
面向数据体系结构的数据性能与价值研究
2019-04-10 06:09熊一君
成都大学学报(自然科学版) 2019年1期
熊一君,苗 放
(1.成都大学 商学院,四川 成都 610106; 2.成都大学 大数据研究院,四川 成都 610106)
0 引 言
研究表明,在大数据背景下进行系统架构设计之时,必须围绕着大数据的4个特点展开,即大量、高速、多样、价值[1].对于数据而言,不再是简单的增、删、查、改等操作,而关键是数据管理、数据分析及数据挖掘.事实上,传统的系统架构是以完成功能需求为最终目标,并采用面向对象的模式进行编码,这样的优点在于在单一数据存储模式下系统流程与业务方式对等.而大数据背景下,针对数据存储的一个基本要求是设立数据分片副本,系统架构设计的核心思路已由功能需求转变到数据价值需求.因此,若按照传统软件工程模式,系统架构设计将面临2个问题:首先,数据存在着多个分片副本,根据数据一致性要求,每个分片数据副本必须相同,当分片副本较大时,则必须对多个分片副本依次操作,而大数据环境下,数据的容量都以拍字节(PiB)为单位,因此分片副本巨大,这无论是对物理机的性能还是数据库性能都是极大的考验;其次,传统系统架构是面向业务的,以设计出符合业务逻辑的功能,核心在于“是否好用,功能合理",数据库设计依托功能需求展开,当功能改变,数据必然面临重构,这将造成资源浪费.
可见,在大数据时代背景下,数据为核心,一切其他方法只是为挖掘数据价值而服务,数据本身不再依托功能,而是功能服务数据[2-3].基于此,本研究提出了一种面向数据体系结构(Data-oriented architecture,DOA)的数据性能与价值的评价模式.该模式以一种全新的数据架构模式(即DOA)为基础,采用“两中心模式"来解决数据的性能与价值评价的问题.
1 数据分片中心
1.1 体系架构
在面向数据体系架构中,数据存储方式是将一份数据进行数据分片分别存储到不同的物理机内来进行数据交换,并降低系统延时.但是,当面对海量数据集时,如何保证数据一致性与延时性之间的均衡分配,是目前挖掘数据性能与价值所面对的首要问题.对此,本研究提出了利用数据分片中心[4]来解决一致性与延时性之间的矛盾.
数据分片中心采用主从式分片模式,即设立一个主分片,其他分片为从分片.该模式的特点是,由于数据流是由主分片发出,从分片响应的数据流也返回给主分片,客户端操作只针对主分片进行,主分片与从分片之间没有其他的操作指令干扰,因此只要主分片数据流完成发送,那么所有主从分片的一致性得到绝对保证.
通常,当数据分片过大,请求延时取决于最慢的从分片更新速度[5].为了确保整个系统的强一致性,在该模式中通过设置缓存分片来实现降低数据的延时性,具体如图1所示.主分片与从分片之间不再直接进行数据交换,而是通过两者之间的缓存完成数据交换.主缓存数与主分片数相等,从缓存数与从分片数相等.
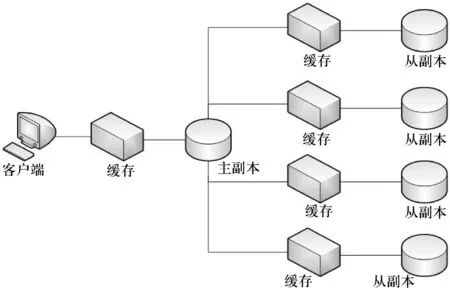
图1主从分片模式架构图
1.2 分片缓存内部机制
数据分片中心引入分片缓存的最主要的目的是减少客户端与各个副本之间的数据交换量.分片缓存主要的功能是缓存一部分需要频繁在客户端与副本之间交换的数据流,如用户信息与登录信息等.通常情况下,副本需要的数据只需从对应的缓存中直接读取,其优点是减轻了由于数据频繁交换而造成对服务器的高负载情况[6].
在分片缓存下,每个缓存内部有个数据记录表,记录表指向缓存中已经被缓存的数据.当有新数据被缓存后,则在记录表中自动建立一个关联字段,指向这个新缓存记录值.同样地,如果需要与副本进行数据交换,只需查找对应的记录表,如果记录表中有该条数据关联字段,则进行数据交换,否则返回说明该记录不存在的信息.
1.3 数据序列化
针对数据传输模式,本研究采用数据序列化与反序列化模式来降低数据传输过程的延迟.
序列化与反序列化功能使用XML作为数据通信的格式.由于客户端与副本之间反复传输各类信息,为了提供传输效率,将数据采用二进制格式,因为其容量更小,所以数据格式转换为高效简洁的模式,特点是速度快且占用很少的额外存储空间.序列化与反序列化模式拥有极高的消息传输能力和较高的稳定性,数据传递延迟低,也能对数据进行较长时间的保存.
2 数据价值评价中心
2.1 数据价值评价原则
大数据背景下,大量的数据需要被处理与分析,数据不仅量大,同时类型广泛.除此之外,数据价值的评价还必须面对以下特性:数据量成几何级增长,高效处理海量增长的数据,是进行数据价值评价的前提;数据很多,价值为零,大部分数据的价值非常低,数据产生到呈现过程中影响数据价值的因素非常多.因此,针对数据价值评价的方法必须能有效地解决以上问题.
数据量的问题,可由数据分片中心解决,而如何有效地筛选影响数据价值的因素来正确评估数据价值,则需要建立相应的评价模型.
2.2 数据价值评价模型
2.2.1 层次分析法(Analytic hierarchy process,AHP).
由于影响数据价值评价的因素有很多,评价模型的核心思想是筛选对数据价值影响最大的因素,并采用权重值的方式进行表示.同时,该模型还应该满足以下条件:模型的结果适用于各种数据价值评价情况;模型产生的结果是否准确反映影响数据价值的因素;本模型产生的结果是否容易理解.
因此,基于以上模型的要求,并考虑多因素这一核心特点,本研究采用AHP建立数据价值评价模型,通过该模型来计算影响数据价值因素的对比矩阵及矩阵的特征向量与指标权重,并利用一致性指标、随机一致性指标和一致性比率进行一致性检验.当检验通过,特征向量即为权向量.
2.2.2 AHP步骤.
1)目标需求分析.确定最终目标实现的策略与限制因素,综合收集各类型信息.
2)构建多级层次结构.根据最终目标的差异,对系统进行多层次分级.
3)采取专家模式判断方式,确定多级层次结构内各元素之间的比较尺度,构造对比矩阵及矩阵运算的数学方法,确定本层次中元素集针对父级层次内某个元素的权向量.
4)计算所有层次元素的合成权向量,并对其进行排序,排序后的结果即为各个元素的重要程度.
2.2.3 AHP关键指标.
在AHP中,比较2个可能具有不同性质的因素Ai和Bj之间的相关程度时,要确定1个合适比较尺度aij.对此,本研究采用1-9尺度法,即aij∈[1,9]∪[1/9,1],具体如表1所示.

表1 1-9尺度aij的含义
随机一致性指标RI用于衡量对比矩阵的一致性指标CI标准.当n=1,2时,RI=0,1与2阶的对比矩阵总是一致阵.对于n≥3的对比较阵A,将其一致性指标CI与同阶的随机一致性指标RI之比称为一致性比率CR.当CR=CI/RI<0.1时,则认为A的不一致程度在容许范围之内,可用其特征向量作为权向量.
2.3 数据价值评价计算过程
2.3.1 构造对比矩阵.
层次分析模型中最重要的步骤是构造一个合适的对比矩阵.构造合适的对比矩阵的难点在于要从aij∈[1,9]∪[1/9,1]的值域内选择相对尺度值,同时要尽量保证矩阵判断的一致性.事实上,对比矩阵的建立比层次分析模型难度更大,尤其当采用层次分析模型解决多对象、多层次等复杂环境时[7].对此,本研究利用了成都大学专家平台公共资源,在学校大数据研究院的平台支持下,邀请了大数据与计算机领域内多位专家参与层次结构的设计,同时由多位专家给出对比矩阵中各指标之间的相对尺度,相对尺度的取值范围采用1-9尺度标准.最后,组织专家进行集体论证,统一各层级评价指标和指标的相对尺度值,如表2所示.
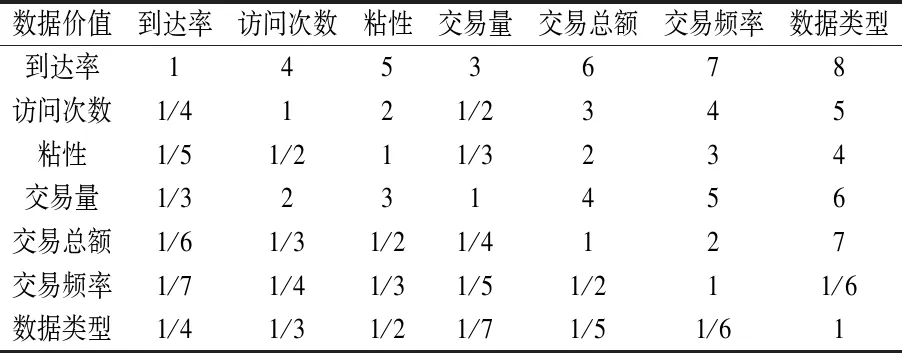
表2 对比矩阵评价尺度
2.3.2 关键计算过程.
对比矩阵A的最大特征根的特征向量作为权向量,即权向量w满足Aw=λw.本研究采用一致性指标、随机一致性指标与一致性比率作一致性检验,如果检验通过,特征向量即为权向量,反之则调整对比矩阵.
本研究中,权向量w、一致性指标CI与一致性比率CR的计算过程全部采用R语言实现,其核心代码如下:
//权向量计算
weight<-function(B)
{
A=matrix(B,nrow=sqrt(length(B)),ncol=sqrt(length(B)),byrow=TRUE)
n=ncol(A)
mul-collect=c(1:n)
for (i in 1:n) mul-collect[i]=prod(A[i,])
weight=mul-collect^(1/n)
weight-one=weight/sum(weight)
round(weight-one,4)
}
//一致性指标CI、一致性比率CR
CI-CR<-function(B)
{
RI=c(0,0,0.58,0.9,1.12,1.24,1.32,1.41,1.45,1.49,1.51)
Wi=weight(B)
n=length(Wi)
if(n>2) {
W=matrix(Wi,ncol=1)
A=matrix(B,nrow=sqrt(length(B)),
ncol=sqrt(length(B)),byrow=TRUE)
AW=A %*% W
aw=as.vector(AW)
la-max=sum(aw/Wi)/n
CI=(la-max-n)/(n-1)
CR=CI/RI[n]
cat(“ CI=",round(CI,4),“ ")
cat(“ CR=",round(CR,4),“ ")
cat(“ la-max=",round(la-max,4),“ ")
if(CR<=0.1) {
cat(“通过 ")
cat(“ Wi:",round(Wi,4),“ ")
}
else {
cat(“请调整判断矩阵! ")
Wi=NULL
break
}
}
else if (n<=2) {
return(Wi)
}
}
3 实验与性能仿真
本研究的实证分析选取四川省教育资源公共服务平台V2.0作为实验对象.该平台是以DOA思想为核心下实施的系统平台,V2.0系统平台最大的特点是应用了本研究提出的“两中心模式”,即数据分片中心与数据价值评价中心.
四川省教育资源公共服务平台主要功能是提供教学资源数据的共享,其共享的方式为部分免费共享而另一部份付费销售.目前,根据该平台的决策者需求,该平台需解决海量数据的存储与读取问题,能有效评估不同学科平台的数据价值且准确评判影响数据价值的影响因素.
3.1 平台数据性能测试数据
本研究的测试环境为:硬件环境为,Intel(R) Xeon(R) CPU E3-1230V3,内存16 GiB,操作系统为Ubuntu Server 15.本研究选取平台数据内18个大小不同的数据包,分别测试这18个数据包在操作过程中所耗时间.表3与表4是平台没有采用分片中心及采用分片中心后数据操作性能对比,相应的数据性能耗时如图2与图3所示.
通过以上图表信息的对比可以看出,分片中心的作用.
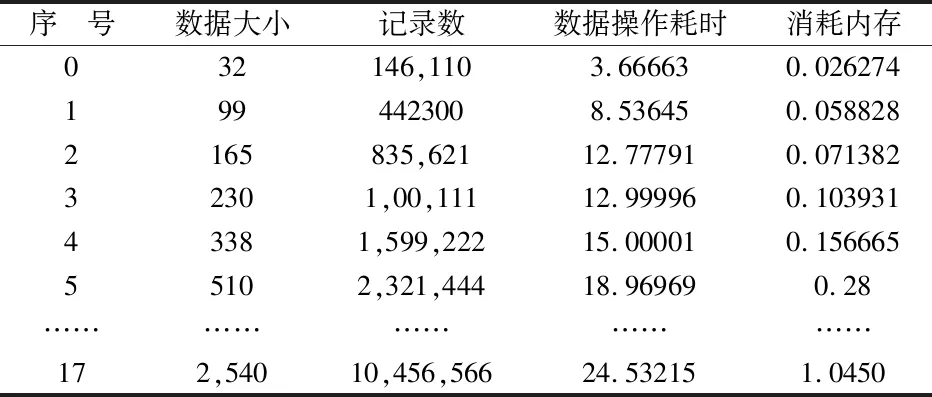
表3 无分片中心数据性能
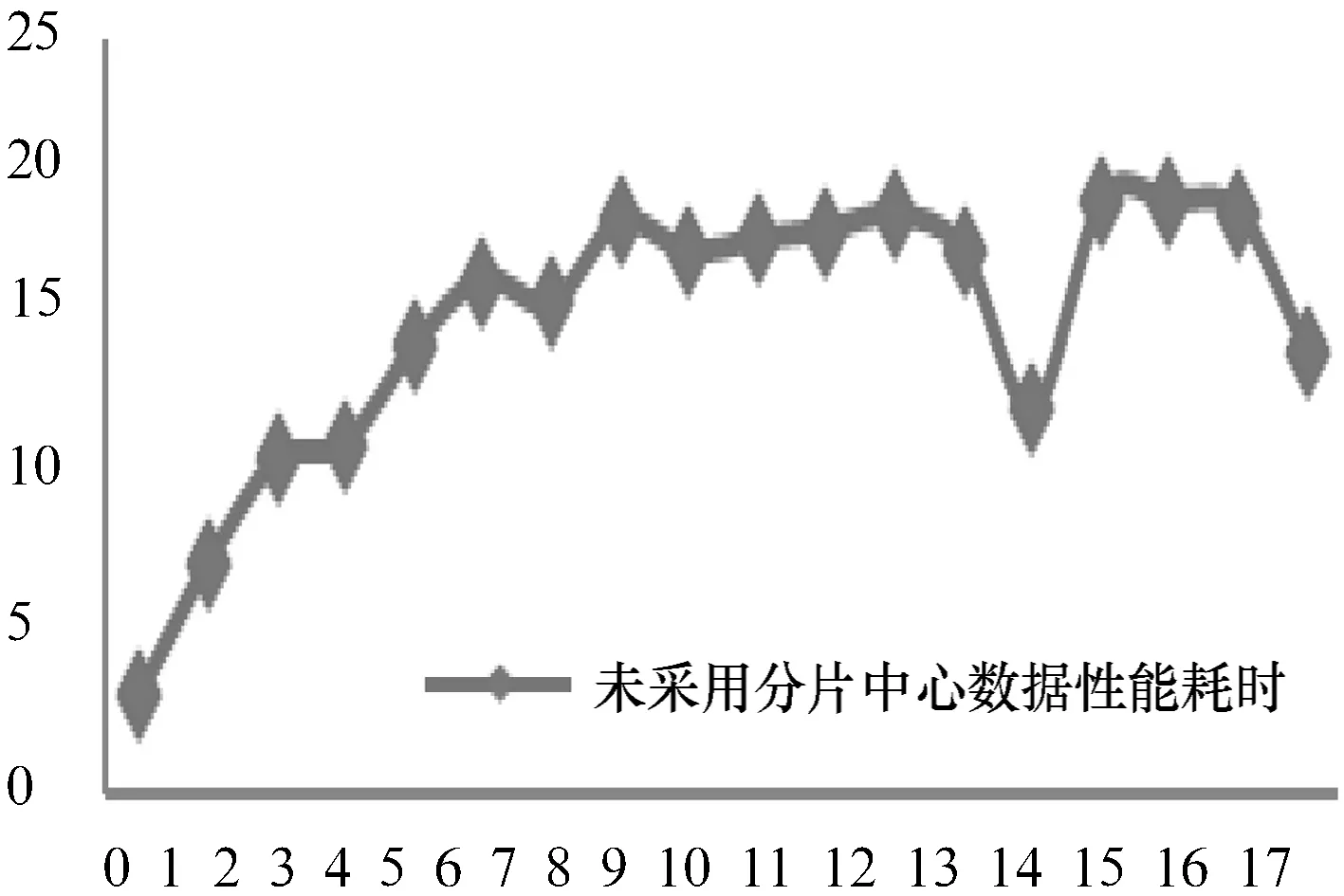

图2 无分片中心数据性能耗时
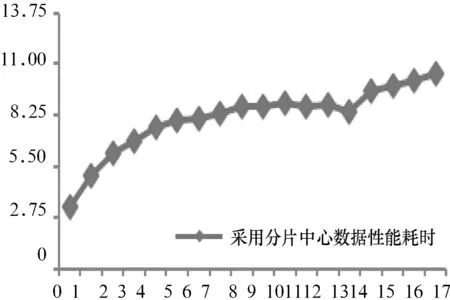
图3采用分片中心数据性能耗时
从以上图表可知,数据操作性能耗时与数据大小成单调递增.图2中第18个数据包耗时达到了14.628 61 s,而通过采用数据分片后,第18个数据包耗时减少到了10.492 688 s,此时消耗时间减少了33.3%.根据图3得出,数据包越大,消耗时间减少比例就越大.
四川省教育资源公共服务平台V2.0每日实际的数据包总流量达到了1 TiB,而在使用了数据分片中心后,数据操作过程的整体平均耗时下降了50%左右.
3.2 数据价值评价指标评测
3.2.1 评价指标.
数据价值指标权重的确定主要有4个步骤:通过专家咨询法构建评价指标影响因素的对比矩阵;采取专家群体判断的方式,采用1-9尺度方式确定对比矩阵内各因素的比较值aij;采用数学方法求出对比矩阵归一化的特征向量w,同时计算出一致性指标CI、一致性比率CR;判断一致性检验是否通过.
由前面的计算方法获得,本次评价指标对比矩阵的一致性指标CI=0.1165,一致性比率CR=0.0883(CR=CI/RI,RI可由表2查表得到),因为CR<0.1,因此w=(0.409 7,0.146 4,0.096 3,0.217 5,0.071 3,0.029 4,0.029 4),通过一致性检验.
由此,最终评价指标的权重排序后情况为:到达率>交易量>访问次数>粘性>交易总额>交易频率>数据类型,其中到达率的权重为0.409 7,几乎占所有权重比的0.5.到达率的大小很大程度上决定了数据价值,这与通常采用数据交易总额来衡量数据价值的传统方法不同,即决定数据价值的指标是到达率.
3.2.2 数据评测.
本研究选择四川省教育资源公共服务平台的资源中心版块数据进行测试.资源中心是提供访问者进行数据访问、购买及下载的接口.V1.0版本没有采用DOA进行系统架构,数据的盈利方式仍采用传统会员付费方式,即判断版块内容是否具有吸引力及数据是否具有价值,只能通过付费额度反映,而版块的到达率数据则被视为无关参数,因此最终的决策结果是自然科学版块与人文科学版块的价值基本相同,具体情况如图4所示.
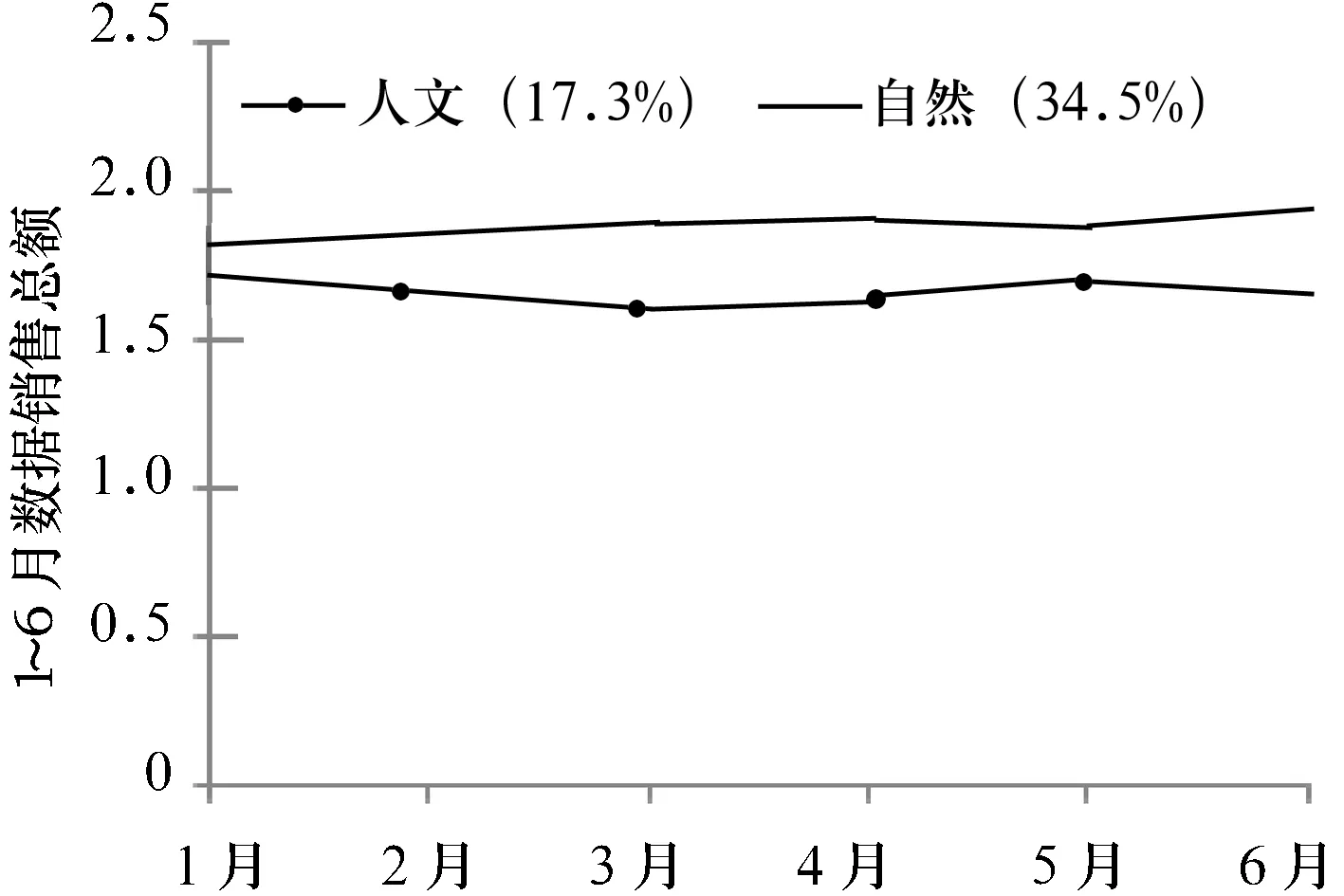
图4 V 1.0应用平台盈利数据
从图4可知,虽然自然科学版块的到达率比人文科学到达率高出1倍,但是实际的数据下载付费总额却相当接近.由此可见,2个版块数据内容的价值相同.
V2.0系统平台采用DOA进行重构,采用数据价值评价中心,确定到达率是数据价值影响因素中权重值最大的因素,因此为了将到达率的作用体现出来,以数据作为中心,本研究对V2.0平台的数据盈利方式从传统付费方式转变为数据获取免费而投入广告实行盈利的方式,具体情行如图5所示.
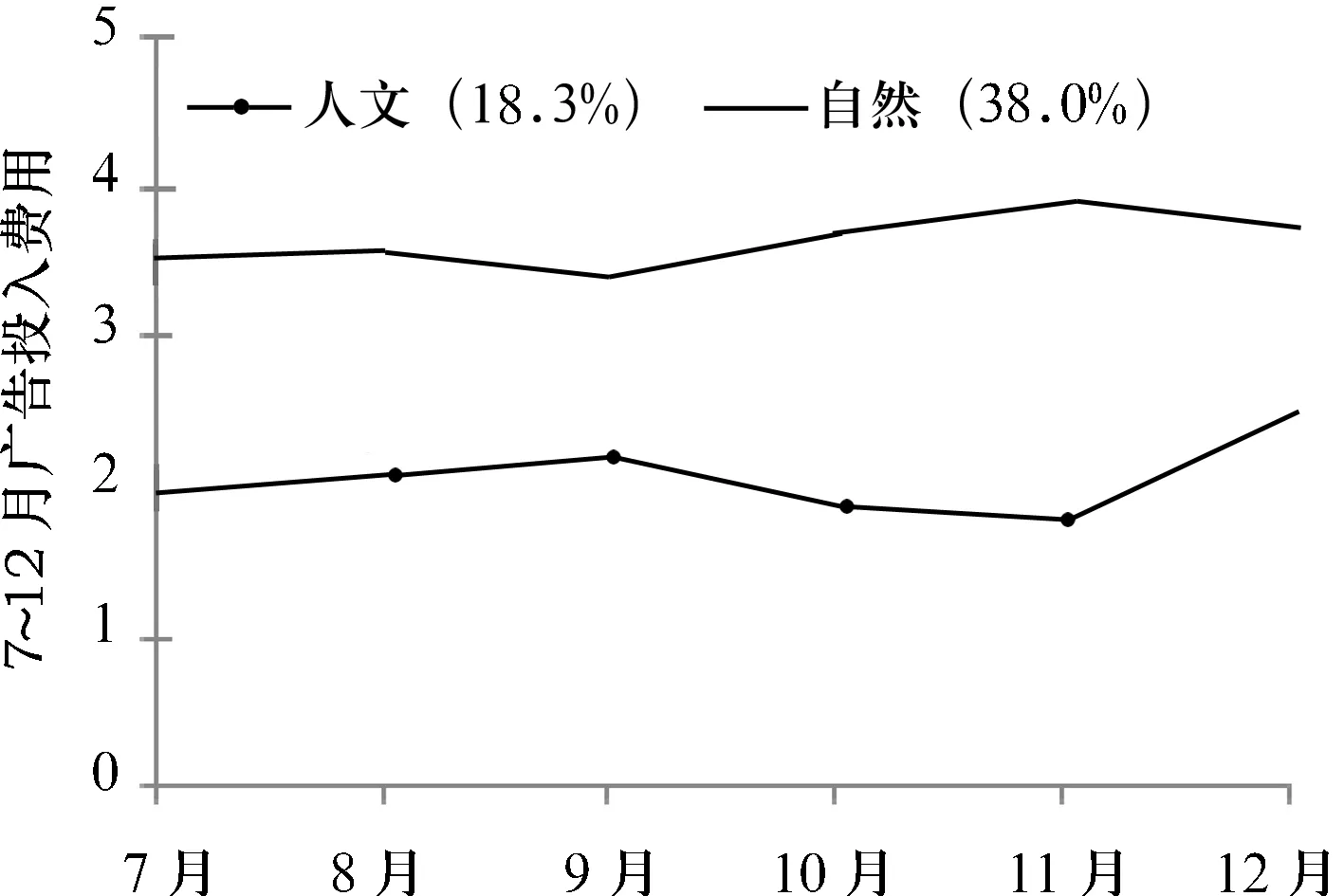
图5 V 2.0应用平台盈利数据
从图5可知,当数据盈利方式改变后(付费到免费),自然科学版块的广告收入(7~12月)加权平均值为3.64,人文与社会科学版块的广告收入(7~12月)加权平均值为2.08,前者是后者的1.5倍,因此,到达率对于提供版块的广告收入有着较大的影响,同时在改变了数据盈利方式后,2个版块的收入都有较大的提高.
4 结 论
本研究以DOA思路为核心,提出通过“两中心模式"来解决大数据背景下应用系统内数据使用过程中的效率及数据价值的评价问题.其中,数据分片中心采用主从副本缓存模式并结合数据序列化方式来解决海量数据下数据一致性与数据传输效率这一矛盾问题;数据评价中心采用AHP获得每个指标的权重,使得评价结果更准确、合理.同时,基于评价指标的权重影响,对应用平台的运营模式进行了改变,从而获得更大的收益.所有的计算过程均采用R语言完成,保证了结果的快速与准确.
猜你喜欢
词学(2022年1期)2022-10-27
计算机工程与应用(2022年2期)2022-01-25
科学与社会(2020年4期)2020-03-07
当代水产(2019年11期)2019-12-23
网络安全和信息化(2019年8期)2019-08-28
计算机系统应用(2019年2期)2019-04-10
火控雷达技术(2018年4期)2019-01-15
小型微型计算机系统(2018年3期)2018-03-27
北京航空航天大学学报(2016年12期)2016-02-27
电子竞技(2009年14期)2009-09-07
