
卡口数据挖掘与城市道路交通分析
2019-03-01 03:01王蓓宁平华段小梅王世明司徒惠源
城市交通 2019年1期
王蓓,宁平华,段小梅,王世明,司徒惠源
(1.广州市市政工程设计研究总院有限公司,广东广州510000;2.广州市公安局交警支队,广东广州510000;3.香港大学,香港999077)
0 引言
城市道路交通量、车速、密度、通行能力和行车延误等是衡量城市道路服务水平、交通拥堵程度、交通基础设施布局合理性、交通管理水平等的重要依据。针对这些指标的调查方法有跟车法、浮动车法(基于GPS)、试验车法、人工观测法、机械观测法(传感器)、录像法和航拍法等。基于已有的调查方法得到的道路交通指标形成了庞大的调查指标体系[1],例如交通量指标体系、车速指标体系、道路通行能力指标体系和行车延误指标体系等。
随着交通电子设备的快速发展,道路交通调查手段越来越丰富,指标准确度提高,指标体系扩大。近年来,可收集大样本综合信息能力的交通电子设备被广泛应用[2],道路高清摄像卡口监控系统就是其中之一。高清摄像卡口被安装在各个公路、城市快速路和城市主干路上,全天记录经过的车辆信息并在线录入卡口数据库。卡口数据包括车辆出现的地点(卡口的地理位置)、时间、车牌和车型等信息,具有实时、大样本和高可靠性等特征。目前,卡口数据的分析和应用主要集中在违法车辆抓拍、套牌车检测和可疑车辆识别等方面[3]。然而,融合卡口数据中的地理、时间、车牌和车型信息进行交通调查分析,可获取例如道路截面交通量、行程时间和延误等传统的道路交通指标,甚至可推导传统交通调查手段无法获取的新兴中、宏观道路交通指标,例如车流轨迹特征指标和毗邻区域交通量。由卡口数据分析得到的道路交通指标可应用于交通工程的多个方面,包括城市道路交通系统规划、道路交通设计和道路交通管理等[4]。面对包含多元信息的卡口数据,设计什么交通分析任务、得到什么道路交通指标、以何种技术路线去实现,值得深入探讨。
1 卡口数据分析任务与技术方案
在卡口数据库中,一条数据至少包括以下字段:拍摄卡口、拍摄时刻、车牌和车型。因为卡口的地理位置是已知和固定的,拍摄卡口字段等同于空间地理位置。使用数据库工具对卡口数据按字段进行统计分析[5],可得到卡口所在道路截面交通量、车型比例和车辆来源地比例等常规交通调查指标。将卡口数据按照车牌分组并将每辆车经过的卡口以及经过的时刻按先后顺序排列,可得到所有车辆的卡口序列和对应的时刻序列。

图1 车辆卡口序列和区域序列示例Fig.1 Example of check point sequence and area sequence of a vehicle
基于Hadoop平台,采用JAVA编程工具对卡口序列和时刻序列进行分析可获得传统交通调查手段无法获取的交通指标。首先,卡口序列反映了一辆车经过的所有区域。统计所有车辆跨区的总次数可获得宏观的毗邻区域交通量。第二,卡口序列和时刻序列反映了所有车辆的时空轨迹。对特定车辆群体的卡口序列和时刻序列进行数据挖掘,发现规律,可判断车辆群在分析时段内的重点活动范围和行驶路径。第三,基于车辆卡口序列和时刻序列,可标记经过分析路段的车辆集合并获取车辆离开该路段的时刻和路段行程时间数据,获得多项路段运行指标,例如自由流平均行程时间、高峰平均行程时间、TTI指数①、全日平均速度、同一时刻车辆之间的最大行程时间差等。本文结合湖北省宜昌市的实例②对卡口数据分析任务和技术方案进行解释。
2 毗邻区域交通量分析
将城市划分为多个区域。对于两个毗邻且有道路连接的区域,在分析时段内从其中一个区域到另一个区域的车辆数量为单向毗邻区域交通量。毗邻区域交通量矩阵包含所有的毗邻区域交通量,是一个n×n的矩阵,n代表区域数量。矩阵元素vi,j代表从区域i到区域j的单向毗邻区域交通量,如果区域i与j毗邻且有道路连接,则vi,j≥0;否则,vi,j=0。使用传统交通调查手段无法获取毗邻区域交通量矩阵。以下介绍基于卡口序列得到毗邻区域交通量矩阵的方法。
每个卡口归属一个区域。将一辆车的卡口序列映射到区域序列。以图1为例,黑色实线代表道路,黑色虚线代表分区线,箭头线代表车辆行驶轨迹。该车的卡口序列为HJKA,映射的区域序列为①④⑧⑤。
在统计所有毗邻区域交通量之前,必须先校正区域序列。校正区域序列的主要目的是检查车辆是否在经过某些区域时被漏拍;如若有,补齐漏拍的区域。判定车辆在某些区域内被漏拍的标准有两个:一是车辆先后在两个不毗邻的区域内被拍摄到,二是车辆先后在两个没有道路连接的区域内被拍摄到。校正区域序列的方法如下:1)假设所有车辆选取最短路径到达目的地;2)检查一辆车的区域序列中的任意相邻一对区域是否满足毗邻且两个区域有道路连接的条件;3)如果一对相邻区域不满足以上任意一个条件,补充这对区域之间缺失的区域,补齐缺失区域编号使用最短路径算法[6]。以图1为例,区域对①④不满足毗邻条件,需在二者之间补充区域②;区域对⑧⑤不满足道路连接条件,需在二者之间补充区域⑥和⑦。校正之前的区域序列是①④⑧⑤,校正之后的区域序列是①②④⑧⑥⑦⑤。校正后的区域序列中任意一对相邻的区域之间有一次单向毗邻区域交通量。基于所有车辆校正后的区域序列,统计任意两个毗邻且有道路连接的区域在所有区域序列中作为相邻区域对出现的次数,可得到毗邻区域交通量矩阵。
将毗邻区域交通量矩阵图形化可得到毗邻区域交通量图,例如图2展示的是宜昌市中心城区的毗邻区域交通量图。将毗邻区域交通量矩阵中第i行的所有元素值相加,得到进入区域i的车辆总数si。将毗邻区域交通量矩阵中第i列的所有元素值相加,得到离开区域i的车辆总数di。定义si+di为区域i的区域交通活跃度,值越大表示区域i的交通活跃度越高。可按数值区间给区域交通活跃度分级。图3中红色部分是宜昌市中心城区交通活跃度较高的片区。毗邻区域交通量矩阵中元素vi,j和vj,i是区域i和j之间的双向毗邻区域交通量,将较大交通量与较小交通量的比值定义为区域交通平衡系数。平衡系数的最小值为1,代表双向交通量相等;平衡系数越大,双向交通量越不平衡。以宜昌市为例,大部分毗邻区域的区域交通平衡系数在1.2以内,双向交通量基本保持平衡。计算所有从区域i到j的道路的通行能力总和,得到毗邻区域通行能力ci,j。定义毗邻区域交通量与毗邻区域通行能力的比值为区域交通服务度。区域交通服务度是判断区域间道路连接是否足够的依据之一。
综上所述,卡口序列分析可得到毗邻区域交通量矩阵,以及毗邻区域交通量图、区域交通活跃度、区域交通平衡系数和区域交通服务度等指标。
3 车流轨迹分析
基于车辆卡口序列和时刻序列可查找特定车辆群频繁经过的卡口和经过卡口的顺序。车辆群频繁经过的卡口反映了车辆群的重点活动区域,频繁经过卡口的顺序反映了车辆群采用的重要路径。车辆群的选择由分析者决定,选择在分析时段内经过核查点卡口的车辆,并分析车辆群在抵达核查点之前以及离开核查点之后的重点活动区域以及抵达和离开核查点采用的重要路径。

图2 宜昌市中心城区毗邻区域交通量Fig.2 Inter-area traffic flow of Yichang central districts
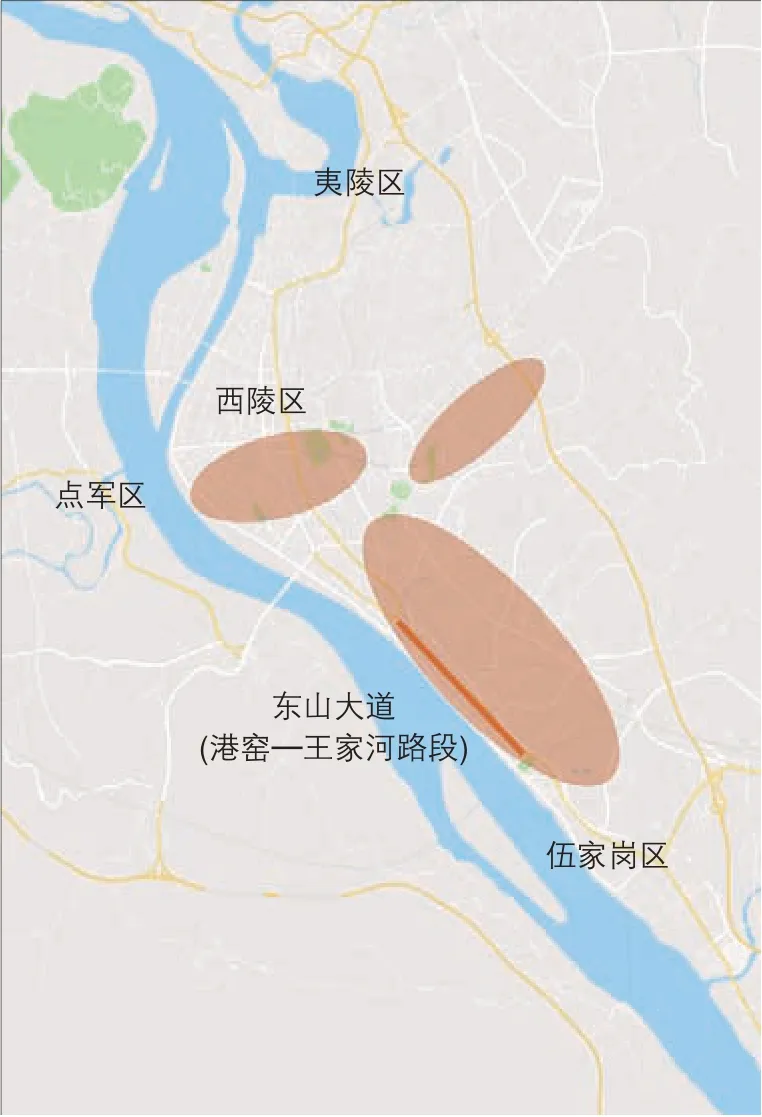
图3 宜昌市中心城区道路交通活跃片区Fig.3 Road traffic-active areas in Yichang central districts
定义分析时段和一个时间阈值m/min。假设核查点安装了卡口A。对每辆车的卡口序列进行条件判断。如果一辆车的卡口序列包含A且对应的拍摄时刻在分析时段内,标记该车。例如,一辆车的卡口序列为HJKASHSK,对应的时刻序列是t1t2t3t4t5t6t7t8。t4在分析时段内,标记该车。对标记车辆的卡口序列增加时刻约束,仅保留某时刻在核查点卡口(卡口A)对应mmin内的卡口。例如,t1,t7和t8皆不在t4的mmin内,则去掉HJKASHSK的第1个、第7个和第8个卡口,得到卡口序列JKASH。卡口序列中,卡口A及其之前的片段被定义为该车的上游子序列,卡口A及其之后的片段被定义为下游子序列。则上游子序列是JKA,下游子序列为ASH。
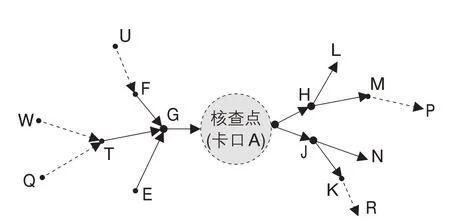
图4 m min频繁上游、下游卡口片段树杈图Fig.4 Branch diagram of m min frequent upstream and downstream check point sub-sequence
每辆被标记车辆的上游子序列的首个卡口反映了该车在抵达核查点卡口前mmin内最早经过的卡口,下游子序列的末尾卡口反映了该车在离开核查点卡口后mmin内最后抵达的卡口。定义一个卡口作为上游子序列首个卡口的次数与车辆群车辆数量的比例为mmin起点交通比例;定义一个卡口作为下游子序列末尾卡口的次数与车辆群车辆数量的比例为mmin终点交通比例。计算所有卡口的mmin起点交通比例可获得车辆群的mmin来源地分布,计算所有卡口的mmin终点交通比例可获得车辆群的mmin抵达地分布,进而获得重要mmin来源区域和重要mmin抵达地区域。
对车辆群的上游子序列和下游子序列进行频繁模式挖掘(frequent pattern mining),并制定关联规则[7]。上游和下游子序列中出现次数超过自定义阈值的卡口片段分别反映了车辆群抵达核查点前的mmin重要来源路径和离开核查点后的mmin重要去向路径,本文定义为mmin频繁上游卡口片段和mmin频繁下游卡口片段。采用GSP算法,得到所有mmin频繁上游、下游卡口片段。将所有mmin频繁上游、下游卡口片段用树杈图表示。以图4为例,mmin频繁上游卡口片段包括UFGA,FGA,GA,WTGA,TGA,QTGA和EGA,代表了mmin重要来源路径;频繁下游卡口片段包括AH,AHL,AHM,AHMP,AJ,AJN,AJK和AJKR,代表了mmin重要去向路径。
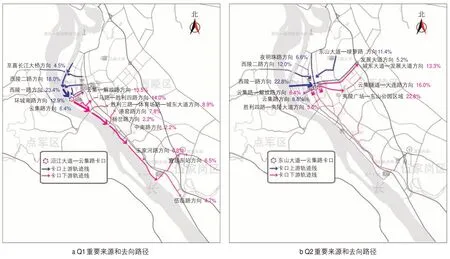
图5 车辆群Q1和Q2的15 min重要来源路径和去向路径Fig.5 15-min frequent from-and-go routes of vehicle groups Q1 and Q2
以宜昌市为例进行车辆群分析。选定云集路—沿江大道交叉口的卡口A为核查点1,云集路—东山大道交叉口的卡口B为核查点2。本案例有两个研究对象:1)沿着沿江大道从北向南被卡口A拍摄的车辆群Q1;2)沿着东山大道从北向南被卡口B拍摄的车辆群Q2。图5展示了车辆群Q1和Q2的重要来源路径和去向路径。图6展示了车辆群Q1和Q2的15 min来源地和抵达地分布。观察可得,从北向南经过卡口A的车辆多数来自北侧紧邻长江的片区和江对岸片区,多数沿着沿江大道前往南侧临江片区和向南出城;从北向南经过卡口B的车辆多数来自离江中心城区内的多个小区和片区,分成多个方向前往多个片区。该案例揭示了沿江大道主要服务于临江片区中长距离出行的用户,东山大道主要服务于离江地区中短距离出行的用户。
综上所述,基于卡口序列可以获得特定车辆群在抵达核查点卡口之前的mmin来源地分布、重点来源区域和重要来源路径,以及离开核查点卡口之后的mmin抵达地分布、重点抵达区域和重要去向路径。
4 道路运行状况分析
基于卡口序列和时刻序列可以获取经过分析路段车辆的行程时间以及车辆离开该路段的时刻数据,并进行路段运行状况分析。前提条件是分析路段的起点和终点都安装了卡口。以图7中的城市快速路为例,卡口A和卡口B分别安装在路段的起点和终点,路段中可能还安装了其他卡口,例如卡口C和卡口D。对每辆车的卡口序列进行条件判断,判断条件为:卡口序列是否含有ACDB的片段。假如有,则获取该车在卡口A和在卡口B的拍摄时刻间隔作为该车的行程时间,以及该车在卡口B的拍摄时刻作为离开路段的时刻。
所有经过路段的车辆的行程时间和离开时刻都可以通过以上方法提取,并形成数据集合φ。然而,根据此方法提取的数据有可能包含了噪声数据。噪声数据的存在是因为部分车辆不是连续地从卡口A所在断面行驶到卡口B所在断面,而是从中间的其他出口(如图7中其他出入口道)离开、经过一定时间后再进入路段。这类数据属于噪声数据,必须剔除,否则会影响行程时间分析结果的准确性。噪声数据清洗算法一般分为两个步骤:1)将全日内行程时间绝对值过高和过低的数据剔除。例如,95%数据的行程时间都在800 s以内而有一个数据的行程时间是2 000 s,则剔除该数据;2)将不同时间区间内行程时间相对值过高和过低的数据剔除,例如在0点到1点间,数据的行程时间集中在200 s而有一个数据的行程时间是600 s,则剔除该数据。经过清洗的数据可以形成路段行程时间-时刻散点图。0:00—6:00的平均行程时间为平均自由流时间,结合路段长度可得到平均自由流速度。观察行程时间高峰和平峰,可获得高峰(平峰)的平均行程时间和速度、行程时间高峰(平峰)对应的时刻、高峰(平峰)持续时间、高峰(平峰)最长行程时间以及最短行程时间等。同一个时刻的最长行程时间减去最短行程时间等于行程时间带宽,反映了行程时间的最大差异。另外,可获得的指标还包括TTI指数、道路运行等级(反映道路拥堵水平)等。
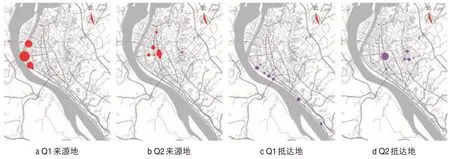
图6 车辆群Q1和Q2的15 min来源地和抵达地分布Fig.6 15-min origin and destination distributions of vehicle groups Q1 and Q2
以宜昌市东山大道的南部港窑—王家河路段作为研究对象,其位于中心城区边界处,港窑位于北侧,王家河位于南侧,该路段中间有交叉口可出入东山大道。获取该路段的行程时间-时刻散点图(见图8)。由图8a可以看出,北向南道路凌晨时段(0:00—5:00)的车辆行程时间为400 s左右。日间(6:00—18:00)车辆行程时间集中分布在420~720 s,行程时间带宽为300 s。日间无通行时间高峰,TTI指数为1.5。另外统计得到港窑和王家河道路截面北向南全日交通量分别是2.1万pcu和1.1万pcu,说明至少有50%从港窑出发的车辆并没有抵达王家河,而是从港窑和王家河中间的其他出口离开。结合行程时间指数特征,可得出东山大道港窑—王家河路段全日交通量不大、交通不拥堵。由图8b可以看出,南向北道路凌晨时段的车辆行程时间集中在400 s左右,日间出现两次行程时间高峰。高峰行程时间集中在750~900 s,带宽为150 s;非高峰行程时间集中在500~700 s,带宽为200 s。高峰TTI指数为2.0。另外统计得到王家河和港窑道路截面南向北全日交通量分别是1.3万pcu和1.6万pcu,说明有少量的车辆在王家河和港窑之间的其他入口进入东山大道。结合行程时间指数特征,发现该路段的特征是交通量低、早晚高峰延误高,意味着南向北道路在早晚高峰时段处于拥堵状态。

图7 城市快速路卡口示意Fig.7 Check points on urban expressway
可以看出,东山大道港窑—王家河路段的双向道路运行状况差异明显。该路段虽然位于中心城区边界,但王家河不是重要交通吸引地,从港窑到王家河的交通需求小,因此北向南道路不拥堵。作为重要的入城通道,南向北道路有典型的早晚拥堵双高峰。造成双向道路运行差异的原因与宜昌市的城市道路分布和城市功能分区紧密相关,在此不做深入探讨。另外,行程时间带宽代表车辆的停车延误(包括信号灯延误和等待行人过街时间)。双向道路的行程时间带宽均在150 s以上,北向南带宽高达400 s以上。应考虑采用信号灯绿波带、设置人行天桥等措施减小停车延误。
综上所述,基于卡口序列和时刻序列可获得分析路段的行程时间-时刻散点图,并得到一系列指标作为交通分析的重要依据。
5 卡口数据道路交通分析框架
机动车的卡口序列和时刻序列数据包含城市所有机动车的移动轨迹,隐藏着大量珍贵的道路出行规律,亟须有效的技术手段将其获取。以上介绍的3个分析任务和技术方案仅仅是冰山一角。然而,卡口数据挖掘与城市道路交通分析在学术研究和工程应用中依然是新兴技术,没有统一的行业技术标准。
通过研究和实践,本文总结提出B2T(Bottom to Top)流程,指导卡口数据分析,也可以伸延到其他类型的交通数据分析。B2T流程包含三大步骤,涉及四个层面(见图9)。步骤1:通过统计方法和数据挖掘算法从海量、多元的数据层提炼出各式各样的交通指标,得到指标层。步骤2:对指标层中的交通指标进行专业解读,得到城市出行特征信息,指导工程应用。步骤3:对信息层进行归纳提炼,得到深层次的出行规律。数据层是整个信息金字塔的最底部,规律层是最上层。数据分析即由下向上提炼信息,得到信息金字塔最顶部、最有价值信息的过程。

图8 东山大道港窑—王家河路段车辆行程时间-时刻散点图Fig.8 Travel time and time of day relationship at Dongshan Avenue(Gangyao-Wangjiahe Section)
在信息金字塔中,指标层的获取最为复杂。首先,指标层是连接数据层和信息层的重要媒介。已有的交通调研指标体系固然重要,但新兴交通指标体系更能体现数据挖掘的优势,展现数据的潜在信息价值。第二,从数据层到指标层的转化是一个开放的探索过程,没有传统、固定的数据挖掘流程,数据挖掘算法也并非一成不变。第三,指标层的获取同时受到数据层和信息层的制约。能提取的新兴交通指标未必有信息价值,有信息价值的传统、新兴交通指标可能无法通过已有的数据挖掘算法提取。确定新兴交通指标体系、制定分析任务、设计和测试挖掘算法是一个反复尝试、不停迭代的过程。同时,亟须一个可扩展的交通分析框架去总结已有的尝试成果,为未来的行业技术标准化打下基础。
本文提出卡口数据道路交通分析框架,分为3个部分:数据分析、指标体系和工程应用(见图10)。数据分析是核心技术部分,包含分析任务(例如前文提及的3个分析任务)以及实现任务的统计方法和数据挖掘算法(本文中未作深入展示)。指标体系包含数据处理后得到的交通指标,例如本文提及的从三大分析任务中得到的具体指标。工程应用是深入剖析指标体系隐藏的交通现象和规律,并用其指导实际的城市交通规划、建设和管理项目。例如,本文提及的宜昌案例中的道路交通分析结果,可作为基础现状信息在宜昌市城市道路交通建设中起到指导作用。卡口数据道路交通分析框架可扩容,可添加新的数据分析、指标体系和工程应用,为卡口数据挖掘与城市道路交通分析的行业规范制定提供基础。
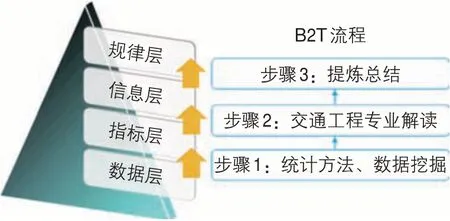
图9 B2T流程Fig.9 B2T procedure

图10 卡口数据道路交通分析框架Fig.10 Analysis framework of traffic camera data-based road traffic
6 结语
卡口数据分析不仅可以用于交警执法,还可用于城市交通规划、建设和管理。本文分别从毗邻区域交通量、车流轨迹和道路运行状况层面进行分析,提出一系列传统交通调查手段无法获取的交通指标,例如区域交通活跃度、区域交通平衡系数、区域交通服务度、mmin车辆来源地和抵达地分布、重要来源和去向路径、道路最短和最长行程时间、道路行程时间带宽等。结合湖北省宜昌市的数据,展示了宜昌市中心城区的交通量分布特征、重点核查点的车流来源和去向特征,以及重要城市道路的双向运行特征比较等。这些数据分析成果可以帮助城市综合交通体系规划、交通专项规划、建设项目交通影响评价、交通需求分析和预测、建设项目交通后评估、交通改善设计和实施、交通运行评估和智能交通管控平台的建设等。
注释:
Notes:
①交通时间指数(Travel Time Index,TTI)是美国《道路通行能力手册》(Highway Capacity Manual)收录的用以评估道路交通拥堵程度的指标,等于高峰行程时间除以自由流行程时间,值越大代表道路越拥堵。
②卡口数据来源于湖北省宜昌市公安局交警支队。
猜你喜欢
工会博览(2022年5期)2022-06-30
中国交通信息化(2022年4期)2022-06-17
建材发展导向(2019年11期)2019-08-24
中国交通信息化(2019年12期)2019-08-13
摄影之友(2018年12期)2018-12-26
中国交通信息化(2018年6期)2018-08-29
中国交通信息化(2017年5期)2017-06-06
北方交通(2016年12期)2017-01-15
公民与法治(2016年16期)2016-05-17
中国交通信息化(2015年6期)2015-06-06
