
基于差分进化算法和相关向量机的车辆油耗预测
2018-12-26 05:23周华刘昱郭谨玮沈姝
汽车技术 2018年12期
周华刘昱 郭谨玮沈姝
(1.吉林大学,长春 130022;2.中国汽车技术研究中心有限公司,天津 300300)
主题词:差分进化算法 相关向量机 油耗 预测
1 前言
轻型汽车燃料消耗量公示制度规定,汽车生产企业和进口汽车经销商应保证其汽车产品在销售时都粘贴有《汽车燃料消耗量标识》。公告的油耗通过型式认证试验获得,而型式认证的结果比用户实际使用时的油耗低约34%[1],且不同车型间具有明显差异。产生这种差异的原因主要有:我国乘用车燃油消耗量型式认证试验采用新欧洲驾驶循环(New European Driving Cycle,NEDC),该循环在平均速度、怠速比例和加、减速特征方面与我国车辆的实际运行特征存在明显差异;测试程序的设置与实际不符。针对这一问题,工业和信息化部已委托中国汽车技术研究中心联合行业力量共同开发能够全面反映我国车辆实际运行状况的中国工况,并计划将该工况与新的测试规程一起写入油耗测试标准。但从工况的开发到油耗标准的实施需要较长的时间周期,因此,开发一种车辆实际油耗预测方法非常必要。
Tolouei[2]、庄仲达[3]和蔡凤田[4]等分别从不同角度分析了影响汽车油耗的主要因素,但均采用定性描述的方式。程晓娟[5]和周道良[6]等利用神经网络对汽车燃油消耗进行了定量预测,但神经网络存在着过学习、欠学习和隐含层网络节点数量难以确定等问题。
本文总结了车辆实际运行特征和设计参数中对车辆油耗有影响的特征参数,并利用互信息方法确定了油耗敏感特征。以敏感特征和公告油耗为输入参数,车辆实际油耗为输出参数,建立了油耗预测模型。最后,利用该模型对车辆实际油耗进行了预测。
2 车辆油耗影响因素相关性分析
2.1 车辆油耗影响因素分析
车辆运行实际特征和设计参数对车辆的油耗有重要影响。运行特征参数包括平均速度和怠速比例;设计参数包括车身参数、发动机参数和传动系统特征参数等[5]。表1统计了车辆运行实际特征和设计参数,并给出了量化结果。
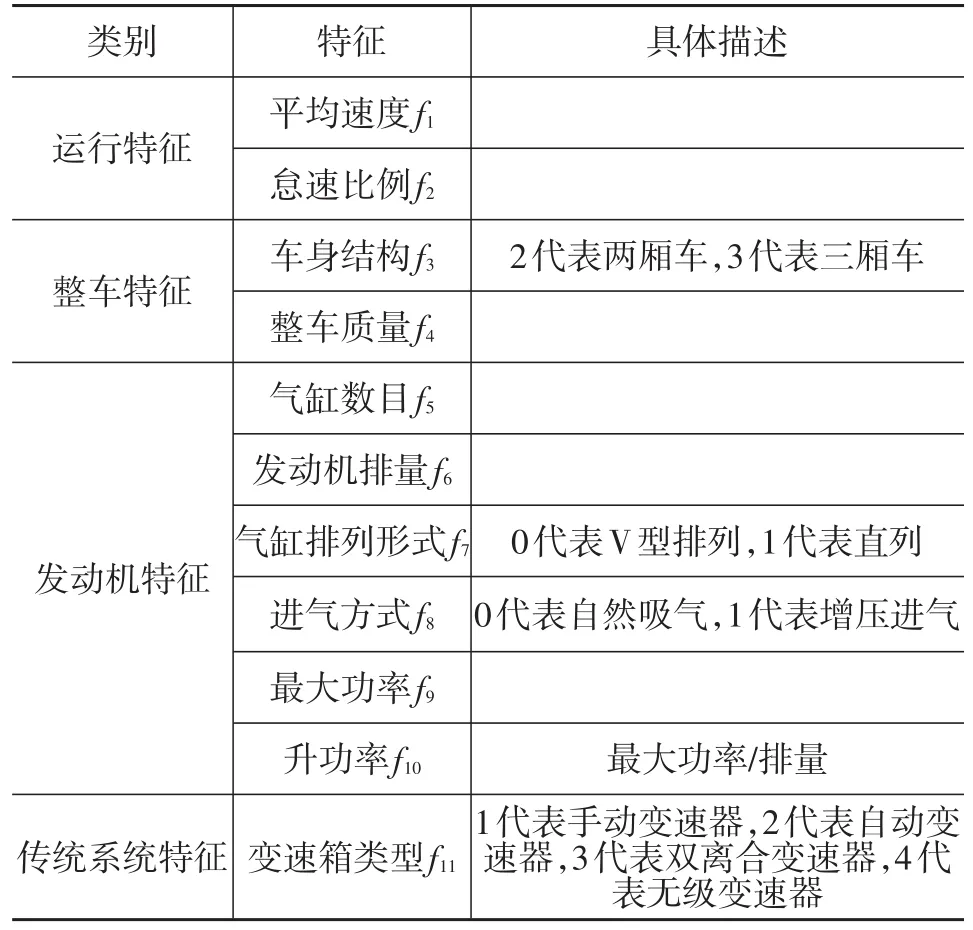
表1 车辆实际运行特征和设计参数量化结果
2.2 利用互信息确定车辆油耗敏感特征
互信息[7]属于非线性度量标准,并且无需预先知道样本数据的分布。因此它在特征选择、相关性分析等领域得到广泛关注。离散变量X和Y的互信息MI(X;Y)定义为:

式中,H(X)、H(Y)分别为变量X、Y的信息熵;H(X|Y)为变量X关于Y的条件熵;H(X,Y)为变量X和Y的联合熵。
本文以300辆轻型车作为研究样本,采用互信息方法计算表1中各参数与车辆油耗的相关程度,进而确定车辆油耗的敏感特征参数。各参数与车辆油耗的相关性(互信息MI)计算结果如表2所示,其中MIi为第i个特征与车辆油耗的互信息。
由表2可知,平均速度、发动机排量、整车质量、发动机最大功率和变速箱类型是影响车辆油耗的关键因素;车身结构、怠速比例和发动机气缸排列形式也会对油耗产生较大影响;发动机气缸数目、升功率和进气方式对油耗的影响较小。因此,建立油耗预测模型时可以根据各参数对油耗的敏感程度确定是否将其用于模型构建。
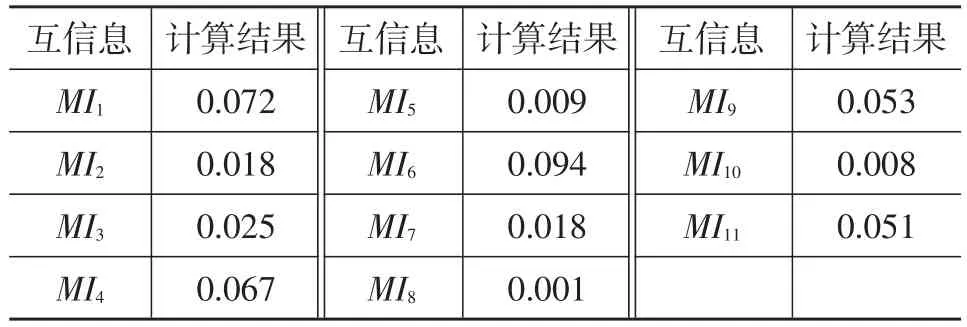
表2 各特征与实际油耗的相关性分析
3 相关向量机
已知训练样本集{xn,tn},其中xn为输入变量,tn为类别标号,n=1,2,…,N为样本标签。相关向量机(Rele⁃vance Vector Machine,RVM)的决策函数可以定义为[8]:
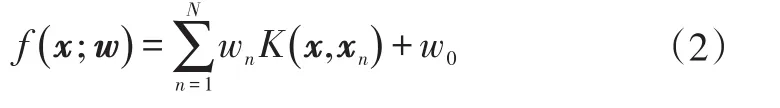
式中,K(x,xn)为核函数;w=(w1,w2,…,wN)T为权重向量;w0为偏置。
RVM核函数选择径向积核函数:
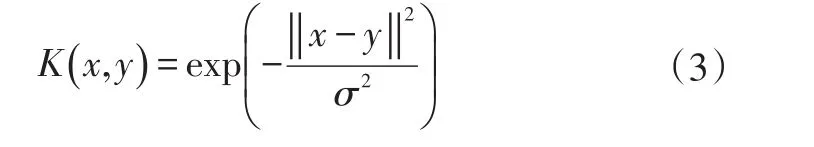
式中,σ为函数的宽度参数。
假设预测概率模型P(t|x)服从伯努利分布,并将logistic sigmoid连接函数应用于预测函数y(x),最终似然函数为:
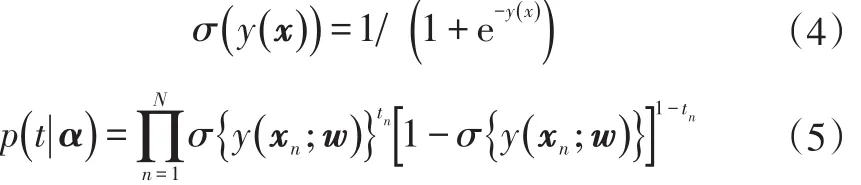
式中,t=(t1,t2,…,tN)T为目标值向量;α=(α1,α2,…,αN)为超参数向量。
定义权值wn的高斯先验概率分布为:
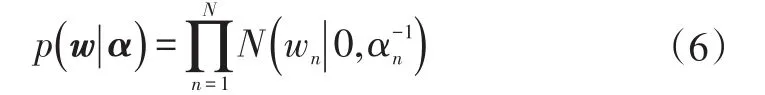
Tipping等提出了一种基于拉普拉斯方法的逼近方法,具体过程见文献[9]。随着迭代的进行,许多超参数趋近于无穷大,找出与之对应的模型的权值并删除,最终可以获得模型的稀疏解,剩余的权重不为零的样本即为相关向量。
4 差分进化算法
核函数参数是影响相关向量机性能的关键参数,如何对它们的取值进行优化是近年来非线性预测领域研究的热点。典型的优化方法包括遗传算法、粒子群算法和差分进化(Differential Evolution,DE)算法等。遗传算法采用二进制编码,计算量较大。粒子群算法简单,可调参数少,但易陷入局部最优解。DE算法计算复杂度较低,同时可以通过设置相对可靠的变异策略提高算法的全局搜索能力,因此近年来得到了较多的应用,差分进化算法包括以下步骤[10-11]:
a.初始化种群
对于D维空间的优化问题,算法首先在问题的可行解空间随机初始化得到包含NP个个体的种群。种群中的第i个个体xi可以表示为xi=(xi1,xi2,…,xiD),其中i=1,2,…,NP。
b.变异操作
差分进化算法通过变异操作产生新的个体。变异算子vi的生成方式为:
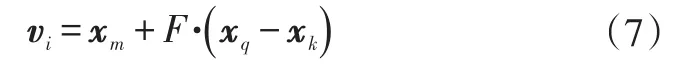
式中,下标m、q和k为[1,NP]范围内互不相等的随机数,每个变异算子均随机生成1次;F为缩放比例因子,用于控制差分向量的影响程度。
c.交叉操作
对变异算子vi和相应的目标个体xi进行交叉操作,得到ui=(ui1,ui2,…,uiD)。
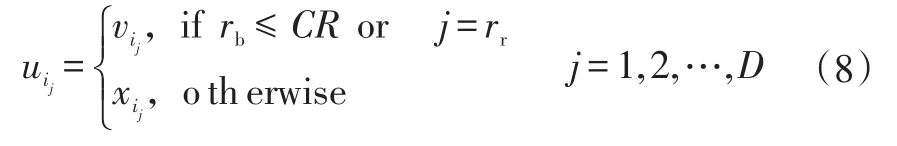
式中,rb∈[0,1]为随机数;CR为交叉概率,用于控制从变异算子抽取元素的比例;rr∈[1,D]为随机整数,用于确保试验个体ui与目标个体xi保持一定的差异。
如果交叉、变异操作后试验个体的取值超出了规定范围,则初始化种群重新随机生成该个体。
随后,计算所有试验个体的适应度。设试验个体和相应目标个体ui的适应度分别为f(ui)和f(xi),如f(ui)≤f(xi),在下一代循环中,利用ui代替xi作为新种群个体,否则保留xi作为新种群个体。
重复以上变异、交叉和选择操作直到满足终止条件。
5 车辆运行数据采集
试验采用自主驾驶法采集了300辆轻型车的运行数据,采集时间为2016年5月1日至2017年1月31日,累计行驶里程为1 500 000 km。试验系统由车载数据采集终端(采样频率为1 Hz)和数据管理平台组成。车载数据采集终端将采集信息按照统一的数据协议编码,并通过GPRS网络实时发送到工况数据管理平台,其数据来源包括GPS信号和车载诊断系统(OBD)信号,采集流程如图1所示。用于油耗预测的参数包括GPS速度、发动机转速、油耗等。其中,油耗通过进气质量流量和空燃比计算得到:

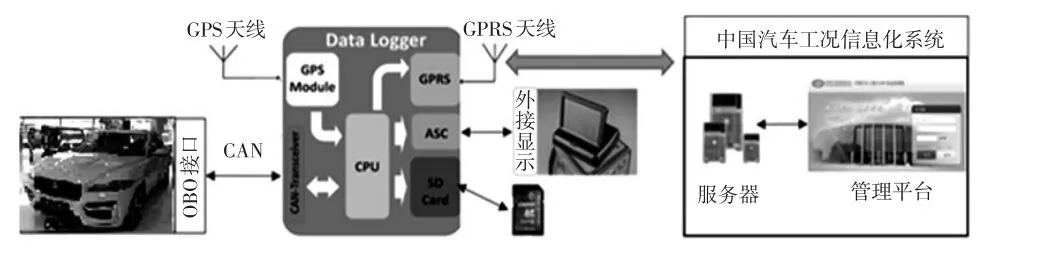
图1 数据采集示意
采集的部分数据及车辆运行特征和设计参数的统计结果如表3所示。
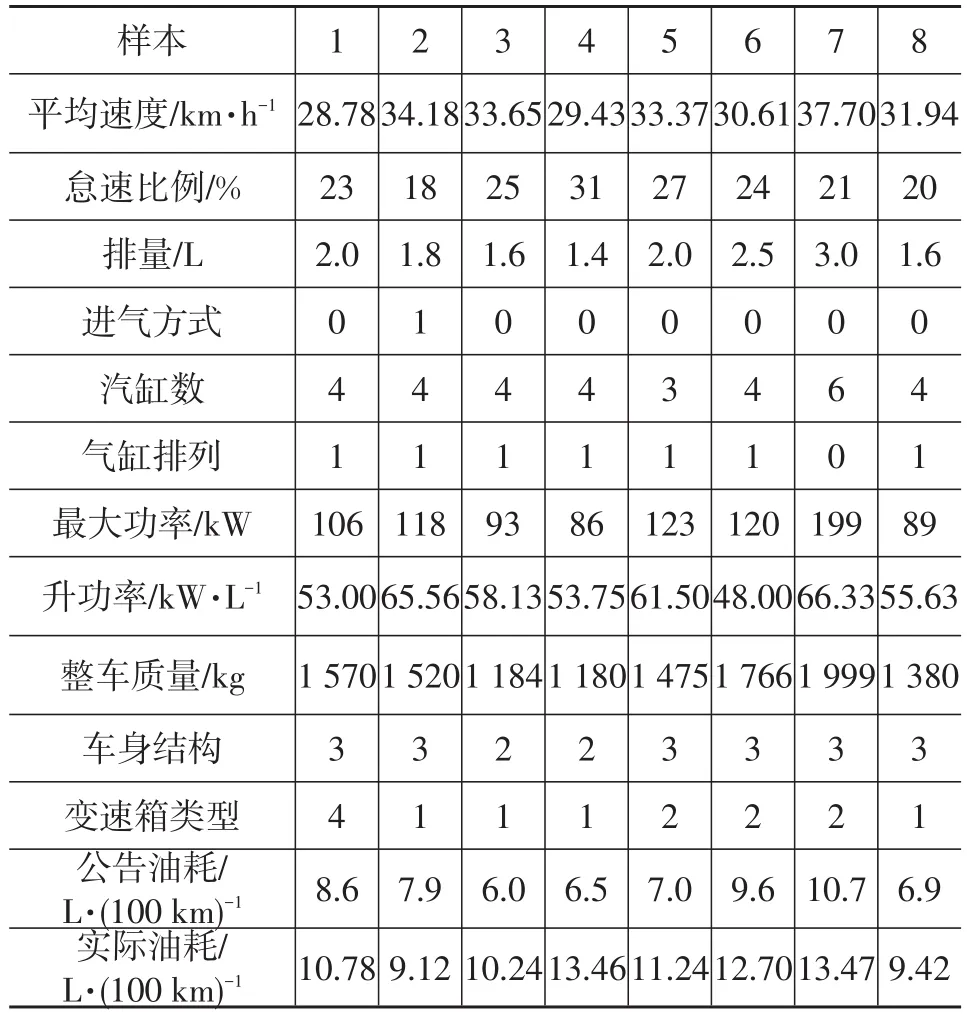
表3 部分采集数据和车辆特征参数
6 基于DE-RVM的车辆油耗预测模型
为了建立油耗敏感特征与实际油耗间的映射关系,本节将非线性预测方法RVM引用到车辆油耗预测模型中,具体如图2所示。
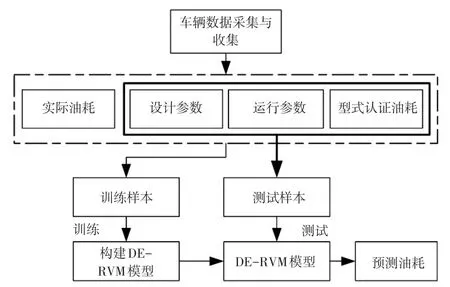
图2 基于DE-RVM的车辆油耗预测模型构建和预测流程
6.1 预测模型构建
从300辆轻型车的试验数据中随机选择200组数据用于构建DE-RVM预测模型,剩余的100组数据用于对训练好的模型进行测试。模型的输入参数包括平均速度、发动机排量、整车质量、发动机最大功率、变速箱类型、车身结构、怠速比例、发动机气缸排列形式和型式认证油耗;输出参数为车辆的实际油耗。设DE算法种群个体数目为10,缩放因子F=0.5,交叉概率CR=0.3,进化代数为100,适应度函数选择预测平均误差率[10]。通过DE算法迭代寻优最终确定最优核函数参数σ=1.7。DE-RVM算法的适应度如图3所示。
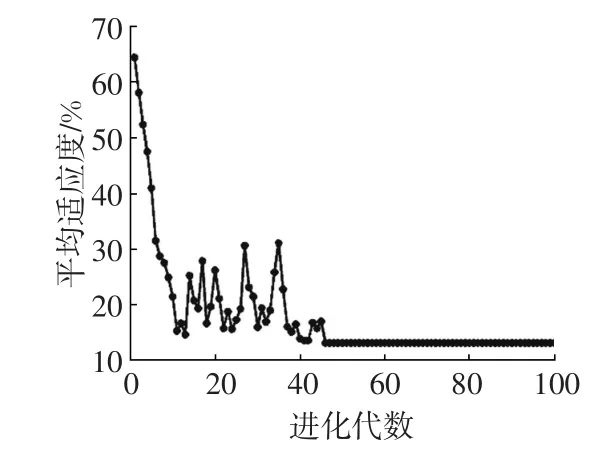
图3 DE-RVM平均适应度
6.2 预测结果分析
利用训练好的DE-RVM模型,对剩余的100组数据进行测试,并将测试结果与实际油耗进行比较,部分结果如图4所示。此外,为了说明本文方法的有效性,采用BP神经网络代替DE-RVM模型进行油耗预测,BP神经网络[12-13]输入层节点数目为9,隐含层节点数目为10,输出层节点数目为1,其训练样本和预测样本与DE-RVM相同,BP神经网络方法计算结果见图4。
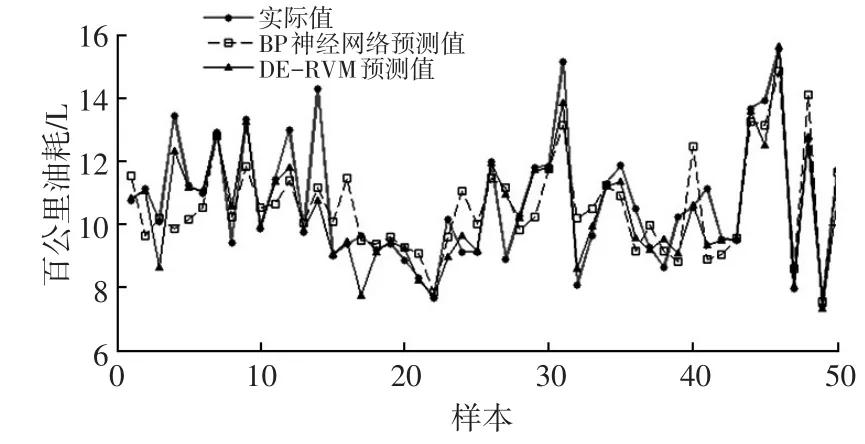
图4 部分预测结果
由图4可以看出,DE-RVM模型的预测精度明显高于BP神经网络模型,进一步计算可知,DE-RVM和BP神经网络算法的平均相对误差分别为4.9%、9.2%。综上可知,本文提出的基于DE-RVM的油耗预测方法优于BP神经网络,可以有效描述车辆运行特征和设计参数与实际油耗特征的映射关系,适用于车辆油耗预测。
7 结束语
本文总结了车辆运行和设计参数中与油耗直接相关的参数,并利用互信息方法对敏感特征参数进行了筛选,结果显示:平均速度、发动机排量、整车质量、发动机最大功率和变速箱类型是影响车辆油耗的关键因素;车身结构、怠速比例和发动机气缸排列形式也会对油耗产生较大影响;气缸数目、升功率和进气方式对油耗的影响较小。将非线性预测方法RVM引入车辆油耗的预测中,并利用DE算法对RVM核函数参数进行了优化。结果表明,本文提出的方法可以对车辆实际油耗进行准确预测。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
计算机应用(2016年10期)2017-05-12
电脑知识与技术(2016年25期)2016-11-16
高中生学习·高三版(2016年9期)2016-05-14
电脑知识与技术(2016年1期)2016-03-22
新高考·高二数学(2015年11期)2015-12-23
消费者报道(2014年13期)2015-03-19
航空兵器(2014年5期)2015-02-10
人民交通(2009年1期)2009-01-19
