
工业控制系统未知协议特征提取及异常流量检测
2019-03-14 07:17方鼎鼎郑荣锋周安民
现代计算机 2019年4期
方鼎鼎,郑荣锋,周安民
(1.四川大学电子信息学院,成都 610065;2.四川大学网络空间安全学院,成都 610065)
0 引言
工业控制系统是国家安全战略的重要组成部分,然而,工业控制系统的工作特点、运行环境、操作模式等特性让传统的IT防护解决方案无法实施,许多关键性基础设施的控制系统很少有防范突发事故和恶意攻击的保护措施。工业控制系统一旦受到攻击往往会导致极其严重的后果,美国埋下的“软件炸弹”摧毁了前苏联的经济命脉、波兰电车脱轨、伊朗核电站因电脑被病毒入侵而瘫痪。因此,加强工业控制系统的安全防护具有重要的战略、经济价值。
目前对于工业控制系统安全性的研究都集中于两方面,一是工业控制系统入侵检测,二是工业控制系统固有脆弱性分析[1]。在入侵检测技术中,分析工控中的异常流量是入侵检测最主要的手段之一。但基于系统安全性的考虑,目前绝大部分工控协议都是私有协议,这为构建正常流量模型带来了障碍。西门子公司的S7协议虽然是私有协议,但网络上已经有相当多的关于S7的协议内容分析,因此利用S7协议流量进行协议特征提取和流量建模,可以验证协议特征提取的有效性和准确性。
不同于传统IT网络流量复杂多变的特性,为了满足特定的工业生产流程,工业控制网络的流量具有一些鲜明的特点。工业现场设备一般都利用轮训机制收集并上传数据,网络中的流量因此呈现出高度的周期性[2]。Barbosa 等人[3]、Pleijsier等人[4]就实证展示了工业控制系统在网络流量所显示的以高度周期性方式产生流量、有非常稳定的连接图等特性。基于工业控制网络流量的周期性的特点,Goldenberg[5]和Wool[6]在2013年和2015年针对Modbus和S7 SCADA网络分别提出了基于DFA的入侵检测模型,有效地识别出了工控网络中的攻击行为。随后,在2016年彭勇等人借鉴传统IT网络中的指纹识别技术提出了工业控制系统中场景指纹模型的建立和异常检测的方法。这些研究都指明了工控系统流量具有周期性,相对简单、稳定的特点,因此,从流量特性出发是研究工控流量很好的切入点。
有限状态机(DFA)模型就是利用工控流量周期性特点建立的一个异常检测模型。传统的DFA的构建,对于协议的先验知识依赖颇为严重,本文通过分析工控流量的特性,利用自然语言处理模型和统计学的相关算法直接提取出工控协议的特征,无需先验知识就可以完成数据包状态的标记,从而实现DFA模型的构建,并同过实验检测了模型的效果。
1 工控异常检测模型
工控异常检测模型是用来监控检测工业控制系统中流量的模型。通过分析正常的工业控制系统工作流量,利用特定的方法提取出正常的流量模型,该模型可以对工业控制网络中的异常流量进行检测并报警。工控异常检测模型如图1所示。
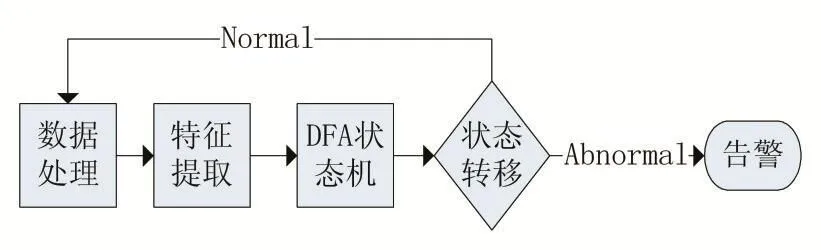
图1 工控异常检测模型
在传统的DFA检测模型中,在数据处理阶段,都需要协议的先验知识来提取数据流中的关键字段,并以关键字段为特征,为各类数据包打上唯一的“状态标签”,形成数据流的状态集。本文通过自然语言处理中常用的N-Gram模型提取出数据流中的N-Gram单元频繁集,利用关联规则算法确定频繁集与其在数据包应用层具体位置的联系,提取出数据包的特征字段,以特征字段标识数据包,形成状态集,再通过状态转移来实现异常流量的检测。
在模型检测过程中分别会将异常行为分为以下几类:
(1)未知信道,表示会话的双方出现IP地址的改变。
(2)未知状态,出现了场景中从未出现过的状态。
(3)未知转移,出现了错误的数据包状态转换。
2 协议特征提取
2.1 数据预处理
S7协议是西门子工业设备中人机交互界面(HMI)与PLC之间常用的通讯协议,作为私有协议,S7协议的格式并未公开,同时S7协议在数据包中是以明文形式存在,对其进行二进制数据分析是可行的[7]。在工业控制环境中,PLC与HMI的通信都是相对独立的,以每个PLC与不同上位机之间的连接建立单独的信道对S7协议进行研究,可以滤除信道中无关数据包的干扰,使检测模型更加简单高效。
彭勇等人在对工业控制系统研究中提出了场景指纹模型,其中有一个关键概念是“工控协议数据包的包大小类型有限”[8]。在本地搭建的模拟真实发电厂工作模式的西门子仿真实验平台中,获取到的数据训练集也验证了这一点。在仿真平台多个工作周期的数十万交互数据包中,也只发现了8种长度的数据包,长度分别为 76、86、87、91、94、97、115、131。数据包各长度在数据集中的占比如图2所示。

图2 各长度数据包在训练集中的占比
因此,在数据预处理阶段,先提取出工控数据流中的S7协议部分,再将S7协议数据流按信道划分,最后在不同信道下,以数据包长度大小再次进行划分得到协议特征提取样本。流程如图3所示。

图3 协议样本提取流程
工控数据流是由Wireshark工具捕获的,而S7协议是应用层协议,故分析时应当剔除掉样本中应用层以上的数据,只对应用层二进制数据进行分析。
2.2 N-Gram模型提取频繁项集
N-Gram是一种自然语言处理模型,在自然语言处理中基于一定的语料库,可以利用N-Gram对句子的合理性进行有效地判断[9]。二进制数据作为机器间进行指令、信息的传输载体,是一种公认的机器语言。因此本文利用自然语言处理模型N-Gram对二进制数据进行切分。N-Gram切分的基本思想是利用一个长为n的窗口,这个窗口从语言处理文本的第一个字符开始向后移动,每次移动一个字符单元。这个窗口中包含的n个字符即为一个N-Gram数据单元。图4为n=3时的切分示意图。
本文利用N-Gram模型对S7协议进行分析,要完成以下两步:
(1)n值的确定,不同的n值会直接影响特征字段的提取。
(2)计算N-Gram字段出现的频率确定频繁项集,这需要设定一个合适的阈值。

图4 3-Gram单元切分图解
首先为了便于分析,将二进制数据流转化为16进制形式,就如图4所示,然后利用N-Gram对16进制数据进行切分。如何进行切分,关键还是在于确定合适的n值,以保证切分后的数据串能涵盖较为完整的协议信息。实践中,一般很少利用高于4元的,因为训练它需要庞大的语料,并且数据稀疏严重,时间复杂度高,最后精度也提升不了多少。因此本文中分别对n=1,n=2,n=3时进行S7协议应用层数据切分,最后利用齐夫分布[10]来确定合适的n值。如图5是n=1,n=2,n=3时的齐夫分布图,可以发现当n=1时最接近于直线。因此选定n=1来进行切分,可以提取出最多的协议信息。
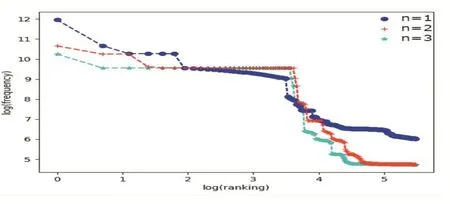
图5 齐夫分布图
2.3 1-Gram频繁单元的筛选
利用n=1对数据帧进行切分,可想而知会得到大量的1-Gram单元,这些获取的1-Gram单元中必然包含具有一定意义且频繁出现的数据单元,首先可以将频次明显极低,不符合特征要求的串删除。其次再利用基于基础相似度计算模型中的向量空间模型,计算1-Gram单元间的相似度,最终得到筛选后的频繁数据单元。本文利用Jaccard参数[11]来比较1-Gram样本的相似性和分散性的概率,获得1-Gram频繁数据单元,Jaccard参数的计算公式如下。
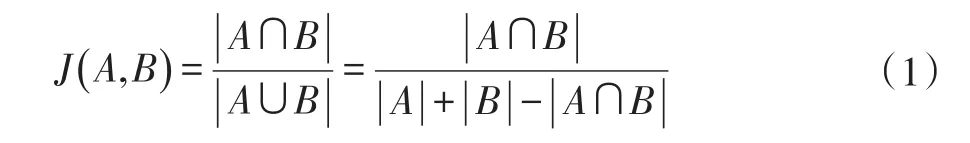
将切分好的1-Gram集合随机的分成A和B两部分,在两部分分别统计每个单元出现的次数,而后按照降序排列,此时,降序排列号就是和A(A1,A2…),B(B1,B2…)按照公式(1)代入计算得到两部分的相似度。计算长度为91的数据包1-Gram单元Jaccard参数,结果如图6所示。

图6 1-Gram单元Jaccard系数值
将图6中(Ai+Bi)/2升序排列,当其对应的Jaccard参数值最大时其对应的(Ai+Bi)/2即为阈值,然后依据阈值进行筛选,低于阈值的就删去,对高于或者等于阈值的数据单元进行存储,这些被存储的数据单元就是1-Gram频繁数据单元,之后再进行下一步处理。
2.4 利用关联规则挖掘 1-Gram频繁数据单元同其位置信息的联系
关联规则挖掘的目的在于从海量数据中找寻数据间的有价值的规律和关系[12]。本文利用Apriori关联规则算法进行关联数据挖掘。关联规则的获取就必须引入两个关键的概念支持度和置信度,设有两个事件A和B,以及发生过的总事件的集合T,支持度定义如下:

即为A事件发生时B事件也发生占总的发生事件的比例。
置信度定义如下:

即当A事件发生时B事件也发生的事件总数与A事件发生的总数的比值。
因此,根据这两个指标,关联规则的挖掘有两个基本步骤,首先找出所有的频繁项,获得频繁项集,也就是根据最小项集支持度,在集合中找出频繁项集。其次根据最小置信度,寻找符合条件的关联规则。
在一个工控场景中S7协议数据包长度类型有限,出现的1-Gram频繁数据单元同其出现在数据包中的位置可能有着一定的关联规则,通过统计每个1-Gram单元同其在每个数据帧中的位置信息,并利用关联规则算法可以获得1-Gram单元与其存在位置信息的某种联系。
因此对于1-Gram数据单元进行关联规则分析的步骤如下:
设1-Gram频繁数据单元在数据包中出现的事件为P,并设1-Gram单元在数据包位置N出现的事件为K。
它们的关联规则定义为R:p->k。它表示当频繁数据单元在数据包出现后,同时频繁数据单元又在数据帧位置N出现的概率。如果这个事件出现的概率很大,那么就可以认为1-Gram数据单元只要在数据帧中出现,则它大概率在数据帧的位置N上,在本文中就可以认为如果1-Gram数据单元出现在数据包位置N上,则它属于数据包的特征单元,按出现位置次序拼接特征单元得到数据包特征串。

图7 关联规则计算结果
如图7所示,以长度为91的S7协议数据包为例,通过计算发现除了位于66,67及90,91位置的1-Gram单元以外,其他位置的频繁项单元置信度都为100%,这意味着在整个工作流程中这些位置的字节并没有发生过变化。显然,这些字节对于S7协议的研究并没有任何帮助,故我们将频繁1-Gram单元与位置之间关联规则置信度的筛选阈值设为10-75%。同时,由于66,67位置出现的频繁项单元置信度低于阈值,所以如表所示,满足条件的只有90,91位置的频繁项单元。
置信度太低,则表明字节与位置的关联不强,字节没有代表性,但置信度阈值的下限需根据工控场景的复杂度动态调整,如果场景足够复杂,则特征位中的特征值种类可能会比较多导致每个特征值的占比降低。由于工业控制系统流量的周期性,置信度太高则可能会受一些周期出现的无用字节的干扰。作为一个周期性工业流程的特征串,特征串提取后必然也应当具有周期性,故最后还需对特征串进行周期性检验。
至此,完成了S7协议应用层特征串提取的整个过程,图8为流程图。
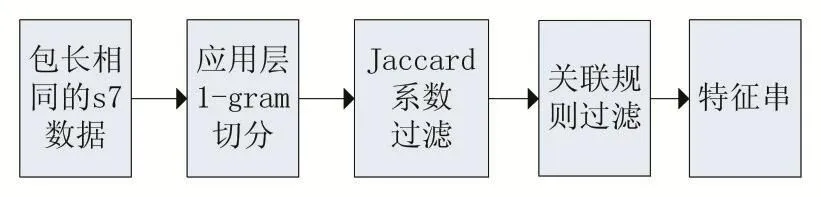
图8 S7协议应用层特征串提取流程
特征串提取后,就可以利用特征串来区分一个信道下的数据包的不同状态,相同特征串的数据包归为一类,以字符si标记这类数据包的状态,实现单个数据包状态标记。
3 有限状态机模型
在工业控制网络环境中,为了满足特定的工艺生产流程,网络流量具有明显的规律性,因此可以用一个五元组:(q,Σ,δ,s,t)来描述网络中各个连接的数据交互情况,这就是一个有限确定自动机模型。其中q为一个信道中下行数据流量有限状态的集合;Σ为导入模型的数据流;δ为状态转移函数;s为当前状态,是q的一个子集,t为s转移到下一个状态的可能性的集合,当s完成一个正常状态转移时,有如下公式:

建立状态机的流程图如图9所示:
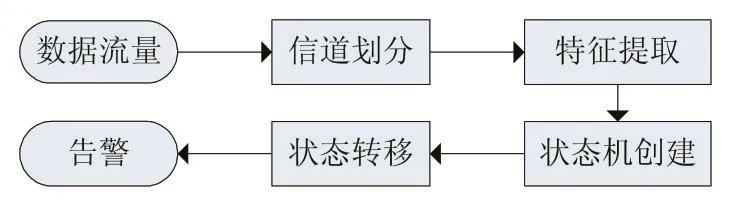
图9 有限状态机建立流程图
在工业控制网络中,网络流量一般分为两大类,一类是上位机发送给PLC对工控现场进行实时控制的下行数据,一类是上位机HMI软件与PLC协商由PLC定时发送给HMI软件工控现场实时数据,能实时反映工控现场的工作情况。因为针对工控网络的攻击通常都是通过获取上位机权限进而控制PLC的,为了降低模型的复杂度,所以在传统的有限状态机的构建中,只考虑下行数据。
4 实验检测
4.1 网络拓扑
本地搭建的西门子工业控制系统实验仿真平台是模拟实际的发电厂的工作模式,仿真平台由3台上位机同 3个西门子 PLC(2个 S7-200,一个 S7-300),还有灯、蜂鸣器、发电机构建而成。整个系统分为两部分,一是控制端,由3台上位机构成,上位机分为工程师站、操作员站、还有实时服务器,在工程师站安装了PLC编程软件,可对3个PLC进行编程。第二部份是设备端,即由3个PLC、灯、蜂鸣器、发电机构成,S7-200控制蜂鸣器报警,S7-300控制发电机运作。
3台上位机中安装了西门子公司提供的人机交互界面组态软件(HMI),通过HMI可以实时监测控制整个系统的运行情况,并收集系统运行过程中的数据流。通过路由器端口将流量镜像到检测主机中,再利用Wireshark工具就可以将数据流输出成pcap类型文件。当系统正常运作时,这些抓取的数据流就是本文的模型训练数据,当对系统模拟攻击时,抓取的数据就是本文需要的异常检测数据。工控实验平台的网络拓扑图如图10。

图10 西门子仿真实验平台网络拓扑
4.2 模型训练
当工控实验平台正常运转时,连续抓取了8个小时左右的数据包作为正常数据集进行模型训练,按照上文所述的数据处理规则,数据集中总共有3个信道,工程师站与S7-200、工程师站与S7-300、操作员站与S7-300,将这3个信道分别编码为信道1、信道2、信道3。在不同信道下按长度划分数据包并分别提取每个长度数据包的特征,每个特征构成一个数据包状态。从而构建不同信道下,下行数据包DFA状态机模型。以信道2为例,下行数据包只有长度为91、87的S7协议数据包如图11所示。

图11 信道2下行数据包
分别对两种长度数据包提取特征,则得到91数据包特征 4种(s1、s2、s3、s4),87数据包特征 1种(s5)。从而得到DFA有限状态机模型的正常状态转移如图12。

图12 有限状态机正常状态转移
图12是信道2下行流量有限状态机模型状态转移,其中的带箭头的线段表示正常的状态转移,其中标明的数字表示状态转移条件概率。同理其他信道也是如此构建有限状态机模型,当信道中出现未知的状态,未知的状态转移则模型报警。
4.3 异常检测结果
在仿真平台上通过实施以下几种异常操作获取异常数据流量进行异常检测:
中间人攻击,通过拦截HMI与PLC之间正常工作时的网络通信数据,并对数据进行篡改和嗅探,可以同时达到欺骗HMI与PLC的目的。
响应注入攻击,HMI组态软件除了对系统进行数据收集的功能外,也会同时对PLC返回的各项参数如发电机转速值进行监测,如果转速超过一定阈值,HMI软件就会对操作人员进行告警,通过捕获PLC发往HMI的响应数据包,并修改数据包中的关键内容,可以掩盖PLC的异常运行信息。
序列攻击,通过修改数据包的传送次序,来达到篡改工业控制系统运行逻辑的目的,因为数据包是网络中出现的正常数据包,对单一数据包的检验方式无法发现这种异常
Snap7攻击,工业控制场景中往往缺乏PLC对于HMI设备的检测认证机制,因此同过在局域网内的另一台主机上安装S7协议的编程软件,对PLC进行编程操作。
正常流量数据集,一个合格的入侵检测模型的建立不仅要能识别流量的异常,对于正常流量也应具有足够低的误检率。
通过表1中的实验结果可知,本文提出的基于工业控制系统流量特性有限状态机模型在西门子工控仿真实验平台上运行良好,不仅可以准确识别出工业控制网络中的常见异常,对于正常流量也未产生误报警。

表1 流量检测结果
5 结语
基于工业控制系统流量特性的有限状态机,利用了工业控制系统流量周期性和工业控制系统中包长度类型有限的特点,在传统的DFA模型中,改进了协议特征提取方式,无需先验知识就可对未知格式的工控协议进行特征提取,能很好地识别系统的逻辑异常行为,提高了模型的检测精度和适用范围。
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
数字技术与应用(2021年4期)2021-06-01
空间电子技术(2021年1期)2021-04-09
民用飞机设计与研究(2020年4期)2021-01-21
北京航空航天大学学报(2019年9期)2019-10-26
中国电子报(2019年75期)2019-01-16
物联网技术(2018年8期)2018-12-06
中国经济周刊(2016年9期)2016-03-09
中国信息化周报(2015年17期)2015-06-01
现代电子技术(2009年14期)2009-09-05
