
基于大数据技术的水情云数据中心设计与研究
2019-02-27 03:43:26邱超许金涛元晓华
浙江大学学报(理学版) 2019年1期
邱超,许金涛,元晓华
(1.浙江省水文局,浙江杭州310009;2.浙江大学环境与资源学院农业遥感与信息技术应用研究所,浙江杭州310058)
随着浙江省水情信息化建设的大力推进,全省水情数据量已扩展到TB/PB级,包括地形地理数据、水利工情数据、高频次海量遥测及人工的实时与历史水雨情数据、水文预测预报数据等结构化数据和遥感图像、重要河道断面图像视频、水文分析总结成果文档等非结构化数据两类。传统的数据采集和存储管理方式已不适应当前对应用数据的需求。从应用角度看,水情数据是水利防汛的重要信息来源。随着“以人为本”防汛理念的提出,对防汛的要求日益提高,特别是近几年极端气候频发,河流源短流急,小流域山洪具有突发性、水量集中流速大、冲刷破坏力强等特点[1],势必对水情数据管理系统的运行效率有更高的要求。全国大数据战略的提出,为水情大数据中心的建设提供了很好的发展契机,相关技术也已相对成熟[2-3]。充分运用成熟的大数据存储、管理、挖掘分析技术,建设水情云数据中心,为后续水情信息的信息化推进及数据挖掘共享提供强大的动力。
1 国内外研究进展
近年来,遥感、遥测等信息收集技术在水文领域的快速发展与大量应用,极大丰富了水情数据的时间尺度、空间尺度以及数据类型,水情数据量急剧膨胀,种类趋向多元化。
水情数据中心用于管理的这些高频异构水情数据,是搭建水信息资源共享环境与服务体系的核心,亦是推动我国水利行业精细化、现代化管理的必要条件。早在2008年初,水利部便印发了《水利数据中心建设指导意见》,制定了《国家水利数据中心建设基本技术要求》。如今,各地水利数据中心建设成绩斐然。
广东省水利数据中心作为国内首个省级水利数据中心,建立了存储结构化数据的25类数据库、存储非结构化数据的分块云存储和多级元数据存储,整合了各类信息资源数据记录和GIS图层水利数据专题要素,实现了全省的数据交换共享平台。统一的数据标准、标准的服务模块与接口、高效的水情数据处理及发布共享,极大提高了广东省水利工作的效率,同时也形成了丰富的成果[4-5]。吉林省为建设水情数据中心,规范全省水情数据的统一标准、统一格式、统一管理,初步做到了水情数据的互联互通和资源共享[6]。山东省水情数据中心将运营管理平台部署在云服务器上,云平台为数据中心分配虚拟机,并为应用系统建设分配数据库和数据库容量,创建中心文档库,存储非结构化数据[7]。
目前,研究者已着于从技术层面优化水情数据中心的架构和部署。马泽生等[8]围绕低碳能效型水情数据中心的建设,利用虚拟化技术整合服务器、存储器、网络等基础设施,将水情数据中心的利用率提高至80%以上。吴涵宇等[9]采用物理迁移与逻辑迁移的方式汇集异构的、分布式水情数据,并以GIS空间数据为框架,通过统一的数据模型和对象编码,构建物理集中与逻辑映射相结合的数据库群,对数据中心的数据资源进行管理和维护。王海峰[10]探索了物联网、虚拟化和云计算等技术在宁夏水利数据中心的应用。陈德清等[11]将网格技术用于水利数据中心的异构数据库的数据集成,实现了分散数据的集成访问和应用。胡金龙等[12]对水情数据中心的数据交互以及应用服务技术做了研究,为异构数据库之间频繁的数据汇集问题、数据中心不同用户节点的数据共享问题等设计了解决方案。龚琪慧等[13]总结了水利大数据架构、实时数据处理和元数据等关键技术,提出了传统关系型数据库与分布式文件系统相结合的水利数据中心架构。杨楚骅[14]以广州市水利数据中心建设为例,提出了基于面向服务架构的水利地理信息数据中心的建设思路,给出了水情数据的整合与共享建议。
存储、处理、分析高频且异构的水情数据并不容易,传统的数据仓库等技术均无法胜任。过去10年,大数据技术在数据存储、分发、查询和分析上取得了重大进展。计算机及数据领域的学者开发了许多工具,用于操控大型数据集。例如稳定地汇集和传输海量异构的数据、快捷地查询数据、高效地分析发布数据等。SHAFIEE等[15]将大数据技术用于水情系统中的水情数据汇集和分析模块,并对数据中心的高效自动化数据汇集以及异构数据的建模进行了展望。HU等[16]使用基于Hadoop的云计算技术和基于多项式混沌扩展的方差分解方法,利用大量大规模的水文模型和异构水情数据,评估流域地下水位的下降程度,计算和处理速度较传统方法提升了500倍。
将大数据、云平台等技术运用于水情数据中心,是国内外水文行业研究和应用的热点。本文研究了先进的分布式水情数据采集技术、智能数据过滤技术、大数据存储技术,以浙江省为研究区域,将分散的水情数据进行整合,实现对水情大数据的质量控制、深度挖掘和高效共享,以满足水利业务和事务的现代化发展需要。
2 浙江省水情数据现状
目前,浙江省水情数据中心总数据量已达PB级,日处理数据量在TB级以上,主要包括以下几方面数据:
2.1 全省高精度的地形、地理数据
全省地形、地理数据主要包括:全省万分之一的地形数据(局部地区分辨率达100 m)、高精度的河道数据、水情站点及水利工程分布数据、行政区划数据、地形数据等,总数据量达到TB级。
2.2 高频次海量实时遥测水雨情数据
遥测站点的数量、采集频次及要素均发生了质的变化:(1)遥测站从初期的几百家增加到现在的6 000家左右,增加了10多倍。(2)采集频率也从以前的1次·h-1提高到现在的0.2次·min-1,个别潮位站点甚至提高到 1次·min-1,增加了 12倍以上。(3)采集要素从最初的雨量水位,到现在的流量、蒸发、气温、气压等,要素量也增加了2倍以上。
这些变化导致数据量增加了240倍以上,数据量从以前的年GB级增加到现在的TB级,日处理遥测数据量也在GB级以上。
2.3 不断增长的历史水情数据
已存有从20世纪50年代至今60多年的水文历史数据,包括文本数据、图片扫描数据以及经整编的水情结构化数据,数据量已达TB级以上。近年来,随着站点的不断建设,数据呈指数级增长。
2.4 每年更新的全省河道断面及河道地形数据
2010年,浙江省开展了分布式洪水预报系统的建设,对主要河流进行了洪水预报。该系统需高精度的河道断面数据和河道地形数据做支撑,目前数据量已达TB级。随着全省主要流域分布式洪水预报建设的发展,河道断面及地形数据将以指数级递增,急需一个支持大数据的存储系统。
2.5 高频次多波段大尺度遥感卫片数据
浙江省近年引入了遥感数据分析系统,对全省的灾情和旱情进行实时监视。遥感系统每天会接收10 GB以上的原始数据,对数据进行分析处理,生成各类分析专题图表。随着系统开发的深入,遥感数据量越来越大,现有的存储和分析系统将面临较大的运行瓶颈。
2.6 大量非结构化的水文分析和总结文档
当前,省、地市及县级水文分析成果都汇集到现有的水情中心,其中含有大量文档、图片和视频材料等非结构性数据。目前所用的结构化分析方法已无法满足异构数据深度分析的要求,只有采用深度数据挖掘技术以及非结构化存储方式,才能对从异构数据中挖掘到的有价值的信息进行高效科学的分析。
3 系统建设主要内容
本研发系统将采用大数据存储分析技术,通过全面整合分散的各类水情数据,实现对大数据量水情信息的深度挖掘分析,生成科学的分析报告。对有价值的信息资源进行资源共享,以满足新形势下水利防汛对水情业务的要求。系统总体架构如图1所示。

图1 系统总体架构图Fig.1 The overall architecture of the system
水情云数据中心建设,主要包括以下内容:
3.1 分布式水情信息采集子系统
水情信息资源中心需对不同来源的异构数据进行实时汇集,主要包括采集数据、基层节点数据及其他领域交换的数据。采用数据实时抽取技术,对多源、异构、多时空尺度数据进行动态抽取和集成,生成标准化的数据存储结构,并统一存储在混合型的存储系统中。
3.2 海量水情信息存储子系统
水情大数据中心架构将对结构性数据存储系统和非结构性数据存储系统进行融合,共同支撑水情大数据存储。2种存储系统之间可以通过抽取转换进行相互通讯,实现数据的无缝对接。并采用元数据技术,对各种数据进行描述和定义,为系统提供更高的可用性和易有性。
3.3 水情信息分发子系统
系统可通过高效的数据分发机制,通过数据的分发定制功能,将应用端定制的各种水情信息资源实时分发到各个应用部门或社会相关机构,为各服务对象提供高质、高效的数据资源支持。
3.4 水情云数据中心管理平台
用户通过PC端或移动终端,对水情云数据中心平台进行在线管理和监视。管理用户可在线监视系统运行的各项参数,同时可设定一些关键参数,及时监控预警,确保系统正常有序运行。
4 系统建设关键技术及难点
4.1 分布式水情数据采集
采用分布式采集技术可采集到各类与水情相关的数据,水情数据种类繁多,按格式分,有:(1)结构化数据,例如实时水雨情数据、水文预报数据、数值降雨预报数据、工情数据、采集设备状态数据等;(2)半结构化数据,例如卫星云图、卫星降雨数据产品、卫星土壤墒情数据、卫星洪水淹没监测数据、多普勒雷达数据、台风路径数据、气象数据产品等;(3)非结构化数据,例如视频监控影像、地质灾害预警报告、水文专题总结报告、无人机采集影像数据等。按数据来源分,有水文行业自有数据(水雨情数据、水文分析数据等)、合作方提供数据(如气象局)和公共数据资源(如互联网上抓取的气象产品及地理信息等)。
采集子系统的功能架构如图2所示,覆盖数据从标准化预处理、抽取、校验、过滤、清洗直至加载到大数据存储系统的全过程。
分布式数据采集子系统可以针对不同的数据源类型和格式,提供多种数据抽取方式与之适配,例如数据库直连、Web service接口连接、RESTful API调用、共享文件读取、FTP服务器文件下载、文件导入、手工录入等,并对数据进行校验、清洗、加载等操作,最终将数据存储到大数据存储子系统中。
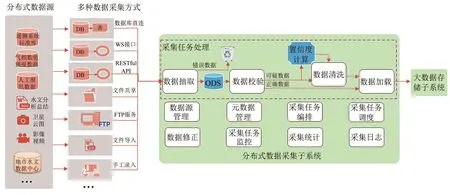
图2 分布式数据采集子系统架构Fig.2 Architecture of distributed data acquisition subsystem
针对不同的数据类型,采取不同的引擎实现多源、异构、分布式数据采集。水文大数据的采集任务由Datahub流式数据采集引擎和阿里云StreamCompute流式处理采集引擎共同完成。
4.1.1 流式采集引擎
相较传统的以SDK或服务的形式采集数据的方式,流式采集引擎具有高吞吐、低延迟、单条任务TB级别的写入能力,配置更灵活,且接口简单,可满足不同的场景需求。
针对数据源格式多样、复杂的特性,批处理采集任务可采用定制的ETL(extract transform load)工具来实现,使用Java开发框架并利用JVM实现一次开发多平台(不受操作系统局限)使用。ETL工具数据流设计示例如图3所示。
ETL工具的另一优势是不仅完美支持结构化数据,而且也支持半结构化、非结构化数据,且以文件的形式采集进入大数据存储平台。开发的采集任务以JAR形式打包,已运行在多台云服务器ECS中,并通过了元数据管理。采集子系统操作界面提供JAR包的调用配置,由门户配置调度系统提供的定时轮询触发执行采集任务。
图3 ETL工具数据流设计Fig.3 Data flow design using ETL
4.1.2 流式处理引擎
与批处理引擎擅长处理离线数据不同,流式处理引擎由存储和计算2个模块组成,擅长实时处理[17]。阿里云最新一代的流式引擎Blink是一种较为纯粹和完善的流计算技术,在理论模型上具备了流计算的所有特质。StreamCompute为以Blink流式计算引擎为核心技术构建的流式计算框架,满足了海量数据实时分析的需求。StreamCompute流式计算框架的数据源可不断更新,即收到一条数据处理一条[18]。通过StreamCompute提供可靠的处理无限数据流能力,可实时进行数据清洗,同时还可实现对视频流的实时处理和专业模型的实时计算。
4.2 原始采集数据质量控制
在通过分布式采集技术采集的数据中,存在大量不合格或错误数据,通过建立数据质量管控体系对进入系统的数据进行有效管理。
4.2.1 数据质量分类
按等级分,数据可分为错误数据和可疑数据,见图4。系统有针对性地采取不同的处理策略对校验后数据构建完整的质量管控体系。
4.2.2 数据质量管控流程
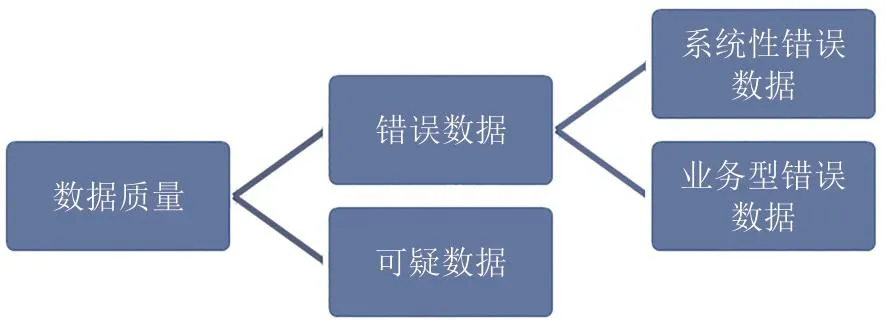
图4 数据质量分类Fig.4 Data quality classification
错误数据可分为系统性错误数据和业务型错误数据,系统性错误数据(如测量时间明显错误)会直接被拦截,原始水文数据在ODS临时存储中,保留其原始数据格式。其他数据在进入系统前不会被拦截和过滤,而是在根据配置信息对其进行校验后标注数据质量(校验置信度的计算并标注),根据标注的数据质量(是否为业务型错误数据)由下一环节对其进行过滤,过滤后的数据进入后续处理环节。业务型错误数据根据基于简单的上下限区间设置来判断。由系统提供的规则配置页面按站点的错误数据上下限进行配置,操作界面的测站数据类别略有不同,如雨量、河道、水库、潮位、日蒸发量、河道均值、水库均值、降水量等。具体流程如图5所示。
4.2.3 可疑数据校验算法
有别于错误数据,对采集的可疑数据的处理原则是先放行,但要有可疑数据警示标注。过去的可疑数据校验与错误数据校验方法类似,基于预先设定好的可疑上下限参数配置采用一刀切方法,无法准确计算数据的有效性。
如图6所示的水位过程线,B点的数值虽然超出了可疑上限设置,但相对于当时的水位来说,数据质量无任何问题。从对应的测量时间点来看,A点所标注的测量数据显然是错误的,但仅依赖固定边界值尚无法准确甄别可疑数据。
新的水文数据资源中心将采用更智能的校验算法检验实时水雨情数据质量。如对上文描述的质量管控场景,可采用移动均值等时间序列平滑预测手段,结合对数据偏离度上限的配置进行更加准确科学的数据质量智能校验。
应用智能算法,校验上文描述场景的效果改良示意图见图7。

图5 数据质量管控流程Fig.5 Process of data quality control
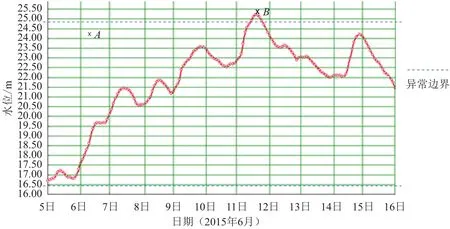
图6 传统的可疑数据校验Fig.6 Traditional suspicious data validation
除时间序列预测方法在数据质量校验中的应用外,系统还提供其他定制开发的智能数据检验算法,将复杂的算法与雷达、云图、周边站点、空间位置及上下游关系相结合,专门建立相应的质控模型,进行数据质量的挖掘分析。
4.3 大数据存储
水文数据中心采用关系型数据存储、分布式NoSQL数据库存储和分布式文件对象存储相结合的方式,支持不同的数据类型(结构化、非结构化、半结构化)。3种数据库对应的公有云服务组件分别为RDS关系型数据库、TableStore表格存储以及OSS对象存储。
4.3.1 RDS关系型数据库存储
RDS是传统关系型数据库的云端服务化实现,可提供与传统关系型数据库完全一致的功能。平台将采用与源数据相同技术的RDS for SQL Server,将校验失败的采集数据,按源数据格式原封保存。
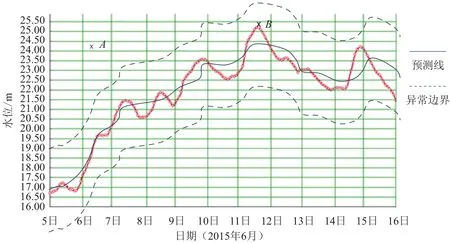
图7 可疑数据智能校验Fig.7 Intelligent verification of suspicious data
4.3.2 TableStore表格存储
表格存储服务中的数据存储模式可类比开源技术中的Hbase,是基于键值(key-value)实现的大数据宽表存储。不同的键值将按取值范围分配到不同的存储单元,由集群底层架构实现分布式存储及备份,并对键值建立高速索引。水雨情遥测数据通常以“时间+站点”作为key值,数据采集频率高且数量惊人,非常适合表格存储的行键(rowkey)特性实现高速写入及扫描,实现数据的海量存储及高效调用。
4.3.3 OSS对象存储
对象存储可以简单理解为一个云端的文件磁盘,用来存储数量庞大的文件。同时,公有云对象存储还可提供针对多媒体数据的便捷操作服务,如视频数据的编码解码、图像文件的直接调用等。
4.4 水情云数据中心管理
管理中心为各类用户提供统一和便捷的数据访问及系统管理入口。用户角色类型包括各级系统管理员、各类相关部门用户、访客等,并支持自定义角色和权限。
对于非结构化数据的管理,云平台采用Hadoop中的分布式文件系统(Hadoop distributed file system,HDFS)。HDFS具有高容错性、高吞吐量等特点,能对PB级数据进行快速并行处理,且成本较低。对半结构化数据,在云平台上部署NoSQL服务进行存储管理;对结构化数据,继续使用传统的关系型数据库。这些数据库服务均部署在云上,通过集成融合平台进行集中管理,需要时,通过共享交换平台提取。
4.5 可配置的数据分发
水文数据中心需要实现定制化的业务数据分发,并提供界面进行管理。系统满足分布式数据分发的特点,只要互联网能联通,就能执行数据分发或调用请求。需通过统计手段对水文数据资源分发与调用的种类、数量、效率等指标实现监控。根据实际情况,以可配置方式设定调用数量,提高数据的安全管控能力。
5 系统建设创新点
5.1 水情数据的分布式汇集
以结构化水情数据的汇集为例,传统的数据汇集思路是基于数据集中的物理整合,本文所采用的整合方式是基于服务的逻辑数据。这种分布式的数据汇集方式不强求物理上的集中,而是将各个数据源的数据通过接口包装成服务,注册到服务总线,通过服务总线提供统一的数据服务,实现数据在逻辑上的整合。
5.2 基于元数据的多源异构数据集成
传统的水情数据中心仅支持结构化的关系表数据,难以存储多源、非结构化的数据。本文设计的水情云数据中心支持多数据源、异构数据,能管理多个物理数据源,数据源之间可以无缝集成。
针对本数据中心所提供的各类服务,将以元数据的方式进行描述,并建立相应的注册机制,在多用户、多平台、多数据源的复杂异构环境下,实现数据共享和数据集成。异构数据集成共享机制主要包括一个中心元数据服务器和多个分布式数据服务器以及远程客户端,元数据服务器包含所有用于共享的异构数据元数据,各个数据服务器则存储共享的异构数据,用户在远程客户端通过分布式网络数据,先访问元数据库,通过对元数据的解释,选择合适的数据接口访问存储在不同数据服务器中的异构数据。
5.3 以数据为中心的业务联动(DDA架构)
基于全局共享交换的需求建设水情大数据中心,旨在通过大数据技术打通内外部数据中心之间的共享壁垒,完成数据的高效共享,提高数据集成度,通过数据融合实现业务融合。更进一步,水情大数据中心通过数据驱动业务的方式,对基于大数据中心精心设计的业务系统,通过数据事件直接驱动业务逻辑运行,为各业务应用系统难以横向拓展这一难题提供一站式解决方案。
5.4 以平台为基础的大数据分析服务
水情大数据分析平台实现了水情信息资源的综合深入利用,多层面挖掘数据价值,实现大数据应用,为决策和管理提供技术支撑。平台提供大数据分析的基础服务,能够快速按需部署分析集群。其主要功能是将数据中心的业务数据按业务主题进行重新组织,建设统一的大数据分析平台,利用分布式数据库、信息处理等技术,针对水文状况进行统计分析,并进行成果资源转换。建立面向主题的数据仓库或数据集市,并通过前端展现工具以查询分析结果、固定格式报表以及灵活分析报表的形式展现给最终用户。
大数据分析平台和数据资源中心是大数据挖掘和智慧分析的基础支撑平台。大数据平台可以整合数据查询、数据集成、机器学习、数据可视化等高级组件和服务。通过客户分析模型与经营分析模型,实现区域、单位、项目等多维度分析,形成数据钻取、数据联动等多种分析效果。
6 总结
基于大数据云平台技术的浙江省水情云数据中心,对多源异构数据的高效汇集、存储和应用进行了全新设计,并进行高可靠性的数据质量管控,显著提升了水情数据资源的质和量。云数据中心的数据流转效率较原数据中心提高了2倍多;数据质量的管控水平亦显著提高;数据挖掘分析能力有了质的飞跃;特别是多源异构数据集成后的大数据中心,为拓展水情分析的深度和广度、提升综合分析能力、丰富水情的社会化服务产品、提供更为科学的决策依据奠定了坚实的数据基础。
猜你喜欢
小学教学研究(2022年5期)2022-04-28 21:29:36
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
军营文化天地(2017年10期)2017-12-05 10:27:39
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
水科学与工程技术(2016年6期)2016-02-27 13:29:18
计算机工程(2015年8期)2015-07-03 12:20:35
汽车零部件(2014年10期)2014-11-11 12:25:04
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:32
