
一种基于OCSVM的PLC网络异常检测技术
2019-03-14 07:17何世敏刘嘉勇郑荣锋
现代计算机 2019年4期
何世敏,刘嘉勇,郑荣锋
(1.四川大学电子信息学院,成都 610065;2.四川大学网络空间安全学院,成都 610065)
0 引言
由于在实际的工业控制系统中,采集到的正常流量样本数远多于异常流量的样本数。所以采用传统的支持向量机算法对正负样本分类的准确率会较低。而单类支持向量机算法利用一种类型的样本数据就可以训练出检测模型,并且也不需要对数据类型进行标记。该算法是通过核函数把输入的工控流量数据映射到高维特征空间,并在此空间中找出最大超平面来分类出异常和正常类型[1-3]。文献[1]提出了一种基于单类支持向量机和递归K领域方法结合的异常检测技术,通过不断调节单类支持向量机算法中核函数的参数g,算法本身参数C和设置K领域的阈值来提高检测异常流量的准确率。文献[2]中,作者通过使用单类支持向量机和增量学习的方法分类正常和异常的数据类型。文献[3]中,作者通过在单类支持向量机模型和K-means方法来检测工控网络流量。这些检测方法都能够分类出异常类型,但是对单类支持向量机中核函数的参数g和算法的本身参数C的优化,传统的方法是采用网格搜索法。该方法虽然具有全局的搜索能力,但是耗时多,效率低[4]。此外,在实际的工业操作过程中,由于获得的样本量大,数据维数过多,会使得训练模型和异常检测时间复杂度高[2-3]。
本文针对西门子S7协议的通信特征和减少模型计算时间消耗的问题,采用单类支持向量机的算法建立异常检测模型,同时结合了主成分分析法对数据的特征进行降维,减少了模型的训练和检测时间。
1 特征选择
在传统的针对网络层和传输层的网络异常检测研究中,一般选择源端口、目的端口、源IP、目的IP、IP包总长度、TCP总长度、窗口流量大小作为能够代表原数据包的特征[5]。针对在实际情况中,对工控网络应用层的攻击手段较多的特点,本文除此之外,还对应用层的S7协议进行了特征选择。
S7协议的通信端口是102端口,工作在TPKT协议和COTP协议之上。该协议被IP头、TCP头、TPKT头和COTP头封装。其数据包结构如图1所示。

图1 S7协议数据包结构
根据文献[12]对S7协议的分析,Header部分是由Protocol Id、ROSCRT、Protocol Data Unit ReferenceData、Length、Parameter length字段组成,其中除了Protocol Data Unit Reference字段的值会随着请求与响应命令的发送增加外,其他字段的值都是固定不变的。因此本文把Protocol Data Unit Reference字段作为特征之一。
Parameters部分由Parameters set和Parameter Data字段组成。在Parameters set中Function字段代表的是PLC的操作,而在一般的攻击行为中,都会通过改变Function的值来改变对PLC的操作,因此,Function字段也作为本文的特征之一。
Parameter Data字段定位PLC中的内存信息[6],该字段结构如图2所示。为了提取出内存地址,字节大小,本文把Parameter Data整个字段作为特征。

图2 Parameter Data结构
Data部分中存储的是PLC操作的数值,本文把如图3所示的字段作为特征。因为文中在异常检测实验中,为了获得异常流量数据,会在实验平台上运行多种攻击脚本,其中一种就是伪造图中所示字段数值来改变发电机转速。

图3 Data字段
2 特征降维
假设采集到的PLC和上位机之间的网络流量中数据包有m个,经过特征选择之后,每个数据包中共有n=19个特征代表原始样本的信息,用矩阵形式表达如下:

在特征选择的过程中选择的有效特征越多,越能体现原始样本的信息。但是在实际的工控系统中,由于样本量大和矩阵M的维多数的原因,会造成训练模型和检测异常的时间消耗过多的问题。为此,本文在对数据包特征选择之后,还采用主成分分析法对这些提取出的特征进降维处理。该算法流程图如图4所示。

图4 主成分分析法流程
步骤一:在经过特征选择之后,确定S7协议数据包的n=19个特征,用并将特征从网络层,传输层和应用提取出。
步骤二:将n个特征的值归一化。归一化处理是因为提取出的特征往往是具有不同的量纲单位和大小,这样的数据如果经过降维处理,会使得结果不在同一数据范围类,不具有可比性。本文采用的方法是首先求得每个数据包的n个特征的均值 μ和标准差δ,然后根据公式ni'=(ni-μ)/δ计算归一化后的特征值。其中ni代表的是第i个特征值,用ni'代替原来的ni。
步骤三:把经过归一化处理的特征排列成矩阵M。 M=(N1,N2,N3…Nm),其中 Ni=(n1',n2'…nn')T。
步骤四:计算矩阵M1。根据主成分分析法的原理,在变换过程中需要对矩阵M进行均值化。目的是为了减少那些远离平均值的点带来的降维误差,同时也是为了对归一化做进一步的规范[7]。均值化的第一步是对M中的样本求均值向量,然后用M中的样本减去均值向量得到新的矩阵M1。
步骤五:计算矩阵K。首先计算特征M1矩阵的协方差矩阵,然后求出协方差矩阵的特征向量和特征向量对应的特征值,最后将特征向量按照特征值的大小降序排列,得到矩阵K。
步骤六:计算矩阵Y。去均值化之后,将样本中的n个特征经过投影映射,过程如下:

所得的结果Y就是由新特征组成的矩阵,其中yij=(ki1n1j'+ki2n2j'+…kinnnj')。
3 单类支持向量机模型构建
3.1 模型构建方法
单类支持向量机的本质是把原点看成异于训练样本类型的点,通过非线性映射关系,把在低维空间中的数据映射到高维空间中,并在这个空间中找出一个超平面,使得原点到这个平面的距离尽可能地大[9-10]。该算法流程如图5所示。
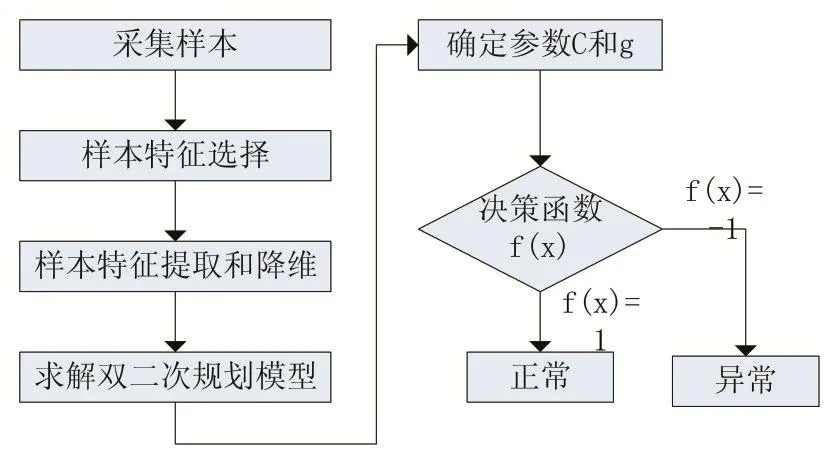
图5 单类支持向量机模型
步骤一:在PLC和上位机之间采集样本流量数据。
步骤二:确定样本的特征值,个数为n,并提取出这些特征值,用主成分分析法对特征值降维,降维过后的特征值个数为k。
步骤三:求解双二次规划模型。把经过前两步处理之后的样本用X={(xi),i=1,2,3…m}表示,其中每个xi都有k个特征。根据单类支持向量机的原理,为了使得样本能够通过非线性映射关系σ(xi)投射到高维空间中,先在高维空间中构造一个超平面为Wσ-ρ=0。其中W是超平面的法向量,ρ为偏置量。根据文献[2]可知,映射过程如下所示:

式中xi就是输入的样本。εi是一个惩罚系数,系数C=1/(μm),μ是一个权衡系数,m是样本的个数。为简化问题,单类支持向量机在映射过程中,引入了拉格朗日乘子式,将求解超平面的问题转换为二次规划问题[1]:
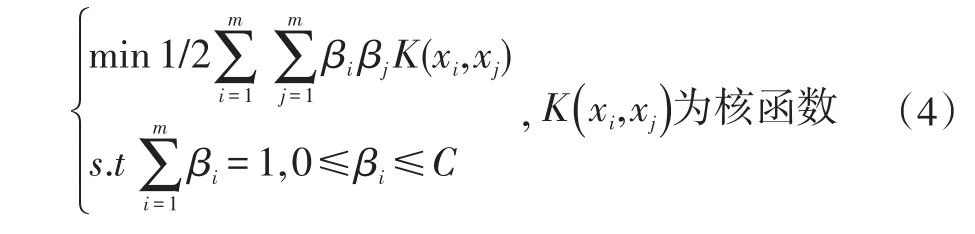
其中核函数是有多项式核函数,线性核函数,径向基核函数。根据文献[3]的实验证明,选择径向基核函数(exp(-g‖xi-xj‖2))的单类支持向量机的检测准确率更高。
步骤四:确定参数C和g。
步骤五:在确定最优参数g与C之后,求得双二次规划模型的解为{W*,ρ*,ε*},利用求得的解求出单类支持向量机的决策函数为 f(x)=sgn((W*)δ-ρ*)。该决策函数中sgn是一个符号函数,取值只有1或者-1,如果输入样本之后,结果 f(xi)=-1,那么这个样本就被标记为异常类型输出,如果结果 f(xi)=1,这个样本就被标记为正常类型输出。
3.2 基于人工蜂群算法的模型参数寻优
单类支持向量机的两个参数g和C影响着算法的准确率,为了获得最优参数,本文采用人工蜂群的方法。该方法与用粒子群求解最优参数方法相比,具有控制参数少的优点。
人工蜂群的方法是通过模仿蜜蜂采蜜的过程,把求解单类支持向量机最优参数的问题转换为蜜蜂确定食物源位置问题[11-12]。该方法中的蜜蜂是分为采蜜蜂,观察蜂和侦察蜂3种。人工蜂群算法将采蜜蜂和观察蜂在食物源附近搜索新食物源以及侦察蜂在可行解空间中的随机探索定义为一次迭代的过程,每次迭代所获得的解质量都比上一次迭代获得的解质量要高,当迭代次数接近无穷时,算法将以概率1收敛于全局的最优解[11]。
用人工蜂群确定最优参数g与C的方法如下:
以岗位能力点为标准,以项目为载体的过程教学模式具有系列考核指标,学习效果评价管理网络信息化便于教师记录过程信息与考核结果,避免了传统纸质记录的不便与管理的繁琐。通过信息平台向学生实时公开过程考核情况,以使学生了解自身的学习状况,及时制定弥补措施,公开透明的评价方式也利于形成好的学习风气。
步骤一:初始化参数。根据人工蜂群算法的原理,本文用核函数参数g和算法本身参数C组成的二维向量(g,C)来代表一个食物源的位置解。利用文献[17]的结果,把循环次数设置50,最大迭代次数设置为1000,g和C的范围设置为(0,1),原始食物源的位置解个数设为N=20,用Xi=(g,C)i,i=1,2,...,N表示。其中(g,C)i是(0,1)之间随机生成的。
步骤二:在原始解Xi的领域附近搜索新的解。由于Xi是由参数g和C组成的二维向量,所以搜索之后的新解也是g和C的二维向量。根据人工蜂群算法原理 ,新 解 vi2=Xi+random(0,1)×(Xi-Xk)。 其 中i,k=(1,2,3,…,20),且 i≠k 。
步骤四:比较vi2与Xi适应度的大小。如果vi2适应度大于Xi适应度,用vi2替代Xi。其中i=1,2,…,20。
步骤五:重新确定新解。根据步骤三中替换后的结果,计算结果中每个解被选择的概率i,2,3,…,20,并根据概率Pi重新选择解。把得到的新结果代入步骤二的公式中,重复步骤三四五,并记为一次循环。
步骤六:如果某些解经过循环50次,适应度没有得到提高,就把对应的解放弃,并且用公式xi=(g,C)min+rand(0,1)×((g,C)max-(g,C)min)随机生成新解替代原来放弃的解。
步骤七:计算迭代的次数。记步骤二至步骤六为一次迭代过程。若迭代的次数大于1000,输出的解就是最优解,也就是最优参数g和C,若小于则返回步骤二。
4 实验与结果分析
4.1 模型训练与检测
实验代码所用工具:Python 2.7,Python scapy模块提取特征和scikit-learn机器学习库。实验采集的训练样本数据是工控实验平台中S7-300PLC和上位机之间的正常网络流量数据。本文针对数据集中的单个数据包选择的部分特征如表1所示。

图6 实验平台示意图

表1 数据包特征选择
在经过特征提取之后,采用主成分分析法降维,结果如图7所示。其中横轴代表的是降维后的矩阵中的特征,也就是主成分的分量,纵轴代表的是各个主成分的累计方差贡献率。由图可以看出前11个主成分的累计方差的贡献率已经达到了95%,所以可以把前11个主成分作为替代之前选择的特征数据。

图7 累计方差贡献率
为了获得测试数据集,本文在西门子实验平台上运行了三种攻击脚本:
(1)中间人攻击:在实验平台的正常工作过程中,操作员站对发电机转速的控制是通过S7-300PLC的。当发电机的转速达到一定的阈值后,实验平台的蜂鸣器会产生警报。中间人攻击是改变了操作员站与PLC之间的数据,使得转速超过阈值之后,蜂鸣器不工作[6],数据集记为T1。
(2)转数逻辑序列攻击:在正常工作流程中,PLC和现场控制的发电机工作产生的数据包的序列都是有逻辑顺序的,通过修改数据包的次序来改变PLC和发电机的工作逻辑,数据集记为T2。
(3)转速值改变攻击:手动修改操作员站发送给PLC的数据来改变发电机的转速,数据集记为T3。
4.2 实验结果分析
为了能够更加准确的评估模型的性能,本文结合了分类的准确率和F1-score两个评价指标。分准确率和F1-score基于混淆矩阵计算,其中混淆矩阵如表2所示。
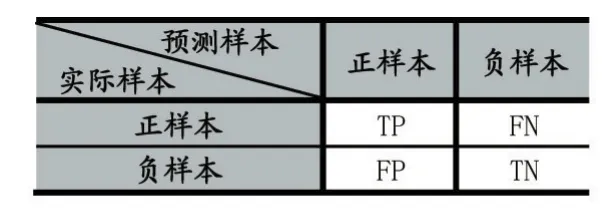
表2 分类器混淆矩阵
其中,TP表示实际和预测结果都是正样本类型的样本数。FN表示的是实际是正样本但是预测结果是负样本的样本数。FP表示的是实际是负样本但预测结果是正样本的样本数。TN表示的是实际和预测结果都是负样本的样本数。
分类准确率计算如公式(5)所示:

分类的精确度是表明测试集中被预测的正样本中为实际正样本的比例,召回率是表明被模型预测的正样本占总正样本的比例。由于精确度和召回率相互制约的,所以F1-score是精确度和召回率的调和值[13],计算如过程如式(6-8)所示:
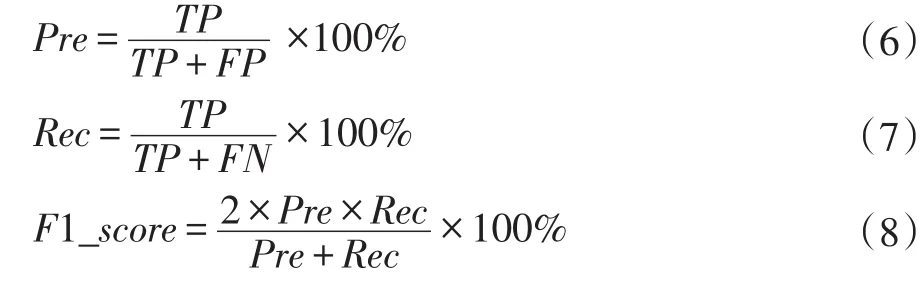
在模型训练阶段,用人工蜂群方法求得最优参数g=0.0123,C=0.462。本文对比了传统的OCSVM的准确率和计算时间,结果如图8和图9所示。相比于传统的OCSVM,本文的方法在降维之后依然保持着传统OCSVM异常检测的准确率,在数据集个数大于2000个时,传统的OCSVM算法和本文采用的主成分分析结合OCSVM算法模型训练的分类准确率都达到90%以上。但是在模型的训练时间对比中,传统的OCSVM算法消耗的平均时间比主成分分析结合OCSVM算法消耗的平均时间多46.45秒。
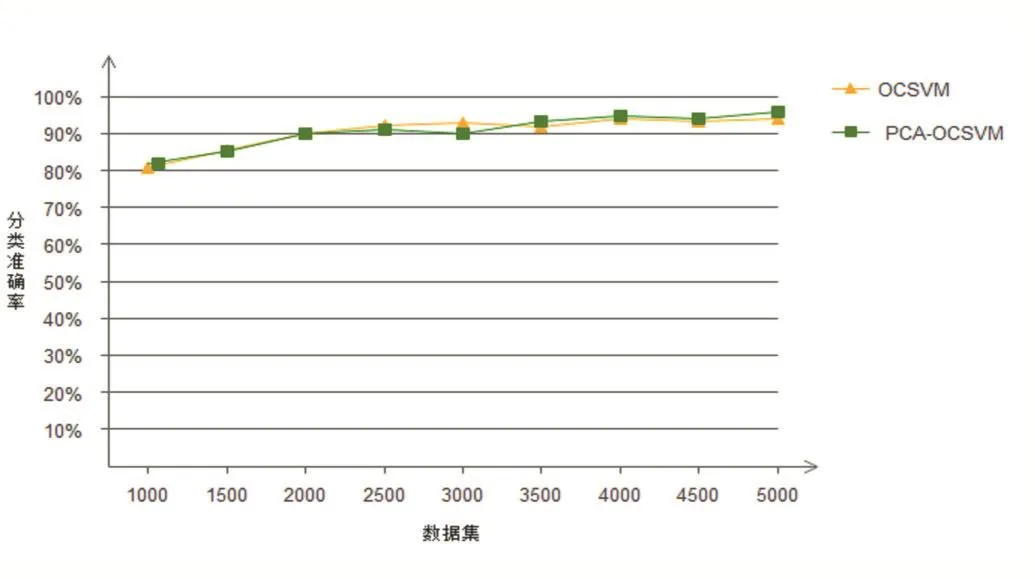
图8 训练模型的准确率
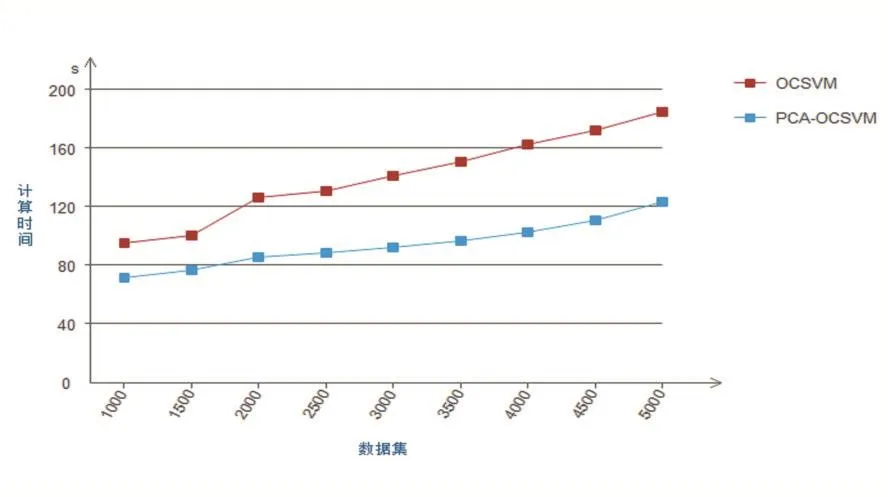
图9 模型训练时间对比
在使用相同用测试集T1,T2,T3的情况下,本文对比了传统OCSVM算法的分类准确率,F1-score和模型检测时间,如表3所示。
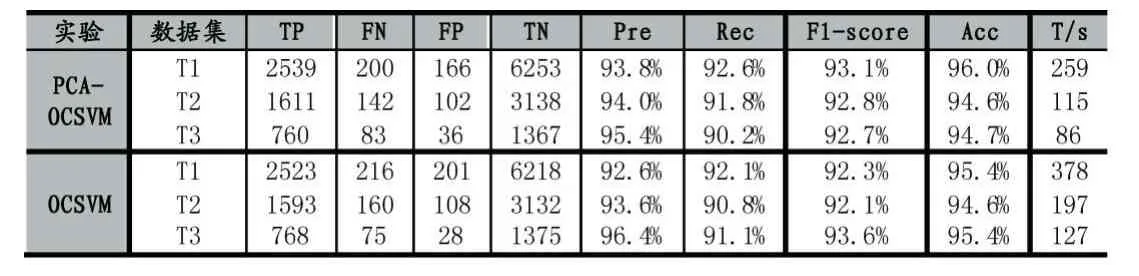
表3 异常检测结果对比
实验采集的三种攻击脚本下的数据集T1,T2,T3数据包总数分别为9158,4993,2246。使用主成分分析结合单类支持向量机的方法在分类准确率Acc和F1-score上都保持着传统支持向量机的90%以上的检测性能。但是在检测时间消耗方面,使用主成分分析结合单类支持向量机检测数据集T1,T2,T3比使用传统支持向量机检测分别少119秒、82秒和41秒。
5 结语
本文主要是以西门子S7协议为研究对象,针对实际情况下工控网络异常数据少,维数多的情况,在使用主成分分析法降维之后,采用单类支持向量机的方法来进行模型训练和检准精确度的同时,能有效减少模型运算时间的消耗。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
计算机与数字工程(2022年3期)2022-04-07
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
民用飞机设计与研究(2020年4期)2021-01-21
健康体检与管理(2021年10期)2021-01-03
物联网技术(2018年8期)2018-12-06
高中生学习·高三版(2016年9期)2016-05-14
