
基于TF-IDF算法的唐代著名诗僧残缺诗句的填充方法研究
2019-04-22 12:03邓金史国阳蔡天鸿朱晋怀丽波
现代计算机 2019年8期
邓金,史国阳,蔡天鸿,朱晋,怀丽波
(延边大学计算机科学与技术学科智能信息处理研究室,延吉133002)
0 引言
中国诗词在传统文化中占据着重要地位。在文学史领域中,研究者通过研究不同时期的诗词,结合历史背景,可以深入了解不同时期的政治、经济、文化等。唐朝作为中国历史上版图最大的大统一中原王朝,涌现的著名诗词数不胜数。中晚唐后兴盛的诗僧,将自己的所闻所见所想写入僧诗中,促进了儒、佛二者的合流[1]。然而,由于历史遗留中一些不可抗因素,如文物的破损等,很多流传下来的僧诗成为残缺诗,这些残缺不全的诗句影响了世人对唐朝时期三教发展的研究。本文针对唐代遗留下来的著名诗僧的诗句残缺问题,提出一种基于文本处理技术的填充方法,期望得到一个合理且具有一定参考价值的结果。
1 相关工作
1.1 唐代僧诗的研究现状
唐代僧诗主要盛行于中晚唐时期,随着中国佛教在盛唐时期的发展而盛行,唐代兴盛的诗僧,是唐朝兴盛时期的见证人,他们对整个唐朝诗歌文化的发展具有很大促进作用。自上世纪80年代起,唐代诗僧研究逐渐引起人们的关注。整体来看,唐代诗僧研究在文学史领域主要还是宏观、背景式的[2]。大多数研究者或关注中唐僧诗的发展脉络,或着眼晚唐代僧诗的创作特征,或以某位诗僧为特定的研究对象[3],很少有人研究唐代僧诗残缺诗句的填充方法。
1.2 残缺诗句填充方法研究现状
目前国内外对于残缺诗句的填充方法主要是采用人工填充的方式,它需要填充者在熟悉作者诗词风格的基础上,对残缺进行补全。这种填充方式对填充者的文学功底要求非常高,且诗词填充效果也是因人而异。目前,还没有研究者采用计算机技术自动对残缺诗句进行填充,但对于诗词的其他方面如计算机自动生成诗歌、诗词的分类等已经有学者进行研究,如国外的Lutz在1959年用计算机生成了第一首德文诗,国内的诗词生成研究始于上世纪九十年代中期,如台湾罗凤珠的格律检查和同韵词查找系统,周昌乐等人利用遗传算法进行宋词的自动生成等[4]。20世纪80年代,陆续有一些民间人士在诗歌生成方面做了一些有益的探索和实践,产生了一些诗歌生成软件,如梁建章的“计算机诗词创作”程序、林鸿程的“稻香老农作诗机”,等等。这些民间自发的业余爱好,带动了汉语计算诗学的学术研究[5]。自20世纪90年代后,我国国内的不少学术机构和学者陆续在诗歌语料库及知识库的建设、韵律分析、风格分析、情感分析和诗歌自动生成等领域开展了汉语计算诗学的广泛研究[6]。人工填充诗句是填词者通过认真拜读原作者诗词进行的再创造,融入了大量后来者的主观色彩,且没有一个量化的标准来衡量诗词所填内容的好坏。本文将自然语言处理技术应用于唐代诗僧残缺诗句的填充上,为填充诗词提供了一个量化标准,为文学工作者和爱好者研究唐代时期的诗僧文化提供了一定的帮助。
1.3 文本处理相关的研究现状
自然语言处理对象即文本的表示,如今普遍采用Salton等人提出的向量空间模型。在这个模型中不必考虑文本中语义单元的顺序,而是将文本简化为一个BoW(Bag-of-Word),并表示为特征权重的向量。向量空间模型主要以词作为特征,以词频矩阵为基础计算权重[7]。常用的特征提取方法有文档频率、信息增益、互信息、卡方检验、期望交叉熵、TF-IDF方法和特征降维[8]。现有的特征降维技术有PCA等。
文本分类是基于内容的文本信息挖掘的基本技术之一,目前常用的文本分类方法主要有朴素贝叶斯分类算法、决策树分类算法、神经网络分类算法、K-最近邻(KNN)分类算法、支持向量机(SVM)分类算法,等等[9]。其中SVM算法分类器训练时间长,而决策树算法的效率也会因为数据量的增大而降低。KNN算法在准确率和稳定性方面均有优势,它不需要预先训练模型,同时具有很好的鲁棒性。
2 基本理论
2.1 文本处理相关技术
在VSM模型中,单词权重计算最为有效地实现方法是TF-IDF,它是Salton在1988年提出的。它的计算式如下:

其中,W(ti,dj)是特征项ti在文本dj的权重取值;tf(ti,dj)是特征项ti在文本dj中出现的频率,用于计算该词描述文档内容的能力;idf(ti,d)是特征项ti在文本集d中出现文本频率数的反比,称为反文档频率,用于计算该词区分文档的能力[10]。
KNN分类算法能够确定待分类样本与训练样本之间的相似程度,从而确定与待分类样本距离最近的K个训练样本。其最关键的因素是相似性度量方法,最常采用的相似性度量方法是余弦相似度,见公式(2):

其中,X、Y代表两个文档表示向量。对于一个待分类文本x,根据相似性度量函数从整个训练集中找到与文本x最相似的K(K是预先设定的一个整数)个文本,然后根据K个近邻文本所属的类别给x的候选类别评分[11]。本文采用1NN的方法进行比较。
2.2 基于TF-IDF的唐代著名诗僧残缺诗句的填充方法
本文收集唐代著名诗僧齐己、贯休、皎然收录于《全唐诗》的现存所有诗句,通过中文分词、建立TFIDF空间向量等步骤,对诗僧的残缺诗句进行了算法填充。先将诗人的所有诗句进行分词后,进行特征提取获得特征向量,这个特征向量就代表着诗人的诗风。诗风可量化的部分就是不同诗人对不同词语的偏好程度。同派别尤其是同时期的诗人之间会互相影响,所以部分诗词内容所含有词语是通用的。
要想在浩瀚汉字海洋里挑选出符合残缺诗句的合适词语就犹如大海捞针一般,本文选取三位诗人的诗作为词典,他们同为一个时代的诗人,有当代的共同点,因此残缺部分会以更大概率出现在这些通用的词语中间。这是本文进行唐代诗僧诗词填充的基础。
皎然、齐几、贯休是唐代诗僧的杰出代表,他们的诗风互相影响,尤其是齐己和贯休,基本处于同时代。基于上述分析将他们可能用到的词整理成词典(具体做法是将他们完整诗句进行中文分词),然后在词典里挑选更合理有效的词进行填充。利用词典和各自完整诗句集构建出三位诗僧的特征向量,这是为了量化他们的诗风,便于后期在填充结果集选择最优结果。本文采用余弦相似度作为填充好坏的度量,较人工填充更加规则规范化。
本文的填充算法步骤如下:
输入三位著名诗僧的完整诗句和残缺诗句
Begin
Step 1:对所有完整诗句,使用NLPIR汉语分词系统进行分词,获得总词典;
Step 2:构建向量空间模型,利用公式(1)分别构建三位诗僧的特征向量;
Step 3:对三位诗僧的残缺诗句进行分词;
Step4:在词典中从头到尾遍历,查找与空缺词字数相同的词,进行填充,并将填充后的诗句构建特征向量;
Step5:将Step4的特征向量与三位诗僧的特征向量利用公式(2),进行余弦相似度的计算;
Step6:利用KNN方法,总是选取相似度最高的前k(本文测试取k=1)个诗句填充的词作为结果进行输出;
输出僧残缺诗句的填充结果。
End
3 实验结果与分析
本文采集了唐代诗僧齐己、贯休、皎然收录于《全唐诗》的所有诗,并将上述采集内容分为完整诗句和残缺诗句两部分,并对空缺诗句进行填充。
3.1 验证诗僧之间诗风的独立性
为了验证三位诗僧之间的独立性,利用三位诗僧的完整诗句构建各自在向量空间下的特征向量(采用中科院分词系统进行中文分词),两两进行特征向量间的余弦相似度计算,得结果表1。
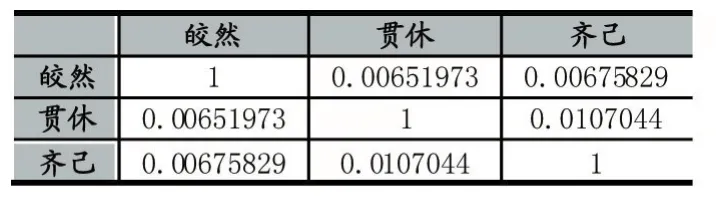
表1 三位诗僧两两之间的余弦相似度值比较结果
在向量空间比较特征向量之间的余弦相似度,如果越趋近于1则说明两个特征向量之间越相似,相反,越趋近于0则说明两个特征向量越独立。通过表1看出,三位诗僧的特征向量两两之间是趋近于0的,这说明他们之间是独立的。本文通过TF-IDF向量空间模型下产生的结果,这与后人将他们奉为诗僧界作诗的三大杰出代表不谋而合。此外,皎然的时代早于齐己、贯休,所以对后两者的相互影响较弱,而齐己、贯休基本处于同时期,所以相互影响理论上应较强,这均与表1的数据相吻合。
3.2 基于TF-IDF的残缺诗句填充方法
实验一:仅使用每位诗人自己的诗词构建词典进行填充
为验证本文实验方法的可行性和合理性,进行了两组对比试验。
方法一:利用某位诗人的所有完整诗句进行分词得到这位诗人的词典,将该诗人的每一首诗作为一个文档,计算出词典中的每一个词的idf值和tf值后,构建诗人的特征向量。
方法二:利用某位诗人的所有完整诗句进行分词得到这位诗人的词典,将该诗人的所有诗作为一个文档,计算出词典中的每一个词的tf值,构建诗人的特征向量时,由于idf值为1,所以诗人的特征向量中每一个特征值都只由该词的tf值确定。
利用三位诗人的六个残缺诗句进行实验:
(1)皎然:别离芳月积,岐路浮云偏。正□入空门,仙君依苦县。
(2)皎然:江上重云起,何曾裛□尘。不能成落帽,翻欲更摧巾。
(3)贯休:嘉树白雀来,祥烟甘露坠。中川一带香,□开幽邃地。
(4)贯休:望尘□□连紫闼。吾皇必用整乾坤,莫忘江头白头达。
(5)齐己:巴江□□涨,楚野入吴深。他日传消息,东西不易寻。
(6)齐己:夏□松边坐,秋光水畔行。更无时忌讳,容易得题成。
诗句填充结果见表2。

表2 两种方法的诗句填充结果
对实验结果进行分析,发现方法一与方法二填充结果效果不好,分析其原因可知,方法一由于文档数量庞大idf变化大而词频均较小,实验填充的词主要受idf的影响。方法二与方法一相反,方法二idf值一致,填充的词只受tf值的影响。所以本文最终采用的方法是使用三位诗人的所有完整诗构建词典,然后进行实验。
实验二:使用三位诗人的所有完整诗构建词典进行填充
“巴江□□涨,楚野入吴深。他日传消息,东西不易寻”是齐己《与张先辈话别》一诗中的残缺部分。构建该句的TF-IDF特征向量,并计算当前该句和三位诗僧特征向量之间的余弦相似度得表3。

表3 《与张先辈话别》残缺部分的比较结果
由于一句诗所包含的词语特征太少,在计算余弦相似度时,大多数词的特征值值为0,所以总体的余弦相似度值均偏低。但仍可以看出,该句与齐己的余弦相似度值最高,而事实上这就是诗僧齐己的诗句。
对该句进行填词,分别获得与三位诗僧特征向量余弦相似度最大的词,如表4所示。

表4 填词结果
本文算法填词是没有考虑到诗句押韵和词词耦合以及诗意衔接,但是通过本文算法填词后不难发现:
巴江(起见)涨,楚野入吴深。他日传消息,东西不易寻。
首先,填完词的诗句是没有影响押韵,其次词语之间也有所关联,其次“起”和“入”字对仗,整体构成的诗意给人一种反差美,这也能和下句达到匹配,有进一步研究的意义。
“别离芳月积,岐路浮云偏。正□入空门,仙君依苦县。”是皎然《兵后早春登故鄣南楼望昆山寺白鹤观示清道人并沈道士》一诗中的残缺部分。构建该句的TF-IDF特征向量,并比较该句和三位诗僧的特征向量之间的余弦相似度值得表5。

表5 《兵后早春登故鄣南楼望昆山寺白鹤观示清道人并沈道士》残缺部分的比较结果
仍可以看出,该句与皎然的余弦相似度值最高,而事实上这就是诗僧皎然的诗句。
对该句进行填词,分别获得与三位诗僧特征向量余弦相似度最近的词,如表6所示。

表6 填词结果
填完词的诗句为:
别离芳月积,岐路浮云偏。正(凄)入空门,仙君依苦县。
如果上句是创造出一个意境来,那么下句就是这个意境里的具体内容。苦字奠定了整句的感情基调,整个意境给人一种凄凉的感觉,所以填写出的凄字也是具有相当大的参考价值。
“嘉树白雀来,祥烟甘露坠。中川一带香,□开幽邃地。”是贯休《上卢使君》一诗中的残缺部分。构建该句的TF-IDF特征向量,并计算该句和三位诗僧的特征向量之间的余弦相似度值得表7。

表7 《上卢使君》残缺部分的比较结果
依旧可以看出,该句与贯休的余弦相似度值最高。
对该句进行填词,分别获得与三位诗僧特征向量余弦相似度最近的词,如表8所示。

表8 填词结果
填完词的诗句为:
嘉树白雀来,祥烟甘露坠。中川一带香,(遄)开幽邃地。
遄字有快、迅速之意。祥烟给人一种冉冉升起的感觉,而甘露坠就是一种迅速之感。上句作为铺垫虽没有明说,但下句的“遄开”一语道破,使前后句具有强关联性,参考价值不菲。
本文用的是三个著名诗人的完整词构建的词库,因此词数有限,可以增大词库,然后进行降维处理,也可以增大k值以便尽可能获得更多参考结果,这相对于研究者在浩瀚的文字中寻找一个词容易很多,因此可以为研究者提供借鉴。
4 结语
本文将TF-IDF技术应用于残缺诗词的研究,初步构建了一个简单的填词系统,获得了可供参考的填充词。但本文的方法在进行填词的时候并没有考虑到诗的意境、押韵等方面的问题,构建的词典也只是基于三位诗人的完整诗,具有较大的局限性,所以接下来的工作是改进本算法,考虑押韵、词性以及多缺失词的诗意限制等因素。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
英语文摘(2019年5期)2019-07-13
数学学习与研究(2018年15期)2018-11-12
计算机辅助工程(2018年2期)2018-06-03
中学数学杂志(高中版)(2016年6期)2017-03-01
福建中学数学(2016年7期)2016-12-03
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
