
基于微博的人格分类模型
2019-04-22 12:03冯豆豆
现代计算机 2019年8期
冯豆豆
(四川大学计算机学院,成都 610065)
0 引言
随着网络及移动设备的普及,新浪微博逐渐融入人们的生活,越来越多的用户利用微博来记录生活,表达个人观点和抒发内心情感。这些微博数据记录了用户真实、长期的心理活动,是研究用户人格的很好的数据。
人格作为心理学的一大分支,其研究重点是个体间的差异性。人格计算则是通过分析用户的行为结果,预测用户的人格,以量化个体间的差异性。利用这些量化了的差异性,可以判断出不同用户的不同需求,以提供更好的个性化服务,例如为高尽责性用户推荐实用性较强的产品,为高开放性用户推荐新奇产品等。人格计算拥有广泛的应用空间,利用用户的人格数据,可以为员工选聘提供指导意见,可以预测用户是否具有攻击行为,判断用户是否抑郁等。
全特质理论是William[1]等人提出的,全特质理论认为人格具有周期性,不同人格特质的人周期变化不同。
1 相关工作
微博是我国青年最常用的社交工具之一,在微博上人们可以无约束地表达自己的感受和心情。这些数据记录了用户真实、长期的心理活动,为建立人格分类模型提供了理想的数据基础。
人格分类是通过分析用户的行为结果,预测用户的人格属于哪种类型,以量化个体间的差异性2。据笔者所知,人格分类的第一个研究是Sholomo等人[3]在2005年发表的,他们收集了1200名学生的2263篇散文,研究中使用功能词(Function Words)1功能词:Function words,不具有实际意义,但发挥语法作用的词,如英语中的冠词the。和系统功能语法(Systemic Functional Grammar)2系统功能语法:是韩立德等人提出的一种理论,认为语言是一个系统网络,其中包含了多个子系统,语言使用者可以从中做出选择。中的词类作为特征,分别为外向性和情绪稳定性特质建立分类模型。2006年,Oberlander等人[4]认为博客可以记录用户在不受限制的条件下所想的内容,能够更好地体现用户人格,于是收集整理了71名用户在一个月内写下的博客,以n元组在博客中出现的次数作为特征值,使用支持向量机和朴素贝叶斯建立分类模型,模型的准确率可达到85%。为检验模型的泛化能力,Nowson等人[5]建立了一个更大的语料库,语料库中包含了1672名用户的博客,并将模型应用到新语料库上,模型的准确率从85%下降到了60%左右,可见模型的泛化能力弱。
Golbeck等人[6]是最早开始用社交网络数据进行人格计算的,他们开发了一个Facebook应用,可以让用户在线填写人格测试问卷,并且在用户填写问卷时收集用户在Facebook上的数据,去掉不合格样本后,剩余167个被试。用到的特征包括:文本特征、个人信息、网络结构特征以及活动偏好特征,一共77个,最终的平均绝对误差在0.11左右,证明使用社交网络数据预测人格是可行的。
此后,利用社交网络进行人格计算的研究层出不穷,为便于各研究成果之间进行比较,Stillwell等人[7]建立了myPersonality语料库,语料库来自Facebook平台,收集了用户的文本数据以及网络结构数据,使用IPIP NEO-PI-R 大五人格量表(Goldberg L R,2006)[8]获取用户人格分数。
基于 myPersonality语料库,Markovikj等人[9]用SMO和AdaBoost算法建立分类模型,准确率高达0.86~0.95。模型用到的特征可分为五个子集:网络属性、LIWC、词性统计、Afinn和H4Lvd,结果表明文本特征对于提高模型准确率很有帮助。
Farnadi等人[10],分别在 Facebook、Twitter和 You-Tube三个社交平台上建立人格计算模型,并且尝试用另一个社交平台上的数据扩充当前语料库(如,使用Facebook上的数据扩充Twitter语料库),结果发现扩充后的语料库更难以预测。因为,不同社交平台上的用户分布不同,简单的扩充只会增加数据噪声。所以,本文将关注的重点只放在新浪微博一个平台上。
除了英文语外,其他国家的研究者们也针对自己的母语进行了研究。目前,最进的成果是Suhartono等人[11]的研究。Suhartono等人通过印度尼西亚版的Twitter平台,收集了359名用户的数据,分别用SVM和XGBoost建立分类模型,SVM的准确率为76.2%,而XGBoost的准确率达到了97.9%,甚至对于情绪稳定性和外向性达到了100%。
国内方面,基于中文社交媒体的人格计算一般从微博、人人网收集数据。
Bai等人[12]从335名人人网用户的数据中提取出五个子特征集,包括基本信息、网络属性、时间属性,情感类型四个方面,使用C4.5建立二分类模型。分类依据是所有用户得分的平均值和标准差,低于平均值一个标准差的为低分组,高于平均值一个标准差的为高分组,剩余为中间组,中间组忽略不计。但正如Mairesse[13]所说,这样做虽然可以提高准确率,但却降低了召回率。考虑到召回率,且为避免数据不均衡,本研究中的分类依据以中位数为分界线。等于高于中位数者为高特质,低于中位数者为低特质者。
2 人格分类模型
在人格心理学中有多种人格因素模型,目前最流行的是大五人格模型(Big Five Model)也叫做五因素模型(Five Factor Inventory)。大五人格模型基于特质流派,研究取向可分为两个:词汇研究和问卷研究。词汇研究基于词汇假设,认为通过分析自然语言中的词汇及语义,可以探究人格的维度。问卷研究的理论基础是特质论,特质论认为人格是可预测的,通过观察个人长期行为,便可总结得出人格特质。常用的人格问卷是Paul Costa和Robert McCrae共同编制的《NEO人格问卷》(NEO Personality Inventory,简称 NEO-PI,修订版称为NEO-PI-R)。大五人格模型共包含五个特质因素,表1介绍了大五人格模型的各个特质因素。
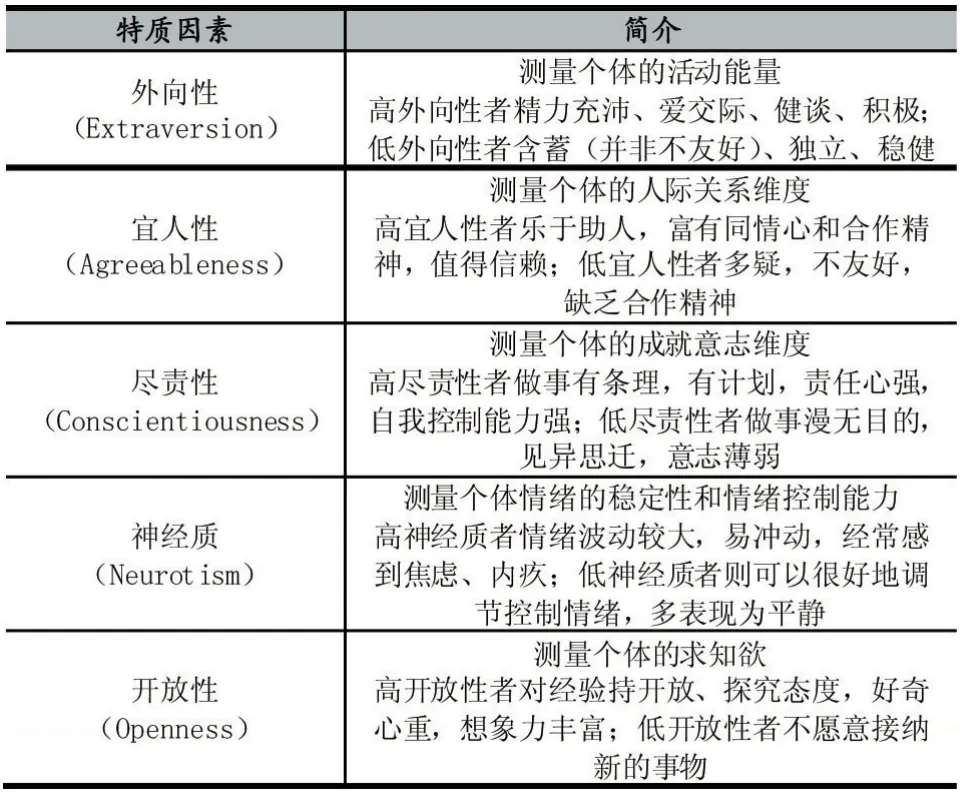
表1 大五人格模型
2.1 数据采集
为了收集数据,建立了人格测试网站3网址:http://www.panvote.top/。用户打开网站后首先需要使用微博账号登录,然后做44题中文版的人格问卷。具体的操作流程如图1所示。
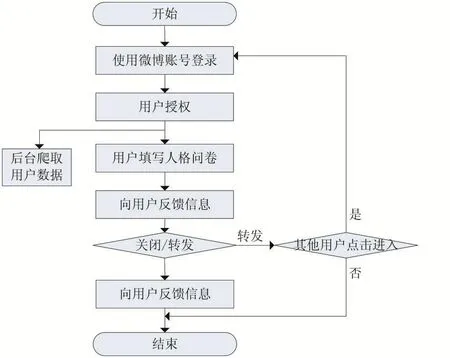
图1 网站操作流程图
用户填写完量表后,向用户反馈其人格数据。用户看到结果后,可以选择分享到微博或关闭。其他用户若点击了该用户分享的内容,也可参与调查。数据收集过程从2017年12月5日到2018年5月23日,共收集了324名用户的微博数据。为保证收集到的数据是有用户自己写的,过滤掉了非原创数据。
2.2 数据筛选
为去除噪声、无效数据,对数据进行筛选,筛选规则如下:
(1)将注册时间低于一个月的用户数据去除,因为这样的用户可能还不熟悉微博的使用方式;
(2)将用户中转发的内容去掉,非原创的内容并不能体现出用户的人格;
(3)将微博数量小于10条的去掉,因为这样的用户数据量太少;
(4)去掉平均每天发微博的数量超过50条的,因为这样的账号可能是营销账号,通常由某个工作室维护,并不是单个用户使用。
筛选过后,只有236名用户数据有效。
2.3 模型特征
本研究中用到的特征包括四个部分:
(1)个人信息:
个人信息是指每个用户所公开的个人数据,包括昵称、性别和年龄。
(2)网络特征:
网络特征是指用户在使用微博网络属性,主要包括:粉丝数、关注数、微博数、分享数、评论数。不同的用户在使用社交网络时,会产生不同的行为,这些行为长期累积使得用户的网络属性各不相同。所以,网络属性可以帮助我们分析用户的人格。
(3)文本特征:
Pennebaker等人[14]认为个体所写下的文本内容反映了个体的人格。所以,用户的文本数据是人格计算的重要线索。
对于用户文本分析来说,传统的做法是基于SCLIWC等词典提取文本特征,但是这种方法并不适合微博数据。因为微博数据具有很强的时新性,网络用语更新换代快,新生词层出不穷。而传统做法所依赖的词典并没有囊括这些新生词,会丢失许多信息。因此本研究中的文本特征通过TF-IDF选出特征词,然后使用特征词的频率作为文本特征。
(4)情感特征:
基于中国知网的情感词词典分析每条微博的情感。如果微博中包含的积极情感词数量大于消极情感词数量,则该条微博属于积极情感,反之亦然。以一个月为单位,统计每个月中积极情感的微博条数numpos,和消极情感的微博条数numneg,统计用户最近一年内,每个月的numpos和numneg,分别求出积极情感的平均值avgpos和标准差stdpos,和消极情感的平均值avgneg和标准差stdneg。
2.4 分类模型
人格分类领域常用的分类算法有朴素贝叶斯NB[4,15-16,18]、支持向量机 SVM[4,10,17,20]和 C4.5算法[12]。为方便对比本文使用了朴素贝叶斯、支持向量机和C4.5,表2介绍了这四种分类算法的原理并列举了各自的优缺点。

表2 NB、SVM、KNN及C4.5原理简介及优缺点列举
2.5 实验结果
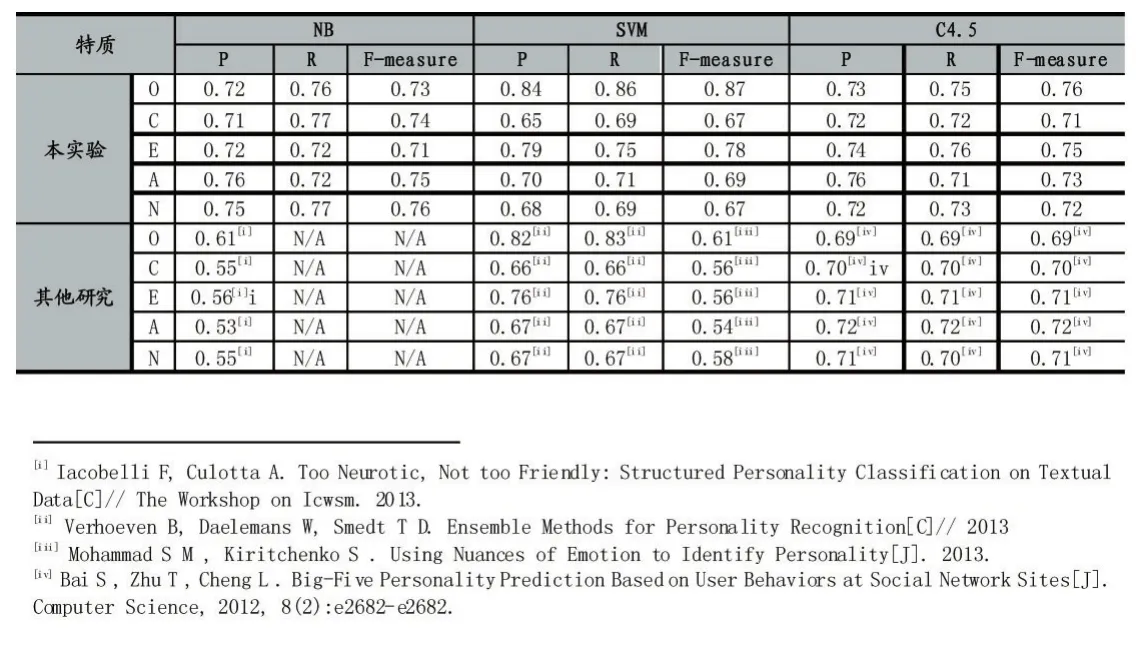
表3 本研究实验结果和其他研究结果的对比
从表3中可以看出本研究结果优于其他研究。
3 结语
随着社会的发展,人们对智能化的要求越来越高,因此,让机器了解人类的心理活动,并作出适合的响应越来越重要。这就需要将心理学和计算机科学联系起来,人格计算正是这样的一个领域。人格计算自提出至今已有十多年的历史,但仍存在很多问题,本文提出以下两个改进方面。
(1)人格特质间的弱连接
文献[18]提出人格特质间存在弱连接,文献[19]中用皮尔逊相关计算人格特质间的相关性,发现各特质之间存在相关性(相关系数为-0.406~0.318),尤其是开放性和外向性这两个维度,呈显著相关(0.318)。文献[20]中用J-S散度来计算人格特质间的弱相关性,并且使用肯德尔相关加以验证,最后还比较了人格间弱相关对人格计算系统的影响,并得出结论:当不考虑人格特质间的弱相关性时,系统F1值相较于峰值下降很多。在未来的工作中需要将人格特质间的弱相关加入到人格计算系统中。
(2)利用大数据分析情境
人格计算根据用户的行为结果(本文指文章内容)来预测用户人格,但同一个用户在不同的情境下产生的行为结果是不同的。例如,某用户具有高外向性特质,在与朋友聚会后写下的随笔记录可以反映出他的外向性特质,但是在失眠后写下的随笔记录可能会表现出低外向性。文献[21]提出需要在人格计算中考虑到情境因素,文献[22]针对文献[25]中的情境问题提出:通过大数据分析可以获得情境对用户行为的影响。朱廷劭等人[23]利用中文心理分析系统分析微博用户的情绪内容,得出了情绪在一天内随时间的变化规律。该变化规律在一定程度上反映出了情境对用户行为的影响,基于此我们可以去除人格计算中的部分噪点信息。例如,文献[27]中的规律指出,用户在凌晨3点左右处于消极情绪,一个低神经质的用户在凌晨3点可能受到失眠的困扰,而表现出高神经质的特质,这就属于人格计算中的一个噪点信息。未来的人格计算工作中,可以考虑用大数据分析情景对用户行为的影响,从而降低人格计算中的噪点。
猜你喜欢
社会科学战线(2022年8期)2022-10-25
汽车实用技术(2022年14期)2022-07-30
现代企业(2022年5期)2022-05-31
心理学报(2022年2期)2022-02-15
外语学刊(2021年1期)2021-11-04
国画家(2021年4期)2021-10-13
天津外国语大学学报(2020年1期)2020-03-25
意林·全彩Color(2019年7期)2019-08-13
福建基础教育研究(2019年12期)2019-05-28
外语教学理论与实践(2014年4期)2014-06-13
