
几种开源英语识别工具包的对比分析
2019-01-07 05:21:54刘琼
计算技术与自动化 2018年4期
刘 琼
(西安航空职业技术学院通识教育学院,陕西西安 710089)
关键字:开源语音识别工具;HTK;Spinx;Kaldi;语言模型;声学模型
在过去的几十年里,大量的连续语音识别系统被开发出来。一方面,诸如AT&T Watson、Microsoft Speech Server、谷歌Speech API和Nuance识别器等十分成熟的语音识别系统已经得到较为广泛的商业应用[1-4]。另一方面,商业语音识别器几乎不能为其他专用系统提供接口功能,使得对其他软件实现本地的功能集成造成极大限制,导致大量开源自动语音识别系统成为研究热点[5-6]。
由于开源语音系统的数量不断增加,越来越难以准确理解哪一种最适合给定目标应用的需求[7]。将通过实验的方法比较目前较为主流的开源大词汇量语音工具包的可用性和识别准确率。对比的开源语音识别工具包括:HDecode(v3.4.1)、Julius(v4.3)、Pocketsphinx(v0.8)、Sphinx4、Kaldi。
本研究使用一个自行录制的实验语料库应用于四个语音识别工具包的对比分析中。为了使得本文的对英语识别结论具有较好的普遍性,因此使用阅读式语料而不是对话式的语料。研究的最终目标是通过开源语音识别工具包的全面评估,为提高英语语音识别系统的口语理解能力提供参考。
1 对比数据
研究使用的英语语料库包含4男4女,内容为大声朗读的人民日报英文版。语料库包括训练集、开发集和测试集。语料库的详细信息如表1所示。
2 声学建模
2.1 HDecode和Julius声学模型
解码器HDecode和Julius的声学模型使用HTK工具包进行训练。HTK工具包提供了一个很好的参考文档和一个包含基本功能的训练示例,这为进一步进行深入开发提供了较好的帮助,有效提高了开发效率[8]。
基于HTK参考手册所提供的功能描述搭建本研究的训练方法。HTK工具包中的语音文件操作软件HCopy软件将音频数据从语料库中的语音文件转化为具有零阶梅尔频率倒谱系数和倒频谱均值归一化的特征文件[9]。主要编码参数如表2所示。

表2 编码参数
单声道训练包括静音处理和重新排列,以增强发音和声学数据之间的匹配。在训练的每一步中,都会执行四次Baum-Welch算法以重估训练结果。
在完成单音符训练后,使用了几个接收器来训练单词内部和单词之间的音素。尽管单词内部音素参数是默认设置,但是单词之间的音素参数是HDecode解码器所必需的,并可作为Julius的选项进行测试。对于捆绑和合成看不见的音素状态,使用基于决策树的集群。将隐马尔可夫模型与高斯混合的训练分离,首先在两个步骤中完成,之后是预先设定的步骤。
在单词之间的三音素的识别训练时,基于树的聚类的细节以及用混合高斯训练模型的方法必须由用户进行自定义开发。还有更多先进的技术,例如个性化适应和区分性训练来提高识别系统的可用性能,但是这种工具链的开发费用显着增加,没有丰富的知识就不可能建立起来,所以我们在比较中没有使用这些技术。
2.2 Pocketsphinx和sphinx4声学模型
pocketsphinx和Sphinx-4的声学模型使用CMU sphinxtrain(v1.0.8)工具包进行了训练,sphinxtrain工具包提供了训练特征文件的所有必要工具。配置参数都可以很容易地设置在配置文件中,因此不需要编写对应的配置脚本[10]。但是在构建语音识别器的过程中,需要由相当的程度的专业知识,因为sphinxtrain的参考文档支持度不够。
除了连续的声学模型,sphinxtrain还可以训练半连续高斯混合模型[11]。这些模型接受了梅尔频率倒谱矢量的训练。在默认情况下,sphinxtrain与HTK相似,由13倒谱系数、13个变量增量和13个加速系数组成。进一步的特征提取参数如表3所示。此外,本文利用线性判别分析,最大似然线性变换(LDA+MLLT)来减少特征维数。

表3 sphinx特征提取参数
与pocketsphinx相比,Sphinx-4仅限于连续的声学模型。
2.3 Kaldi声学模型
KALDI工具包为不同语料库提供了几个示例性数据准备。这些数据准备的功能包括LDA+MLLT、说话人自适应训练(SAT)、最大似然线性回归(MLLR),特征空间 MLLR(fMLLR)和最大互信息(MMI、FMMI)。Kaldi识别工具包还支持高斯混合模型(GMM)和子空间模型(SGMM)。进一步在基于受限玻尔兹曼机的分层预训练,基于每帧交叉熵训练和序列鉴别训练的GMM模型上对深度神经网络(DNN)进行训练,使用网格框架并优化状态最小值贝叶斯风险准则[12,13]。
Kaldi训练的计算成本很高,需要在技术实现上通过并行计算加以优化,因此在DNN的训练中支持使用GPU实现高并发计算以加快处理速度。
3 语言建模
HDecode和Julius的语言模型是ARPA ngram模型。在语言建模的第一步,使用HTK工具构建工具链的训练,训练的结果文件不能用于外部解码器。然后用CMU语言模型工具包进行语言模型训练。该工具链包含从输入文本中提取单词频率和词汇,并使用text2wfreq和wfreq2vocab生成带有text2idngram和idngram2lm的ARPA语言模型文件。使用Julius将ARPA文件转换为二进制格式,直接与HDecode一起使用,并使用工具mkbingram加速ARPA文件的加载[14]。
Sphinx同样使用的CMU语言模型工具。其中ARPA文件也使用mkbingram转换为二进制格式,以提高解码的效率[15]。
Kaldi语言模型由于其内部表示为有限状态转换器,因此要求将上述工具所训练的ARPA语言模型转换为特定于解码的二进制格式[16]。为此,需要使用了工具arpa2fst、fstcompile和多个Perl脚本等一些实用工具对ARPA语言模型进行格式转换。
4 实验过程
4.1 HDecode和Julius
首先构建HDecode和Julius的语言模型。在第一步中,本文将n-gram顺序增加到四,发现三个是对实验语料库的最佳选择。观察三个阶段的最佳结果,决定将这些结果用于其他解码器。在测试运行中,本文使用了HDecode和Julius的ARPA trigram语言模型。在第二步中,本研究比较了不同的模型初始化参数构建n-grams语言模型。通过对比发现Witten-Bell discounting是语料库和Julius的HDecode的最佳选择。
其次是构建声学模型。由于声学模型的参数数量太多,因此构建声学模型的重点是性能调优。调优过程是一个相当困难的任务,有许多自由度,覆盖它们几乎是不可能的。本文对以下参数进行调优研究。
对Julius使用单词内部与单词之间音素识别的影响。在对实验语料库开发集进行了大量实验之后,发现采用单词之间的音素识别是更好的选择。
基于状态和基于决策树的集群配置。在树状结合状态下,测试了不同的问题集。测试的主要目的是区分辅音(摩擦音、爆破音、滑音、鼻音、流音)和元音(前元音、中元音、后元音)。还要对消除异常噪音的阈值(RO)、绑定状态和决策树修剪阈值等参数(TB)可用性进行测试。在测试中,本文采用基于决策树聚类的训练模型。解码实验语料库测试集与HDecode一起使用的模型具有2300个绑定状态(RO 100,TB 1250),Julius 2660 绑定状态的模型(RO 100,TB 1000)。在实验语料库上,用于两个解码器的所用模型具有6571个绑定状态(RO 100,TB 2500)。这些参数的选择是基于我们在开发集上的大量调试运行中产生的最佳结果,并根据参数建立一组准确度值。
混合数量和分裂策略。根据已有的研究成果,HDecode和Julius的最佳高斯混合数量为32和24。在第一次测试运行中,使用了分裂为两次幂的混合物。基于使用较小的步骤以提高性能的考虑,因此稍后的测试运行中使用了增加高斯数量的预定义步骤(1-2-4-6-8-12-16-24-32-48-64)。
解码器的构建。解码器可以有多种不同的配置。通过对HDecode的实验,得出最优参数为:字插入代价为0、语言模型的权重为10、修剪阈值为150。总结出的Julius评估的解码参数如表4所示。表4中的参数值增加了计算资源的使用,减缓了解码过程,但提高了识别的准确性。

表4 解码参数
4.2 Pocketspinx和Spinx4
根据前面的HTK解码器研究,对Pocketspinx也采用ARPA trigram语言模型。
在HTK解码器的研究已经对声学模型的参数调优进行实验。针对Pocketspinx识别工具包的特点,基于对以下参数的调优构建的声学模型。
半连续和连续模型的影响。在使用两种模型类型的默认参数的第一个评估周期中,本文发现连续声学模型比半连续声学模型在开发集上的效率为36.10%。
通过基于最大似然度变换(MLLT)的LDA算法来减少混合和音素的数量并减少特征矢量的数量。如表5所示,将维数从39个减少到32个,结果识别错误率提高2%。在实验语料库的测试中,使用了每个句子64个混合词、1750个句子以及LDA+MLLT的模型。
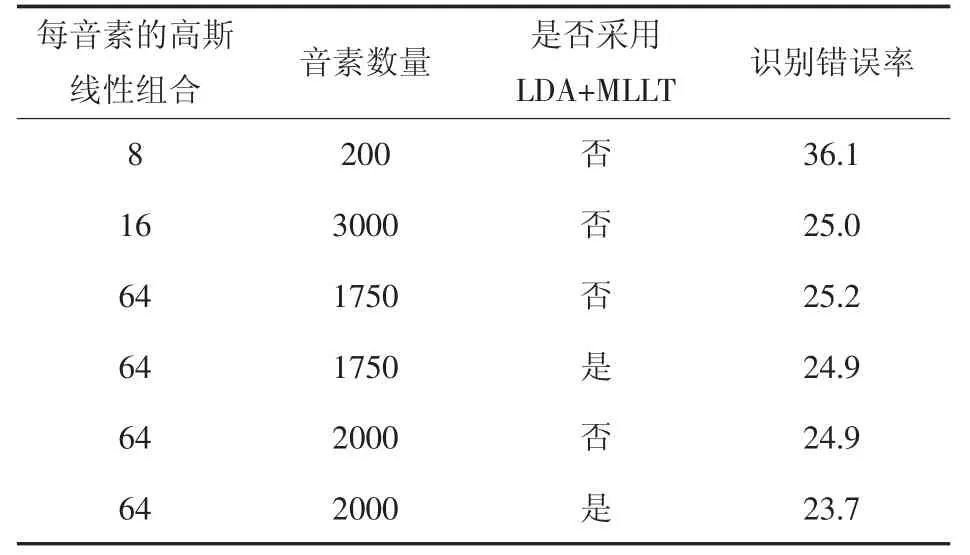
表5 在实验语料库开发集上测试pocketsphinx
在Pocketspinx的实验中,除了表5中所示的特征提取参数以外,其他均使用Pocketspinx语音解码器的默认参数。
4.3 Kaldi
首先建立语言模型。针对实验语料库,将用于pocketsphinx和Pocketsphinx的ARPA trigram模型转换为Kaldi所需的有限状态转换器表示。在转换过程中使用了预定义的训练脚本,其中包括生成4-gram语言模型。
其次是建立声学模型。在所有的Kaldi的测试运行中,使用预定义培训脚本,这些脚本仅针对输入数据进行了调整。在测试运行中,在实验语料库中使用具有LDA+MLLT+SAT+fMLLR的GMM模型之上的DNN。
最后是解码器的配置。在所有的Kaldi的测试运行中,本研究都使用预定义的解码脚本。
5 结果分析
不同识别工具在实验中的错误率结果如表6所示。

表6 在实验测试集上的错误率
由表6的可以看出,与其他识别器相比,Kaldi具有更好的识别正确率。
在实验中,花在设置、准备、运行和优化工具包上的时间最多的是HTK,更少的Sphinx和最少的Kaldi。
Kaldi的出色表现可以看作是开源语音识别技术的一场革命。该系统能够提供方便调用的LDA、MLLT、SAT、fMLLR、fMMI和 DNNs等十分全面先进的技术。即使系统开发者不是语言识别的专家,也能够使用Kaldi所提供提供的菜单和脚本也能在短时间内完成系统的集成。
Sphinx系列的语音工具包也提供了一个声学模型训练工具,但是所提供的训练工具不够全面,导致训练精度不高,但在Sphinx系列的语音工具包声学模型的训练和语音识别也较为简便。
HTK是使用最困难的工具包。建立系统需要声学模型训练工具的开发,这个过程费时且容易出错。基于HTK的语音识别系统的开发和集成需要开发者具有较好的专业语音识别领域的专业知识和熟练的开发技巧。
6 结论
对较为主流的开源语音识别工具包的进行的较为全面评估。在试验评估中,本研究训练了HDecode、Julius、pocketsphinx、Sphinx-4 和 Kaldi的语言和声学模型,部分调整和优化了识别系统的参数,并在试验英语语料库上进行了测试。实验结果显示了Kaldi超越了所有其他的识别工具包的识别正确率,并且Kaldi工具包还提供了较为全面的先进声学模型训练技术的支持。Kaldi工具包这些特点便于在短时间内实现最佳识别结果,但是其计算成本也是最高。Sphinx工具包提供了仅次于Kaldi的声学模型训练技术的支持,但是其训练效率优于Kaldi。Sphinx需要用户开发高级部件进行广泛的性能调优。HTK提供了最简单的启动工具包,需要开发者自行开发自训练的识别系统来达到的所需的识别性能。
猜你喜欢
Asian Pacific Journal of Tropical Biomedicine(2023年7期)2023-08-07 08:13:36
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2020年6期)2020-07-27 01:37:54
家庭影院技术(2019年8期)2019-12-04 14:43:19
家庭影院技术(2019年1期)2019-01-21 02:25:04
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年10期)2018-11-02 05:35:26
中国计算机报(2018年29期)2018-11-01 06:14:46
