
基于CNN-ATTBiLSTM的文本情感分析
2019-04-30 07:40刘书齐王以松陈攀峰
贵州大学学报(自然科学版) 2019年2期
刘书齐,王以松,陈攀峰
(贵州大学 计算机科学与技术学院,贵州 贵阳 550025)
随着互联网技术的飞速发展,各种电商、微博、博客、推特等社交平台纷纷涌现,互联网上产生了大量带有情感倾向的文本信息。通过分析这些带有情感倾向的文本,对电商改进产品服务、政府舆情监控等都具有重要的参考价值。然而,人们在这些平台上产生的数据量是海量的,依靠人工分析这些数据,已经是不可能的了,这促进了文本情感分析技术的发展。文本情感分析又称意见挖掘,简单而言,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程[1]。
文本情感倾向分析方法主要有两类,一类是基于规则和词典的方法;另一类是基于机器学习的方法。基于规则和词典的方法效果比较差,基于传统机器学习的方法虽然效果比较好但是需要人工设计大量的特征,特征的好坏直接影响了算法性能的好坏。随着神经网络研究的再次复苏,基于深度学习的文本表示学习在文本特征提取上取得了重大进步。卷积神经网络(Convolutional Neural Network, CNN)、循环神经网络(Recurrent Neural Network, RNN)等深度学习模型已经很好地应用在文本建模上,并取得了不错的效果。CNN在对文本建模时,提取的是文本的n-gram信息,是局部相连词的潜在特征,但是忽略了上下文信息,而且在池化时可能丢失重要的语义信息。
传统的RNN存在梯度消失和梯度爆炸的问题,在文本建模中常用的是长短期记忆(Long Short-Term Memory, LSTM)网络[2],而普通的LSTM仅仅只是对文本上文建模没有考虑下文,本文引入了双向的长短期记忆(Bi-directional Long Short-Term Memory, BiLSTM)网络[3],考虑上文和下文相关性,由于文本中每个词对文本语义的贡献是不一样的,于是引入注意力机制进一步提升RNN特征提取的效果,即基于注意力机制的双向长短期记忆 (Attention-based Bi-directional Long Short-Term Memory,ATTBiLSTM) 网络,最后为了防止过拟合采用dropout[4]策略。
1 相关工作
2002年PANG等人利用基本的词特征和有监督的机器学习方法(朴素贝叶斯、最大熵和支持向量机)来解决情感分析的问题,比较了词特征组合和各种分类器的分类效果[5]。考虑到文本中的主观句对情感倾向性判定的影响,2004年PANG 和 LEE将主观句子抽取出来引入到情感分类的特征中,同时去掉客观句,提高了分类效果[6]。2010年LI等人分析了极性转移对情感分类的影响[7]。2012年WANG和 CHRISTOPHER ,在SVM、NB两个分类器的基础上提出NBSVM模型,在情感分类任务上比单一的SVM、NB表现得更好[8]。
近年来,越来越多的自然语言处理任务开始尝试使用深度学习模型。2013年TOMAS 等人提出一个用于学习词语分布式表示的神经语言模型,该模型可以学习到词语的表示并包含了词语的语义信息[9]。2014年,NAL等人提出了一种动态k-max池化卷积神经网络用于句子建模[10]。同年,YOON将卷积模型用于句子级的情感分类[11]。KAI等在2015年则使用长短期记忆时网络来解决情感分析问题[12]。2017年YANG等使用基于层次化注意力机制的双向循环神经网络对文本进行分类,取得了很好的效果[13]。
基于传统的机器学习方法的文本情感分析所使用的文本表示方法大多是词袋模型,词袋模型丢失了词的顺序信息,忽略了词的语义信息。基于深度学习的方法可以主动学习文本的特征,保留词语的顺序信息,可以提取到词语的语义信息。
2 模型结构
本文提出的模型结构如图1所示,最下面是文本的词向量矩阵、中间是CNN、ATTBiLSTM网络结构,hc、hr分别为两个结构获取的特征,hs为融合后的特征,最后hs输入softmax层。

图1 混合神经网络模型结构Fig.1 Hybrid Neural Network Model Structure
2.1 CNN
CNN是一种前馈神经网络,本文使用的网络结构可以分为三层,输入层、卷积层、池化层。
输入层:以句子的词向量矩阵为输入,每个句子X为n×k的矩阵,n为句子的长度,k为词向量的维度,词向量采用word2vec工具在中文维基百科语料上训练得到,X=[x1,x2,…,xi,…,xn],i∈[1,n],xi为句子中的第i个词的词向量表示。
卷积层:是特征提取层,通过选择多个不同尺寸的卷积核,同时每种规格的卷积核选择多个,卷积核的规格为m×n,m为宽度大小,n为句子的长度,通过卷积操作最后得到多个特征图。
其中:Cj为第j个卷积核卷积操作得到的特征图,ci为第i个卷积操作的结果,f为线性正单元(ReLu),w形状为m×n,*为卷积操作,xi:i+m-1为句子中第i个到第i+m-1个词语的词向量组成的矩阵,b为卷积核的偏置项。
池化层:也称下采样层是特征选择层,从卷积层得到的特征图Cj中选择最大的特征值,最后将从不同特征图中得到的特征拼接在一起,作为CNN提取的特征。


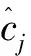
2.2 ATTBiLSTM网络
2.2.1BiLSTM网络
标准的RNN存在梯度消失和梯度爆炸的问题对于长序列学习问题存在很大的困难。为了解决这个问题HOCHREITER 等在1997年提出长短时记忆神经网络(LSTM)[2],在LSTM中有三个控制门(遗忘门、输入门、输出门)和一个记忆细胞,可以有效地保留历史信息即上文,缓解梯度消失或爆炸的问题,学习到更长序列的依赖信息。单向的LSTM只考虑上文依赖信息,这在文本建模中是有明显缺陷的,在句子中还需要下文的信息。
1997年SCHUSTER , PALIWAL 提出了双向循环神经网络[3],网络单元为LSTM的BiLSTM神经网络结构如图2所示。hi为双向LSTM两个隐藏层输出拼接的结果,Wi为词向量。

图2 BiLSTM网络模型结构Fig.2 Bi-directional Long Short-Term Memory Network Model Structure
2.2.2注意力机制
对于整个句子而言,每个词对句子语义的贡献率是不一样的,本文引入注意力机制抽取重要词语的语义信息。
其中:uw为上下文向量,随机初始化,在训练的过程中更新;ui为hi经过一个全连接层运算的结果;Ww,bw分别为注意力计算的权值矩阵和偏置项;αi为第i个词的注意力分数。
2.3 特征融合
CNN和RNN已经被证明在文本语义表示上是有效的。CNN的卷积操作限定在一定大小的窗口内,卷积核所提取的特征受到窗口大小的影响,提取的是n-gram信息,而且池化操作会丢失位置、依赖等语义信息。双向循环神经网络可以捕捉到文本中长距离的依赖信息以及上下文信息,在一些实验上引入了注意力机制的双向循环神经网络的模型效果是可以超过CNN的。但是由于短句子偏多使RNN并没有提取到很好的句子信息,因而在一些实验上RNN的效果甚至不如CNN。本文通过融合CNN、ATTBiLSTM两种模型提取的特征优势互补。
hs=hr+hc
2.4 全连接层
Dropout[4]是指在深度学习网络中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃,在测试的时候保持正常。dropout可以使得学习到的模型更鲁棒,缓解过拟合。
全连接层使用dropout技术和L2正则项防止过拟合,输入为融合特征,通过softmax函数得到分类的分数,使用交叉熵作为损失函数。
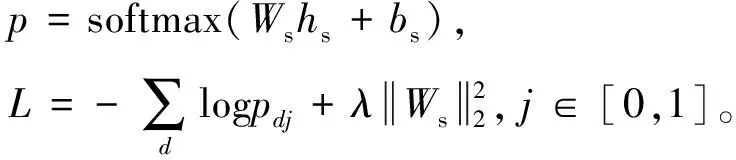
3 实验
3.1 实验数据准备
本文选用有关中文文本情感分析的酒店评论数据集(ChnSentiCorp)做实验验证模型的效果,这个数据集是由中科院谭松波博士整理的一个中文酒店评论数据集,该数据集有四个子集,分别是ChnSentiCorp-Htl-ba-1、ChnSentiCorp-Htl-ba-2、ChnSentiCorp-Htl-ba-3 、ChnSentiCorp-Htl-ba-4、其中前面三个是平衡数据集最后一个是非平衡数据集。本文选用中间的两个平衡数据集。即ChnSentiCorp-Htl-ba-2和 ChnSentiCorp-Htl-ba-3。其中ChnSentiCorp-Htl-ba-2包括正负样例各2000个,ChnSentiCorp-Htl-ba-3包括正负样例各3000个。
3.2 实验评价指标
本文使用四个评价指标衡量模型的效果,分别是准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值,计算公式如下。
3.3 超参设置与训练
ZHANG[14]等人对CNN在句子分类任务中的参数设置进行了实验,本文参考该文进行了实验,最终确定本文网络结构使用的激活函数为ReLu,采用3种不同尺寸的卷积核,卷积核的宽度分别为2、3、4,每种尺寸的卷积核各100个,CNN最终提取的特征向量维度为300。使用的LSTM单元的大小为150,通过ATTBiLSTM后输出维度为300,上下文向量uw维度为10,最终融合CNN和ATTBiLSTM神经网络提取的特征得到300维的特征向量,最终输入全连接层和softmax层,其中全连接层使用dropout正则化技术防止过拟合。整个模型使用Adam优化器训练。本文选取句子长度分布中间80%占比的句子长度的最大长度做为标准长度,对所有的文档做填充和截断。
4 实验结果与分析
支持向量机(Support Vector Machine, SVM):在传统的机器学习方法中,在情感分类上较其他方法有较好的效果,本文使用skip-gram训练得到的词向量对句子中的词向量平均作为输入进行分类。
CNN:使用skip-gram训练的词向量组成的矩阵作为输入经过卷积神经网络进行分类。
BiLSTM:使用skip-gram训练的词向量矩阵作为输入经过双向长短期记忆神经网络进行分类。
ATTBiLSTM:在BiLSTM的基础上引入注意力机制后的模型,同样使用skip-gram得到的词向量矩阵作为输入。
CNN-ATTBiLSTM:以skip-gram训练的词向量矩阵作为输入,分别通过CNN、ATTBiLSTM提取特征,最后将两种特征融合进行分类。
本文与SVM、CNN、BiLSTM、ATTBiLSTM四个基线模型进行对比,实验在ChnSentiCorp-Htl-ba-2、ChnSentiCorp-Htl-ba-3两个数据集上进行,受数据集大小的限制实验采用五折交叉验证,实验结果如表1、表2所示。

表1 ChnSentiCorp-Htl-ba-2实验结果Tab.1 Results on ChnSentiCorp-Htl-ba-2

表2 ChnSentiCorp-Htl-ba-3实验结果Tab.2 Results on ChnSentiCorp-Htl-ba-3
通过以上实验数据对比我们发现,SVM由于只是简单地对词向量进行平均,没有考虑词语的顺序以及句子的深层语义信息因此效果最差;CNN、BiLSTM两者都提取了一定的语义信息所以效果差不多,CNN的效果要略好于BiLSTM,这是由于在数据集较小文本较短的情况下,CNN的卷积效果可以整体提取句子的语义信息,而BiLSTM则无法发挥其优势。而通过在BiLSTM中引入注意力机制的ATTBiLSTM则表现得比CNN好,这是因为ATTBiLSTM在特征提取的过程中会过多地关注句子中比较重要的词语信息,减少那些不重要的信息的负面影响。本文提出的模型CNN-ATTBiLSTM不仅可以捕捉到句子中的n-gram信息,而且还可以捕捉到长距离的依赖关系,充分发挥了CNN和RNN的优势,所以在实验中获得了最好的效果。
5 结论
本文提出了一种融合CNN和ATTBiLSTM网络提取特征的情感分类模型,首先使用在大规模中文语料库上训练得到的词向量对文本句子进行编码,然后通过CNN和ATTBiLSTM网络进行特征提取,将两种网络提取的特征采取相加融合的方法得到分类的特征。实验证明,这种混合特征比单一的两种模型提取的特征效果好,本文所提出的情感分类方法较这些基线模型有所提升。虽然ATTBiLSTM可以提取一定的结构语义信息,但是在情感分类任务中ATTBiLSTM提取的结构语义信息还是不够的。传统的情感分析方法都是基于情感词典和词法、句法特征的,本文提出的模型没有使用任何的情感词典和词法、句法结构特征,下一步工作我们将探讨如何使用深度学习模型获取更多的结构语义信息,同时如何结合传统的方法,考虑更深层次的有用特征进一步提高文本情感分析的效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中国社会历史评论(2016年2期)2016-06-27
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
