
一种面向移动终端地理场景点云在线可视化的集成型索引
2019-02-27 03:43:26邱波张丰杜震洪刘仁义张书瑜范心仪
浙江大学学报(理学版) 2019年1期
邱波 ,张丰 *,杜震洪 ,刘仁义 ,张书瑜 ,范心仪
(1.浙江大学浙江省资源与环境信息系统重点实验室,浙江杭州310028;2.浙江大学地理信息科学研究所,浙江 杭州 310027)
0 引 言
点云数据作为三维GIS(地理信息系统,geographic information system)重要的数据来源之一,具有获取方便、精度高等特点,实现大规模点云数据的快速可视化对地理场景的建立与表达具有重要意义,而可视化的基础是高效的点云数据组织管理方法。
目前,已有大量学者对点云数据的组织管理方法展开了研究,这些研究多以树形结构为基础,可以细分为基于单一树形索引和基于集成型树形索引2种。(1)在单一树形索引的研究中,国内外研究者大多针对该树形结构问题做优化,如四叉树与Hilbert曲线融合以减少索引构建时的I/O开销[1]、支持点云LOD(多细节层次,levels of details)模型扩展的八叉树[2-6]、改进结点编码与解决数据分配不均衡的八 叉 树[7-8]、节 省 内 存 占 用 的 线 性 KD 树(kdimensional树)[9]等。(2)集成型树形索引往往能充分发挥各树形结构的优点,在现有点云数据索引研究上具有重要地位,并呈主流发展趋势,如加强了三维坐标点匹配搜索能力的“规则八叉树&平衡二叉树”集成型索引[10]、提升了R树在点云组织管理中创建效率的“八叉树 &R树”集成型索引[11]、满足自适应点云数据管理的“四叉树&R树”集成型索引[12]、针对公路工程激光雷达点云数据特点设计的“四叉树&KD树”集成型索引[13]、提升索引在各应用场景下鲁棒性的“KD树&八叉树”集成型索引[14]等。
上述研究虽然给出了解决点云数据组织管理的有效方案,但均集中于面向桌面或Web端的可视化应用,缺乏对移动端网络带宽、计算与渲染能力、内外存空间等性能特点的考虑;缺乏针对移动端的数据索引组织方法的深入研究[15-16]。针对上述问题,本文在深度考虑以上移动终端特性的基础上,对面向移动端点云在线可视化应用的点云数据索引内容进行了总结:
(1)数据的相对关联性。可视化端发起的数据请求往往会出现大范围数据重叠的情况,点云数据之间的空间关联度较低,为减少移动端网络资源的浪费,加快渲染速度,需考虑数据空间的关联性建设,以支持对点云数据间关系的判断。
(2)数据在网络上传输的可靠性与在移动端渲染的快速性。数据是应用的基础,移动端发起一次数据请求后,须保证该次请求结果集在网络上传输的稳定性,同时也要保证移动端能够依靠有限的计算渲染资源完成该份数据的快速解析与渲染工作。
(3)数据的多层次细节模型。移动端的硬件资源有限,而点云地理场景开阔、精度高、数据量大,如果为移动端提供的点云场景数据都具有相同的可视化精度等级,显然会出现非重要对象占用过多渲染资源的问题。因此,从后续移动端的可视化效果角度出发,点云数据的组织方法在构建之初,就要求能支持点云数据的多细节层次表达。
基于以上分析,在点云数据索引研究方向逐渐趋向集成型索引的背景下,本文充分利用KD树的平衡性与优秀的空间划分能力、八叉树简单的算法逻辑与较低的计算机资源开销等优点,结合优化后的集成型树形索引的管理结构,提出了面向移动点云在线可视化应用的DKD-tree(动态KD树,dynamic KD-tree)&LLOctree( 链 线 八 叉 树 ,linked_linear octree)集成型点云数据管理方法。首先,利用考虑了移动终端网络带宽与计算渲染能力的DKD-tree对原始点云数据实现均衡划分与编码;然后,利用优化后的二级树组织结构,形成了便于管理且支持点云数据LOD模型的LLOctree;最后,通过自然数编码,联接DKD-tree与LLOctree的内层组织,形成〈1 DKD-tree:1 LLOctree〉的集成型点云数据索引。该方法能为移动端提供基于LOD的高效率渲染方案、支持从数据块层面完成点云数据的空间关系判断、支持移动端对数据的多线程请求以及对数据请求的动态合并。
1 DKD-tree & LLOctree集成型索引
集成型索引的整体结构:首先使用DKD-tree完成数据的划分与重组织,然后再利用LLOctree对DKD-tree划分后的数据进行二次组织。
1.1 基于DKD-tree的点云数据重组织方法
1.1.1 DKD-tree的构建参数
DKD-tree是对KD树的改进,两者都属于二叉查找树在多维空间应用上的扩展,内部结点均拥有“空间划分域”与“空间划分域值”属性。在选择方式上,DKD-tree的空间划分域与空间划分域值由数据的分布情况动态确定,而非静态设定。DKD-tree的叶结点具有“分割粒度”属性与“编码”值。实际上,KD树也具有分割粒度属性,该值为1,即叶结点的数据存储量为1。
对于一棵深度为H、分割粒度为S的DKD-tree,用 D(i,j,d,v)表示该 DKD-tree中第 i层第 j个结点。D所对应的空间划分域为d,v表示点云数据在该空间划分域下的分割超平面的取值,即空间划分域值。
由于KD树具有使用单个结点存储单一k维数据的特性,在管理大规模点云数据时,会浪费较多的内存资源,并且采用交替方法设定空间划分域较为机械,不能保证空间划分尺度的均衡性。针对KD树的这些缺点,笔者对其做了以下改进:
(1)空间划分域d。对任意非叶结点D(i,j,d,v),在i相同的情况下d的取值可以不同(i=1,2,…,H-1)。d的取值取决于D结点下的点云数据集在对应三维空间中最长的坐标轴,与点云数据其他维度无关。非叶结点情况下,d的取值为0,1或2,分别对应x、y、z坐标轴;叶结点情况下,d的取值为-1,表示无空间划分域。
(2)空间划分域值v。v的取值为D结点下的点云数据集在空间划分域d上的中值。
(3)叶结点的“分割粒度”S。DKD-tree不再使用叶结点来维护仅仅一条k维空间数据;对任意叶结点 D(H,index,dindex,vindex),其中 index=0,1,2,…,2H-1-1,当点云数据量最接近“分割粒度”S的设定值时,DKD-tree停止对当前叶结点的剖分。
(4)DKD-tree叶节点的编码index。对每一个叶节点 D(H,index,dindex,vindex)设定编码 index,其中index=0,1,2,…,2H-1-1。
由以上改进可知,DKD-tree是一棵满二叉树。由改进(1)与(2)知,DKD-tree叶结点所对应的点云数据量近似相等。任一叶结点所对应的点云数据的最小外包长方体,经一定操作后理论上接近正方体。以上特点保证了点云空间与数据划分粒度的均衡性。由改进(3)知,DKD-tree的深度由分割粒度决定,分割粒度值直接影响点云数据传输的可靠性与速度、移动端的渲染速度以及后续筛选查询的效率,最终影响移动可视化端的用户体验。因此,分割粒度值S是构建DKD-tree的关键。
移动端可视化应用基于“在线获取数据,即时渲染呈现”的工作模式,因此,在有限网络带宽的情况下,要使移动端能秒级响应场景渲染请求,须考虑以下情况:DKD-tree某一叶结点D对应的点云数据完全满足用户需求,均须给移动端提供解析和渲染(不考虑数据压缩、LOD分级以及多线程请求的情况)。针对上述情况,为了使该结点下的数据通过网络稳定传输,也须保证在移动端的硬件条件下被快速地解析和渲染。综上,以秒级响应作为参考标准,得到“分割粒度”S以及“分割粒度”S与深度H的大致关系:

式(1)中,count表示在某格式的点云下1MByte可以存储的点云数量;speednetwork表示移动端网络带宽条件下最小的数据下载速度,speedrendering表示移动端能够秒级渲染呈现的点云数据大小;speednetwork与speedrendering都以 MByte·s-1为单位;式(2)中的 M 为原点云数据总量。
作为在开放式网络环境下工作的移动终端,speednetwork值应以移动通信网络的带宽阈值为参考标准(封闭式内部网络环境除外);speedrendering值应以主流设备的计算与渲染能力为参考进行测算。
1.1.2 本地点云数据的重组织方法
如果每次构建点云数据索引时都需要对原始点云数据重新读取和处理,会造成时间和计算机资源的大量浪费。因此,将索引构建的基础建立在经重新组织的点云数据上,可有效提升构建效率。本文依据DKD-tree参数设定完成对原始点云数据的重组织工作,以提升后续构建DKD-tree的效率。
对任一点云数据,由1.1.1节,可计算在其基础上构建的DKD-tree的分割粒度值S与深度值H。若重组织操作中生成的某一点云文件具有划分深度h的属性值,则表示该文件由原始点云文件经(h-1)次二分操作得到。DKD-tree的深度值与重组织操作的最大划分深度对应,原始点云文件的划分深度为1。基于以上设定,点云数据重组织方法的具体过程如下:
输入:本地原始点云数据文件的路径Path;重组织操作的最大划分深度H。
(1)如果H≤1,进入步骤(3);如果H>1,设定h=1,进入步骤(2)。
(2)①依据文件名获取Path路径下划分深度为h的文件集合{file0,file1,file2,…,file2h-1-1}。②对于集合中每一份点云文件filei(i=0,1,…,2h-1-1)内的数据,计算其在x、y、z维度上的最长轴di(d取0,1或2,分别对应x、y与z轴),并基于桶统计思想计算其在轴 di上的中值 vi,以 di,vi为 filei生成左右子文件,子文件的文件名分别在filei.name的基础上添加(di,vi,“left”)、(di,vi,“right”)信息。③h++。④如果h<H,继续步骤(2);如果h≥H,进入步骤(3)。
(3)点云数据的重组织过程结束。
根据以上点云数据的重组织方法,任意点云数据最终都会得到2H-1个划分深度为H的子点云文件。图1(a)为点云数据data.txt执行了划分深度为3后的过程,划分深度为1的文件即为原始点云文件data.txt。data.txt生成了2份划分深度为2的子文件,解析这2份子文件的文件名可以得到本次划分操作的信息:数据划分的依据是z轴、数据在z轴上的中值是z=0.5的超平面。同理,对以上2份划分深度为2的点云文件分别进行划分操作,将产生4份新的子文件,其文件名同时包含第1次划分与本次划分的属性。至此,点云文件data.txt的重组织过程结束。

图1 点云文件划分示例及在其基础上构建的DKD-treeFig.1 The example of file partition on point clouds and the DKD-tree constructed on it
通过分析点云数据的重组织方法可知,对某一点云数据进行重组织的过程,即为依据该份数据第一次构建DKD-tree的过程。重组织方法的数据划分轴与DKD-tree的空间划分域对应,数据在划分轴上的中值与DKD-tree的空间划分域值对应,生成的每一份文件都与DKD-tree中的一个结点对应,其中,2H-1个划分深度为H的子点云文件与DKD-tree的叶结点对应。
1.1.3 DKD-tree的构建方法
基于重组织后的点云数据,可以快速构建DKD-tree。此时,仅通过解析本文1.2节中划分深度为H的2H-1个子点云文件的文件名,就可以快速构建一棵深度为H的DKD-tree。具体构建方法如下:
输入:DKD-tree深度H。
(1)获取划分深度为H的点云文件集合{file0,file1,file2,…,file}。
(2)①对集合中的每一份点云文件filei(i=0,1,…,2H-1-1)的文件名进行字符串解析,更新或从根结点到叶结点 D(H,i,di,vi)的简单路径上生成每个结点信息。②为叶结点D(H,i,di,vi)设定唯一编码i,并将文件filei的数据委托叶结点D管理。
(3)构树完成。
基于图1(a)中最终生成的4份点云数据的文件名,可以构建如图1(b)所示的DKD-tree。除只含有编码标记的叶结点外,其他每个结点都包含了每次的空间划分信息:左右子树位置、空间划分域,空间划分域值。
1.2 基于LLOctree的点云数据管理方法
如果仅使用DKD-tree作为服务端数据服务的基础,当移动在线应用平台需要提供精细的点云数据时,通过遍历相应叶结点内所有数据完成深度查询操作显然会降低索引的效率。若对DKD-tree叶结点继续进行剖分操作,降低叶结点的分割粒度,导致以DKD-tree叶结点为请求单位的移动端必须请求多倍的细粒度数据,造成大量网络资源浪费,甚至导致信令风暴,同时,较小的分割粒度值增加了DKD-tree深度,数据查询效率也会相应下降。综上所述,在保证索引原有效率的基础上,为了应对数据深度查询的需求,为每个DKD-tree叶结点内的数据建立二级索引非常必要。
本文在对每一份叶结点数据进行LOD建模的基础上,用LLOctree作为二级索引来存放LOD模型。
1.2.1 点云数据LOD模型的构建方法
LOD(levels of details)技术指根据物体模型的结点在显示环境中所处的位置和重要度,决定物体渲染的资源分配,降低非重要物体的细节度,从而获得高效率的渲染运算。对于大规模点云数据,移动应用没必要更没能力一次性完成点云场景绘制;即使在面向桌面级应用的相关研究中,点云数据的LOD建模方法也是研究的重点之一。
通常在基于任意对象构建的多层次可视化精度描述中,除了“最精细”外,还包含临界层次“接近最精细”与“最粗糙”及两者的中间层次。对于“接近最精细”与“最粗糙”两项可视化精度描述,在本文的LOD建模方法中分别代表2项具有实际意义的参数:最大可视化精度比VPR_Max(maximum visual precision ratio)与最小可视化精度比VPR_Min(minimum visualprecision ratio) 。VPR_Max是点云数据LOD建模是否合格的判定条件;VPR_Min是在当前点云数据LOD模型下,为移动端提供的LOD数据是否达到可视化精度要求的判定条件。确定VPR_Max与VPR_Min的方法为:对任意场景下的点云数据,分别隔n个点进行粗采样绘制(n=2,3,…),通过对比原渲染效果,在视觉效果差别非常小的情况下,采样的数据占原数据的比例为VPR_Max;能基本分辨对象的情况下,采样数据占原数据的比例为VPR_Min。笔者对多份不同来源、不同场景的点云数据进行了测试与验证,发现VPR_Max值通常在1/2,VPR_Min值在1/10。

图2 点云数据LOD建模方法在二维空间下的示例Fig.2 A example of the LOD modeling method on point cloud in the case of 2D
图2 使用二维图方式描述了三维空间下点云数据的LOD建模方式。设定空间中每个点具有level属性,表示该点在LOD模型中所处的层次。图2(a)表示原始点云数据集(黑色点簇)及其最小外包矩形grid(三维空间下对应最小外包长方体);计算并标记距离grid中心(紫色菱形点)最近的点为红色,level赋值为 0;图 2(b)中首先移除图 2(a)已被处理的红色点,然后对grid实现金字塔划分,得到4个child_gridi(i=0,1,2,3),同样,计算得到每个child_grid中距离该child_grid中心最近的点,并将这些点的颜色标记为橙色、level赋值为1;对于剩余的未经处理的5个黑点,level赋值为2。处理结果如图2(c)所示,统计图2(c)中各点信息,得到的相关数据如表1所示。
以VPR_Min=1/10为例,LOD层次level为0时点数据占总数的比例满足level0。ratio≥VPR_Min,对于该点簇,level0下的点集已经达到识别该点簇的可视化精度要求。当移动端请求该点簇数据用于渲染时,LOD模型至少需要为移动端应用提供level0下的数据,以满足用户的可视化精度需求。

表1 图2(c)中的点信息统计Table 1 Statistics of point information in Fig.2(c)
2次LOD建模操作后,level0与level1的数据集合占数据总量的50%。如果对当前点簇进行1次或3次LOD建模操作,非最大level(最高level值为LOD建模操作次数加1)下的LOD数据占比不及当前情况下接近VPR_Max。因此,当前点云数据合理的LOD模型层级应当设定为0~2;level0与level1的点数据集,具有较好的点云对象可视化效果。而对于剩余的占比50%、level=2的点数据,其重要程度相对较低,在移动端渲染压力与网络压力不太大的情况下,可考虑请求并绘制数据。
上文对点云LOD建模方法的基础流程进行了阐述,值得注意的是,对于每一个DKD-tree叶结点下的点云数据集,均须在相同的LOD层级上进行模型构建;每个数据集的最小外包长方体无论是否为正方体,都需要在x,y,z维度上进行等分。
设在LOD模型层次为0~k的点云数据集中,非最低重要度的数据占原数据的比值为真实最大可视化精度比(real maximum visualization precision ratio):

若LOD模型层级的构建基于0~k-1或0~k+1时的真实最大可视化精度比为RVPR_Max’,则有

1.2.2 LLOctree的构建方法
通常情况下,对2H-1个DKD-tree的叶结点进行LOD建模后,也会构建2H-1棵二级索引存储LOD模型,并与DKD-tree的叶结点一一对应,形成基于〈1一级树:N二级树〉管理结构的集成型树形索引,见图3。很明显,〈1一级树:N二级树〉的索引结构增加了二级索引的管理复杂度,同时造成内存资源的浪费。本文利用具有算法逻辑简单、计算机资源开销较小等优点的八叉树作为存储LOD模型的数据结构,为避免〈1一级树:N二级树〉索引结构带来的问题,融合了DKD-tree下2H-1个叶结点对应的2H-1棵八叉树生成一棵LLOctree,实现了〈1一级树:1二级树〉的集成型树形索引管理框架。
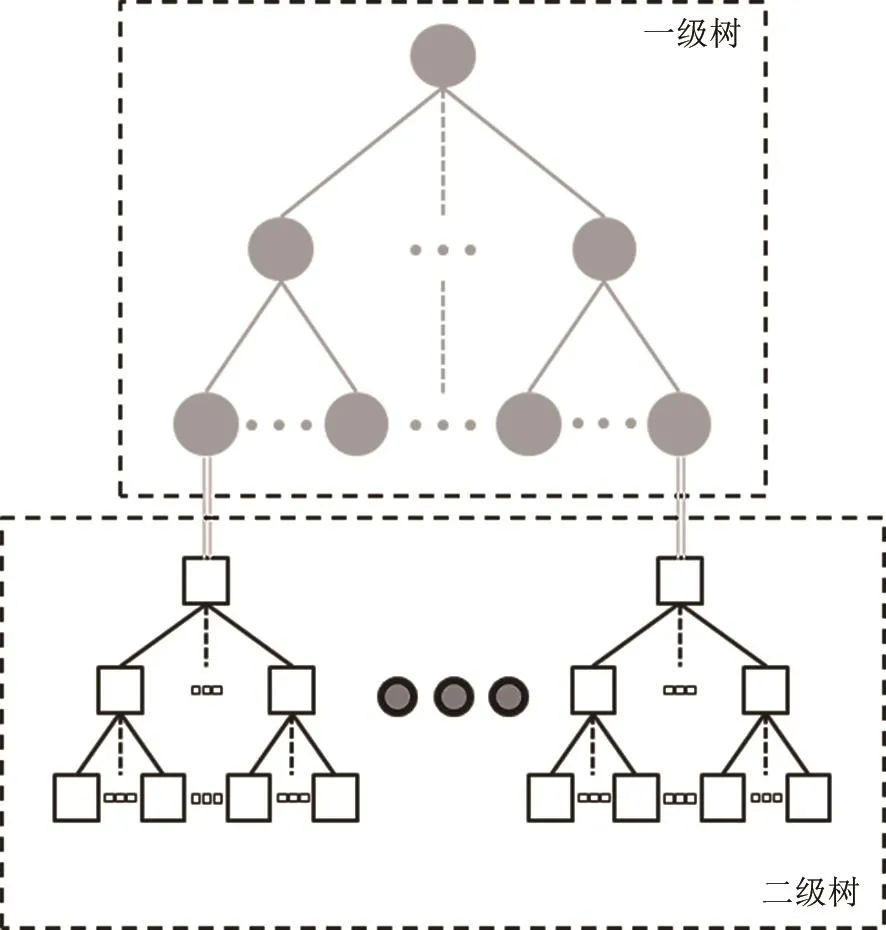
图3 常见集成型树形索引的框架结构Fig.3 The structure of common integrated index
LLOctree具有如下特性:树内结点间关系使用指针维护,每个结点内使用线性数据结构分层存储信息,在其第N个结点的第M内层结构上,存储了DKD-tree下第M棵八叉树的第N个结点信息。综上所述,对任一DKD-tree的叶结点D(H,index,dindex,vindex),可 通 过 自 然 数 编 码 index与LLOctree建立联系,然后对自己映射的点云LOD模型进行数据的存取操作。基于LOD数据模型的LLOctree构建方法较为简单,具体步骤如下:
输入:设定LLOctree的深度height、LLOctree层级与LOD层次的映射关系。
(1)按height生成一颗满LLOctree,根据点云数据块初始化每个结点下每个内层的最小外包长方体信息。
(2)为DKD-tree叶结点编码为index数据构建LOD模型。
(3)按照映射关系将数据模型存储在LLOctree的第index内层。
(4)构树完成。
映射关系描述了LOD某一细节层次数据存放在LLOctree中的层级位置,例如:映射关系((1→0,1))表示LLOctree的第1层存储了某点云数据LOD模型第0级与第1级的细节数据。由上可知,LLOctree的查询深度仅与可视化端的精度需求挂钩,而每一结点的数据量有限,LLOctree的深度往往较低,从而可有效避免树的深度与查询效率间的矛盾。
1.3 混合空间索引的搜索策略
本文的集成型树形索引的整体结构为:DKD-tree用作数据块的初步定位,仅为叶结点保留编码数据,本身不存储任何点云数据;LLOctree存放了经DKD-tree重组织后的点云数据LOD模型,并用作数据的深度查询,LLOctree的入口是DKD-tree叶结点编码。因此,DKD-tree&LLOctree集成型索引的空间查询分为DKD-tree与LLOctree两部分,具体查询算法如下:
1.3.1 DKD-tree部分
(1)确定待查询视域空间,以及视域最小外包长方体在各坐标轴上投影的最大、最小值range[xmax,xmin,ymax,ymin,zmax,zmin],然后进入 DKD-tree的根结点D(1,0,d0,v0)。若移动端采用基于透视投影的渲染模型,则可将视椎体扩展为长方体后再计算range[xmax,xmin,ymax,ymin,zmax,zmin],如图 4 所示。
(2)若当前待处理结点D不为叶结点,进入步骤(3);若为叶结点,进入步骤(4)。
(3)获取当前结点的空间划分域d与空间划分域值v,取得range在当前空间划分域d所映射的坐标轴上的最大值Axismax与最小值Axismin(Axis=x,y,z),进而计算空间划分域值 v与(Axismin,Axismax)的关系。

图4 本文邻域查询模式下的视椎体扩展结构Fig.4 Extended structure of viewing frustum in neighbor query mode of this paper
①v<Axismin,进入当前结点D的右子结点;
②v>Axismax,进入当前结点D的左子结点;
③ Axismin≤v≤Axismax,同时进入当前结点D的左子结点与右子结点。
执行步骤(2)。
(4)在结果集合Index Array中加入当前结点D的索引编号index。
1.3.2 Octree部分
(5)对于每一个 index=Index Array[i],由 index在LLOctree相应内层下的递归情况搜索各结点在range空间范围内的数据,然后根据移动在线应用的需求将过滤后的数据返回。
DKD-tree混合LLOctree的空间索引模型以及LLOctree的结点结构如图5所示,其中颜色箭头指向表示1次搜索过程。DKD-tree的第2H-1-1个叶结点会根据自身编码进入LLOctree的相应内层,然后执行后续数据查询任务。

图5 DKD-tree与LLOctree集成的混合空间索引结构Fig.5 Structure of the spatial index integrated with DKD-tree and LLOctree
1.4 本文索引支持下的移动端数据获取方法
面向移动在线应用的索引方法最终要以服务的形式为移动终端提供数据支持。基于本文索引构建的点云数据服务,除索引本身支持的LOD数据请求方法外,还有以下几种移动端数据获取方法:
(1)多线程请求。移动端可视化应用,首先根据视域范围从服务端DKD-tree查询到点云结果集的编码集合。然后,根据编码集合,利用多线程请求方法从服务端的LLOctree中查询到真正的数据结果。
(2)数据请求的动态合并。移动端的网络状态可能存在与服务端DKD-tree分割粒度不对等的情况,如移动端处于4G移动网络条件下,而DKD-tree构建的依据是3G移动网络。针对以上情况,移动端可依据网络状态,实时、动态地完成数据请求的合并操作,减少不必要的网络请求带来的硬件与时间资源的浪费。
(3)缓存与预取。在移动端硬件条件允许的情况下,利用视点预测算法,预先获取可能视域下的点云数据,以提升移动端点云场景漫游时的界面响应速度。
对于获/预取得到的数据,如果某一点云数据块完全处于视域范围内,通过〈编码,数据块〉键值对方式,完成该数据块的磁盘缓存或内存缓存,供后续需要时使用,以降低数据的网络请求频率,提升界面响应速度。
2 实验与分析
为验证本文针对移动端点云在线可视化应用提出的DKD-tree&LLOctree集成型空间索引是否具有实用性与有效性,用了Robotic 3D Scan Repository网站上公开的德国不来梅Schlachte城(镇)部分激光点云数据(约12 000 000个点)作为测试数据,选择KD树与八叉树作为实验的对比对象。为避免八叉树构建时掺杂人为因素,如内部结点是否存储数据、树的深度值设定、结点的扇出值设定等,本文参照LLOctree的特点对八叉树设定了构建规则:(1)八叉树的非叶结点与LLOctree一样也存储数据。(2)八叉树每个结点的扇出值(即分割粒度,超过该值则将结点剖分为8个子结点)参考DKD-tree的分割粒度值。
本节将从三方面展开讨论,服务端硬件环境为:处理器 Core(TM)i7-6700 CPU@3.40GHz;内存8GB;操作系统 Windows 10 64位。客户端的硬件环境为:设备名称 EVA-AL10(华为P9);处理器Hisilicon Kirin 995;内存 4 GB;操作系统 EMUI 5.0(Android 7.0)。
2.1 索引构建效率
执行隔点采样操作,得到10份实验样本数据,样本数据量分别为100万,200万,300万,…,1 000万,隔点采样方法保证了各样本数据的空间分布范围与密度比例基本一致。
由图6的对比结果可知,八叉树索引的构建效率最优,这与自身简单的逻辑结构紧密相关。KD树索引使用〈1结点:1数据〉的数据存储方式,易导致大量内存资源浪费,甚至在数据量较大时导致建树困难。实验结果表明,KD树索引的构建并不稳定,总体而言,KD树索引不适合大规模地理场景点云数据的组织管理。本文的DKD-tree&LLOctree集成型索引方法的构建效率较八叉树索引低,主要原因在于该索引方法扩展了对数据LOD模型存储管理的支持,消耗了一定时间。在索引构建上,本文方法较KD树方法可靠性高。

图6 本文方法、KD树与八叉树索引的构建性能比较Fig.6 Building performance of the integrated spatial index,KD-tree and Octree
2.2 空间查询效率
依据实验数据构建生成的DKD-tree&LLOctree集成型索引的具体参数如下:满二叉树DKD-tree的深度H为11,“分割粒度”S为15 000(以移动3G网络的带宽阈值作为参考),叶结点编号依次为0~1 023,为每一叶结点的数据构建了8个层级的LOD数据模型,1 024个LOD模型最终的RVPR_Max值为 0.589 1;LLOctree的深度 height为5,结点内层数为1 024,LLOctree层级与LOD模型层次两者的映射关系为((1→0,1),(2→2,3),(3→4,5),(4→6),(5→7))。参考 DKD-tree,将八叉树结点的扇出值设定为15 000。由2.1节的实验内容可知,无法基于原始数量的点云数据构建KD树,因此,通过对实验数据隔点采样得到半份数据约6 000 000个点,构建KD树。

图7 本文方法、KD树与八叉树索引的空间查询性能比较Fig.7 Query efficiency of the integrated spatial index,KD-tree and Octree
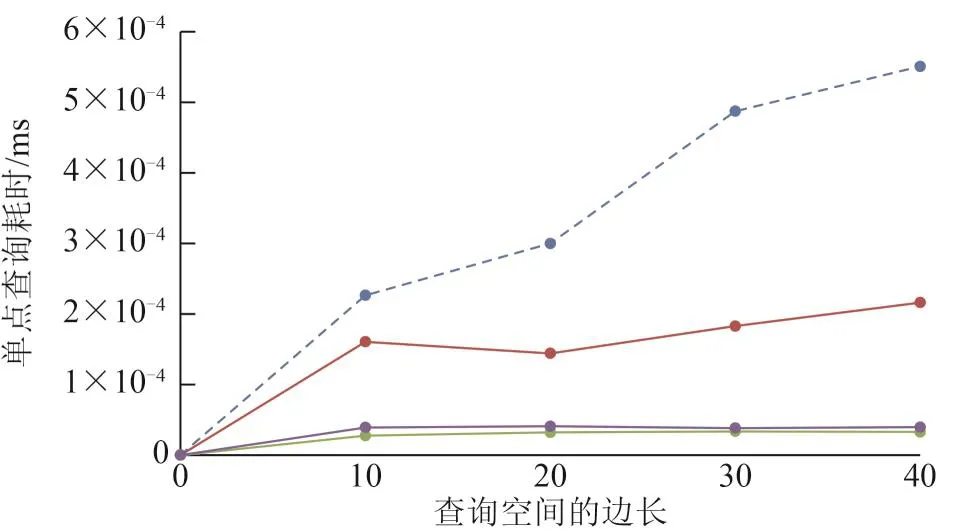
图8 本文方法、KD树与八叉树索引的单点查询性能比较Fig.8 Query efficiency of single node of the integrated spatial index,KD-tree and Octree
图7为各索引在不同的查询范围内,空间查询操作所耗时间的数据对比。图8为对图7实验数据进一步处理的结果,表示各索引在空间查询操作中的单点耗时情况。本实验的查询空间为正方体,边长用实验数据的单位表达。
由以上实验结果可知,即使基于半份数据构建而成的KD树索引,在数据查询效率上仍与八叉树、本文方法存在差距,这是因为在对数据量大的点云数据执行空间查询操作时,KD树在邻域关系重建环节上浪费了大量的计算资源,致使空间查询效率较低,进一步证明其不适合大规模点云数据的组织与管理。八叉树作为一种结构简单的树形索引,空间查询效率保持中等水平。本文提出的DKD-tree&LLOctree集成型点云数据管理方法,在空间查询效率上较KD树索引与八叉树索引优势明显,单点查询耗时约为4.0×10-5ms,较KD树索引与八叉树索引降低了一个数量级。
图9为各索引在不同数据量下每次查询操作的耗时。结果显示,KD树索引与八叉树索引的空间查询耗时基本与查询结果集点数呈指数关系。无论本文的集成型方法是否采用LOD数据查询策略,空间查询耗时基本都与查询结果集点数呈正比,表现出非常好的稳定性。
2.3 数据的传输成功率
为验证依据KD树索引、八叉树索引以及本文集成型索引搭建的点云数据服务是否支持移动端稳定、快速地获取查询结果,基于2.2节内容搭建了HTTP服务进行实验验证,以JSON作为移动端与服务端的数据交换格式。

图9 本文方法、KD树与八叉树索引空间查询稳定性对比Fig.9 Query stability of the integrated spatial index,KD-tree and Octree
实验结果如下:基于KD树索引与八叉树索引构建的数据服务,在将结果集重组织为JSON格式时均耗时过长,导致移动端数据请求发生错误。基于本文集成型索引的数据服务,移动端可在服务端DKD-tree查询返回的编码集合基础上,使用多线程方式进一步向数据服务端的LLOctree请求具体的点云数据,在以上多线程请求与LLOctree端LOD模型的保障下,移动端以100%的成功率获取数据服务端的全部结果集。
导致以上结果的原因如下:
(1)基于KD树与八叉树搭建的数据服务不支持移动端的多线程查询操作,只能将查询结果一次性提供给移动端,但查询结果的数据量对数据服务器造成压力,导致重组织耗时过长。
(2)基于KD树与八叉树搭建的数据服务不支持点云数据的空间关联性判断,因此无法实现对结果集的规则性划分。如果移动端与服务端配合实现查询结果的分段获取,那么服务端必须对每次分段请求执行查询操作,显然会造成服务端计算资源与时间资源的巨大浪费,使移动端应用困难。该方法不具可操作性。如果由服务端缓存每次查询结果,供移动端分段请求,那么,在移动端设备较多的情况下,会很快消耗完服务端的内存资源,造成服务崩溃。
图10为基于该DKD-tree与LLOctree数据服务在移动端实现的点云场景可视化效果图,图11为某视点下的LOD可视化效果图。
3 结 语
点云技术的发展和应用的推广,所产生的点云数据量和复杂度随之增大,如何高效实现对大规模点云数据的组织与管理,为移动GIS下的点云可视化应用平台提供可靠、高效的数据支持,是三维GIS发展过程中面临的难题之一。

图10 移动端点云场景可视化效果图Fig.10 Visualization of point clouds on mobile

图11 移动端点云多细节层次描述的效果图Fig.11 LOD representation of point clouds on mobile
本文提出了一种面向移动点云在线可视化应用的DKD-tree&LLOctree集成型索引方法。首先,使用考虑了移动终端网络带宽与计算渲染能力双重特性的满二叉树DKD-tree,完成原始点云的均衡划分与重组织,其次,完成对每个点云数据块的LOD模型构建,然后,使用LLOctree实现对点云LOD模型的存储与管理,最后,通过DKD-tree的叶结点编码连接LLOctree的内层组织,形成最终的索引结构。该方法能为移动端提供基于LOD的高效率渲染方案,同时支持服务端或移动端从数据块层面完成点云数据的空间关系判断,支持移动端对数据的多线程查询以及对数据请求的动态合并。实验与分析证明,与传统点云数据索引相比,本文方法构建效率稳定、空间查询性能优秀,同时可提高移动端点云在线可视化应用的效率,提供可靠的数据支持,具有较好的实用性与可扩展性。
如何提取点云数据中的对象,以及以对象为单位进行点云数据的组织与管理,将是下一步需要解决的问题。
猜你喜欢
枣庄学院学报(2022年5期)2022-09-21 09:35:22
世界科学技术-中医药现代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
海洋信息技术与应用(2020年1期)2020-06-11 12:43:56
传媒评论(2019年4期)2019-07-13 05:49:14
数学物理学报(2018年1期)2018-03-26 08:16:42
电子设计工程(2014年12期)2014-02-27 11:58:23
机械设计与制造工程(2013年4期)2013-09-12 03:23:04
科技传播(2012年2期)2012-06-13 10:03:26
图学学报(2010年4期)2010-07-07 06:52:20
