
基于QoS感知的再制造服务选择模型
2019-01-03 02:51苏梅月王丹妮
组合机床与自动化加工技术 2018年12期
吴 冲,潘 莉,苏梅月,陈 乐,王丹妮
(武汉科技大学 a.冶金装备及其控制教育部重点实验室;b.机械传动与制造工程湖北省重点实验室,武汉 430081)
0 引言
随着时代的快速发展,制造业和服务业之间相互融合,“制造服务”由此而来[1-2]。再制造服务就是一种以再制造服务平台为基础,用户通过网络可以随时获取,按需使用的制造服务。但是大量的服务也带来了巨大的信息量,用户如何在参差不齐的服务信息中选择符合自己要求的再制造服务,实际上就是一个衡量服务综合质量(QoS)的问题。
在进行QoS综合性能排序时,需要考虑以下三个问题。首先,在再制造服务过程中,由于缺少有效检测机制,用户可以随意夸大或诋毁服务的质量,这就需要判断数据的可靠性,其次,如何在巨大的历史信息中获取再制造服务的QoS属性值,最后,如何在海量的信息中高效的选择满足客户需求的最优服务。这就需要通过计算指标间的权重并进行多目标决策,最后根据排序结果选择最优服务。
目前有关制造服务的QoS评价方法研究较多,如:文献[3]建立了云服务QoS评价模型,采用ANP 方法计算出结果进行综合排序;文献[4]结合引入模糊DEMATEL并构建了物元模型,提出了基于QoS的再制造服务评价方法;文献[5]在进行QoS排序计算时,考虑了用户的满意度,但忽略了QoS指标间的权重关系;文献[6]构建了制造资源Trust-QoS评估模型并给出了量化评估算法。这些文献对再制造服务评价模型的构建有一定的借鉴意义,但再制造服务作为一种新的服务,区别于传统的制造服务,本文提出了一种基于QoS感知的再制造服务选择模型,通过建立合适的QoS评价指标,基于协同过滤思想分析校正历史数据,调整或弱化用户的主观性因素,过滤恶意攻击数据。利用可变精度粗糙集挖掘出各评价指标之间的权重,并与客户需求事先设定的评价指标权重相结合,计算出理想服务与现实服务的相似度,以此作为选择依据。
1 再制造服务的QoS评价模型与信息量化
1.1 再制造服务
再制造服务是以废旧产品为研究对象,旨在满足客户多样化的制造服务要求,以再制造服务平台为基础,对再制造企业在整个产业链上运作过程中与客户相关的价值增值活动提供服务[7]。再制造服务平台的开放性决定了再制造服务具有动态性和多样性。动态性是指再制造服务会根据用户的需求随时对再制造资源和活动进行动态调整和重新组合;多样性则是指在再制造服务平台上存在着大量的参差不齐的再制造服务,这些服务功能相似但质量良莠不齐。
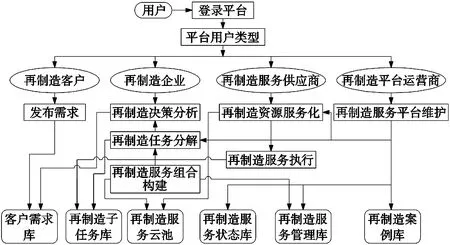
图1 在制造服务平台工作流程
再制造平台运营商主要为再制造客户以及再制造企业提供服务。再制造客户通过在再制造服务平台发布自身需求的再制造服务,平台接收到请求后检索再制造服务云池为客户推荐最优服务,在客户确认后联系再制造企业完成再制造任务。再制造服务供应商的主要工作是将再制造企业的再制造资源服务化并录入再制造服务云池。
1.2 QoS评价体系
QoS是用户用来衡量服务质量的综合效果。本文在以往关于QoS指标的研究基础之上,结合再制造服务的两大特性优化了再制造服务的QoS评价指标。
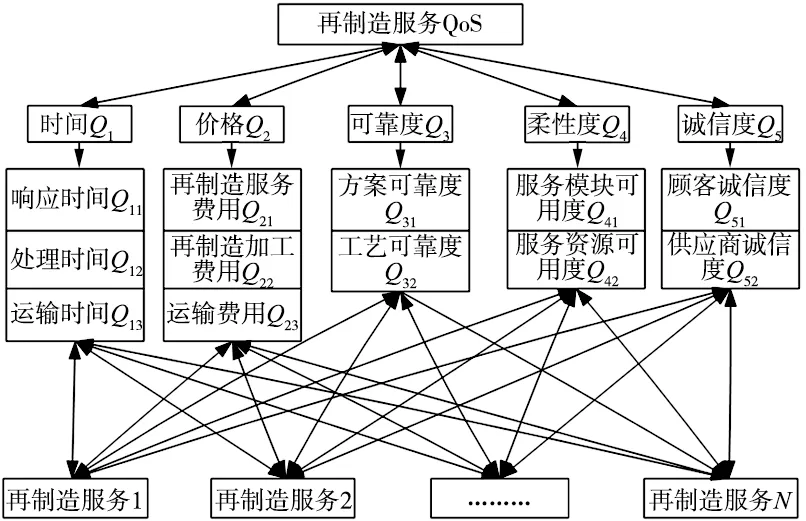
图2 再制造服务QoS评价模型体系
其中,时间Q1由再制造服务的响应时间Q11、再制造产品的加工时间Q12,以及再制造服务的物流运输时间Q13三个部分组成,即Q1=Q11+Q12+Q13。
价格Q2由再制造服务费用Q21,再制造加工费用Q22以及运输费用Q23三个部分组成,即Q2=Q21+Q22+Q23。
可靠度Q3表示再制造服务的可靠度,即一定时间内再制造服务的正常运行能力。设服务S在(t1,t2)内被调用了N次,正常响应的次数为Na,则Q3=Na/N。
柔性度Q4是指发生意外时,再制造服务平台调整服务资源来重新满足用户需求的再制造服务能力。设一定时间内再制造服务发生异常的次数为M,再制造服务能够调整服务资源来重新满足用户需求的次数为Mr,则柔性度表示为Q4=Mr/M。
诚信度Q5是指在再制造服务过程中,由于一些客户会给出一些虚假的评价,影响了服务供应商的信誉。本文通过对数据进行采集并加以分析处理,得到该服务的平均诚信度,值区间为(0,10)。
1.3 再制造服务质量信息与量化
再制造服务质量信息主要分为两类,一类是再制造服务网络性能的QoS指标,主要包括服务调用次数和正常响应次数,这类信息的参数值可直接在再制造服务平台获取;另一类是再制造服务的制造资源QoS指标,主要包括运输成本和加工时间等,由于这类信息的评价值由用户直接提供,因此可以在再制造服务平台中获取。确定了再制造服务质量信息来源之后,再对收集来的数据按照各评价指标的属性分类并进行规范处理,得到再制造服务的QoS综合指标。
设s={s1,s2,…sn}为再制造服务平台中能提供同类服务的候选服务集,每个候选服务的QoS属性值可以用向量qi={qi1,qi2,…qim}表示,则:
(1)
由于不同的QoS属性值差异很大,因此在计算综合效能时需要对QoS属性值进行归一化处理。本文采用文献[8]给出的统一量化效用函数:
(2)
(3)

(4)
2 基于QoS的再制造服务选择模型
2.1 用户评价诚信度计算
在再制造服务过程中,关于用户对于服务提供商的评价,由于缺少有效的管理以及可信服检测机制,用户可以随意夸大或诋毁服务的质量,造成了再制造服务平台提供的QoS推荐值与实际服务评价出现偏差。为此,在再制造服务平台中加入监测器,对所得到的数据进行核查,能够有效降低不合理数据对结果的影响。在核查客户评价值时,采用的是协同过滤的思想,即同类用户使用相同的服务,最后对该服务的评价也应大致相同。
假设两个客户使用过的相同服务集合为s={s1,s2,…sk},则a客户对已消费的k个服务给出的评价为Ea:{(s1,a1),(s2,a2),…,(sk,ak)},同理,Eb:{(s1,b1),(s2,b2),…,(sk,bk)},两向量的相似度用夹角的cos表示,通常余弦值越大,相似程度越高[9]。则客户a和b的相似度可以表示为:
(5)
同理,设E={e1,e2,…em}为与a客户同类型的客户集,假设有m个同类型客户,如果a对服务s的评价值为ha,则第i个用户给出的评价为hi,则评价均值:
(6)
该客户评价的可信程度可表示为:
(7)
最后,将ha×R的值作为最终的评价值写入数据库。
2.2 权重计算
基于QoS的再制造服务选择是一个典型的多目标决策问题,需要对再制造服务信息进行处理之后,综合考虑QoS的性能指标,权衡指标间的重要程度。在进行多目标决策问题上,通常采用的是层次分析法计算权重,但该方法的评价值易受主观因素影响,得到的结果也不够客观。因此本文引入粗糙集理论(Rough set,RS)计算权重,但现实制造服务中的数据存在一定的噪声和干扰,为了增强RS的抗干扰能力,文献[10]提出了一种变精度粗糙集模型,通过引入一个精度β,可以将集合推广到任意精度水平β∈[0,0.5),当β=0时为经典的RS模型。
设I=(E,A=C∪D,V,F)为再制造服务QoS信息决策系统。其中:E为实例对象有限论域的非空子集,E={X1,X2,…,Xn}表示n条历史记录;A为QoS属性的非空有限集合,C={a1,a2,…am-1}为QoS的条件属性集,D={am}为决策属性集;V为属性集合的值域;F为每个属性映射到值域的信息函数。
设X和Y为有限论域的非空子集,如果有X∈Y,∈为偏序关系,则:
(8)
式中,|X|为集合的基数,c(X,Y)表示X关于Y的相对错误分类率。
在再制造服务QoS信息决策系统中,本文设X=E/C={X1,X2,…,X|E/C|}为论域E依据条件属性集C划分的等价类,Y=E/D={Y1,Y2,…,Y|U/D|}为论域E依据决策属性集D划分的等价类。
设β∈[0,0.5),则Yi关于C的β下近似可用以下公式计算:
(9)
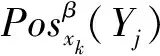
对任一条件属性αP,信息量γ(αP)越大,区分对象的能力越强;被依赖度δ(αP)越大,表示该属性越重要。本文采用以下公式计算:
(10)
(11)
式(10)中Xi为αP划分的各个等价类,|Xi|2为各个等价类的基数。
由于式(10)和式(11)表示属性重要程度的不同方面,因此我们按照两者同等重要并进行归一化处理,得到各条件属性的权重,具体方法如下:
(12)

2.3 再制造服务综合性能计算
在进行再制造服务选择之前,先根据用户的需求以及期望值,对各指标设定一个权重。然后在大量数据中分析得到各个指标权重,最后计算各服务属性最大值向量与权重向量的乘积与用户期望的理想服务向量间的欧氏距离,得到服务Si与理想服务之间的相似度Sim(Si),相似度越大的服务更符合客户需求。
设T=(t1,t2,t3,…,tm)为用户给出的各QoS属性的权重,W=(W1,W2,W3,…,Wm)为粗糙集计算得到的权重,s={s1,s2,…sn}为再制造服务的候选服务集,每个候选服务的QoS属性值用向量qS={q1,q2,…qm}表示,则:
(13)
3 案例分析
3.1 案例分析
床身导轨作为机床的重要零件之一,在机床工作时,导轨极易遭受划伤与磨损。其再制造过程包括机械修整,磨削,刷镀打底层,刷镀工作层,精磨,成品检测,包装入库。某机床厂需要在10天内完成500个再制造导轨的成品检测,当再制造服务平台接收到客户发过来的请求后,将各服务的QoS属性值从再制造服务平台数据库中抽取。再制造服务平台接收到请求后检索再制造服务平台中的资源库,假设有5条再制造服务满足功能需求,再制造服务平台根据价格,时间,诚信度等五个指标来进行决策,其QoS指标值如表1所示。

表1 再制造服务QoS指标值
其中,服务S1中的可靠度的值9/10表示在再制造服务平台数据库中S1被调用10次,正常响应的次数是9次,对应实际情况就是服务S1中标了10次,但是在约定时间内至完成了9次合同。诚信度是所有完成的服务项目评价值的均值,值区间为[0,10],并且诚信度的值都是经过再制造服务QoS监测器校正后的结果。将表1归一化处理后,得到表2。

表2 归一化后的QoS指标值
因为粗糙集的权重计算是从原始数据中分析得出的,为了演示推理过程,从再制造服务平台中随机选取了8条记录作为样本数据。由于不同的服务需要花费不同的价格和时间,因此数据之间没有直接的可比性,所以本文用比值来表示。

表3 样本数据
由于粗糙集只能处理聚类化数据,本文采用文献[10]所述的K中心聚类法,将历史数据库中的数据聚类化处理,聚类群数量为5,聚类化后的数据如表4所示。

表4 聚类化后的样本数据
根据表中数据可知中标决策Y1=U/d1={x1,x2,x5,x7},未中标决策Y2=U/d2={x3,x4,x6,x8},由条件属性a1划分的等价类U/a1={{x1,x2,x5,x7},{x3,x4,x6,x8}},经式(10)可以得到γ(a1)=32/64,同理可得γ(a2)=18/64,γ(a3)=14/64,γ(a4)=34/64,γ(a5)=22/64。
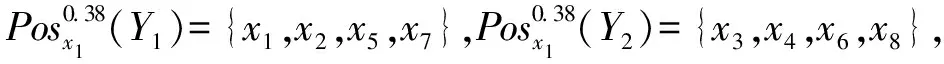
经过式(12)计算得w1=0.279,w2=0.142,w3=0.087,w4=0.282,w5=0.21。
在分析再制造服务平台提供的数据进行分析并且结合专家的建议,初步设定属性偏好权重T={0.35,0.2,0.1,0.15,0.2}。
根据式(13)可以得到sim(s1)=0.818,sim(s2)=0.794,sim(s3)=0.595,sim(s4)=0.76,sim(s5)=0.68,可见最佳服务为s1。
3.2 对比与分析
此外,本文还计算了不考虑QoS指标间相互关系,即各指标权重相同时各个服务的相似度(记作方案2)以及只考虑用户设定的权重,即所有指标权重相同时各个服务的相似度(记作方案3),计算结果见表5。
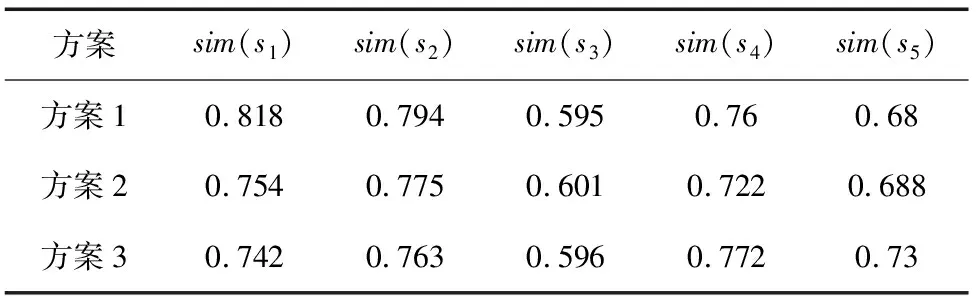
表5 不同方案计算结果
由表可知,方案2中最佳服务是s2。说明即使s2的各项数据都比较中庸,但是由于各个指标的权重相同,因此在整体性能上更占优势。方案3中最佳的服务是s4。说明由于价格的权重比较大,即使s4的时间花费最多,可靠度,柔性度都比较小,但最好的选择还是s4。
最后利用再制造服务平台随机选取了15组不同的再制造服务,每次服务推荐给60位客户,看客户是否接受推荐服务作为实验,并在之前的3种方案基础之前增加了一种没有进行评价值信息校正的方案,记作方案4。实验结果以接受率作为评判标准,实验结果见图3。
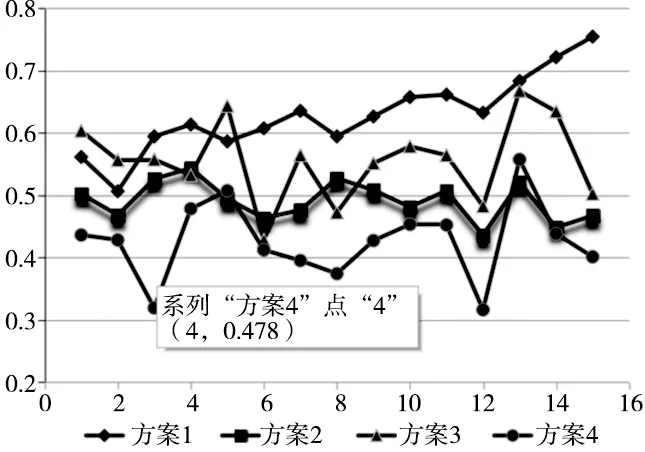
图3 实验结果
可见,方案1跟方案4的差别在于有无对客户评价值进行信息校正,方案1的客户接受率一直稳定在较高的数值并且整体趋势是不断上升的,而方案4不仅接受率数值较低而且极不稳定,说明在没有进行不诚信数据校正的情况下,虚假信息对于客户的选择有非常大的影响;方案2由于所有指标权重都一样导致不能满足客户需求,接受率也整体比较低;方案3由于只考虑客户的自身需求,虽然最后接受率比较高但波动也比较大。实验结果说明只有充分的考虑指标权重以及客户自身的需求,才可以更为准确的向客户推荐最佳服务;同时一些客户恶意的虚假评价也会对再制造服务的选择造成很大的影响。
4 总结
本文在再制造环境下,结合再制造行业实际情况提出了一种再制造服务评价模型,优化了再制造服务的QoS评价指标和量化方法。主要的贡献有三点:①建立了更为完善的再制造服务评价指标体系;②针对评价过程中可能出现的评价不诚信的问题,提出了一种利用协同过滤的思想进行校正;③在大量历史数据中利用变精度粗糙集算出各指标权重,并与客户根据自身需求设定的权重相结合,推算出服务与理想服务之间的相似度,为用户服务选择提供更为直观的结果。最后以某机床上的床身导轨再制造服务为例,验证了该方法不仅可以有效的减小虚假信息对于最终结果的影响,还可以准确的为用户推荐最佳服务。
猜你喜欢
加油站服务指南(2022年6期)2022-07-28
心理学报(2022年5期)2022-05-16
中国交通信息化(2020年11期)2021-01-14
今日农业(2020年19期)2020-12-14
当代陕西(2020年17期)2020-10-28
湖北农机化(2020年4期)2020-07-24
劳动保护(2019年3期)2019-05-16
人大建设(2018年5期)2018-08-16
通信电源技术(2018年3期)2018-06-26
山东青年(2016年2期)2016-02-28
