
基于边缘计算模型的智能视频监控的研究∗
2019-02-27 08:32孙洁钱蕾
计算机与数字工程 2019年2期
孙 洁 钱 蕾
(华北理工大学电气工程学院 唐山 063200)
1 引言
云计算中心具有较强的计算处理能力,将网络边缘设备产生的数据上传到云中心进行存储与处理已经得到了普遍应用[1]。随着万物互联时代的到来,网络边缘设备的数量讯速增加,未来必将产生海量数据,如果直接将源数据上传到云计算中心进行处理,一方面会占用很多不必要的存储空间,另一方面给网络带宽资源带来了巨大的负担。施魏松等提出了边缘计算模型[2],并从概念、原理以及挑战等三个方面对其进行介绍[3]。随着物联网的发展,摄像头遍布了我们的生活。据统计,大约有3000万个监控摄像头部署在美国,每周生成超过40亿小时的视频数据[4],甚至一个摄像头也能产生几百GB的数据[5]。如果将这些摄像头采集到的原始数据未经处理直接上传到云计算中心,那将会是十分庞大的数据量。为此,本文提出在视频数据上传至云中心之前,先在边缘设备上执行预处理,在监控摄像头上加入计算能力,当检测到视频画面中有运动目标时,对监控信息进行存储,如果没有运动目标就不存储。这样可以节省大量的存储空间,而且可以减轻数据传输对网络带宽的压力。
运动物体检测是智能监控中视频图像分析的重点和难点,关于运动目标检测的方法多种多样,其中最基础的有帧差法[6]、背景差分法[7]和光流法[8],其他都是在这三种基础上的改进或者组合。帧间差分法检测到的前景区域的边缘模糊不完整,而且当物体移动缓慢时会出现误判和空洞现象。光流法准确率高,但计算复杂,容易受到背景扰动和光照变化的影响,不适用于实际应用。背景差分法可以将运动目标完整地检测出来,但是容易受到光照变化和背景变化的影响,因此只适用于背景不变的情况[9]。针对上述问题,本文在帧间差分法的基础上,选用三帧差分法结合形态学运算和自适应阈值计算方法进行运动物体检测,其计算简单,可以检测出完整的运动目标。将该方法用于智能监控系统,可以对视频信息选择性存储,减轻了对网络带宽的压力。在视频检索中,可以快速定位异常动态图象,在工作人员回放查看异常信息时节约时间。
2 常用的运动目标检测算法
2.1 帧间差分法
帧间差分法是一种比较常见的运动目标检测方法,根据两帧图像的差分值与设定的阈值进行比较来判定的。当监控画面中有运动物体时,相邻两帧图像间就会有像素的变化。选取相邻两帧图像,进行灰度化处理,然后对处理后的图像进行差分运算,将差分结果的绝对值与设定的阈值T进行比较,若大于阈值T则判断为画面中有运动目标,若小于或等于阈值T则判断为没有运动目标。其数学公式描述如下:
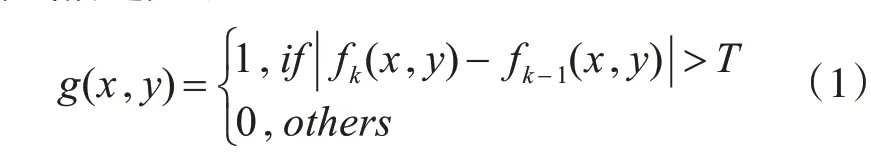
g(x,y)为连续两帧图像经过差分运算、二值化得到的二值图像,fk(x,y)为当前帧灰度值,fk-1(x,y)表示当前帧前一帧的灰度值,T为二值化时设定的阈值,二值化将图像呈现出只存在黑色和白色,g(x,y)=1表示前景,g(x,y)=0表示背景。帧间差分法不会受到缓慢光线变化的影响,算法简单易实现。但是该方法只能检测到前后两帧变化的部分,不能检测到重叠部分,检测到的运动目标内部容易出现空洞现象。
2.2 背景差分法
背景差分法主要应用于背景静止的情况下的运动目标检测,选取没有运动物体进入监控画面时的图像作为背景图像,然后将当前帧与背景帧做差分运算,差分的结果与阈值T进行比较,二值化得到运动目标[10]。如果大于阈值T,则判断有运动目标,如果小于等于阈值T,则判断为没有运动目标。数学公式表示如下:
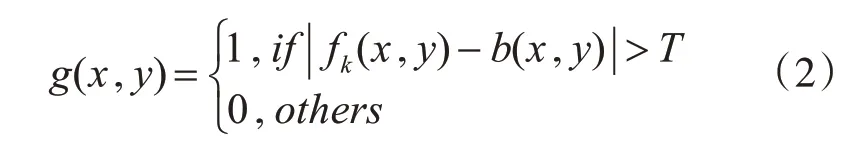
fk(x,y)为当前帧图像,b(x,y)为背景帧图像,g(x,y)为当前帧与背景帧经过差分运算、二值化后得到的二值图像,g(x,y)=1表示运动目标,g(x,y)=0表示背景区域。
背景静止的情况下,背景差分法可以检测出完整的运动目标,但是当背景中有光线变化或者树叶晃动等情况时,就会发生误判,因此不适用于背景发生变化的情况。
2.3 光流法
光流法[11]通过区别静止的物体和运动的物体产生的运动场的不同,将运动目标从背景中分离出来。光流法可以应用于摄像机运动的情况下,但是光照变化、遮挡等因素存在时会影响光流场的分布,增加了计算的难度。这种方法计算复杂、实时性较差,使用存在局限性。
2.4 三帧差分法
在帧差法的基础上,研究学者提出了三帧差分法,基本思路是提取连续三帧图像fk-1(x,y),fk(x,y),fk+1(x,y),然后将第k-1帧与第k帧进行式(1)的运算得到二值图像g1(x,y),将第k帧与第k+1帧进行式(1)的运算得到二值图像g2(x,y),然后对这两个二值图像进行逻辑与运算,提取相同的部分,从而得出运动目标的二值图像。三帧差分法的数学公式描述如下:
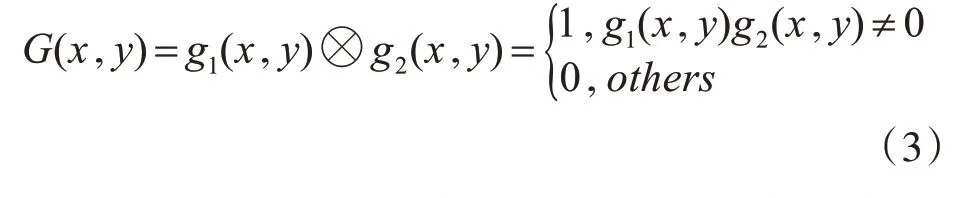
其中G(x,y)是g1(x,y)与g2(x,y)进行逻辑相与的结果,三帧差分法可以定位出运动目标在监控画面中的位置,要比帧间差分法更精确,但是检测到的运动目标内部还是会存在空洞现象。三帧差分法的流程如图1所示。
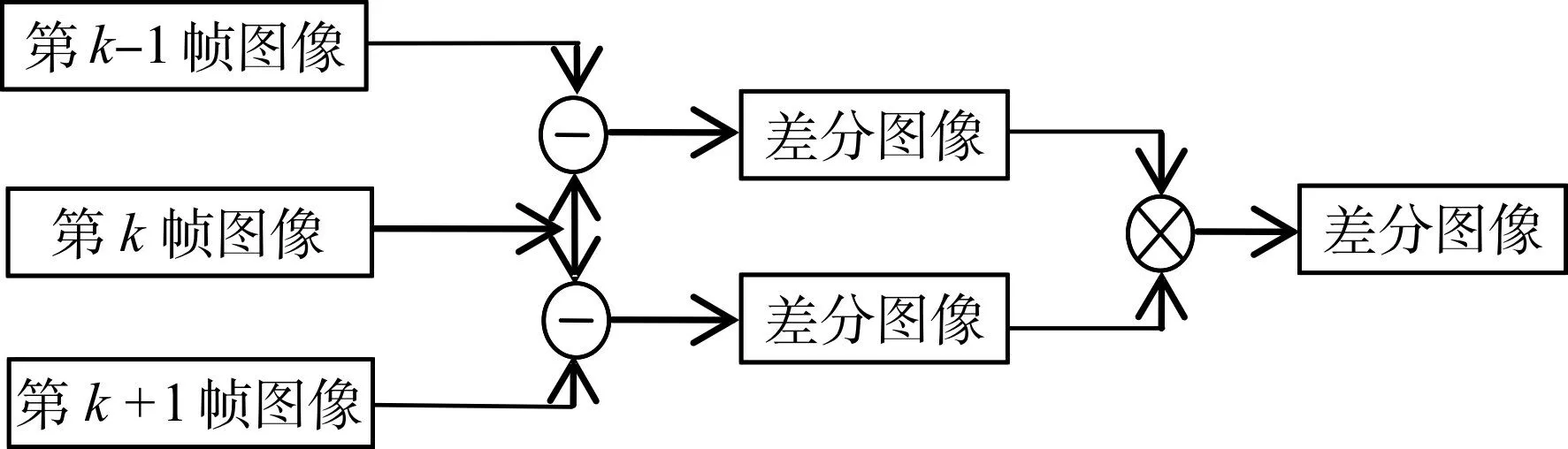
图1 三帧差分法流程图
3 本文算法
3.1 改进三帧差分算法流程
输入原始的监控视频流,对视频流进行图像分帧,采集连续的三帧图像,然后将分帧后的图像从RGB彩色空间变换到灰度空间,获取对应的灰度图像fk-1(x,y),fk(x,y),fk+1(x,y)。然后对两组相邻的图像做差分运算,也就是三帧差分。采用Otsu方法计算出最佳阈值对图像二值化处理,将得到的两个二值图像逻辑与运算。最后通过中值滤波来消除图像中的噪声,图像形态学处理确定移动物体的区域。整个算法的程序流程如图2所示。
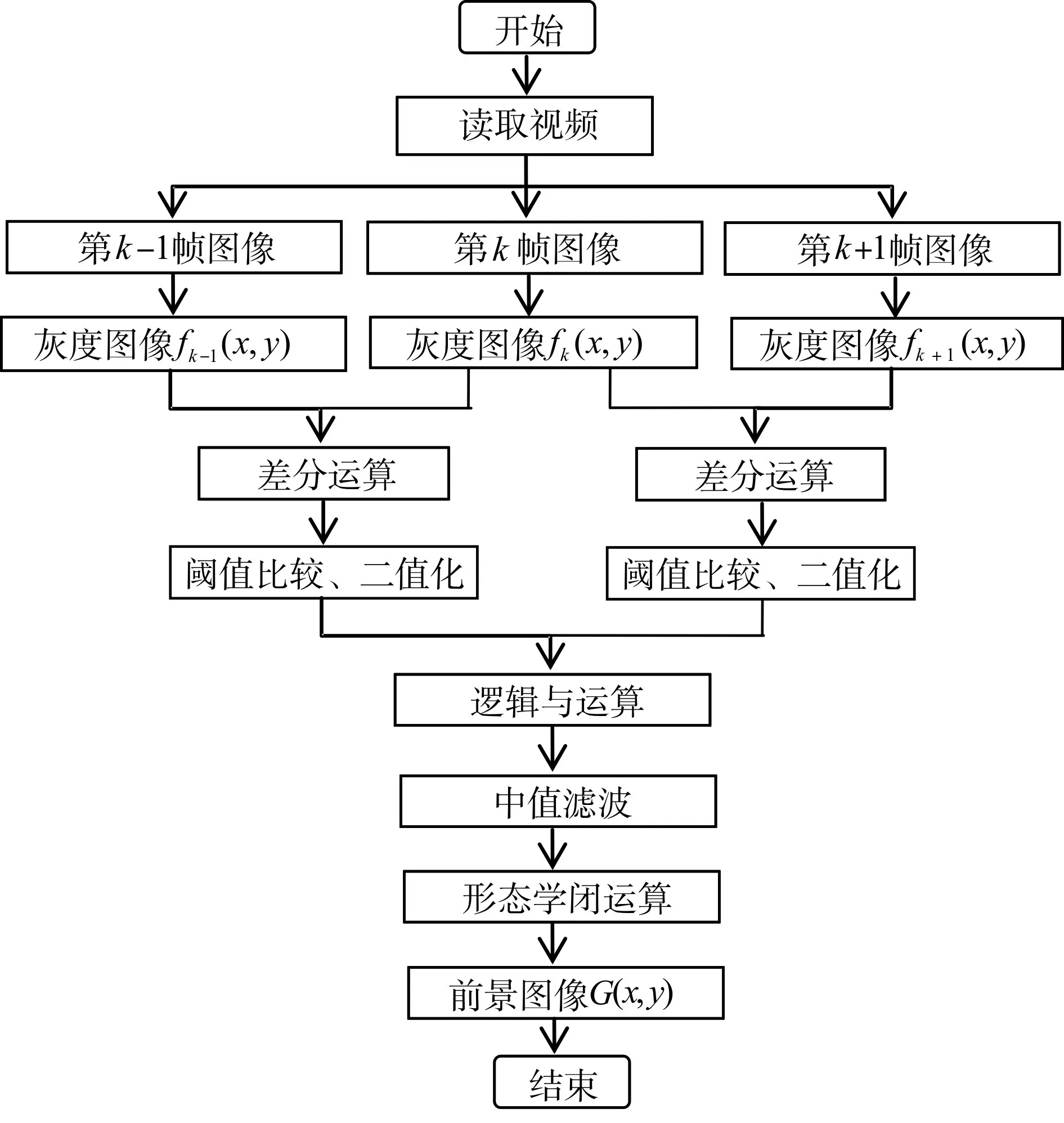
图2 改进的三帧差分法流程图
3.1.1 最大类间方差阈值计算方法
在传统的三帧差分法中,阈值T是根据不同的视频、不同的背景、不同的运动目标来设定的,若T选取得偏大,很可能出现漏检或者检测不完全,若T选取得偏小,会出现大量噪声。本文采用Otsu方法(最大类间方差法),可自动选取阈值进行二值化。计算公式如下:

其中,w0为背景像素点数占图像的比例,u0为背景像素点的平均灰度,w1为前景像素点占图像的比例,u1为前景像素点的平均灰度,u为整个图像的平均灰度,上式的最大值T即为图像的最佳阈值。
3.1.2 图像预处理
此时获得的视频图像并不理想,其中含有大量的噪声,需要通过图像预处理来去除这些噪声。常用的图像去噪方法有均值滤波和中值滤波,中值滤波是图像处理技术中最常用的预处理技术,滤除噪声的同时,能够保持图像的清晰度。本文采用中值滤波的方法,通过3×3模版滤波,消除散杂噪声点对运动目标的影响。
3.2 Canny边缘检测
对灰度化后的第k帧图像进行Canny边缘检测[12],得到第k帧图像的边缘图像E(x,y)。然后将之与改进三帧差分算法得到的二值图像G(x,y)进行与运算,得到运动目标的边缘E1(x,y)。将E1(x,y)和G(x,y)进行或运算,然后再进行形态学处理,从而可以得到完整的前景图像G1(x,y)。
4 实例仿真
4.1 运动目标检测
在普通PC机上进行仿真实验(处理器为Intel(R)Core(TM)i5-3230M,主频为2.60GHz,内存为4GB,操作系统为Windows10专业版64位)。实验所用的视频是在华北理工大学图书馆四层楼梯间门口拍摄,视频为AVI格式,总时长14s,帧速率24帧/s。分别采用帧间差分法、三帧差分法和改进后的三帧差分法,利用Matlab2016a对监控视频进行运动目标检测。
提取视频中的连续三帧图像(分别为视频序列中的第160帧、第161帧、第162帧图像)进行试验,如图3所示。

图3 视频序列中连续三帧图像
图4(a)是帧间差分法检测到的运动目标,虽然可以将运动目标的基本轮廓提取出来,但是检测到的运动目标轮廓不完整,且目标内部存在比较严重的空洞现象,当选取的阈值过小会出现大量噪声,容易出现误报警的情况。
图4(b)是文献[13]中的三帧差分算法检测到的运动目标,可以看出内部有小范围的空洞,而且部分边缘缺失,前后两帧之间运动物体灰度值相同的区域被判断为背景,不能检测到完整的运动目标。
图4(c)是本文算法提取的运动目标,可见轮廓清晰,检测出的运动目标非常完整,很好地解决了传统三帧差分算法内部空洞的问题,具有很强的抗干扰能力。检测效果对比图如图4所示。
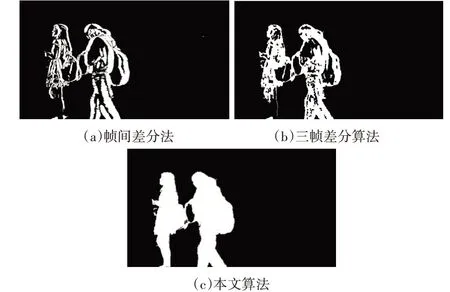
图4 检测效果对比图
4.2 监控视频智能存储
当监控画面中有运动物体时,经过本文运动目标检测算法,可以提取出运动目标(即白色的前景图像)。而当监控画面中没有运动物体时,经过本文算法二值化后得到的是全黑的图像。图像是由一个个的像素点组成的,如果所有的像素点的值都为0,则判断为没有运动目标。
以华北理工大学校园内三处监控摄像头作为实验对象,分别为兰园2号楼一层自习室门口、兰园2号楼五层楼道、图书馆三层电梯间门口。根据实际调查,这几处摄像头每天录下的视频会全部保存,保存时长为三个月。然而,在这种存储方式下保存的视频很多是没有意义的。比如,当监控画面中没有人走动时,录下来的全部是静态的背景视频,可以直接删除。本实验选取了三个监控点,每个监控点分别取三个时间段的视频作为实验数据,得到的结果如表1所示。
监控点A位于自习室门口,正常从这里经过只要短短几秒钟,由表1中数据计算得出,有98%的时间是没有运动目标的。监控点B位于宿舍楼道,早上7:00~8:00是洗漱和出行人数最多的时间,这个时候有运动目标的视频段数也是最多的。由表1中数据计算得出,在实验的这三个小时中,有52.7%的时间是没有运动物体经过的。监控点C位于电梯间门口,可以看出除了等电梯和进出电梯时有运动物体之外,其余67.8%的时间是没有运动物体的。实验表明,将这些没有运动目标的视频图像直接删除,保留下来的都是有用的信息,节省了大量的存储空间。

表1 监控视频智能存储实验结果
5 结语
在边缘计算模型的背景下,为了实现监控视频图像的智能存储,本文提出将网络摄像头加入计算分析能力。在传统三帧差分法的基础上加入了最大类间方差阈值计算方法,因而检测出的前景图像既不会失真也没有大量噪声,Canny边缘算子的加入使得前景图像的轮廓更为完整。实验表明,本文算法能够检测出完整的运动目标,可以自动检测和分析监控范围内的运动物体,并对视频选择性存储,节省了大量存储空间。
猜你喜欢
上海师范大学学报·自然科学版(2022年3期)2022-07-11
重庆大学学报(2022年2期)2022-02-28
汽车工程师(2021年12期)2022-01-17
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
扬州大学学报(自然科学版)(2021年6期)2021-02-14
当代陕西(2020年14期)2021-01-08
智能计算机与应用(2020年4期)2020-08-31
奥秘(创新大赛)(2020年7期)2020-07-27
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
