
基于OI-LSTM神经网络结构的人类动作识别模型研究*
2018-12-25 08:51:56张儒鹏于亚新尚祖强
计算机与生活 2018年12期
张儒鹏,于亚新,张 康,刘 梦,尚祖强
东北大学 计算机科学与工程学院,沈阳 110000
1 引言
目前各种便携式设备得到了快速发展,例如智能手环、智能手机等,这些新兴的自适应移动应用都可以利用嵌入式传感器采集到的大数据对用户进行动作识别和行为分析。比如,医疗系统可以利用动作识别有效监控动作行为和病人身体情况,这样一方面指导了医护人员执行正确的治疗,另一方面又解决了医院工作人员匮乏问题。在康复训练中,动作识别和行为分析可以辅助病人进行康复活动,分析病人动作行为,对老年人进行监控保证安全[1];在体育运动中,人体行为识别技术作为一种辅助手段,可用于分析运动员各项数据,有效的数据分析提升了运动员成绩,从而提高了整体竞技水平[2]。
这种新兴自适应移动应用的特性是:(1)高准确性。在大多数应用背景下,要求动作识别算法能对每个动作达到精确识别,通常准确率达到95%以上才可以得到应用,这就要求系统核心算法要有高准确性。(2)在线实时性。在这种应用背景下,由于实时性要求,系统没有时间去过滤和处理错误数据,这就要求系统核心算法要有很强的鲁棒性和容错性。但迄今为止,已有相关研究工作所用算法几乎没有考虑这些特性所带来的要求,一是准确率达不到系统要求,或者根本没有考虑系统模型的容错性,基于此,本文提出一种新的神经网络结构来提高识别准确率,并在数据集中通过构造不合法数据证明了新的模型具有很高的鲁棒性和容错性。
自适应移动应用可以进行研发的理论前提是人类的某个特定身体运动可以转化为组合传感器的特定信号特征,这种信号特征可以用机器学习技术对其进行感知和分类,也就是说可穿戴动作识别依赖于机器学习对传感器组合信号的模式识别,其中组合信号是加速度计、陀螺仪或磁场传感器的组合。相关研究一直在极力追求实现以下两个目标:增强识别准确率和减少对工程特征的依赖。但这两个目标却难以实现,因为动作识别问题的难点在于特定动作运动模式的巨大变化,换句话说,不同个体完成同一动作的运动轨迹其模式不完全相同,因此工程特征难以全面正确表达各个动作的运动轨迹模式,从而导致识别准确率难以达到令人满意的结果。为实现上述两个目标,一种新的基于深度学习的特征提取方法被提出。
深度学习是分层组织的,后一层处理前一层的输出,它是一个使用多个非线性信息处理层来进行特征提取和分类的神经网络。深度学习相关研究中普遍使用的两个经典网络结构是卷积神经网络(convolutional neural network,CNN)[3]和递归神经网络(recurrent neural network,RNN)[4],其中CNN是一种具有特征提取能力的深度神经网络(deep neural networks,DNN),通过堆叠几个卷积运算以创建一个逐步变得更抽象的特征图,从原始数据中自动提取有效特征,不再依赖人类的领域知识,该提取方式不仅增强了系统的准确率和泛化能力,而且还可以形成一个端对端系统,从而减轻系统训练复杂度。而RNN则天生具有序列信息处理能力,它的一个变形LSTM(long short term memory)[4]包含一个记忆模块模拟时间序列中的时间依赖关系,可以很好地处理具有时间先后依赖关系的信息。
因为CNN出众的特征提取能力,本文也将使用它来提取动作的运动模式特征。但是只使用单一CNN,随着CNN层的增加会出现参数爆炸性增长问题以及卷积视野变窄问题,而Inception结构[5]可以解决这两个问题。为此,本文加入了Inception结构,但经典的Inception结构包含大卷积核,造成时间消耗过多,使得模型训练速度和识别速度都有所下降。为克服时间复杂度过高问题,本文对Inception结构进行了适当优化,提出一种新的O-Inception(optimization Inception)结构,一方面该结构通过用多个小卷积核替换大卷积核提高了训练和识别速度,另一方面借助pooling层优化减少了特征丢失,在一定程度上提高了准确率。此外,为使准确率进一步提升,本文又加入LSTM以充分使用被识别动作本身所含的时序信息。对于模型要求的容错性,则通过融合O-Inception和LSTM所形成的OI-LSTM模型得到了有效解决。
本文一共分为6个部分。第1章为引言部分,主要介绍了研究背景。第2章简述了国内外在动作识别领域的研究现状。与深度学习相关的一些理论知识则在第3章进行了详细介绍。第4章阐述了本文所提动作识别神经网络模型OI-LSTM。第5章为实验部分,验证了本文所提模型的有效性、容错性和实时性。第6章为结论。
2 国内外研究现状
2.1节主要介绍了动作识别的基本步骤和传统识别方法。2.2节主要介绍了近些年该领域研究者基于深度学习所做的动作识别研究。
2.1 传统动作识别算法
动作识别一般可以分为以下两个主要的步骤,第一个步骤是时间序列的分段,当前的主流方法是使用一个固定长度的滑动窗口将整个动作的时间序列分割成相等的段。例如针对数据集WISDM的研究,大部分都是使用以上所述的时间序列分段方式,即固定窗口长度和固定移动方向[6-10]。第二个步骤是从得到的原始段中提取有效的特征。整个工程中最为关键的就是特征提取,它将直接影响着系统的整体识别准确率。以前的识别算法中多使用工程特征,这种方式虽然也能表现出优异的性能,但是要求有丰富的领域知识,领域专家寻找好的工程特征也是相当耗时的,它对新的数据源和实验装置的推广通常是平庸的,这将难以达到人们期望的强泛化能力,使得系统难以从动作识别放大升级为更复杂的高级别的行为识别应用。相关研究中常见的工程特征有谱熵、自回归系数和快速傅里叶变换系数等。基于以上两步,动作识别的经典解决方案是使用模板匹配方法[10]或隐马尔可夫模型[11]或支持向量机等。
2.2 深度学习算法
DNN已经应用于可穿戴动作识别(human action recognition,HAR)领域,大家已经开始使用卷积层和非递归层相结合的网络结构[12-13]。在文献[14-17]中,作者使用多个传感器,把这些信号逐行堆叠成一个二维的“信号图”,最后把这个信号图送入卷积神经网络。在文献[18]中,不处理原始传感器信号图,而是将离散傅里叶变换应用于该图,并利用所获得的特征进行分类。CNN的网络结构在不同的研究中也是不同的,在文献[8]中考虑了一个卷积层和两层的DENSE层,在文献[14,16-17]中则是使用另外多个卷积层和一个DENSE层。另外因为CNN和LSTM的结合已经在语音识别领域得到了最先进的结果,基于都需要对时间信息进行建模[19],本文考虑将这种结合应用在动作识别上。
3 相关理论知识
本章主要介绍了深度学习的一些理论基础和网络结构。本文用到的符号及其含义如表1所示。

Table 1 Symbol and meanings表1 符号及含义
卷积神经网络在图像和语音识别领域得到了长足发展,得益于其突出的特征提取性能。用CNN替换全连接不仅可以提取出有效的特征图,还可以加快训练速度和缩短识别时间,这是因为它是部分连接并且是参数共享的。
3.1 CNN基本网络单元
CNN是一种前馈神经网络,受生物视觉系统启发形成。用一个类似于滑动窗口的滤波器filter对输入数据做卷积运算,每次运算只关注一个数据子区域,一个卷积核对一个数据段做一个卷积运算生成一个特征图。其详细结构描述如下:
(1)卷积层:卷积操作的应用取决于应用维度,手机加速度计的数据是一维的具有时间性质的序列,因此本文的卷积层使用一维卷积。这时卷积核可以被看作是一个过滤器,能够去除异常值,过滤数据或充当特征检测器,找出能够确定动作类型的最明显的时间序列。卷积运算是两个向量之间的运算,对于一个输入向量x⊂Rn,用另一个向量f⊂Rm在向量x上滑动,每次滑动做一次点乘运算,所有步骤的输出作为一次卷积的输出。用一维的卷积核从数据中得到一个特征图可以用式(1)表示。
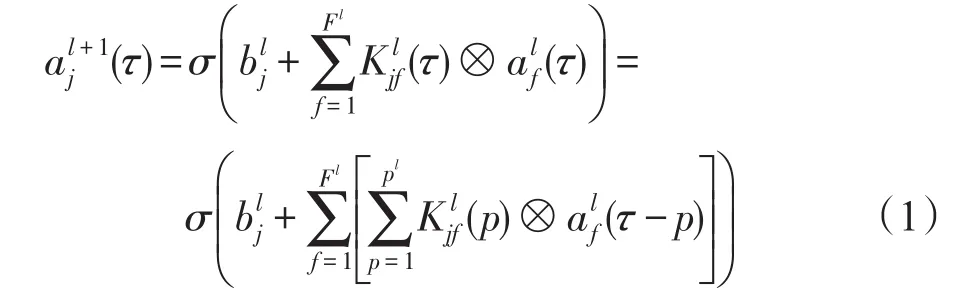
(2)池化层:该层通常紧跟在卷积层后面,用于减少卷积层得出的特征图的特征表示,选出特征图中最具代表性的特征,给特征图降维,使用一个正方形窗口在特征图上移动,取窗口中最大的值或者取平均值,这两种做法分别称为最大池化和平均池化。
(3)全连接层:全连接层的每个神经元都与上一层的神经元全连接,用来把前面提取到的特征综合起来,并把输出转化为一个一维向量用来分类,这一层可以学习更多的非线性依赖关系。
(4)Softmax层:最后一层的输出传给Softmax层以计算每一分类的概率分布。
3.2 Inception卷积结构
Inception的核心思想是用小卷积核代替大卷积核,借鉴了NIN(net in net)设计思路,充分利用卷积和池化性能,将卷积分组,最后再将各个分组的卷积输出连接起来,避免了当网络深度加深、网络宽度变宽时所带来的参数爆炸性增长问题,即梯度不会出现弥散现象。Inception Native结构一方面增加了网络宽度,另一方面又增加了网络对尺度的适应性。但该网络有一个极大缺陷,由于它含有一个5×5的卷积核,因此卷积操作的计算量相当巨大。为减少计算量,提出了正式的Inception结构。它在每个大卷积核之前都加上了一个1×1卷积核来降低特征图的厚度。
3.3 深度可分离卷积结构
深度可分离(depthwise separable)是由深度卷积发展而来。深度卷积是指,对输入数据的每个channel用channel所对应的所有filter去分别做卷积。一个深度卷积结构一般包含4个参数filter_height,filter_width,in_channels,channel_multiplier,其中filter_height和filter_width表示卷积核窗口的大小;in_channels表示输入数据的channel个数;channel_multiplier表示每个channel所拥有的filter个数。每个channel经过一次卷积后产生的特征图(feature map)都会有channel_multiplier个通道,则最后的特征图就会有in_channels*channel_multiplier个通道了。
深度可分离是在深度卷积基础上增加了另外一个Pointwise convolution操作,该Pointwise convolution就是1×1的卷积,可以看作是对多个分离的通道做融合操作。
3.4 LSTM递归神经网络
LSTM网络是一种特殊的RNN网络,可以学习长期时间的依赖信息,擅长处理依赖于时间序列的任务。类似普通RNN,LSTM拥有重复神经网络模块的链式形式,但它所重复的模块与普通RNN有着不同的结构,LSTM重复模块的结构如图1所示。
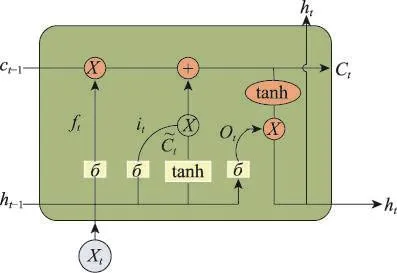
Fig.1 LSTM internal structure图1 LSTM内部结构
LSTM的关键在于图中的Ct-1,它表示细胞状态,贯穿于网络的整个运行周期,类似于一个传送带,只有少量的线性交互,因此信息在上面很容易保存。LSTM精心设计了一种称为门的结构,能给细胞状态删除或者添加信息,并让信息选择性通过。一个门一般包括Sigmod激活和Pointwise乘法两个数学运算。Sigmod函数的输出值介于0和1之间,0代表不允许信息通过,1代表任意值通过。LSTM共包括3个门,分别为忘记门、输入门和输出门。
首先,忘记门决定从细胞状态中丢弃什么信息,该门会读取ht-1和Xt,输出一个在0到1之间的数值给每个在细胞状态Ct-1中的数字。忘记门的输出如式(2)所示。

下一步,输入门决定把哪些新的信息保存在细胞状态中。输入门有两步运算,Sigmod的输出值决定什么值将要被更新,tanh层创建一个新的候选值向量,决定如何把输出值加入到细胞状态中,基于以上两个操作对细胞状态更新的公式如式(3)~式(5)所示。
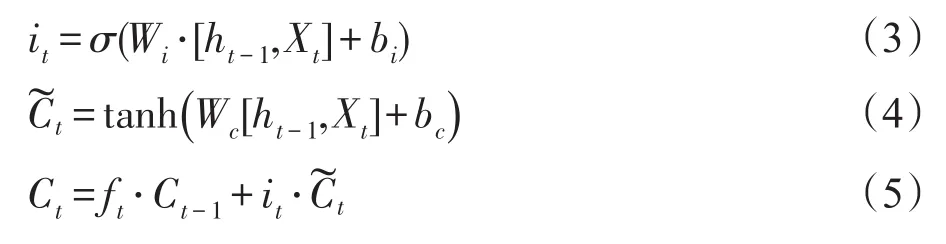
最后,使用输出门得到LSTM的最终输出。先使用一个sigmod层决定哪些信息需要输出,细胞状态经过tanh处理后与sigmod的输出相乘得到整个LSTM网络的最后输出,其公式如式(6)、式(7)所示。

4 OI-LSTM模型
如前所述,动作识别难点在于特定动作运动模式有着巨大变化,模型往往难以表现很高的准确性,或者在一个数据集上表现比较优秀,但是在另一个数据集上却逊色于其他模型。同时手机传感器实时情况下存在错误数据,这就要求模型不仅要准确率高,还要有自适应性、鲁棒性和数据容错性。基于对模型拥有高准确性和容错性缺一不可的特点,本文提出了一种新的网络结构OI-LSTM。
4.1 模型结构
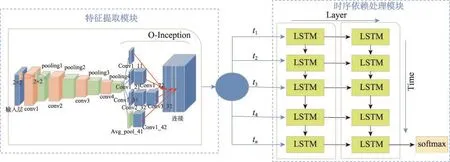
Fig.2 OI-LSTM neural network图2 OI-LSTM神经网络模型
OI-LSTM模型的网络结构如图2所示,该模型分为两个模块:特征提取模块和时序依赖处理模块。特征提取模块包括4个连续卷积层和1个O-Inception结构,根据式(1)进行卷积运算。其中,卷积运算只沿时间方向卷积数据,并使用修正的线性单元(ReLU)计算特征映射;O-Inception结构提取的特征经DepthConcat联接得到各通道的综合特征,把综合特征再按时间依赖关系放入特征池中。时序依赖处理模块是一个双层LSTM网络结构。LSTM每一个时间步骤都从特征池中提取一个对应的特征图,一个时间序列t0到tn的特定动作则对应N+1个特征图。为获得最佳识别效果,在确定时间依赖处理单元中LSTM递归层神经元个数和层数时,本文借鉴了参考文献[17]所提的一个参数确定原则,即纵向至少2层LSTM原则,另外根据任务本身规模,确定每层的神经元个数为32。OI-LSTM模型将上述两个模块进行了有效融合,一方面因为O-Inception结构的加入使得网络层次加深,视野扩宽,即可以提取到更加丰富的特征,从而提高了识别率;另一方面又因为LSTM的加入使得时序信息得以充分使用。LSTM对时序信息的有效处理,不仅可以提高识别率,同时还可利用LSTM推理能力使模型整体拥有一定程度的容错能力。
图2给出了传感器数据在OI-LSTM模型各层中的流动情况。首先,经过第一个卷积层conv1,它拥有18个卷积核,每个卷积核尺寸是2×2,每次卷积前用0填充原始数据(使卷积后得到特征图尺寸与原数据相同),得到特征图输入池化层pooling1,这层的窗口移动步长和窗口大小都为2。接下来,重复3次卷积和池化操作,但卷积核个数依次增加为36、72和144。为获得更高维度、视野更广的特征图,再把pooling4输出的特征图送入O-Inception结构中,即把pooling4输出分别用3个大小为1×1,个数分别为36、18和18的卷积核做卷积运算,结果分别为conv1_11、conv1_21和conv1_31;同时,把pooling4输入到一个核大小为2×2的avg_pool_41中(avg_pool_41使用平均池化操作);然后,conv1_21输出到卷积核大小为2、个数为36的卷积层conv2_22中,conv1_31则输入到卷积核大小为2、个数为36的卷积层conv2_32中,conv2_32的输出还要输入到卷积核大小为3、数量为36的卷积层conv_3_32中;接下来,avg_pool_41输出到卷积核大小为3、个数为36的卷积层conv1_42中;最后,把conv1_11、conv2_22、con3_32和conv1_42按通道维度叠加起来,叠加后的特征图做平化处理,转化成一个一维向量,把这个一维向量输入双层LSTM网络。
4.2 高识别率
首先,OI-LSTM模型具有高识别率,部分原因在于其中的O-Inception结构。O-Inception结构通过使用一个2×2和3×3的两层卷积替换原始Inception结构中的5×5卷积,pooling层也由3×3替换为2×2,pooling层后的卷积由1×1替换为3×3,结构如图3所示。如果直接使用原始Inception结构,虽然也可提升特征表达能力,但同时会带来更多的时间消耗,使得模型训练速度和识别速度都有所下降。因此,为克服时间复杂度过高问题,OI-LSTM模型对Inception进行了结构调整和优化,即替之以O-Inception结构。由卷积操作过程可知,用多个小卷积核替换一个大卷积核,其前后得到的特征图并没有发生变化,即得到了相同的特征图,但计算复杂度却大大降低,从而加快了网络训练速度和识别速度。另外,用2×2池化替换3×3池化,在一定程度上可以减少特征丢失,比如3×3的一次池化操作将丢失8个信息,而2×2的一次操作仅丢失3个信息。利用3×3卷积替换1×1,由于前者视野窗口大于后者,增强了卷积视野,从而提高了模型准确率。
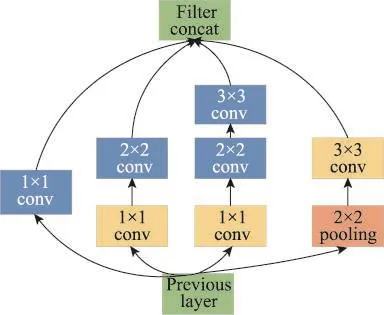
Fig.3 O-Inception structure图3 O-Inception结构
其次,OI-LSTM模型具有高识别率,还在于该模型并没有像传统CNN那样,把提取到的特征简单地用全连接层综合来直接分类,而是通过LSTM把时序依赖信息融入了动作分类中。一个连续动作在持续时间内其各个动作分解都是相互依赖的,例如一个持续2 s的步行动作,该动作在0.1 s那一刻的抬脚与0.5 s那一刻的向前迈步是前后依赖的,离开0.1 s的动作帧,单独识别0.5 s的动作帧将毫无意义,而传统CNN动作识别却并没有把该依赖信息考虑进去,而是把这两个时刻的特征图割裂开来,同等对待,这就丢失了连续动作本身所具有的各个时刻前后依赖的信息。基于此,本文通过加入LSTM实现将连续帧前后依赖关系纳入OI-LSTM模型中,进一步提高了模型的识别准确率。
云团间,有东西一闪而过。三体舰?不,不可能,云团里怎么会有军舰呢?壶天晓再次遥控灰色翼龙的眼睛进行搜索,却没有发现异常。如果目前能用的只有感应网络,那就将它的作用发挥到极致。壶天晓暗自思忖着,全力搜索着庞大的感应网络,希望能发现点儿什么。
4.3 高容错性
如果数据中有错误数据或者不合法数据,传统CNN网络的识别率就会显著下降,甚至无法训练,但这与系统所要求的实时在线处理需求相矛盾,换句话说,系统并没有时间去验证或过滤用户发来的数据,也无法去除脏数据和不合法数据,因此,为实现高容错性,系统需要自动排除错误和不合法数据。经研究发现,深度可分离卷积结构的特殊卷积方式,在某种程度上确实可以解决容错性问题,但却会导致准确率下降。原因在于这种卷积方式使得网络无法在每一层综合各个通道的信息来得到更加全面的特征图,不可避免地丢失了特征图的表达能力,进而降低了准确率。
与深度可分离卷积网络不同,OI-LSTM模型不但具有高容错性,而且还拥有较好的高识别率,其之所以拥有容错能力是因为,当加入LSTM时,若干不同时刻对应着多个特征图,LSTM在每个时刻都会读入一个特征图作为输入,假如ti时刻对应的特征图Mi中某个通道是错误的数据,因为各特征图间是有时间依赖关系的,此时LSTM就会根据其他特征图的正确数据给出对Mi的一个预测,从而可忽略Mi中的错误数据,于是,就不会因为错误数据的存在而对识别准确率产生太大影响。
4.4 实时性
本系统对算法的一个很重要的要求是实时性。从模型本身来说,以下两方面的改进提升了实时性。首先OI-LSTM模型没有使用全连接层,而是使用LSTM按时序顺序来组织综合各个特征图的信息。另外OI-LSTM的卷积层并不是简单CNN叠加,而是使用了改良后的O-Inception结构替代了普通的大卷积核的CNN。通过计算可知,如果模型中包含过多的全连接层,将导致模型整体的训练参数呈指数增长,过多的训练参数必然会增加整个模型的训练时间以及动作的识别时间。另外过大的卷积核,会使窗口滑动期间GPU计算结果的过程中做更多的加法与乘法运算,这里使用Inception结构去代替大卷积核,避免复杂的运算,减轻GPU的压力,把更多的算力用于模型深度的加深。基于以上两方面的优化,模型的训练速度和识别速度都得到了显著的提升,识别准确率却没有下降。
5 性能测试与分析
本章将在WISDM和UCI两个数据集上验证本次研究所提出的OI-LSTM网络的高识别率和高容错性,数据集包含从Android智能手机获取的加速度计时间序列数据。这些数据是在用户执行一系列不同的活动时收集的,例如散步、慢跑、爬楼梯、坐着、下楼梯和站立。数据集的70%用来训练,30%作为测试。这些数据分别来自36个和30个不同的使用者。5.1节介绍了实验环境,5.2节介绍了实验的评估标准,5.3节给出了O-Inception和DWN两个对比网络的详细网络结构,5.4节给出了相关实验结果及对实验结果的分析。
5.1 实验环境及模型参数
这里所设计的四种动作识别神经网络是使用python语言在TensorFlow上实现的,TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。
设备相关参数:GPU,GTX1080;内存,16 GB;CPU,至强E5;操作系统,Windows 7。
模型是在完全人工监督下训练的,从softmax层把梯度回传到卷积层、LSTM层。网络参数的优化使用随机梯度下降(stochastic gradient descent,SGD),Loss函数使用互熵损失,特别注意在含有LSTM的网络中,要另外使用截断梯度法。为了提高效率,模型训练时被分成200大小的mini-batch。学习率均设置为0.000 1,所有模型均训练1 000 epoch,所有参数的初始化均使用截断正态分布随机值。
5.2 性能评估指标
本文用精确率(Precision)、召回率(Recall)、F1值(F1 Measure)、平均准确率(Accuracy)等评测指标来衡量算法性能。
精确率=提取正确的的信息条数/提取的总条数,本文中精确率=各动作识别正确的个数/(各动作识别正确的个数+各动作识别错误的个数),如式(8)所示。
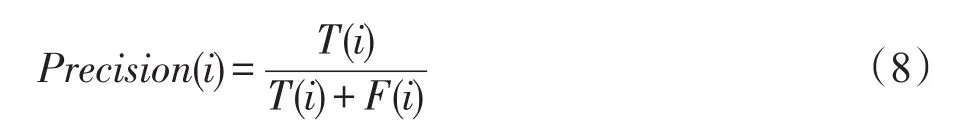
召回率=提取出的正确的信息条数/样本数目,本文中召回率=每类动作识别正确的个数/每类动作样本个数。

式(8)和式(9)中,T(i)表示识别为第i类动作正确的个数,F(i)表示识别为第i类动作错误的个数,D(i)表示第i类动作的样本数量。
F值是准确率和召回率的加权调和平均,即如式(10)所示。

当参数α=1时,F就是F1,即如式(11)所示。

平均准确率表示识别正确的所有动作数/样本总数。

其中,R表示识别正确的动作个数,A表示数据集含有的样本总数。
5.3 实验对比网络
为了观察OI-LSTM模型的性能,另外设计了图4所示的O-Inception卷积网和图5所示的深度可分离卷积网(depthwise separable network,DWN),并在UCI和WISDM两个数据集上分别对它们的准确性和容错性进行了测试,并和OI-LSTM进行对比。可以看到O-Inception卷积网和OI-LSTM使用了相同的特征提取模块。但是O-Inception卷积网使用特征提取模块提取到特征后,就直接输入到一个全连接层,仅仅利用全连接层把前面提取到的特征综合起来后直接进行识别,识别的结果没有利用到时序信息。
图5给出了采集的传感器数据在DWN中的流动情况。首先输入到一个卷积核大小为20,深度为8的卷积层,然后把得到的特征再输入到一个最大池化层(该池化操作的移动步长和窗口大小均为2),特征经过池化层后得到了更加显著的特征图。接下来,再把特征图作为输入,输入到一个深度可分离卷积层(其卷积核大小和深度均为2),该层得到的特征图已经融合了每个通道的特征,融合后的特征图经过池化和平滑处理后送入一个拥有1 000个神经元的全连接层,最后输入softmax层得到动作分类的概率分布。

Fig.4 O-Inception neural network图4 O-Inception神经网络
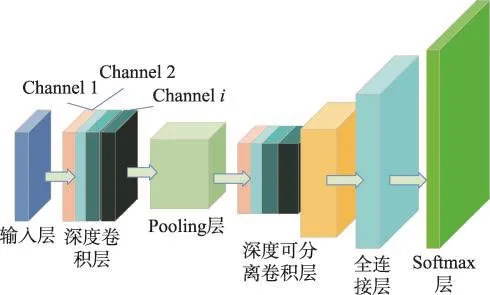
Fig.5 Depthwise separable network图5 深度可分离卷积网络
5.4 实验结果
5.4.1小节测试了OI-LSTM的识别准确率,实验结果表明模型在两个数据集上都得到了不错的效果。5.4.2小节着重测试了模型的容错率,实验结果显示模型在获得容错能力同时仍然拥有很高的识别率。5.4.3小节主要通过实验验证了本文所提出的模型的实时性优于其他模型。
5.4.1 准确率性能测试
本次实验将在两个数据集上做准确率测试。所得实验结果将和相关研究的论文中的其他方法的结果进行比较。实验结果如表2、表3所示。可以看到本文提出的OI-LSTM识别模型的准确率在两个不同的数据集上均高于相关论文中使用的方法。在WISDM数据集上,文献[19]因为使用了CNN并在dense层额外加入了人工提取的数学统计特征,因此它的准确率在相关研究中是最好的,但OI-LSTM、DWN和O-Inception模型在不使用任何人工特征的情况下,它们的准确率却均高于文献[19]中的准确率。OI-LSTM表现最为优秀,达到97.3%的准确率。如果将OI-LSTM的特征提取模块和时序依赖处理模块拆开形成两个网络O-Inception和双层LSTM,这两个网络的识别准确率分别为96.49%和94.62%,可以发现拆开后各自模块单独使用的效果远不如OILSTM,因此将这两种网络结构进行融合是有必要的,且效果提升明显。在UCI数据集上的效果更为明显,单独用特征提取模块中的O-Inception网络和时序依赖处理模块中的LSTM网络去做动作识别,准确率很低,甚至不如相关研究中的CNN+数学特征的方法,但是融合后的OI-LSTM网络的识别率远高于其他方法。实验结果还可以说明,特征提取模块中的O-Inception卷积结构的特征提取能力要高于普通CNN和深度可分离卷积。因为OI-LSTM继承了OInception的优秀的特征提取能力,而且还拥有了LSTM的时序信息处理能力,所以它的准确率是最高的。
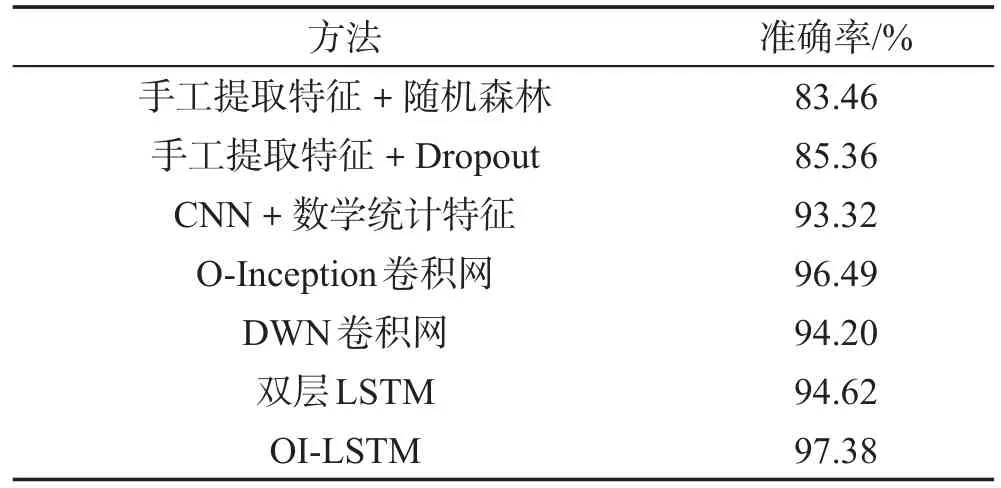
Table 2 Comparison of experimental results of different algorithms on WISDM表2 WISDM数据集上不同算法的实验结果对比
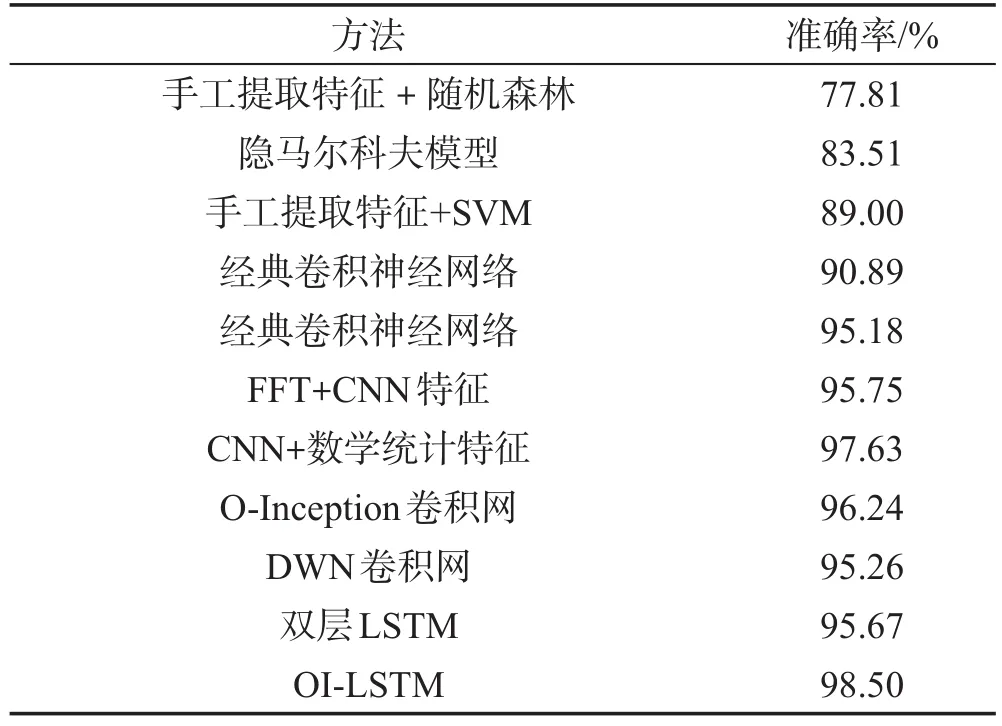
Table 3 Comparison of experimental results of different algorithms on UCI表3 UCI数据集上不同算法的实验结果对比
表4、表5列出了在WISDM和UCI上的各个动作详细分类结果,并与其他论文中的先进算法进行了比较。可以看到,在WISDM上慢跑、步行和站立是最容易识别的,不管是传统机器学习算法,还是本文所设计的四种神经网络其准确率都能达到90%以上的准确率,因为这两个动作的动作变化与其他动作变化区别最为明显,所以最好识别。比较难识别的是上下楼动作。例如上楼的识别,使用Basic featuers+RF算法准确率只能达60%,文献[19]中的CNN+数学特征也只能达到70%多,因为这两个动作最容易混淆。但本文所设计的OI-LSTM网络在上楼这个动作上的识别准确率已经接近90%。在UCI上,OI-LSTM在各个动作上的动作分类结果优势更为明显。另外可以发现单独使用特征提取模块中的OInception、时序依赖模块的双层LSTM和深度可分离卷积表现并不像在WISDM上那么优秀了。它们好像只是擅长其中的部分动作,比如O-Inception卷积只擅长识别躺和坐这两个动作,但识别站和上楼两个动作只有80%多的准确率,而OI-LSTM则没有劣势,基本都可以达到99%以上的准确率。从分类结果的准确性上可以得出,OI-LSTM模型在各个动作的各自准确率和综合准确率上,都远远高于其他模型。

Table 4 Classification precision on WISDM表4 WISDM上分类准确率 %
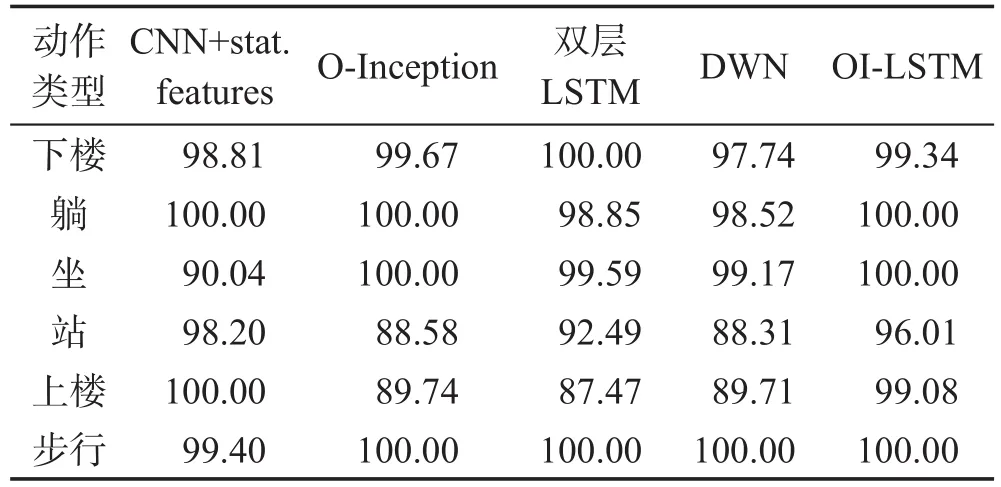
Table 5 Classification precision on UCI表5 UCI上分类准确率 %
为了更精细地观察OI-LSTM模型的性能,分别统计了4个模型O-Inception、DWN、LSTM、OI-LSTM在6个动作上的各自精确率、召回率和F1值,如表6、表7所示。可以看到,OI-LSTM模型的精确率、召回率和F1-score值都远高于其他三种结构的神经网络。实验结果表明OI-LSTM的各项性能指标都遥遥领先,几乎没有弱点。
通过记录各个网络在每个epoch训练结束后其在测试集上的准确率,得到如图6、图7所示的准确率变化图。其中绿色表示O-Inception神经网络,蓝色表示复合OI-LSTM神经网络,黑色表示LSTM,红色表示DWN。可以看到在训练过程中O-Inception卷积网和复合OI-LSTM的准确率在200轮训练后较其他两种网络就有明显的优势。这说明OI-LSTM的特征提取模块提取到的特征图在200 epoch训练后就可以被用来精确分类。WISDM数据集上,O-Inception卷积网络在600 epoch以后准确率就趋于平缓,更糟的是,在UCI数据集上不到50 epoch就很难提升了;而OI-LSTM网络在两个数据集上的整个训练过程中,一直振动上升,并逐渐缓慢超过单独的O-Inception网络结构,UCI数据集上尤为明显。O-Inception之所以在达到一定准确率后出现了瓶颈,准确率难以再次提升,就是因为它丢失了时序信息,也正因如此OILSTM会在训练次数增加的同时准确率会缓慢提升并超过O-Inception。

Table 6 Precision,recall and F1-score of action recognition on WISDM表6 WISDM上的精确率、召回率与F1值 %
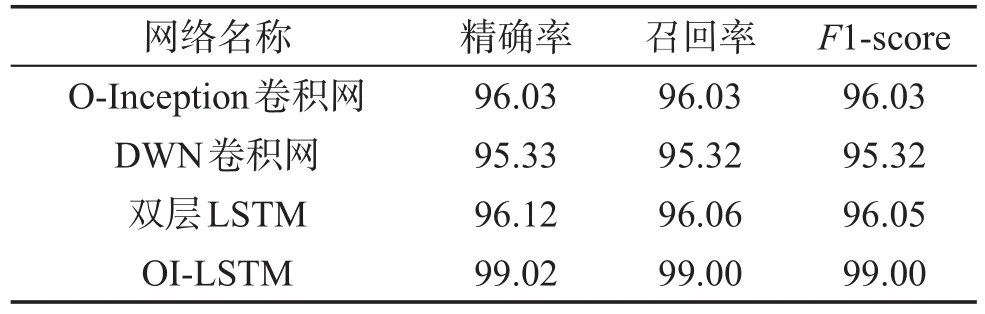
Table 7 Precision,recall and F1-score of action recognition on UCI表7 UCI上的精确率、召回率与F1值 %

Fig.6 Accuracy curve on UCI图6 UCI上准确率变化曲线图
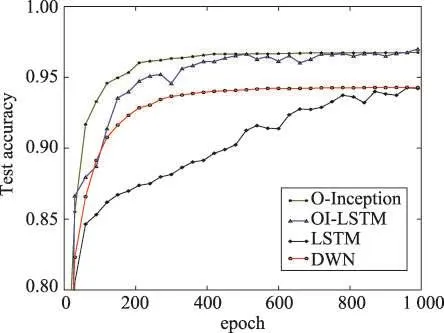
Fig.7 Accuracy curve on WISDM图7 WISDM上准确率变化曲线图
5.4.2 容错能力测试
下面的实验则将注意力放在各种算法的数据容错能力上。为了此实验的顺利进行,将模拟传感器出错,即在WISDM数据和UCI数据集上随机添加错误数据,用如下方式添加:(1)在传感器读数范围内取随机数代替原数据正确值。(2)用NAN类型数据代替原数据正确值。(3)用INF类型数据代替原数据正确值。
实验结果的准确率变化图如图8、图9所示。从图9中可以看到,LSTM和O-Inception结构的网络准确率达到40%左右就不再变化,loss值无法降低,网络的训练无法进行。而DWN神经网络和OI-LSTM网络则可以顺利地训练下去。但值得注意的是,DWN虽然具有容错能力,但是其准确率很大程度上逊色于OI-LSTM,这取决于其容错能力的获得原理与OI-LSTM不同。DWN的容错性得力于其特有的卷积方式,因为各个通道分开卷积,例如1通道的某个a数据发生错误,但是2、3、4等通道数据b、c、d是正确的,由深度可分离卷积的卷积方式可知,最后的总体特征图中的某个点e是由最后一层的pointwise convolution操作把1、2、3、4通道的a、b、c、d综合起来得到的,而b、c、d在3个通道上都是正确的,那么1通道的错误数据a将会被弱化忽略,从而使得网络拥有了容错性。然而,也正是因为这种卷积方式使得网络无法在每一层综合各个通道的信息来得到更加全面的特征图,所以不可避免地丢失了特征图的表达能力,导致准确率有所下降。在4.3节中,已经分析了O-Inception和LSTM融合使得整个模型获得容错能力的原因,并发现它在获得容错能力的同时提升了准确率。基于此,OI-LSTM是优于DWN的。
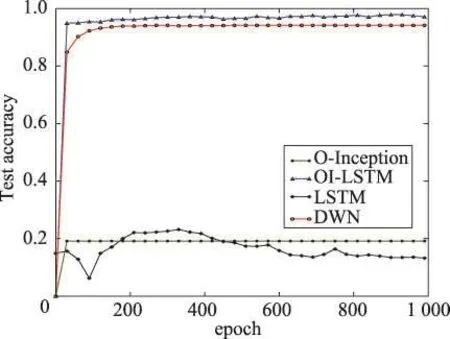
Fig.8 Accuracy curve on error UCI图8 含有错误数据UCI上的准确率变化曲线图
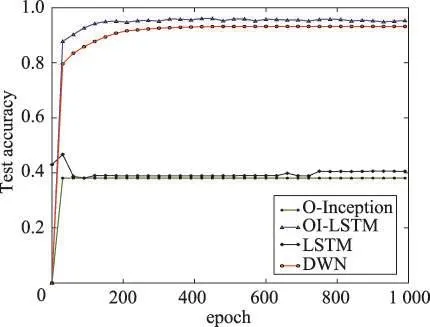
Fig.9 Accuracy curve on error WISDM图9 含有错误数据WISDM上的准确率变化曲线图
实验证明,O-Inception与LSTM的融合出现了1+1>2的效果,不仅使网络的准确率得到提升,还使网络拥有了数据容错能力,对错误数据不敏感。
5.4.3 实时性测试
本次实验验证了本文提出的O-Inception结构在实时性上的优势。实验统计了在UCI数据集上,4种网络OI-LSTM、O-Inception、DWN、LSTM同时训练500轮时的时间,通过对比得出OI-LSTM在速度上的优势。
实验结果如图10、图11所示。从图10中可以看出O-Inception网络的实时性具有很大的优势,是4种类型的网络中训练速度最快的。O-Inception结构的模型的速度是LSTM的10倍之多。从实验结果可以看出,如果单纯使用LSTM这一种结构,是无法满足系统对于实时性的要求的。另外,本文提出的OILSTM模型网络虽然速度稍逊于O-Inception,但是其足以满足系统所要求的实时性。值得注意的是,OILSTM在网络深度加深的情况下,速度比浅层网络DWN还要快。虽然OI-LSTM中含有LSTM结构,但它的速度要比LSTM快5倍之多。从这里可以看出这种融合方式在准确率提升的同时效率也得到了极大的提升。
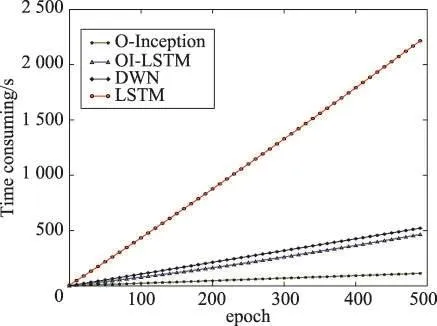
Fig.10 Training time curve of 4 models图10 4种模型训练时间曲线图

Fig.11 Training time consume curve of 3 models图11 3种模型训练时间局部曲线图
图11是把LSTM变化曲线去掉后放大的曲线图。去除LSTM结构的影响,单独从CNN特征提取角度来分析,使用O-Inception结构有效提升了模型提取特征图的速度,它的速度是DWN的5倍。另外因为OI-LSTM用LSTM替换了全连接层,在一定程度上快于DWN这种传统CNN网络。
6 结论
本文提出了OI-LSTM神经网络的动作识别模型,同时设计了O-Inception结构的卷积网、深度可分离卷积网DWN和双层LSTM网络作为对比网络。通过实验可知O-Inception结构的特征提取能力高于普通CNN和DWN,但DWN具有一定数据容错性。最为突出的是复合OI-LSTM,它在O-Inception卷积网的基础上融合了LSTM,使得准确率得到显著提升的同时,获得了一定的容错能力,对错误数据不敏感,从而提高了系统的鲁棒性,使整个系统具有容错性。
为了评估所提出的OI-LSTM模型的性能,在两个流行的WISDM和UCI数据集上进行了测试。实验结果表明本文提出的OI-LSTM的准确性明显优于其他最优方法,并在两个数据集上都建立了最先进的结果。另外,OI-LSTM模型还具有其他模型所不具有的数据容错性。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
电子制作(2018年19期)2018-11-14 02:37:08
数学物理学报(2017年5期)2017-11-23 07:51:31
自动化学报(2017年11期)2017-04-04 02:52:58
工业设计(2016年8期)2016-04-16 02:43:26
电测与仪表(2015年2期)2015-04-09 11:28:56
噪声与振动控制(2015年4期)2015-01-01 07:08:21
电子技术与软件工程(2014年20期)2014-11-19 09:46:07
新课程学习·中(2013年3期)2013-06-14 05:55:20
