的,则NMI=0.也就是说,如果两个数据点相似度越高,越有可能被自动分到一个簇.
4.2 实验结果分析
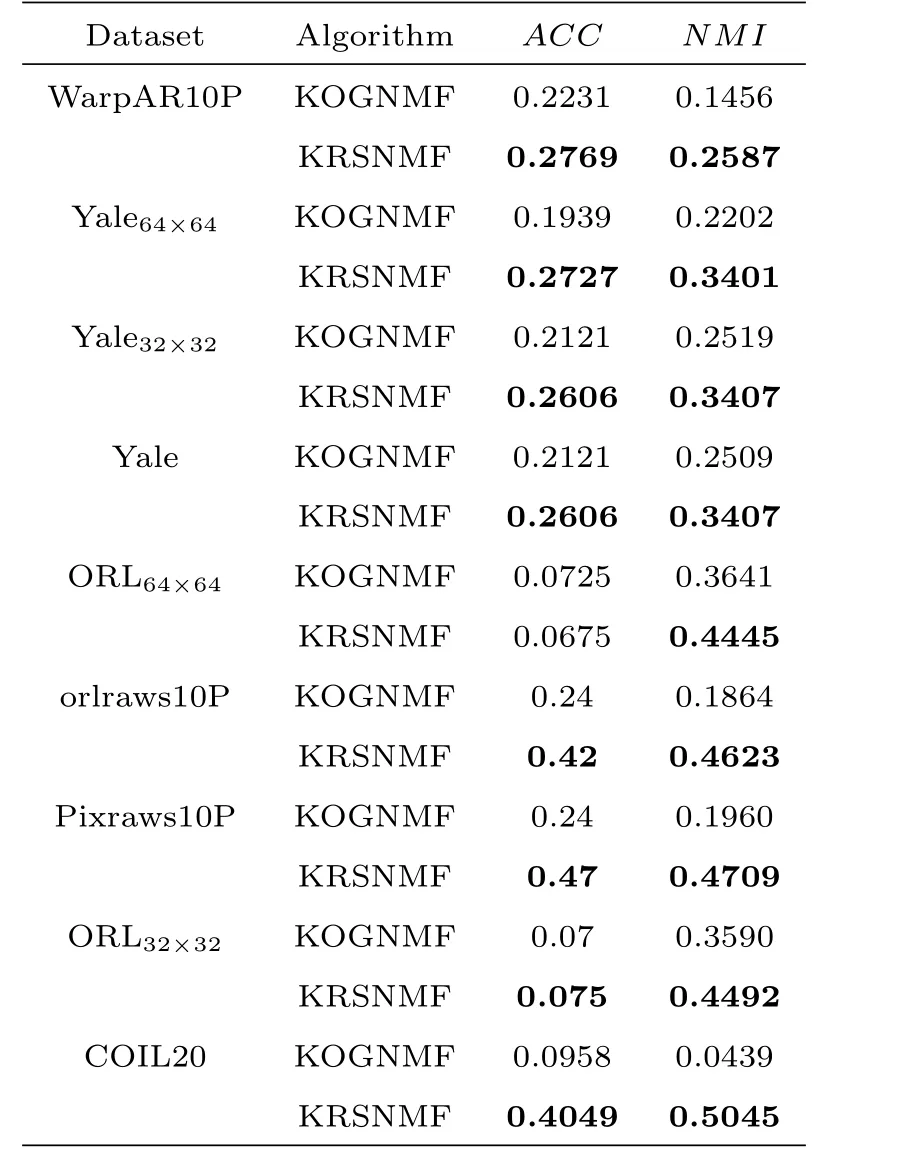
表1 :高斯核聚类性能表
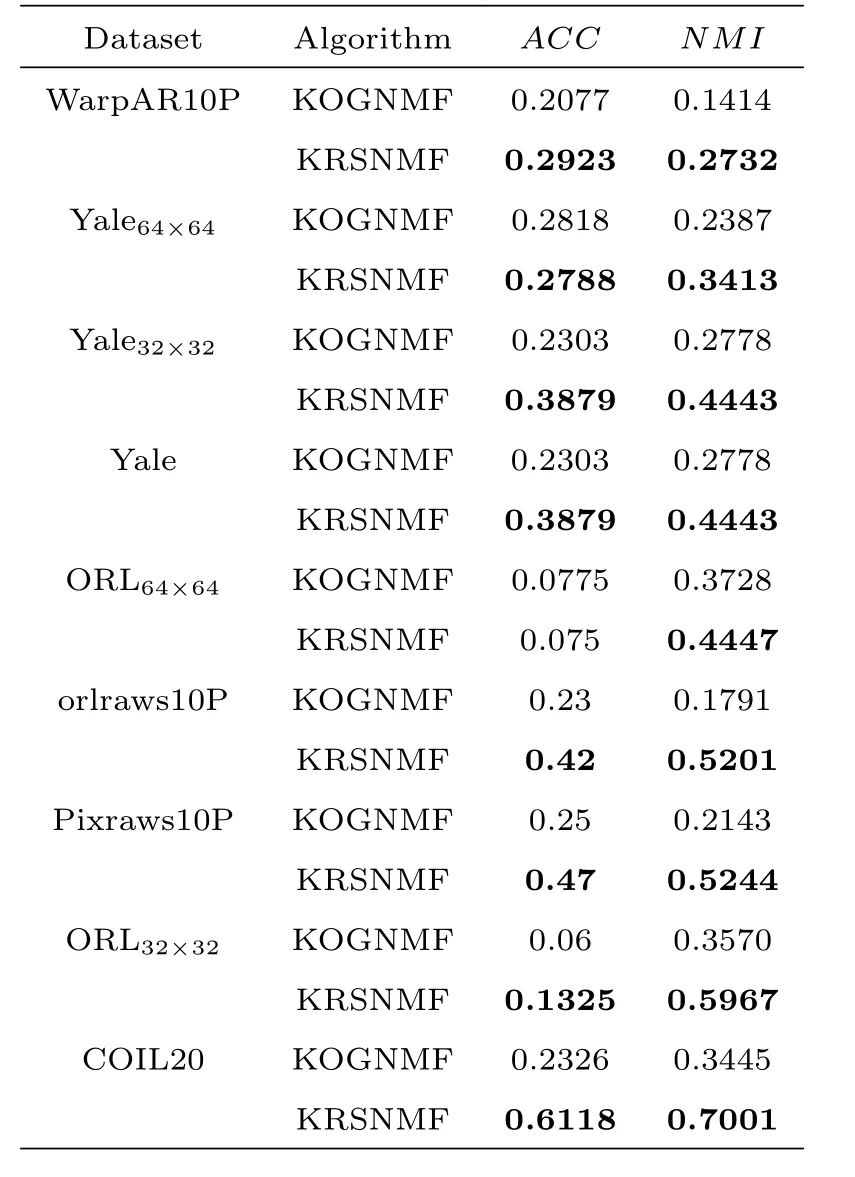
表2 :幂指数核聚类性能表
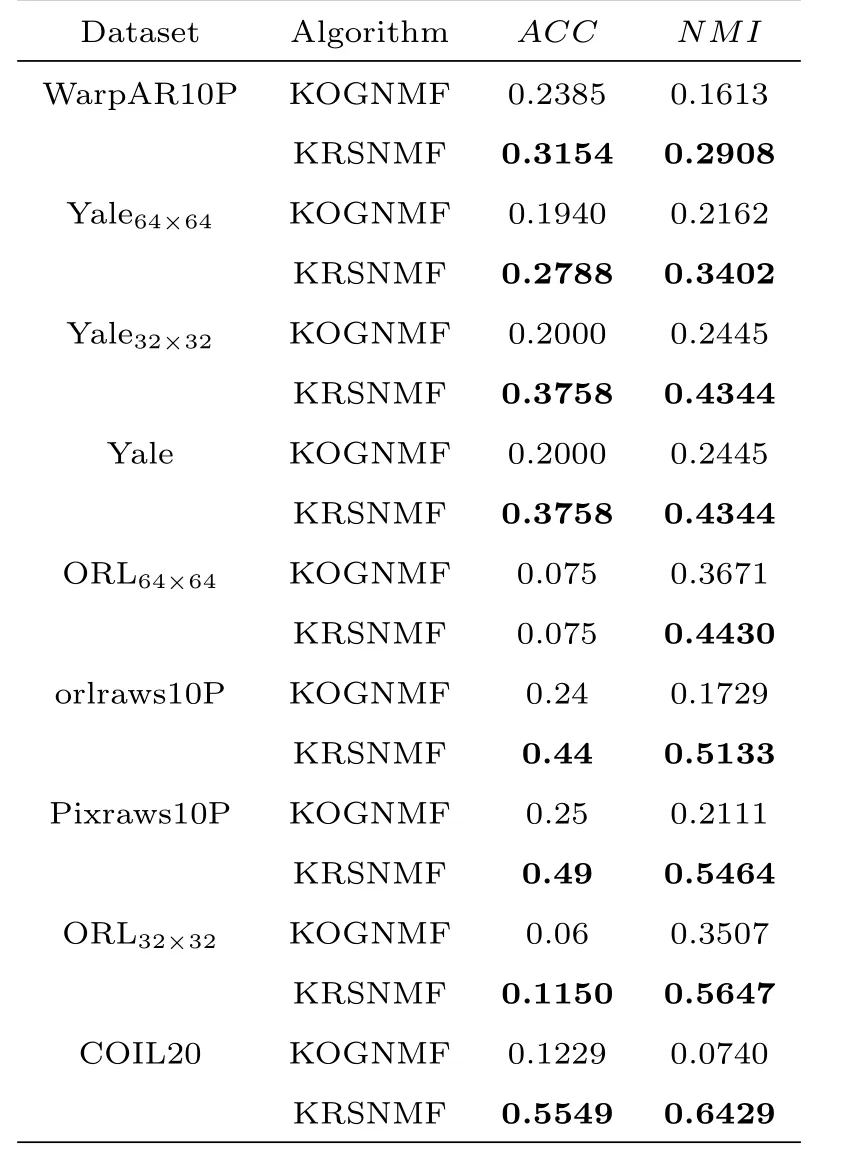
表3 :拉普拉斯核聚类性能表
在文献[21]中,Dijana等人提出了非线性非负矩阵分解算法,本文将此算法记为KOGNMF.这部分主要是KOGNMF算法[21]和KRSNMF算法在九个数据集上的实验结果展示及分析.两种算法的实验结果如表1、表2和表3所示,它们分别展示了运用不同核技巧即高斯核技巧、幂指数核技巧和拉普拉斯核技巧的实验结果.
精度和归一化互信息是评价聚类性能好坏的常用指标.从表1可以看出,在运用高斯核技巧时,对于不同的数据集,KRSNMF算法计算出的ACC和NMI总是要高于KOGNMF的实验结果,在orlraws10P,Pixraws10P,ORL32×32和COIL20这四个数据集上的表现尤为突出.换句话说,对于聚类性能而言,本文提出的KRSNMF算法的性能要优于已有的算法.下面介绍幂指数核的实验结果,幂指数核与高斯核密切相关,只有正态的平方被忽略.而拉普拉斯核心完全等同于幂指数内核,除了对σ参数的变化不那么敏感.事实上,从高斯核、幂指数核和拉普拉斯核的计算公式来看,三者大同小异,都是径向基函数内核,高斯核的σ的选取也同样适合幂指数核和拉普拉斯核.
从表2的显示结果来看,在这九个不同的数据集上,KRSNMF算法的性能总是优于KOGNMF算法,其中在orlraws10P,Pixraws10P,ORL32×32,ORL和COIL20这五个数据集上的更能体现KRSNMF算法的聚类性能,这说明本文提出的KRSNMF算法是有效的.最佳的实验结果体现在体现在COIL20数据集上,该数据集是由20个不同的事物从72个不同的角度拍摄的照片组成的,在此数据上,KOGNMF算法计算出的ACC和NMI分别是0.2326和0.3445,而运用KRSNMF算法时的ACC和NMI分别达到了0.6118和0.7001.这充分展现了KRSNMF算法的有效性.
从表3显示的结果来看,在九个不同的数据集上,依然是KRSNMF算法的性能优于KOGNMF算法,与表2的结果类似,在orlraws10P,Pixraws10P,ORL32×32,ORL和COIL20这五个数据集上的表现更好.其中,在COIL20上的实验结果显示,两种算法计算出的互信息相差0.5689之多.
虽然三种核技巧的计算方式不同,但以上三个表的实验结果都阐明了KRSNMF算法的性能更好.从核技巧的角度而言,选取幂函数核技巧是最有效的.纵观三个表展示的结果来看,本文提出的KRSNMF算法的性能的确要优于已有的算法.这是因为本文在建立的目标模型中引入了对原始数据中的噪音值和异常值点有自动处理作用的L2,1范数,并额外添加了L2,1/2矩阵伪范数作为稀疏约束,从而使算法的稀疏性和鲁棒性得到了良好的改善.
5 结论
本文提出了一种基于核技巧的L2,1范数非负矩阵分解,它是用L2,1范数来替代标准NMF中的F范数,即以L2,1范数为损失函数,并且在保留原始数据的内在流行几何结构和运用核技巧来揭示流形的非线性性质的基础上,添加了L2,1/2矩阵伪范数作为额外的稀疏约束,从而达到提高算法的稀疏性和鲁棒性的目的.在九个常用的标准数据集上进行实验,数值实验结果展示了选取幂函数核技巧是最明智的,也验证了本文提出的KRSNMF算法是有效的.
猜你喜欢
China Report Asean(2022年8期)2022-09-02
物联网技术(2020年12期)2021-01-27
安阳工学院学报(2020年4期)2020-09-11
铁道通信信号(2019年6期)2019-10-08
中国校外教育(下旬)(2017年8期)2017-10-30
汽车零部件(2017年4期)2017-07-12
雷达学报(2017年6期)2017-03-26
自动化学报(2016年3期)2016-08-23
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27

- 数学杂志的其它文章
- CHARACTERIZATION OF A CLASS OF PROPER HOLOMORPHIC MAPS FROM BnTO BN
- TRANSPORTATION INEQUALITIES FOR THE FOURTH-ORDER STOCHASTIC HEAT EQUATIONS WITH FRACTIONAL NOISES
- OPTIMAL CONTROL PROBLEMFOR EXACT SYNCHRONIZATION OF ORDINARY DIFFERENTIAL SYSTEMS
- GRAPHS WITH SMALL NEGATIVE INERTIA INDEX
- 关于短区间的并集中D.H.Lehmer问题的一个推广
- 一维可压缩Navier-Stokes方程组趋向于接触间断波的零耗散极限