
基于拉曼光谱的药片快速鉴别方法
2018-12-25 02:57,,,,
分析科学学报 2018年6期
, , , ,
(1.南京林业大学轻工与食品学院,江苏南京 210037;2.第二军医大学药学院,上海 200433)
药品现场抽检是药品监督管理工作中的必要技术支撑,但传统的检测方法存在着费时、步骤繁琐、破坏样品以及难以实现在线检测等缺点,因此如何实现药品现场高效、快速以及低成本的检测已经成为近年来的研究热点[1 - 2]。拉曼光谱分析技术是基于拉曼散射效应发展起来的一种快速检测方法,主要研究分子的振动与转动信息,与常规化学分析方法相比,拉曼光谱分析技术具有检测时间短、操作简单、无损等特点[3],因此该技术在材料、化工、生物、食品等领域的定性定量分析中得到了广泛的应用[4 - 7]。近年来,随着化学计量学方法和光谱仪器的不断完善和发展,拉曼光谱分析技术在药品的定性定量分析领域中也取得了诸多成果[8 - 10]。但以往研究中,较少有关于在药品拉曼光谱定性判别方面进行综合比较分析的研究。常用的判别分析方法有很多种,如Fisher判别法[11]、线性学习机(LinearLearningMachine,LLM)、簇类独立软模式(SoftIndependentModelingofClassAnalogy,SIMCA)[12]、人工神经网络(ArtificialNeuralNetwork,ANN)[13]、K-最邻近法(K-NearestNeighborMethod,KNN)[14]、贝叶斯(Byes)判别法等,因此选择能适用于多种药品拉曼光谱快速、准确分析的判别算法对于用药安全,以及推广该技术在药品检测领域的应用具有重要的意义。
本研究采用拉曼光谱和4种模式识别算法(SIMCA、KNN、Fisher、LLM)相结合对药品进行快速判别分析。首先采集了甲硝唑、消旋山莨菪碱、卡托普利、阿昔洛韦4种片剂共452个药品的拉曼光谱,在对原始光谱进行预处理和主成分分析(PCA)的基础上,利用4种算法按照活性药物成分(ActivePharmaceuticalIngredients,API)建立分类模型,用于药品API的识别;然后按照上述相同的步骤,分别采用4种算法建立可同时识别药品API及其生产厂家的分类模型。
1 实验部分
1.1 仪器和样品
R10激光拉曼光谱仪(上海仪电分析仪器有限公司)。激励波长:785nm;光谱分辨率:8cm-1;波数范围:200~2600cm-1;激光最大输出功率:300mW;积分时间:3000ms。
实验所用的片剂甲硝唑、消旋山莨菪碱、卡托普利、阿昔洛韦样品共452个均由上海市食品药品检验所提供,样品具体信息见表1。由表1可知,若只考虑API分类,样品集可分为4类;若同时考虑API和生产厂家,则可分为9类。

表1 药片样品分布
1.2 光谱采集
用刀片将待测药片切平整以去除包衣,置于称量纸上,将光谱仪的探头套上套筒,然后在片剂磨平的一面选取一个点进行光谱采集,采集时激光功率为最大功率的70%,每个点重复测量3次,然后取平均光谱作为该样品的原始光谱。
1.3 数据分析
本研究数据分析采用NIRSA系统以及Matlab2010b软件平台。NIRSA系统是本实验室自主开发的,专门用于光谱数据处理的化学计量学软件,本研究中主要用于光谱数据的预处理以及判别模型的建立。Matlab2010b平台则主要用于样本集的划分及判别效果评价。所建模型的性能通过校正集正确率、预测集正确率和建模所需的主成分数来综合评价。
2 结果与讨论
2.1 样本集的划分
本实验中,452个样品分别按照以下两种方式进行校正集和预测集的划分:(1)按药片API划分。由表1可知,样品共有4类,其中甲硝唑120个、消旋山莨菪碱124个、卡托普利144个、阿昔洛韦64个,将每类样品按照3∶1的比例随机划分成校正集1(共340个)和预测集1(共112个)。(2)按药片API及其生产厂家划分。将上述(1)的校正集和预测集中每类样品再按照生产厂家进行划分,则甲硝唑、消旋山莨菪碱和阿昔洛韦又各分为2类,卡托普利可分为3类,因此两个集合都包含9类药品,分别命名为校正集2和预测集2。
2.2 光谱预处理
由于所有样品的光谱在1 800~2 600 cm-1内没有拉曼峰出现,且拉曼强度基本保持在0左右,表明该波段不包含反应样品性质的有效信息,因此截取200~1 800 cm-1范围的光谱用于分析。图1为波段截取后校正集1中的4种药品光谱。从图中可以看出,由于API不同,4种药品波峰出现的位置和峰的强度都有较大差别,如在1 180 cm-1,甲硝唑具有很强的拉曼谱峰,而其他3种药品基本没有吸收。图2为校正集2中3个厂家生产的卡托普利光谱,可以看出不同厂家生产的同一类药品的光谱相似度较高,主要差异为峰的强度差异,而拉曼峰所在的位置基本一致。
由于样品的状态、仪器的响应、杂散光等因素的影响,所测光谱中除了待测样品的信息外还包含了其他的背景干扰信息。因此在建立模型时,对光谱进行预处理以消除无关信息和噪声是很有必要的[15]。分别采用9点一阶微分、7点Savitzky-Golay(SG)卷积平滑、标准正态变量变换(Standard Normal Variate Transformation,SNV)、多元散射校正(Multiplicative Scatter Correction,MSC)等预处理方法,以及它们的组合对光谱进行预处理,通过多次比较发现,光谱经MSC预处理之后的建模效果最好。
2.3 分类识别
2.3.1按API分类按照API进行分类,校正集1和预测集1样品可分为9类。对340个校正集样品分别采用4种方法进行建模,预测集中112个样品用于检验模型对未知药品的识别能力。模型的各项指标如表2所示,其中SIMCA模型中的显著水平为0.01,KNN模型中的所选取的近邻样本的个数k=5。由表2可知,这4种方法仅需要提取较少的主成分就能使模型的预测正确率达到100%,这是因为4种药品不同API导致其光谱之间差异较大,所以仅需从原始光谱中提取少量信息就能完全将它们区分开。因此对于仅考虑API进行分类的情况,这4种模式识别算法均可满足要求,达到很高的预测精度。
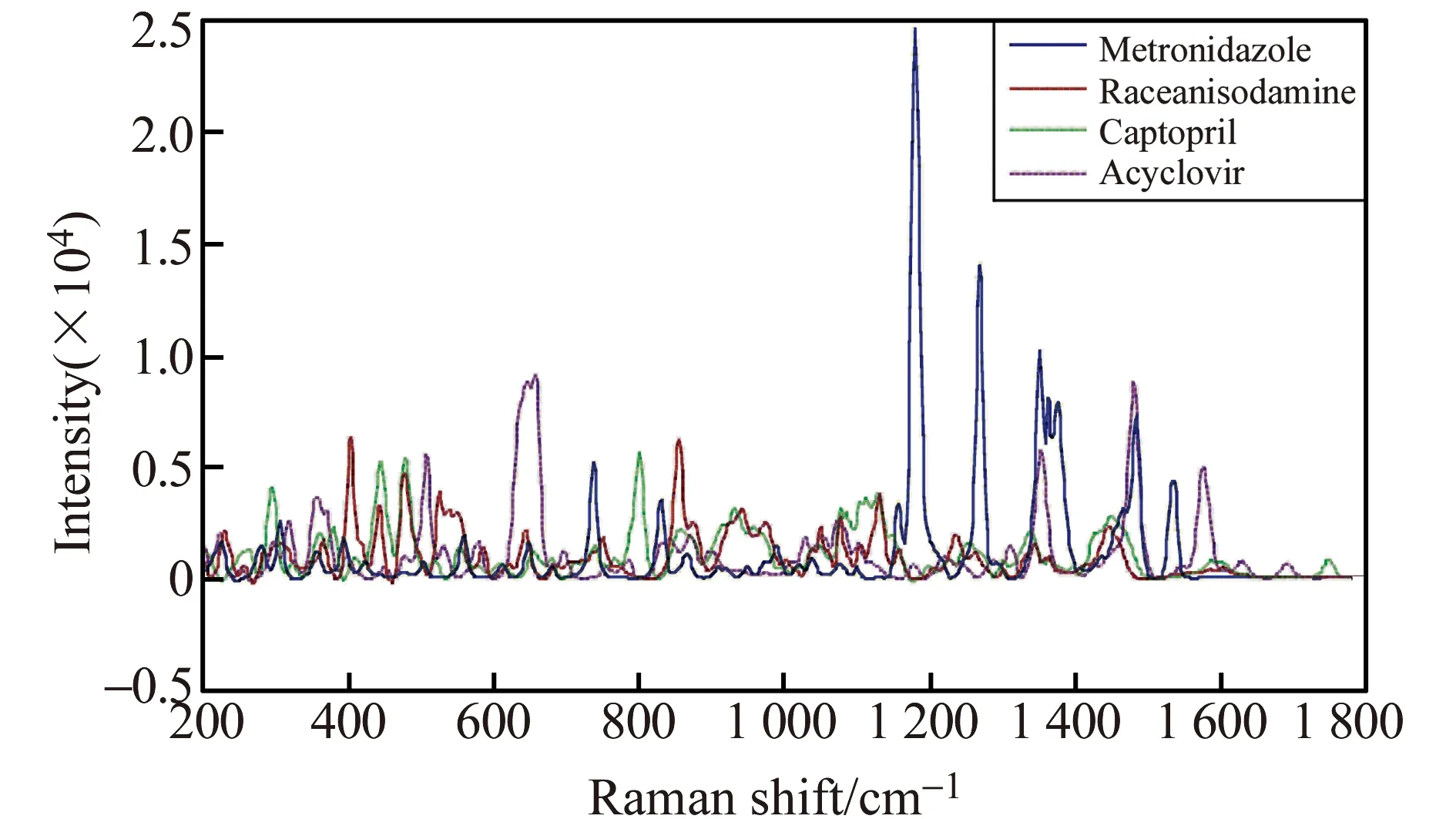
图1 4种药品的拉曼光谱Fig.1 The Raman spectra of 4 tablets
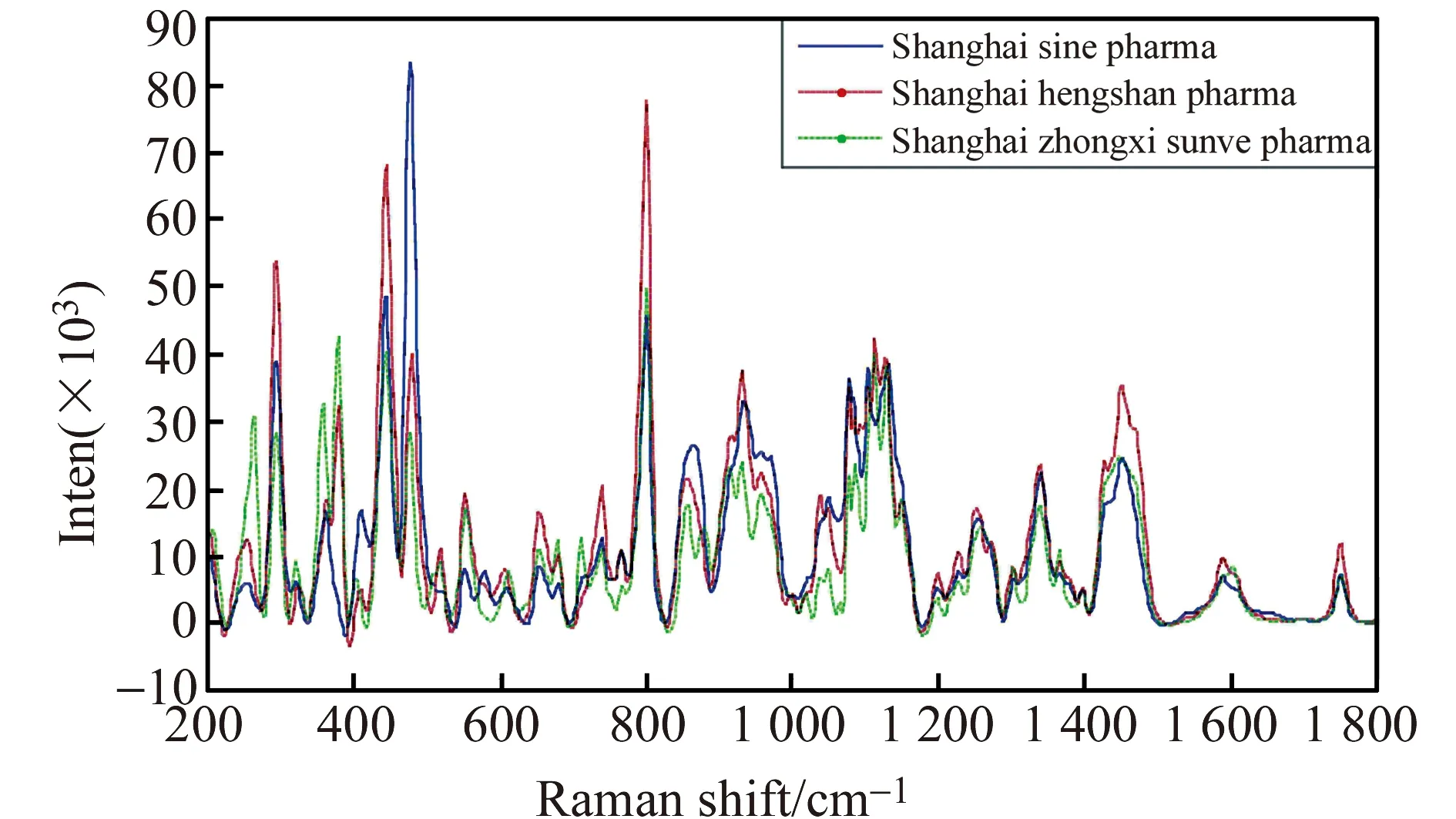
图2 3个厂家的卡托普利的拉曼光谱Fig.2 The Raman spectra of captopril from 3 manufacturers

表2 4个API分类模型预测结果
2.3.2按API和厂家分类同时考虑API和厂家,以便建立能识别API及其生产厂家的分类模型。以校正集2中的9类340个样品为研究对象,分别采用4种方法进行建模,并对预测集2中的9类112个样品进行识别。模型的各项指标如表3所示,其中SIMCA模型中的显著水平为0.01,KNN模型中的k=13。

表3 考虑厂家的4个API分类模型预测结果
比较表3和表2可知,兼顾药品API与生产厂家识别的模型所需的主成分数明显增大,4个模型的最优主成分数分别为10、10、11和9,这是因为不同厂家生产的同种API药品的差异主要体现在辅料上,为了能同时识别药物类型和生产厂家,因此需要采用更多的主成分从原始光谱中提取足够的变异信息以利区分。不过因辅料的干扰,建模集和预测集识别正确率均有不同幅度的下降,其中SIMCA和KNN模型的预测正确率均保持在95%以上,即112个预测集样品中出现了5个错判样品,且错判仅出现在两个厂家生产的甲硝唑中;虽然Fisher模型的预测集正确率也达到91.96%,但是其错判的样品不仅分布在两类甲硝唑片中,在其它类别的样品中也存在;而LLM的预测集判别正确率仅为79.46%,显然达不到实际应用要求。
从药品拉曼光谱模式空间角度分析,如果只以不同药品API来划分,因拉曼峰差异明显,模式空间类域分布相对简单,仅用线性的Fisher和LLM分类器即能准确判别。但是当还需要识别同一API药品的生产厂家时,类域分布趋于复杂,这两类线性判别函数已经无法准确划分药品的模式空间,而KNN算法则可适用于线性不可分体系。尽管SIMCA算法的核心是基于线性变换的PCA,但其对每一类样品的光谱构造主成分回归模型用于分类,具有更确定的特征判别能力[16]。因此表3中,KNN和SIMCA模型预测正确率明显高于Fisher和LLM所建模型。Fish算法通过类间与类内方差比值最大寻求最佳投影方向,但因仅提取一个投影向量作为类间划分特征,判别能力欠佳。而LLM算法则按误差纠正反馈(Error-correction Feedback)法进行训练从而调整判别函数权重系数,形成的判别面简单且受数据分布限制,在样本空间线性不可分时,LLM算法建立的分类器也难以很好地工作[16 - 17]。
针对以上同时考虑API和生产厂家分类时4种模型均会出现甲硝唑错判的情况,本研究通过比较各类样品光谱之间的相关系数进行了进一步探讨。表4中列出了9类样品平均光谱之间的相关系数。由表4中9类样品平均光谱之间的相关系数可以看出,1号和9号样品即两类甲硝唑之间的相关系数最大,达到0.9990,表明这两种甲硝唑之间的谱图相似性很高,这可能是由于这两个厂家生产的甲硝唑不仅API含量相同,而且辅料的种类以及含量差别也很小,所以两者之间在光谱上的也体现很小差异,从而导致了误判。

表4 9种药品平均光谱相关系数
3 结论
通过4种模式识别算法结合药品的拉曼光谱对药物按照API和厂家进行快速分类识别进行了探讨。结果表明:(1)按照药品API分类时,SIMCA、KNN、Fisher和LLM模型仅需提取较少的主成分就能全部正确预测。 若同时识别药物API类型和生产厂家,则需要从原始光谱中提取更多的主成分以表征药品之间的差异,且4种方法所建模型预测正确率均不同幅度下降,其中Fisher和LLM模型的预测精度均不能满足实际应用要求。(2)从模式空间角度分析,仅以药品API定义的类域分布相对简单,因此4种方法均具有良好的分类效果;但当不同厂家生产的同种API药品定义为不同的类时,模式类域空间分布则趋于复杂,此时由Fisher和LLM法生成的线性判别函数识别效果较差。SIMCA模型充分利用了各类光谱的特征信息,KNN法则具有较好非线性划分能力,更能适用于药品的拉曼光谱快速判别分析,这对于药品的监督管理工作具有重要的现实意义。(3) SIMCA和KNN模型对于不同厂家生产的甲硝唑出现误判是因为二者光谱差异性很小。对于如何识别出不同厂家生产的同种API药品拉曼光谱之间的这种微小差异还有待对算法的进一步改进和研究。
猜你喜欢
口腔护理用品工业(2021年4期)2021-11-02
辽宁省博物馆馆刊(2021年0期)2021-07-23
中国粮油学报(2018年12期)2018-03-19
老年医学与保健(2017年6期)2017-02-06
光学精密工程(2016年1期)2016-11-07
原子能科学技术(2014年3期)2014-02-28
河南医学研究(2014年3期)2014-02-27
郑州大学学报(理学版)(2013年3期)2013-03-11
物理与工程(2013年2期)2013-03-11
物理与工程(2013年1期)2013-03-11
