
基于深度学习的肺部医学图像分析研究进展
2019-05-24 03:03:00刘锐何先波
川北医学院学报 2019年2期
刘锐,何先波
(1.西华师范大学计算机学院;2.川北医学院基础医学院,四川 南充 637000)
据2018年《CA》杂志发表的全球癌症报告显示,全球发病率和致死率第一的癌症依然是肺癌,每年有18.4%的癌症患者死于肺癌,远高于其后的结肠直肠癌(9.2%)、胃癌(8.2%)和肝癌(8.2%)等[1]。早期肺癌症状很容易被患者忽视,通常很不明显甚至没有症状,一旦患者出现咳嗽长期不愈并且伴随咳血等症状时,表明肺癌大多已经出现转移并进入中晚期,此时病理特征复杂,恶化速度快,已经错过了最佳治疗时机[2]。
肺癌筛查和检测的方式主要可分为两类:一种是通过穿刺获取组织进行筛查,虽然组织学检测对肺癌的检测率非常的高,然而这种方式需要进行皮肺穿刺,对患者会造成不确定的创伤甚至于肺部感染,所以往往作为最后的检查手段;另一种是利用医学影像技术检测,医学图像作为智慧医疗的重要媒介,在医学领域中的作用越来越明显。在医学上,早期肺癌主要的表现形式为肺结节,对于肺结节的检测,临床上大多依赖医学影像技术对患者进行初步诊断,诸如X线成像、计算机断层扫描成像(computed tomography,CT)、锥形束CT、磁共振成像(magnetic resonance imaging,MRI)、正电子发射断层成像(positron emission tomography,PET)等。其中,CT成像技术是当前普遍采用的最高效、最直接的肺结节检测医学影像学方式,因其检查方便且可以清晰地显示体内任何器官组织的结构,成为医生诊断肺部病灶的重要工具。
目前,临床上的肺部肿瘤医学影像诊断方式主要还是人工阅片,然而由于肺部肿瘤的多模态影像和各阶段诊断报告等图像数据呈爆炸式增长[3],海量数据加重了医生的工作量,纵使阅片经验丰富的熟练医生也很难保证完全准确的判断,容易因为人眼疲劳导致漏诊和误诊。随着人工智能的快速发展,深度学习在计算机视觉领域的巨大成功,对于解决医学领域的诸多应用性困难提供了可能性。深度学习是一种通过使用神经网络的表征学习能力来寻找最佳特征表示及其组合的方法,较之浅层学习具有更强的特征学习能力,结合医学影像学可以辅助医生进行准确、高效地诊断,对于肺癌的诊断有着重要的研究意义和应用价值[4]。本文介绍了深度学习及其在医学图像处理领域的研究进展,尤其对肺部肿瘤图像方面的应用研究现状做了重点介绍,最后总结了深度学习在医学图像分析中面临的主要问题并对应用前景进行了展望。
1 深度学习
1.1 深度学习概述
深度学习作为机器学习领域的一个重要分支,其概念的提出最初是由Hinton等人通过对人工神经网络的研究发表于2006年的《Science》杂志中[5]。目的是通过多层网络结构来模拟人脑神经元的数据处理特性。较之于传统的机器学习方法,深度学习是更加优异的图像特征表示方法,可以同时在一个模型结构里进行学习和分类,因此我们可以直接输入原始图像进行训练和预测学习并且可以取得一个不错的结果。如今,深度学习作为机器学习中的佼佼者,在序列预测、语音识别、计算机视觉和图像处理等多个领域取得优异的成绩,其主要原因是:计算机运算能力大幅度的增长;以NVIDIA公司为代表的厂家推出更高性能的阵列GPU集群,正是高性能GPU的广泛使用为深度学习提供了硬件支持;随着人工智能理论知识体系的不断完善以及数据采集方法的提高,使深度学习可以采用分层式的方式通过更加高效的计算单元完成快速有效的特征学习和预测回归。深度学习采用训练大规模数据集的方式搭建拥有多个隐含层的自动学习网络模型,通过自动学习让每层得到有用的特征,继而提取得到逐层数据特征,获取低维、稀疏和更高层的特征,在医学图像处理方面具有明显的优势。深度学习模型结构主要分为三类,即生成性深度结构,区分性深度结构以及混合型结构[6]。常用的模型结构主要有自动编码器(auto encoder,AE)、深度玻尔兹曼机(deep boltzmann machine,DBM)、限制玻尔兹曼机(restricted boltzmann machine,RBM)、深度信念网络(deep belief networks,DBN)、循环神经网络(recurrent neural network,RNN)、卷积神经网络(convolutional neural networks,CNN)等[7]。
1.2 深度学习框架介绍
深度学习技术的不断突破,除了众多学术界的专家在理论方面的贡献之外,工业界也作出了巨大贡献,出现了许多开源的深度学习框架可用于快速搭建神经网络模型并可直接运用到实际系统中。接下来介绍几个目前流行的开源框架的设计思路和优点。
(1)Caffe框架
Caffe(convolution architecture for feature extraction)是由加州大学伯克利分校视觉和学习中心(berkeley vision and learning center,BVLC)开发的基于C++/CUDA/Python架构实现的卷积神经网络框架,其创建者是贾扬清博士。Caffe以前馈卷积神经网络架构(如CNN)为基础,提供了面向命令行、Matlab和Python等众多接口。最大的特点是适合做特征提取,并且能够在CPU和GPU之间快速切换,支持GPU加速以更快的实现CNN的学习过程。2017年4月18日,Facebook根据BSD许可协议开源出Caffe的升级版Caffe2,鉴于其更加全面的特性,预期未来可能超越Caffe成为更受追捧的深度学习框架。
(2)MxNet框架
MxNet的开发者来自分布式机器学习社区(distributed machine learning community,DMLC),是一个面向效率和灵活性设计的深度学习框架,被亚马逊云计算服务平台(AWS)官方所推荐。MxNet是各个框架中最先能够支持多GPU和分布式训练的框架。MxNet基本支持所有的主流脚本语言的绑定,比如C++、Python、R、Julia、MATLAB和JavaScript等。
(3)TensorFlow框架
TensorFlow是相对高阶的基于Python开发的开源深度学习库,由Google Brain基于第一代深度学习架构DistBelief开发,用户可以简便快捷的使用它设计神经网络模型。TensorFlow支持自动求导,核心代码是用C++编写并且降低了线上配置的复杂度,能够支持异构设备的分布式计算,可以部署在包括智能手机、PDA、电脑、服务器等多种设备上自动运行算法,具有极佳的灵活性、轻便性和高效性。TensorFlow使用数据流图集成了目前深度学习中最流行的单元,除了支持图像识别、语音识别、自然语言处理等领域诸如CNN、RNN和LSTM算法的常用神经网络模型结构外,还支持深度强化学习,比如求解高维偏微分方程,并且依然在不断的快速更新。
(4)Keras框架
Keras是采用纯Python语言开发的极简和高度模块化开源神经网络库。旨在支持深度神经网络的快速实验而生,能够在TensorFlow、Theano、CNTK和MxNet上运行。Keras提供了目前最方便的API接口,用户组合多种高级模块就能够快速简便的进行神经网络模型的设计,非常容易入门。Keras同时支持CNN和RNN,支持多输入和多输出结构,具有高灵活性、高简洁性、易理解性等特点。Keras可以从CPU计算到GPU加速之间无缝地切换,常以TensorFlow和Theano作为后端,因此可以直接通过此两种框架持续开发所带来的性能提升,将性能损失降低到最小,而且往往只需要极少数的代码就能实现其他任何框架大量代码才能实现的任务,对于新模块的添加非常便捷,非常适合前沿研究。
2 医学图像分析研究现状分析
2.1 医学图像分割研究进展
2015年,研究提出了一种利用少量的医学图像直接进行端到端训练的全卷积神经网络模型,用于轴向切片上的候选选择,大幅度刷新了之前机器学习模型保持的记录,在当年的医学图像分割的比赛中取得了优异的成绩,此模型即为医学图像分割中最著名的模型U-net[8]。元昌安等[9]基于K均值和新的核函数的方法改进RSF模型,通过此模型对进行图像分割处理,与原算法相比,实验结果显示改进后的算法在具有更快执行速度的情况下对分割精度提高了40%。Carneiro等[10]将深度学习技术和基于导数的检索方法相结合,分割心脏超声图像的左心室,结合动态模型与深度神经网络对左心室心内膜超声数据进行跟踪,使结果更加的精确。Zhao等[11]提出了一种结合CT图像的灰度信息的肺实质的分割算法,基于传统的区域生长法采用四角旋转的方法分割了图像。Jia等[12]提出了一种利用主动轮廓模型来分割肺结节的方法,将肺部医学图像的局部灰度平均值和边缘能量结合了起来。Zhang等[13]基于三维深度卷积神经网络对医学图像进行特征提取,明显提升了对MRI脑肿瘤(婴儿)、膝关节软骨和前列腺组织的分割结果。
2.2 病灶图像识别研究进展
Wu等[14]利用超声造影的良恶性结果基于深度学习对肝脏局灶性病变进行分类。Jia等[15]通过稀疏自编码器对肺结节的良性和恶性进行识别。Song等[16]提出了基于二维卷积神经网络(2D CNN)直接训练横切面图像的结节检测方法。Shin等[17]采用稀疏自编码器将动态对比增强磁共振成像(DCE-MRI)的组织类型进行了全自动分类。Donahue等[18]采用ImageNet训练100多万张自然图像得到的卷积神经网络模型DeCAF中提取出中高维特征进行目标识别、情景分析和图像分类都取得了优异的结果。
2.3 计算机辅助诊断研究进展
Suk等[19]利用深度玻尔兹曼机在多模态医学图像中挖掘高维特征,对阿尔茨海默病和轻度认知功能障碍的诊断准确率高达95.35%与85.67%。Burlina等[20]基于深度卷积神经网络结合超声检查图像对80例受试者的肌肉全自动分类,以此诊断肌炎。Dou等[21]提出了一种直接对三维的原始数据进行训练的卷积神经网络模型检测人体大脑微出血状况,获取到大量有用的高维特征,敏感度达到了93.16%。金林鹏等[22]提出了一种导联卷积神经网络,以多导联心电图独特的二维结构进行识别,准确率达到了83.66%。
3 深度学习在肺部肿瘤诊断中的应用
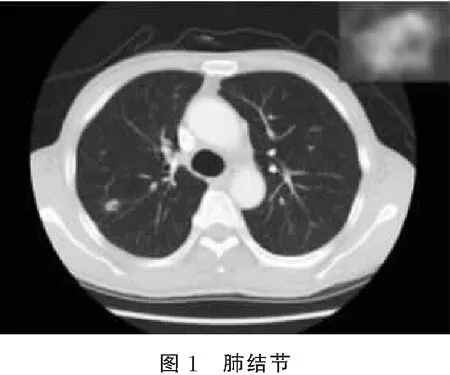
肺癌的早期筛查对于患者的及早治疗意义重大,肺癌的主要早期表征是肺结节,由于其体积或半径极小,一般为不规则的类圆白亮结构(图1),在CT影像中很难被分辨出来,大大增加了漏诊的几率[23];通常按照肺部病变形态学和患者的实际感受来区分良性和恶性结节,恶性肺结节边缘具有毛刺且多为不光滑形态[24],放射科医生往往是根据自己的经验界定肺结节的良恶性,这种情况下会导致诊断结果的客观性不足,由此产生的假阴性结果会使患者错过治疗的最好时机,与此同时,通常假阳性疑似患者要利用组织学等临床手段排除,这会给患者增添痛苦甚至增加病情恶化的风险,且费用较昂贵。为了帮助医生和患者解决这些问题,基于深度学习结合医学影像学进行肺结节检测识别变得尤为重要。Sun等[25]基于癌症图像数据库集合(lung image database consortium,LIDC)结合深度学习算法进行了肺结节计算机辅助诊断研究,使用到的深度学习算法有三种,即为堆叠去噪自编码(SDAE)、深度信念网络(DBN)和卷积神经网络(CNN),与传统的计算机辅助诊断系统的准确率(0.794 0)对比发现,SADE的准确率为0.792 9,CNN的准确率为0.797 6,DBN的准确率为0.811 9,CNN与DBN的准确率略高。目前,肺部病变利用计算机辅助诊断检测主要有两个步骤:第一个是通过肺部感兴趣区域的分割提取大量疑似病变组织,在尽量不考虑假阳性的前提下筛查出真结节,降低漏诊率;第二个是通过良恶性判断,提取有效特征,对感兴趣区域进行良恶性分类从而去除假阳性,提高准确率。
常见的疑似结节提取方法主要有模板法、形态学法、遗传算法、阈值法、聚类法、以及其他神经网络算法等,关键技术主要包括:图像增强、图像ROI分割、提取多维度特征。在对肺部病变组织进行检测识别时,为了初步定位病灶区域,先要对肺实质进行分割,接着对比分析提取出的灰度、形状、纹理、对比度等不同特征,确定疑似病灶,达到检测肺部肿瘤的目的。
基于肺部医学图像的计算机辅助诊断系统进行良恶性判断涉及到的关键技术在于模型设计和疾病分类,候选结节的分类作为肺结节检测的热点,常用分类器通常分为基于规则的分类器和基于模式识别的分类器,如决策树、随机森林、神经网络、支持向量机等。近些年来,随着深度学习技术的不断进步,神经网络算法越来越多的被用于肺部病变计算机辅助诊断系统中。王克全等[26]将模糊神经网络辅助诊断介入到肺部肿瘤CT图像的诊断中,实验结果显示与病理结果相比该方法对于肺部肿瘤的诊断结果相差不大;Yoshida[27]利用肺区左右对称的原理用以降低肋骨结构对肺结节检测的影响,达到降低假阳性的目的。Suzuki等[28]提出了一种大规模人工神经网络图像处理技术,直接输入胸片的感兴趣区域,该技术可有效解决胸片上肋骨和锁骨遮挡肺结节而影响检测的问题,降低假阳性,提升了准确率。Weng等[29]首先预训练深度神经网络,输入相干反斯托克斯拉曼散射图像再次训练模型,对于肺部图像正常、小细胞癌、腺癌和鳞状细胞癌的分类,准确率达到89.2%。
4 总结与展望
随着大数据时代的来临,深度学习应运而生,凭借着优异的图像处理能力,已经出现了可用于临床上的肺部肿瘤计算机辅助诊断系统,并且具有一定的辅助诊断意义,可是最大的问题依然是如何降低假阳性,减少人工干预实现真正的智能化检测。同时由于肺结节计算机辅助诊断研究需要大规模的带医生标注信息的数据集作为基础,反而使之成为了制约系统功能进一步增强的因素。因为大规模带有医生标注信息的医学图像数据集很难获取,这需要耗费大量的人力、物力才能实现普及标准化的医学图像数据集。所以如何使深度学习可以通过小样本的学习准确预测病变组织,取得不弱于使用大规模数据集训练后的结果,是未来可以研究的方向。同时对抗学习方式的出现也为我们提供了一个解决思路,如果可以通过对抗网络(GAN)生成具有实际意义的病变组织数据集,以此扩大原有的医学影像数据集,就可以产生大量带有金标准的医学影像数据。此外,在国家进一步的医疗改革的大背景下,医疗大数据中心的建立使得含有大量自然语言描述的电子病历和诊断报告都可作为医学图像数据的补充,基于计算机视觉领域中的先进方法对于医学图像处理、计算机辅助诊断等领域可以预见到会有巨大的帮助。随着深度学习技术的改进和完善,计算能力和硬件性能的不断提高,在这个有标记医学图像大数据时代中,深度学习在医学图像分析中具有广阔的应用前景。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中老年保健(2021年6期)2021-08-24 06:53:54
中老年保健(2021年9期)2021-08-24 03:50:24
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
中国民间疗法(2021年1期)2021-04-20 02:30:30
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年11期)2019-07-04 00:34:38
中国生殖健康(2019年10期)2019-01-07 01:21:06
中国交通信息化(2018年5期)2018-08-21 03:37:40
