
生成对抗网络模型的基本介绍和应用综述
2019-03-14 07:17冯杰班彪华
现代计算机 2019年4期
冯杰,班彪华
(广西师范学院计算机与信息工程学院,南宁 530000)
0 引言
与神经网络相关的大量工作诞生于20世纪五十年代,然而当时的计算机运行得十分缓慢,数据量也小,科研人员并没有发现在现实世界中能够使用神经网络的场景。因此,在21世纪初,神经网络几乎被机器学习领域学者所遗忘。直到近年来,神经网络最先在2009年的语言识别领域,接下来在2012年的计算机视觉中,其凭借优异的表现重新回到人们的视线(同时伴随着LeNet、AlexNex等网络架构的提出)。大数据(Big Data)以及廉价高速的GPU为神经网络的发展提供了动力,使其快速成为当今最炙手可热的研究方向。
深度学习是机器学习中十分令人振奋的一个分支,它利用大量的数据来训练计算机去做一些之前只有人类才能做的事情,诸如如何分辨图像中有哪些物体,分辨人们在打电话时对话的内容,将文档翻译成另一种语言,帮助机器人探索世界并对各种事情及时响应,等等。深度学习成为解决机器认知问题最为核心的工具,并且是计算机视觉和语音识别领域当下最为优秀技术之一。
最近几年,深度神经网络[1]在图像识别、语音识别以及自然语言理解方面的应用有了爆炸式的增长,并且都能达到极高的准确度。目前最新进的深度神经网络算法可以通过数据学习到高度复杂的模型和模式,它们的能力令人印象深刻。然而人类可以做能力远超出图像识别和语音识别的任务,而这些任务想要通过机器进行自动化似乎还是天方夜谭。例如:①通过学习维基百科上的文章来训练出一个人工智能作者,以一种通俗易懂的方式写一篇面向社区解释科学概念的文章。②创造一个可以通过学习著名画家的作品集来模拟他的风格进行创作的人工智能画家。毫无疑问,这些都是很困难的任务,但是生成对抗网络(GAN)使得这些任务的解决变为可能。深度学习的领军人物,Facebook AI部门主管Yann LeCun曾经说过:“生成对抗网络(GAN)及其变种已然成为近10年来机器学习领域最令人激动的想法。”
1 生成对抗网络
生成对抗网络(Generative Adversarial Networks,GAN)是Goodfellow等[2]人在2014年从自博弈论中的“二人零和博弈(即二人的利益之和为零,一方的所得正是另一方的所失)”中受到启发而提出的。GAN是一个通过对抗过程来估计生成模型的新框架,并可使用随机梯度下降(Stochastic Gradient Descent,SGD)实现优化。这避免了反复应用马尔可夫链学习机制带来的配分函数计算,不需变分下限也不需近似推断,从而大大提高了应用效率[3]。它需要同时训练两个模型:捕获数据分布的生成模型G(Generative Model)和一个用于估计样本来自训练数据而非G的概率的判别模型D(Discriminative Model)[1]。生成模型捕捉真实数据样本的潜在分布并生成新的数据样本,判别模型是一个二分类器,判别输入的数据是来自真实数据还是生成的样本数据。为了能在博弈中胜出,两个模型需不断提高自身的生成能力和判别能力。生成模型和判别模型均可用深度神经网络。生成对抗网络GAN的优化过程是一个极大极小博弈(Minimax Game)问题,优化的期望是达到纳什均衡,使得生成模型估测到数据样本的分布或生成期望的数据样本。
2 基于生成对抗网络GAN的各种变体
2.1 CGAN(Conditionall GAN)
一个生成对抗网络(GAN)会同时训练两个网络——一个从未知分布或者噪声中学习生成伪造样本的生成器,以及一个学习如何从样本中区分真伪的判别器。
条件生成对抗网络[4]是在生成对抗网络(GAN)的基础上进行了一个扩展。由于GAN不需要预先建模,使得生成过程过于自由,对于较大的图片,较多像素(Pixel)的情形,基于简单生成对抗网络(GAN)的方式就变得不可控。为了解决GAN太过自由这一问题,很自然地就想到给生成对抗网络增加一定的约束,让生成对抗网络以我们理想的方向去生成图片。在条件生成对抗网络中,生成模型并不是直接输入一个随机噪声,从一个未知的噪声分布开始学习,而是通过一个特定的约束条件或者某些特征(例如一个图像的类别标签,用于图像修复的部分数据属性等)开始学习如何生成样本。在生成模型和判别模型的建模过程中都引入条件变量,即给两个网络都加入一个参数向量y。这样生成模型和判别模型都拥有一组联合条件变量。一般情况下,生成模型中的先验噪声输入p(z)和条件变量y会以隐藏节点连接的方式结合在一起。
所以,条件生成对抗网络的目标函数为:


图1 条件生成对抗网络架构
从图1所示的架构中可以看出,CGAN相比于GAN增加了一个输入层条件向量C,同时连接到了生成模型网络和判别模型网络。
2.2 DCGAN(Deep Convolutional Generative Add--versarial Net woorrkk)
DCGAN即深度卷积生成对抗网络[5],它的基本原理是将卷积神经网络和生成对抗网络进行结合,将CNN的概念思想融入到生成模型和判别模型中,让生成对抗网络的性能得到极大的提高,为后续各种关于GAN的工作提供了思想依据。
DCGAN主要通过以下几个架构性的约束来固化网络:
●使用步数卷积取代卷积网络中的池化层;
●在生成模型和判别模型中均使用批规范化;
●消除网络架构中较深的全连接层,并且在最后只使用了简单的平均池化;
●在生成模型的输出层使用tanh激活函数,而在其他层则使用ReLU激活函数。
●在判别模型的所有层中都使用了Lecky ReLU激活函数。
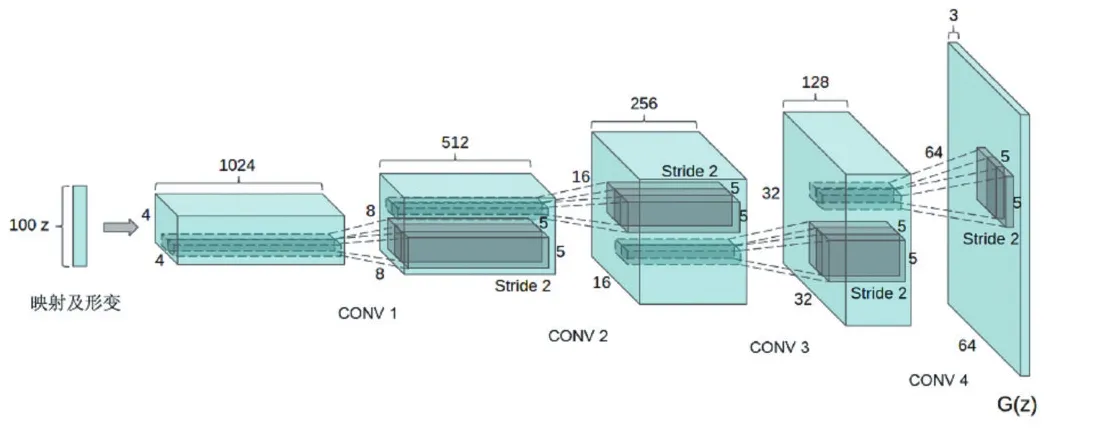
图2 DCGAN生成模型的架构图
2.3 CylclleGAN(Cycle Consistent Generative Nett--wwoorrkk)
循环一致生成网络[6]最初在论文Unpaired imageto-image using CycleGAN-arXiv:1703.10593,2017 中提出,主要用来寻找不需要其他额外的信息就能将一张图像从源领域映射到目标领域的方法。被学者们认为是“最好玩”的GANs模型,它可以将灰度图像变成彩色图像、将普通的马转换成黑白条纹的斑马、还能将一副普通的画作瞬间变为具有莫奈和梵高等大师风格的“惊世之作”。

图3 CycleGAN的有趣应用
CycleGAN的核心思想是一个环形结构,主要有两个转换器F和G组成(一个转换器含有一组生成模型和判别模型),如图所示,X表示X域的图像,Y表示Y域的图像。其中x域的图像先通过转换器G生成y域的图像,再通过转换器F重构回X域输入的原图像。同样的,y域的图像先通过转换器F生成X域的图像,再通过转换重构回y域输入的原图像。其中判别模型Dx和DY起到判别作用,促使图像进行风格化迁移。因此,对于一个在域X的图像x,我们期望函数G(F(x))的结果与x相同;同样,对于一个在域Y的图像y,我们期望函数F(G(y))的结果和y相同。

图4 图像从域到域的迁移示意图
CycleGAN模型有以下两个损失函数:
●对抗损失:它和生成图像的分布以及目标域的分配相匹配。

●循环一致损失:它用来避免学习到的转换器G和F互相矛盾。

完整的CycleGAN目标函数如下:
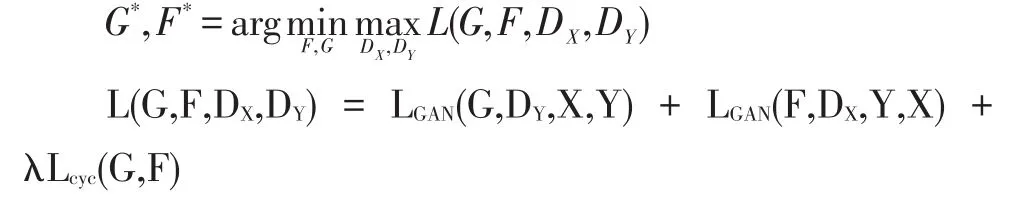
2.4 StackGAN(Stacked Generative Adversarial Networks)
堆积生成对抗网络的思想最早来自文章Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks—arXiv:1612.03242,2017,GAN 在文中被用于通过文字描述来生成图像。
通过文本制作逼真的图像在计算机视觉领域是一个极具挑战的问题,并且有着极其广泛的应用场景。通过文本生成图像的问题可以分解为两个更易于控制的子问题,进而可以使用StackGAN[7]。通过这种方法,我们根据特定条件(文本描述和上一阶段的输出)堆叠出了一个两阶段生成对抗网络来解决从文本生成逼真图像这个问题。
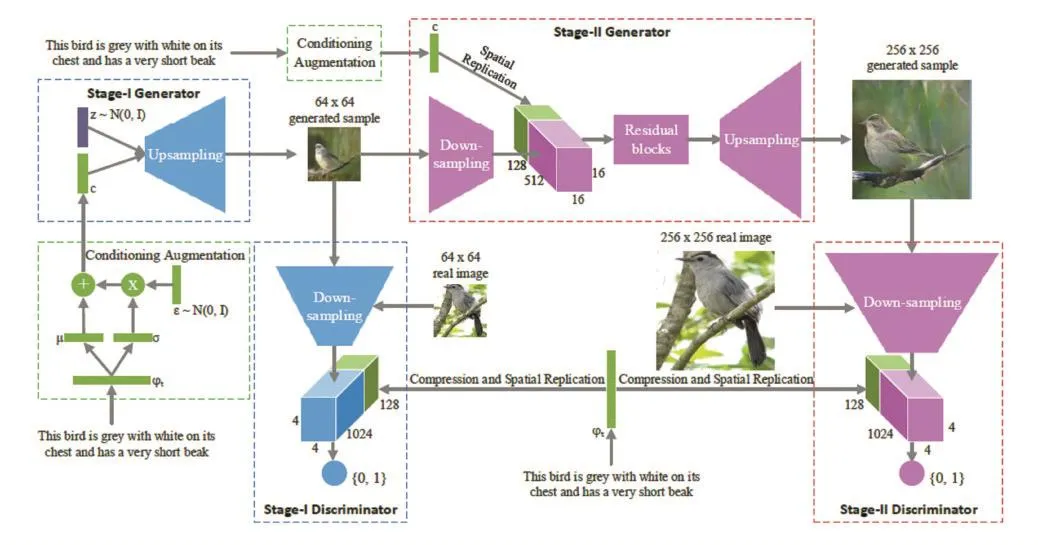
图5 StackGAN的架构模型
StackGAN模型主要分为两个阶段:
(1)阶段一
在本阶段中,StackGAN就是一个标志的条件生成对抗网络,输入就是随机的正态分布采样的z和文本描述刻画的向量c,网络需要学习以下内容:
●根据文本描述的条件生成物体大致的形状和基本的颜色。
●通过先前的分布和随机噪声样本生成背景区域。
在这个阶段生成低分辨率的64×64的粗粒度图像看起来并不真实,有可能物体形态被扭曲,或者丢失了某些部分。
阶段一中GAN分别通过下面的公式来训练判别模型D0(最大化损失)和生成模型G0(最小化损失):
判别模型损失函数:
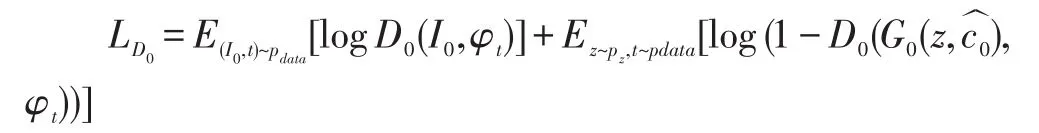
生成模型损失函数:

(2)阶段二
在本阶段中,GAN网络专注于勾勒细节,将第一阶段的生成结果和文本描述作为输入,用第二个生成对抗网络生成一张符合文本描述信息的256×256分辨率的高清晰度逼真图像。
判别模型损失函数:

生成模型损失函数:

3 生成对抗网络GAN的相关应用
3.1 图像超分辨率
超分辨率技术(Super-Resolution,SR)是指把低分辨率图像重建出相应的高分辨率图像,其在安防监控、卫星观测和医疗影像等领域都有较为重要的应用价值。SR一般可分为从单张和多张低分辨率图像重建出高分辨率图像两类。基于深度学习的SR,主要是采用单张低分辨率的方法。
来自Twitter公司的Ledig等[8]提出了一个用于超分辨率的生成对抗网络SRGAN,将低分辨率图像变换为具有丰富细节的高分辨率图像。作者以VGG-19网络作为判别模型,用规则化处理的残差网络作为生成模型。实验结果如图所示,可以看到SRGAN取得的效果比目前最先进的深度残差网络(Deep Residual Net⁃work,ResNet)更加出色。

图6 SRGAN生成效果对比
3.2 图像修复
图像修复是对图像上信息缺损区域进行信息填充的过程,其目的是利用图像现有的信息来恢复丢失的信息。图像修复技术可用于旧照片中丢失信息的修复,视频文字去除以及视频错误隐藏等。Pathak等人[9]将CGAN应用到图像修复中,利用生成对抗网络的思想,以图像缺失部分的周边像素作为生成模型的输入修复完整的图像,再将修复样本和真实样本输入到判别模型中,进行对抗训练,如图所示,相比于传统方法(Image Melding),基于GAN的图像修复可以更好地考虑图像的语义信息,所生成的修复图像与周边更加连贯自然。
最近,英伟达深度视觉实验室发表了论文Progres⁃sive Growing of GANs for Improved Quality,Stability,and Variation,提出一种以渐进增大的方式更稳定地训练GAN,实现了前所未有的高分辨率图像生成。
3.3 视频预测

图7 GAN与传统方法的数据填补效果[10]
视频预测是指根据视频的当前几帧,来预测接下来发生的一帧或多帧视频。普遍方法是使用最小二乘法来逐一回归视频帧的像素值,这种方法的问题是生成的视频会存在动作模糊。Mathieu等人[11]最先提出将对抗训练的思想应用到视频预测中,其生成模型是根据前面若干帧来生成视频的最后一帧,而判别模型则是对该帧进行判断。除了生成的最后一帧外,前面的若干帧都是视频中的真实图片,这样的优点是能使得判别模型利用时间维度的信息更加有效,同时通过对抗,有助于生成帧和前面的若干帧保持一致性。
最近,卡内基梅隆大学和Petuum合作提出了一种对偶运动生成对抗网络架构[12],可以使用一种对偶对抗学习机制来学习明确地未来帧中的合成像素值与像素上的运动轨迹保持连贯。具体来说,它能同时根据一种共享的频率运动编码器而解决原始的未来帧预测问题和对偶的未来流预测问题。这项研究将有助于解决自动驾驶的难题。

图8 对偶对抗学习机制架构[12]
4 结语
自2014年Goodfellow提出生成对抗网络以来,其在机器学习领域得到了广泛的关注和发展。经过近几年,各种新颖有趣的生成对抗网络变体不断被提出,在计算机视觉的各个领域都得到很好地应用。生成对抗网络作为一种新型的生成式模型,它的二人零和博弈思想,“无限”的新样本生成能力,相信会在计算机视觉领域外的语音和语言处理、信息安全等领域发挥更重大的应用价值。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
汽车工程(2021年12期)2021-03-08
科技传播(2019年23期)2020-01-18
当代陕西(2019年16期)2019-09-25
电子制作(2019年24期)2019-02-23
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
