
基于集成算法的股票指数预测*
2018-12-18 11:49孙德山
经济数学 2018年4期
王 玥,孙德山
(辽宁师范大学 数学学院 ,辽宁 大连 116029)
1 引 言
随着经济的不断发展,股票市场逐渐在人们的生活中占据了重要的位置.经过一定时期的发展,股票市场已趋于稳定,但还存在一定的问题和缺陷.目前,股票市场已成为众多学者和投资者的研究对象.政府如何有效地对市场进行监管、防范金融风险;投资者如何最小化投资风险的同时获得最大收益,这些问题都跟股票的准确预测有关.
股票价格起伏不定,观察股票的涨跌情况主要是关注股票指数的浮动情况.股市指数是由证券交易所或金融服务机构编制的表明股票行市变动的一种供参考的指示数字.具体某一种股票的价格变化,投资者方便了解;对于多种股票的价格变化,可以参考大盘的走势.为了适应这种情况和需要,一些金融服务机构根据市场的情况,编制出股票价格指数,公开发布,作为市场价格变动的指标.投资者据此就可以检验自己投资的效果,并用以预测股票市场的动向.
合理的预测股票趋势可以给投资者提供一定的参考,近些年来,人们对股市研究越来越多,研究方法也越来越多[1].文献[2]运用Bayes决策法分析股票价格,得出此方法在分析中是可行的.文献[3]运用逐步回归分析法对钢铁业股票价格进行了研究,最优方程拟合程度达到了80%.文献[4-5]使用了SVM来预测股票开盘价,并对参数选取作了一定的实验.与上述方法不同,集成算法以简单且效果良好被广泛应用,选取集成算法通过股票前一天的数据来预测后一天的开盘价涨跌趋势,并将结果进行比较分析.
2 集成算法介绍
2.1 Bagging
Bagging是一种基于Bootstrap的统计方法[6],从总体中取出多个训练集,在每个训练集中重复取样,假定给定一个训练样本包含m个数据集,先随机取出一部分样本进行实验,再把该样本放回数据集中.假定,这个样本下次有可能在被选中.经过m次随机重复操作,得到m个样本的采样集.对每个采样集,分别训练出一个学习器,再将这些学习器结合,就是Bagging的基本流程.
其基本思想为:
1)给定一个弱学习算法和一个训练集;
2)单个弱学习算法准确率不高;
3)将该学习算法使用多次,得出预测函数序列,进行投票;
4)最后结果准确率将得到提高.
2.2 Boosting
与Bagging相似,Boosting包含了众多决策树的结合,是可将弱学习器提升为强学习器的算法.首先,通过boosting框架对训练样本集的操作,得到不同的训练样本子集,在训练出这些样本的基学习器.再根据基学习器的表现对训练样本的分布进行调整,然后将调整后的样本分布来训练下一个基学习器.将这些学习器进行加权融合,产生最后的分类器.单个的分类器识别率不一定很好,但是联合后的结果会有很好的识别率,从而提高了弱学习器的识别率.
2.3 Random Forest
Random Forest由贝尔实验室的Tin Kam Ho于2001年提出,这个方法是结合Breimans 的 "Bootstrap aggregating"和 Ho 的"random subspace method"想法以建造决策树的集合.随机森林分类器是由单棵树分类{h(x,βk),k=1,2,…}集合构成的组合分类器[7],其中x是输入向量,βk是独立同分布的随机变量序列.其中每个分类器是独立于输入向量的随机向量生成的,每棵树为最普遍的类别投票来进行分类.
和其他算法相比,Random Forest具有以下优点:
1)可以有效的处理高维度数据;
2)在对缺失数据进行估计时,就算存在大量的数据缺失,随机森林也能较好地保持精确性;
3)对于不平衡的数据集来说,可以平衡误差.
3 实证分析
采用R语言程序,选用gbm,random Forest, ipred三个程序包来实现3种集成算法.数据选取股票市场中的上证指数,深证指数,中小板指数,创业板指数的近期数据.分别采用上述3种方法将数据进行分析,用前一天的开盘价、收盘价、成交量、MA5(5日均线)、CCI(顺势指标)、OBV(能量潮)6个数据,来预测后一天的开盘价.如果,前一天的开盘价比后一天的开盘价高,则用“1”表示;如果,前一天的开盘价比后一天的开盘价低,则用“0”表示.
随机选取中小板指的200个数据(2017.01.24-2017.11.20),深证成指的200个数据(2016.12.01-2017.09.21),上证指数的200个数据(2017.05.05-2018.02.27),创业板指的200个数据(2017.06.06-2018.03.27),来实现实验,结果见表1.上述数据的开盘价图像如图1~4.
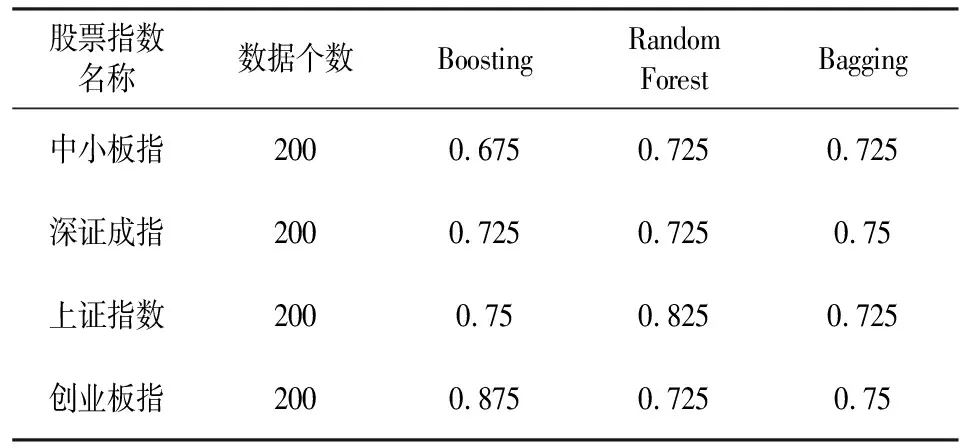
表1 分类结果
图1 中小扳指开盘价

图2 深证成指开盘价

图3 上证指数开盘价(200个数据)
观察表1可知,Boosting在预测创业板指上结果最好,准确率是所有结果里最好的;Random Forest在预测中小板指、上证指数上结果最好;Bagging相比其他两种方法则适用于预测深证成指.
选取中小板中的大连重工、深证A股的中南建设、上证A股的中国医药、创业板的东方国信四支股票;选取数据时间范围为2017.07.21-2018.05.17.用上述方法进行分析,得到表2结果.
图4 创业板指开盘价

股票指数名称数据个数BoostingRandomForestBagging大连重工2000.6750.750.775中南建设2000.7250.750.7中国医药2000.7250.750.7东方国信2000.6250.8250.725
从表2中可以看出,集成算法在数据个数为200的时候,可以对第二天的开盘价进行较好的预测.
4 结 论
通过实验分析三种不同的集成算法的结果,预测不同股票的开盘价涨跌,可知,不同的集成分类方法适用于不同的股票指数的分类.在研究过程中,合理的选取参数会对实验结果产生一定的影响,但是运算量较大,时间较长,以后会对选取参数方法进行研究.对于进行短期的预测,上述方法较为合适.但是对于长期预测,股票市场具有不稳定性,以及不排除突发因素的影响,需要人们更加深入的研究.
猜你喜欢
科技创新与应用(2020年6期)2020-02-29
中国外汇(2019年20期)2019-11-25
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
智富时代(2017年1期)2017-03-10
智富时代(2017年1期)2017-03-10
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
