
时态RDF数据的不一致性修复和预处理
2019-01-07 05:21:56张燕超
计算技术与自动化 2018年4期
张燕超
(南京航空航天大学计算机科学与技术学院,江苏南京210000)
资源描述框架 RDF(resource description framework)是由万维网协会W3C提出的一个语义框架[1],被广泛应用在描述语义网[2]中的各类海量数据,可以用三元组(主语、谓语、宾语)的形式来描述语义网上的任何数据。
随着计算机技术和信息技术的深入发展,语义网中的时态RDF数据也在快速的累积中,RDF数据的涉及到各个领域。时态信息在信息系统中扮演着日益重要的角色,时态RDF数据的一致性检测和恢复也有助于提高时态RDF数据库系统的可靠性和高效性[3],特别是对电子商务、数据挖掘、决策支持系统等信息系统有着越来越重要的意义和保障[4-6]。
国内外学者提出了多种类型的时态数据库模型,其中主要是基于关系模型的时态关系数据库以及相应的查询语言[10]。除了关系模型,Chawathe首次提出了管理历史的半结构化数据[11],他扩展了交换对象模型,使它可以表示更新,借助“增量(deltas)”来跟踪它们。Claudio Gutierrez[12]首次提出了对于时态RDF数据模型的建立,添加时间标签来实现数据的时态性,如(s,p,o):[T],其中 T 就是时态信息。后续的时态RDF模型的研究都是在此时态RDF数据模型的基础上进行更多的语义和时间信息的表达上的扩展[13,14],还有进行双时态扩展,同时支持有效时间和事务时间。还有更多的时态和语义的逻辑分析与推理,基本都停留在理论上的分析。
时态数据的一致性研究中文献[7,8]是基于关系数据库的多版本,文献[7]需要追溯过去的版本中的所有的不一致性数据,操作复杂耗时。因为支持多时态多版本XML,恢复数据库的一致性要通过纠正过去的所有错误和不一致性。文献[8]对于时态RDF数据提出了新的框架,确定一个子类的一阶一致性约束,利用调度理论有效的映射到约束图来解决问题。这个方法优于普通的近似启发式算法,但是是对一个子类做出的约束,并不能更好的包含所有时态RDF图,应该一步推广一致性约束。这篇文献是针对于查询中出现不确定性的结果进一步做一致性检测和恢复,存储的数据还有不一致性和不正确性。文献[9]提出了时态XML的一致性要求,并提出了环路检测来检测和修复不一致性,算法思路比较严谨。但是考虑数据不一致性不全面,分类太简单,现实生活中的数据一定会更复杂。因为RDF的特殊性,并不适用于时态RDF数据的一致性分析。
本文是针对添加有效时间标签来扩展的时态RDF数据模型,根据有效时间的现实意义分析时态RDF数据存在的不一致性,并对每一类的不一致性提出了修复的方法,针对执行变化操作时产生的不一致性,进行了预处理的研究,以保护时态RDF数据的一致性,并通过实验验证了可行性。
1 时态RDF数据的不一致性修复
尽管现在从语义网上提取信息的技术有了很大的进步,但是产生的RDF知识库仍然存在大量的噪音和与事实不一致的问题,需要添加一些额外的一致性约束。本节就是根据扩展的有效时间的现实意义,分析时态RDF数据存在的不一致性,根据不同情况进行了分类,并对存在的所有类型的不一致性提出修复算法。
1.1 有效时间的设定
本文研究的时态RDF模型是用时间标签来标记RDF数据三元组,且表示有效时间。以下就是时态RDF模型的基本定理。
定义1一个时态RDF数据的组成分为两部分,时间标签和 RDF 三元组,用符号表示(s,p,o):[t].(s,p,o):[t1,t2]表示{(s,p,o):[t]|t1≤t≤t2}。
其中SPO代表RDF三元组中的主体、谓词和客体。t是一个自然数,用来代表时间,表示在t时刻s的p属性值为o是有效的。
定义 2 时间区间[start,end]中,start+1≤end,单位时间设为1;
为了表示时间上的连续,即使使用秒数作为单位时间在现实中时间也是不连续的,为了下文的使用方便和自然,将单位时间设为1,t和t+1两个时刻就表示是时间上的连续。
1.2 三元组重复的不一致性修复
主体、属性、客体都是相同的,即RDF三元组是一样的,表示为(s,p,o)[T1]和(s,p,o)[T2],其中T1和T2只要有重合的部分就是存在三元组重复不一致性。
对于T1和T2间断,可以解释为在T1和T2时间段内s的p属性值为o,但是在T1和T2间隔的时间内这个信息失效了,所以不存在不一致性。
修复重复三元组不一致性,用R代表(s,p,o)[start,end])是一条时态RDF数据记录,Ri表示第i条记录,Ri+1就是下一条记录。首先在时态RDF数据库中的记录中匹配(s,p,o)三元组,找到三元组完全一样的时态RDF数据记录,通过比较两个时间区间的起始时间点和结束时间点,计算出修改时间区间,对一条记录的两个时间点进行修改,再删除另外一条记录。
算法1 修复三元组重复的不一致性
FixSameRDF(){
(1)Group by SPO;
(2)Foreach R have same SPO
(3)gathe of T[start,end]
(4)If T have superposition;
(5)//时间完全重合,就删除记录
(6)Then{
(7)if R1.T incloded R2.T delete R2
(8)else{//修改时间点,使时间连续
(9)R.end=start+1;
(10)or R.start=end-1;}}}//T变连续
1.3 生命区间的不一致性修复
定义3(节点的生命区间lifespan)节点的生命区间是这个节点的所有入边和出边的有效时间的并集的最大集合。在只有(s,p,o)[start,end]一条数据的情况下,lf[start,end]就是节点s和节点o的生命区间。
计算节点的生命区间要包含节点的所有出边和入边的有效时间。通过遍历并计算所有边的有效时间的并集的最大集合,也就是找到最早的开始点和最晚的结束点。
算法2 计算节点的生命区间
输入:节点的URI(唯一性)
输出:节点的生命区间lf[start,end]
Lifespan(URI){
(1)Initialize lf[start,end]lf.atart=null,lf.end=null;
(2)for each(s,p,o)[start,end]{
(3)if(URI==s||URI==o){
(4)if(lf.start==null)lf[start,end];
(5)//lf取范围大的时间点
(6)Else{lf.start=MIN(lf.start,start);
(7)lf.end=MAX(lf.end,end);}}
(8)Return lf;}
记录的有效时间T超过S和O的生命区间就是存在生命区间的不一致性。
只有s和o有效存在,s的p属性值为o的信息才会有意义,否则就是与事实不一致。
对于生命区间的不一致性修复,需要修复所有不一致性出入边的有效时间,首先在记录中匹配s,找到节点所有相关记录,再通过比较两个时间区间的起始时间点和结束时间点,计算出保持一致性的有效时间区间,对边的记录的两个时间点进行修改,或直接删除这条出边信息的记录。
算法3 修复生命区间的的不一致性
FixLifespan(){
(1)For each node(URI)n do
(2)lf=lifespan(URI);
(3)group by R.O gathe of T[start,end]
(4)foreach T
(5)if(lf and T have superposition)
(6)//缩小记录的时间区间,包含于节点的lf
(7)then{R.start=lf,start||R.end=lf.end}
(8)if(lf and T have no superposition)
(9)//没有重合就删除记录
(10)then deled R;}
1.4 发散性属性的不一致性修复
主体和属性相同,不同或相同的客体,表示为(s,p,o1)[T1]和(s,p,o2)[T2],其中 T1 和 T2 有效时间有重叠就存在发散性属性不一致。例如一个人的体重属性在同一时刻的体重值就是唯一的。
发散性属性的不一致性修复,需要对具有发散性p属性的记录进行分类,按照s分为不同的记录子集,重复的有效时间就缩小有效时间区间。需要修复所有节点的p属性不一致性出边。
算法4 修复发散性属性的不一致性
CheckDivergent(p){
(1)collection of R.p=p,{R.s}is grouped by different R.s
(2)foreach{R.s}gathe of T[start,end]
(3)if(T1 and T2 have superposition)
(4)//缩小时间区间,使得有效时间连续
(5)then {R2.start =R2.end -1 or R1.end=R2.start-1}
(6)if(T1 included T2)
(7)//完全重合就删除记录
(8)then deled R2;}
1.5 收敛性属性的不一致性修复
主体不同或相同,但是属性和客体相同,表示为(s1,p,o)[T1]和(s2,p,o)[T2],其中 T1 和 T2 有效时间有重叠就是存在收敛性属性不一致。例如手术室O1在同一时刻只能有一个病人在做手术。
收敛性属性的不一致性修复,将包含p属性的记录按照O分为不同的记录子集,重复的有效时间就缩小有效时间区间。
算法5 修复收敛性属性的不一致性
CheckDivergent(p){
(9)collection of R.p=p,{R.o}is grouped by different R.o
(10)foreach{R.o}gathe of T[start,end]
(11)if(T1 and T2 have superposition)
(12)//缩小时间区间,使得有效时间连续
(13)then{R2.start=R2.end-1 or R1.end=R2.start-1}
(14)if(T1 included T2)
(15)//完全重合就删除记录
(16)then deled R2;}
2 变化操作的不一致性预处理
对于时态RDF数据的添加、修改和删除都可能会造成上文中提出的不一致性问题,因此需要对插入操作、删除操作和更新操作的时态RDF数据首先进行检测与分析,是否会造成4种类型的不一致性,如果存在不一致性问题就要通过修改新的时态RDF数据来进行修复,使得操作后的数据库中的时态RDF始终保持一致性。
2.1 插入操作
插入一条新的时态 RDF 数据 (s,p,o)[start,end],考虑存在的不一致性类型,对不存在的s、p、o,在操作执行后还要建立新的URI,节点o和节点p的生命区间也要计算添加。
第一步:当s和o同时已经在时态数据库中存在,需要对两个节点的生命区间的交集作为生命区间lf进行生命区间的不一致性检测和修复;只有一个节点存在,对这个节点的生命区间进行生命区间的不一致性检测,执行操作,设置另一节点的生命区间为最终的有效时间;两个节点都不存在,执行操作,创建两个节点的URI,并设置两个节点的生命区间为[start,end]。

图1 生命区间和插入数据的有效时间关系
如图1所示,实现表示生命区间,虚线是插入数据的有效时间[start,end]。情况 1:在[start,lf.start-1]和[lf,end+1,end]的两段时间,节点不存在,存在生命区间的不一致性,修改插入数据的有效时间为[lf.start,lf.end];2:[start,end]与 lf有间隔或连续,不一致性的时间为[start,end],不执行插入操作;3:生命区间一致性;4:[lf.end+1,end]时间内,存在不一致性,修改插入数据的有效时间为相交的时间[start,lf.end]。
第二步,当p和s存在且p是发散性属性,需要检测修复s的p发散性属性不一致性,如果插入操作执行,但是o不存在,o的生命区间为修改后的数据的有效时间。
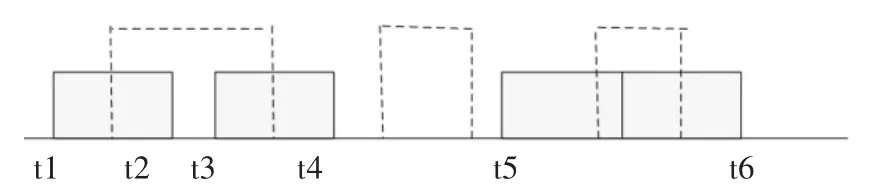
图2 发散性属性出边的有效时间关系
如图2实线为s的p属性的有效时间,虚线是要插入数据的有效时间。情况1:在[start,t2]和[t3,end]有两个p属性值,存在发散性属性的不一致性,但[t2+1,t3+1]有间隔,将插入的数据的有效时间修改为[t2+1,t3+1];2:p 属性一致性;3:在[start,end]内s有两个p属性值,存在不一致性,不执行插入操作。
第三步,当p和o存在且p是发散性属性,需要对o进行p属性的收敛性属性不一致性检测和修复,如果插入操作执行,s不存在,s的生命区间为修改后数据的有效时间。
找到p属性值是o的所有记录的有效时间,与图2的情况相同,情况1:存在收敛性属性不一致性,将插入的数据的有效时间修改为[t2+1,t3+1];2:p 属性一致性;3:[start,end]内都存在 p 属性的不一致性,不执行插入操作。
第四步,当spo都存在时,进行三元组重复的不一致性检测与修复。
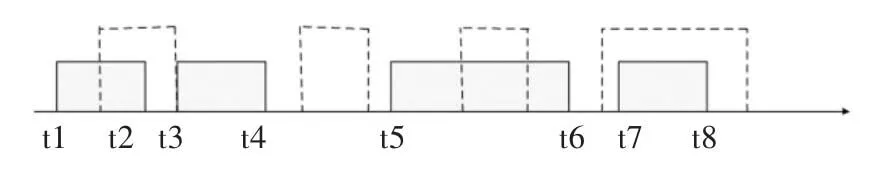
图3 (s,p,o)所有的有效时间关系
如图3 所示,实线是(s,p,o)的所有有效时间,虚线是插入的有效时间。情况1:时间的重叠存在三元组重复的不一致性,修改插入数据有效时间为[t1,t4],并删除记录(s,p,o)[t1,t2]和(s,p,o)[t3,t4];2:不存在三元组重复的不一致性;3:不一致性时间区间为[start,end],不执行插入操作;4:[start,end]包含[t7,t8],只需删除记录(s,p,o)[t7,t8]。
分情况按照上述的步骤进行所有类型的不一致性检测和修复,如果执行插入操作,就将spo中不存在的创建URI,并对节点添加生命区间。
2.2 删除操作
删除一条时态 RDF 数据(s,p,o)[start,end],当spo中的一个或多个不存在时,就不执行删除操作。

图4 相同三元组的有效时间的关系
如图4 所示,实线是(s,p,o)的所有有效时间,虚线是要删除数据的有效时间。情况1:[start,end]包含[t1,t2],或者相等,直接删除(s,p,o)[t1,t2]记录;2:(s,p,o)在[t1,start-1]的时间内有效,修改记录(s,p,o)有效时间为[t1,start-1];3:(s,p,o)在[start,end]的时间内无效,删除操作不用执行;4:(s,p,o)在[t3,start-1]和[end+1,t4]时间内是有效的,修改记录(s,p,o)有效时间为[t3,start-1],再插入一条记录(s,p,o)[end+1,t4]。
(s,p,o)的有效时间的缩小并不会造成任何的不一致性,要对相应的记录做修改,而不是直接匹配一模一样的数据记录进行删除。
2.3 更新操作
更新操作可以分为两部分,首先是删除原有的数据,再插入新的数据。
更 新(s,p,o)[start,end]为(s’,p’,o’)[start’,end’]。首先找到(s,p,o)[start,end]所对应的记录。情况与图4 一样,情况 1:[start,end]包含[t1,t2],或者相等,最后要删除的记录就是(s,p,o)[t1,t2];2:修改记录(s,p,o)[t1,t2]为[t1,start-1];3:不执行更新操作;4:修改记录(s,p,o)[t3,t4]为[t3,start-1],再插入一条记录(s,p,o)[end+1,t4]。
找到相应的记录后,插入(s’,p’,o’)[start’,end’],对这条新时态RDF数据也要进行4种类型的不一致性的分析,如果不执行插入操作,说明存在不一致性,不执行更新操作,在之前找到相应记录的分析作废,也就不用修改记录了。
3 实验结果
本节是对上文中提出的时态RDF数据的不一致修复和变化操作的不一致性预处理进行了实验验证。在LUBM(Lehigh University Benchmark)标准数据集的基础上随机生成有效时间添加时间标签,在对不同数量的数据集上分别进行了实验,并进行对比和说明,实验环境如表1所示。

表1 实验环境
首先检测500条时态RDF数据的不一致性,首次计算节点的生命区间。左边就是存在不一致性数据,右边是修改后的一致性数据。
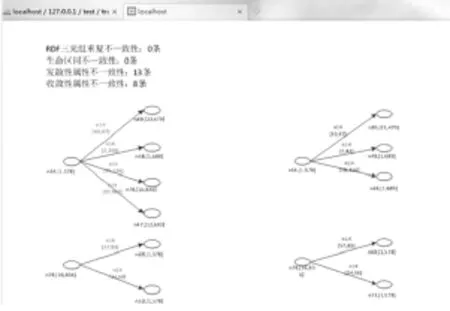
图5 时态RDF数据存在的不一致性
下图是逐渐增加数据且修改后产生的不一致性的折线图:
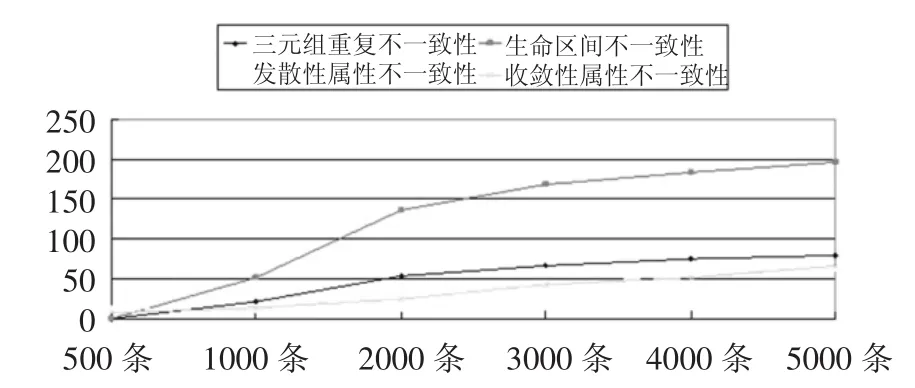
图6 不同数量时态RDF数据存在的不一致
每增加1000条时态RDF数据,产生的每一种不一致性是在逐渐增加的。生命区间的不一致性产生的数量最多是因为节点的生命区间是由500条时态数据产生,后续的有效时间随机产生,超过生命区间可能性很高。
对于变化操作的预处理实验采用5000条一致性的时态RDF数据的数据集。
图7是插入的500条数据中存在的不一致性分布情况,白色的柱状图表示可以修复的不一致性,插入修改后数据;黑色的柱状图是无法修复的不一致性,只能放弃执行插入。
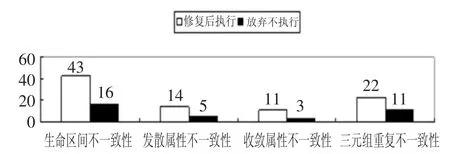
图7 插入500条数据存在的不一致性
图8是删除300条数据造成不一致性的修复情况,有213条数据不能直接删除,有176条数据不一致性修复后删除,有37条数据找不到对应的记录,不执行删除操作。
图9是更新150条数据存在不一致性的情况,没有对应删除的数据有26条,不更新,有125条更新后的数据存在不一致性,白色的柱状图表示有90条数据修复后更新,35条数据不执行插入操作。

图9 更新操作的不一致性情况
4 结束语
针对支持有效时间的时态RDF数据进行了在有效时间上的不一致性研究和分析,分别是三元组重复的不一致性、生命区间的不一致性、发散性和收敛性属性的不一致性,并对4种类型的不一致进行了修复,对于更新的时态RDF数据,针对每种变化操作,即插入、删除和更新,分析了每种操作的不一致性预处理方法。
未来工作:1.时态RDF数据会时常更新,修复不一致性消耗太大,修性算法的效率还有待提高。2.对于支持有效时间的时态RDF数据之间的推理、蕴含等内置函数和数据间关系和结构都没有讨论和研究。3.对有效时间的确定与验证没有进行讨论,对于不确定时间的处理也需要另行研究。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
公民与法治(2022年5期)2022-07-29 00:47:28
教学考试(高考物理)(2021年5期)2021-11-08 10:31:22
中医眼耳鼻喉杂志(2021年1期)2021-07-22 07:38:14
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
家庭影院技术(2021年2期)2021-03-29 07:18:22
疯狂英语·新策略(2019年12期)2020-01-04 02:48:06
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
燕山大学学报(2015年4期)2015-12-25 02:19:49
现代防御技术(2014年6期)2014-02-28 18:26:29
