
基于全卷积网络和条件随机场的宫颈癌细胞学图像的细胞核分割
2018-12-14 05:26刘一鸣张鹏程桂志国
计算机应用 2018年11期
刘一鸣,张鹏程,刘 祎,桂志国
(中北大学 生物医学成像与影像大数据山西省重点实验室,太原 030051)(*通信作者电子邮箱gzgtg@163.com)
0 引言
宫颈癌是全球女性因癌症死亡的最重要原因之一,每年有近27万人死亡[1]。巴氏涂片由Papanicolaou[2]于1942年提出,是宫颈癌预防和早期检测的最简单但是最重要的细胞学筛查手段之一[3]。
在传统的宫颈癌细胞学筛查中,细胞涂片是通过细胞学家或者病理学家手动筛查的,是高重复性、高耗时的工作,即使是最有经验的细胞学家或者病理学家,在长时间的筛查中也会因为疲倦和注意力下降等原因错分很多细胞, 因此,宫颈癌的自动计算机辅助细胞学筛查与诊断系统的发展具有重要的临床意义。这类系统的主要目的是在一张涂片中,将少量可疑的异常细胞从数千个细胞中挑选出来,供医生进行进一步筛查与诊断。实际上,医生是通过TBS(The 2001 Bethesda System)来判断细胞是否有异常[1],而这些异常细胞多数表现为细胞核的特征异常(如:形状、颜色、尺寸等),这些特征在医生的决策中起到了非常重要的作用。
辅助诊断系统可以利用这些特征来进行筛查, 总体上需要执行细胞核的分割,特征提取和分类等步骤才能将特征异常的细胞自动筛查出来; 而分割作为这些处理过程的第一步,其精确度和效率决定了异常细胞识别的准确率和可实施性。但是由于涂片中细胞的不规则形状和染色质的不均匀分布等因素,准确分割细胞核较为困难[4]。
近年来,针对分割细胞核的算法,主要基于活动轮廓[5]、基于水平集[6]、基于分水岭[7-8]、基于聚类方法[9]、基于无监督分类[10]以及基于形状建模[11]等方法。其中,大多数算法未用到细胞核的先验知识,仅运用细胞图像的空间域信息来进行分割,在某些细胞核与细胞质的不明显过渡区域,分割精度较差,少数算法用到了细胞核的形状等简单先验知识,但也因先验知识有限,分割结果不够鲁棒, 例如,Garcia-Gonzalez等[11]提出了一种首先运用多尺度边缘检测进行初始分割,然后运用椭圆形状逼近的方法。该方法在某些分割场景下,如异常细胞的细胞核形状不规则时,得到的结果较差。
针对现有方法结合空间域信息与先验知识不充分而分割不够鲁棒的问题,本文提出一种结合了全卷积网络(Fully Convolutional Network, FCN)[12]和全连接条件随机场(Conditional Random Field, CRF)[13]的细胞核图像分割算法。本文先构建符合Herlev巴氏涂片数据集的微型FCN(Tiny-FCN, T-FCN),T-FCN以每个像素的类别作为监督信息,其多层网络在训练过程中可自主学习对分割结果有利的特征,学习到的特征数量与层次都较以往的先验信息多。由于在经过多个池化层后,分割精度下降,T-FCN只能得到粗分割结果,而全连接CRF可以充分运用细胞图像中全部像素的色彩值和位置信息[14],因此,本文最终通过最小化全连接CRF的能量函数来最大化粗分割图像的后验概率,优化T-FCN的粗分割结果。
1 T-FCN与全连接CRF
为了有效利用空间域信息与先验知识,本文结合了T-FCN与全连接CRF两种方法: T-FCN利用标注图像(Ground Truth, GT)的像素级先验知识作为监督来训练模型; CRF则利用了T-FCN得到的粗分割图像和图像本身的空间域信息进行优化。
本文方法包括两个阶段,即粗分割阶段和优化阶段,如图1所示。在粗分割阶段,搭建了T-FCN,训练该网络得到用于细胞核粗分割的模型。在优化阶段,通过全连接CRF来将分割轮廓细化,并剔除较小的误分割区域。
1.1 T-CNN
1.1.1 FCN
卷积神经网络(Convolutional Neural Network, CNN)一般由输入层、卷积层、激活层、池化层和全连接层组成: 输入为图像的像素值,卷积层配合池化层,从底层到高层,随着感受野的扩充,完成低级特征到高级特征的提取; 在全连接层,将最终得到的前向传播运算结果传递到损失层; 损失层以真实类别作为监督信息,以最小化分类误差为目标,通过反向传播来调整网络各层的权值,完成模型的训练。
FCN已成功应用于语义分割,FCN将CNN中的全连接层替换为卷积层,保留了高级特征的空间信息,再通过反卷积层将特征图还原到原始图像的尺寸,形成pixel-to-pixel的监督。这就使得CNN的图像整体分类转变为图像中所有像素的分类,从而实现整幅图像的语义分割[15]。
1.1.2 T-FCN
对于T-FCN而言,感受野的设定与可检测到的目标的尺度密切相关。感受野,即为决定某一层特征图中一个响应值所对应的输入层的区域尺寸,CNN由于全连接层的存在,感受野一定能够包含全图信息。FCN缺乏全连接层,因此对于特定的数据集,需要设定具有适合目标区域感受野的网络。若感受野小于目标尺寸,则预测值只是目标的局部响应,此时属于相同目标的像素可能产生不连续的预测,若感受野大于目标尺寸,则目标可能被忽略而预测为背景[16]。以FCN-VGG16为例,运用FCN- 8s分割的分割结果,如图2所示。

图2 感受野与目标分辨率不符产生不良分割
现有的FCN一般都基于ImageNet图像分类竞赛著名网络设计,如Alexnet[17]、VGGNet[18]和GoogLeNet[19]等网络。从感受野的角度来看,大体符合ImageNet数据集中图像目标的分辨率,Alexnet最后一个池化层的感受野为195,VGG16最后池化层的感受野为212,GoogLeNet loss1均值池化层感受野为235。Herlev数据集中的7类图像,低度鳞状上皮细胞核最小,且细胞核外接矩形短边尺寸基本不小于30,非典型增生细胞最大,且细胞核外接矩形短边尺寸基本不超过85。由于在临床条件中,巴氏染色图像的放大率保持不变,因此,本文保持了Herlev的原始放大率,即不进行图像的缩放。对于当前Herlev数据集,细胞核分辨率范围较广,不存在可以同时良好分割出不同分辨率细胞核的感受野,这就需要确定对不同分辨率细胞核的分割优先级。T-FCN作为粗分割,首先要求识别出所有的细胞核,因此需要先分割出小分辨率的细胞核,则感受野的设定应当以小分辨率细胞核外接矩形短边尺寸为依据。即对于外接矩形短边不小于30的细胞核分辨率,需要在分割最小细胞核的前提下尽可能提升大目标的分割效果。考虑到细胞核与细胞质在图像中的过渡区域的纹理信息约为5个像素,感受野应增加10像素,因此确保利用所有细胞核信息的感受野尺寸不小于40。
在相同感受野条件下,小尺寸卷积核和非线性激活函数交替的结构,由于可以更好地非线性化特征而比大尺寸卷积核表现更好[18]。因为提取像素八邻域信息的最小卷积核尺寸为3×3,本文采用3×3的卷积核与池化层构造FCN。VGG的所有结构可以近似为3×3卷积核CNN的一个遍历,在这些结构中,VGG16的C结构pool3的感受野为36,VGG16的D结构pool3的感受野为44。从感受野的角度来看,VGG16的D结构中pool3层前的网络构造出的FCN可以良好分割出鳞状上皮细胞的细胞核。因此本文在上述网络结构后添加一个卷积层和一个上采样层作为T-FCN的初始结构,如图3所示。

图3 T-FCN初始网络
T-FCN的输出类别包括背景、正常细胞核和异常细胞核三类,这里将正常细胞核和异常细胞核两类合并为细胞核一类,得到包含细胞核区域和背景区域的预测图像。
运用Zhang等[20]提出的方法进行细胞核的筛选,即选取距离图像中心最近的轮廓区域的长宽均扩展20像素的区域与边界的交集作为该细胞图像的细胞核区域,其他区域均赋值为背景。因此,T-FCN最终的输出为具有单个细胞核区域和背景区域的预测图像。
T-FCN的下采样,在获取高级特征的同时也牺牲了分割精度,在不平滑的边缘分割较为粗糙,这是所有FCN固有的缺点,且T-FCN由于感受野根据细胞核来设计,不能有效利用全局细胞图像的信息,在细胞图像中部分较小的孤立区域存在误分割。
1.2 T-FCN-全连接CRF
1.2.1 全连接CRF
全连接 CRF考虑了细胞图像中所有像素间的关系,以最小化包含有细胞图像全部像素标签信息、位置信息和色彩值信息的能量函数为目标,来细化T-FCN的分割边缘,并剔除较小的误分割区域。
像素的标签信息来自T-FCN最终的输出,即包含单个细胞核区域和背景区域的预测图像,其中每个位置的像素值都对应标签集合L={l1,l2,…,lk}中的一个标签变量,这里k=2,即背景和细胞核,所有的变量构成一个随机场Y={Y1,Y2,…,YN},Yj为像素点j对应的类别标签。在另一组变量上定义另一个随机场X={X1,X2,…,XN},N为细胞图像的像素数量,Xj代表细胞图像像素点j的颜色向量。则条件随机场(X,Y)可以通过一个吉布斯分布表示:
(1)
其中,Z(X)为归一化项
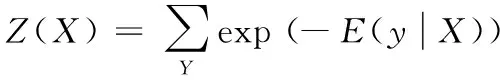
(2)
E(Y|X)为输入图像像素点分布为X、标签分布为Y时的能量。条件随机场的目标即求最大后验概率对应的随机场y∈LN,由于以输入图像像素点分布X为固定条件,为了表示方便,后续推导过程中,将省略条件X的表示。则对于y∈LN分布,其对应的吉布斯能量为:
(3)
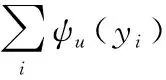
ψu(yi)=-lnyi
(4)

ψp(yi,yj)=
(5)
式中,μ(yi,yj)为标签兼容性函数,这里运用Potts模型:
(6)
括号中第一个指数函数被称为Appearance Kernel,第二个指数函数被称为Smooth Kernel,p表示像素的位置。对于RGB图像而言,Appearance Kernel相当于在五维空间中衡量像素的相似性,即鼓励位置相近,颜色相似的像素具有一致的分类,θα和θβ控制相近和相似的程度。Smooth Kernel则用于移除孤立小区域,θγ控制像素相近的程度。
1.2.2 T-FCN-全连接CRF推断
全连接CRF的成对能量项数量庞大,使用传统的算法推断时间复杂度太高,因此运用由Krähenbühl等[13]提出的基于平均场近似的高效推断方法。该方法提出了一种可以替代CRF原始分布P(y)的简单分布Q(y),且Y在这个分布内相互独立:
(7)
最小化Q和P的KL(Kullback-Leibler)散度:
(8)
得到迭代更新公式:
Qi(yi=l)=
(9)
整个推断过程,以T-CRF的最终预测图像为输入,以迭代结束后的y作为全连接CRF的输出,输出的y为了观测方便,映射为彩色图像,即为流程图中的CRF优化结果。
2 数据集及其预处理
2.1 数据集
本文方法通过一个公共数据集进行评估,即Herlev巴氏涂片新版数据集。该数据集由海莱乌大学医院 (Herlev University Hospital, HUH)和丹麦科技大学(Technical University of Denmark, TUD)搜集,其中包含了917个单独的巴氏涂片细胞图像。Herlev数据集中的图像是在0.201 μm/pixel的放大率下得到的,平均图像尺寸为156×140。所有图像的长宽中,最长的边为768,最短的边为32,变化范围大。917个细胞图像分为7类, 如图4所示,其中,前3类为正常细胞,后4类为异常细胞。每个细胞均有细胞学家和医生手工标注的实际细胞核、细胞质和背景区域。7类示例细胞及其GT图像如图4,为了保留图像中细胞核的相对尺度信息,这里未统一示例细胞图像尺寸,GT图像中黑色区域内深灰色区域代表细胞核,黑色区域代表细胞质,浅灰区域代表主体细胞周边背景,黑色区域外深灰区域是整幅图像的背景,也即与主体细胞无关区域。
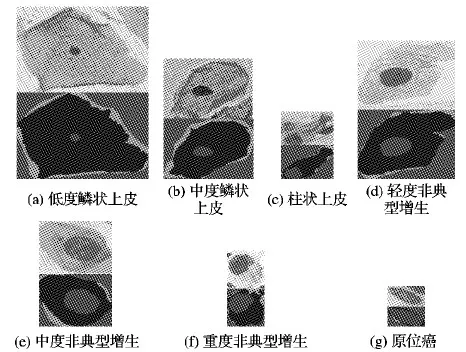
图4 Herlev数据集中7类示例图片
Herlev数据集中917张细胞的详细分布情况见表1。
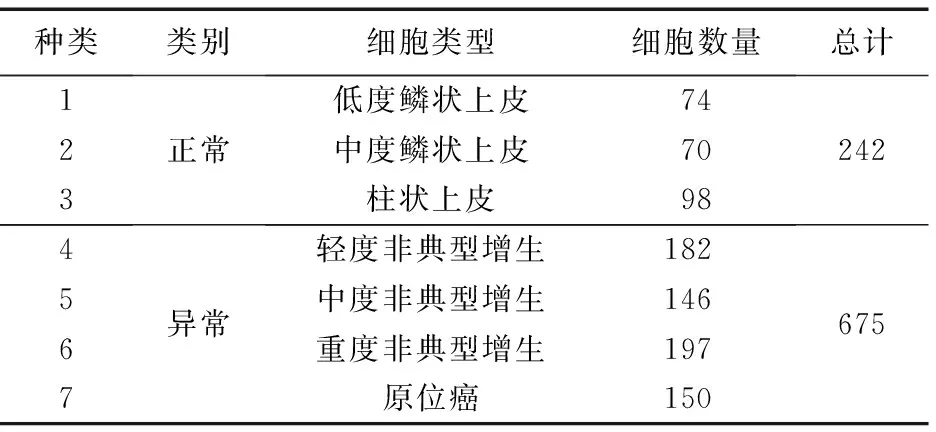
表1 Herlev数据集细胞分布
2.2 细胞图像区域提取与标签制作
对于宫颈细胞数据集Herlev而言,如图4中的(b)、(c)、(f)和(g),并不只是包含主体细胞本身,在GT图像的黑色区域外深灰区域存在其他细胞的细胞核和细胞质,但是并未进行标注。因此,以此标注得到的标签作为细胞的监督信息直接进行训练,会引入较多干扰,且完全通过限制长宽来分离主体细胞图像较为困难。考虑到FCN的训练存在减均值的步骤,本文将GT图像中黑色区域外深灰区域对应的细胞图像中的区域用数据集中细胞图像整体的均值来替代, 由此得到的图4中细胞图像的主体细胞区域提取结果如图5所示。

图5 细胞图像区域提取
对于细胞图像中各像素的标签:若像素对应GT图中的黑色区域外深灰区域、浅灰区域和黑色区域,赋值为0;若对应黑色区域内深灰色区域则根据其所属类别,正常细胞核赋值为1,异常细胞核赋值为2。
2.3 数据增强
从表1中可以看出,Herlev数据集中正常和异常细胞的数量比较失衡,从图5中可以看出,正常细胞核的像素数量也较异常细胞核的像素数量少,这就使得在FCN训练阶段,正常细胞核像素数量严重少于异常细胞核与背景两类的像素数量,考虑到Herlev数据集本身的图像数量较少,本文通过增强训练集中正常细胞图像的数量,来平衡训练集中正常细胞核像素和异常细胞核像素的数量。
对于训练集中的正常细胞图像,增强的倍数应当至少使得正常和异常两类像素数量基本相当,同时需要防止因增强倍数太大而导致的模型过拟合,因此,将正常细胞核的增强倍数确定为3。为了确保所有的增强图像有效,要求图像中所有细胞核在增强后依然在图像中,因此采用随机水平或垂直翻转、幅度为0.01的随机平移抖动的组合来进行增强。
3 实验结果与分析
3.1 评估方法
对于细胞核分割结果的评估,需要细胞核和整个细胞的GT图。以3个像素级精度的参数作为分割结果的评价方法,分别为查准率(Precision)、查全率(Recall)和Zijdenbos相似性指数(Zijdenbos Similarity Index, ZSI)[21]:
(10)
(11)
(12)
其中:TP为检测正确的细胞核像素数,FP为检测为细胞核但在GT中不是细胞核的像素数,FN为在GT中为细胞核但是未检测到的像素数。查准率反映正确检测为细胞核像素数占所有检测为细胞核像素数的比例, 查全率为正确检测为细胞核的像素数占所有GT中细胞核像素数的比例,查准率低表明误检像素较多,查全率低则代表漏检像素较多,因此一个良好的分割要求两者均具有良好的表现。ZSI则综合考虑了TP、FP和FN,根据Zijdenbos的描述[21],检测到分割边界与GT在ZSI大于0.7时高度匹配。
3.2 实验结果与分析
本文使用第2章得到的数据集进行实验,在Windows 10的Caffe[22]框架上实现。梯度下降算法运用随机梯度下降法(Stochastic Gradient Descent, SGD), 批大小为4,迭代次数为100 000,动量为0.9,学习率策略为inv,基础学习率为0.001,gamma为0.000 1,power为0.75,dropout为0.5。为了评估的客观性,采用10折交叉验证。
在T-FCN训练阶段,由于感受野的限制,只截取了VGG16的D结构的pool3层前的网络,使得网络提取的特征较少,因此需要充分挖掘底层的特征,本文将各卷积层的卷积核数量扩展为原卷积核数量的2倍。
从训练集和测试集的角度进行本次修改的评估。训练集以训练损失(Loss)作为评估指标,在测试集上,由于图像中背景比重太大,直接以全局像素精度(Overall Accuracy, OA)度量所得结果中背景部分的影响将远大于细胞核部分。平均像素精度(Mean Accuracy, MA) 是OA的一种提升,首先计算每个类别中正确分类像素的比例,然后求所有类别的正确分类像素比例的均值,可以避免某一类像素多或少产生的影响。以第3折为例,评估结果如图6。
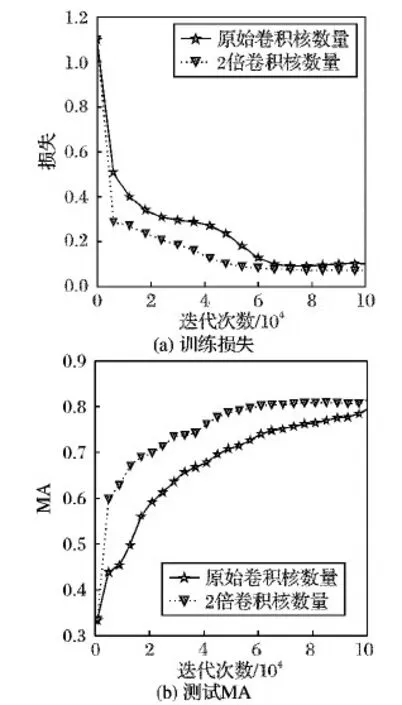
图6 T-FCN卷积核数量优化
图6结果显示,将卷积核数量扩展为2倍,可以稳定提升网络性能,因此本文以扩展2倍数量的卷积核得的网络作为最终的T-FCN。
在FCN- 8s中,由于感受野与细胞核分辨率相差太大,导致网络不收敛,与本文最终的T-FCN的结果对比如图7。图7中,在训练阶段,T-FCN的损失下降快并收敛于0.1以下,而FCN- 8s的损失并未收敛;在测试阶段,T-FCN的测试MA达到0.8,而FCN- 8s一直为0.33。模型实测图像显示,FCN- 8s将所有的像素均分为背景。实验结果表明,本文针对Herlev数据集修改的T-FCN可以明显提升细胞核分割结果。对于单幅图像的平均粗分割时间,FCN- 8s用时1.359 s,而T-FCN用时0.192 s,极大提升了粗分割效率,满足了临床对细胞学图像分割实时性的需求。
图7 T-FCN与FCN- 8s表现对比
在优化阶段,CRF涉及参数有θα、θβ、θγ以及迭代次数n,对于θα、θβ和θγ,经过多次实验并结合文献[12],在θγ=1、θα=20和θβ=10时,实际表现良好。迭代次数n在高于10时,Q和P的KL散度几乎停止下降,考虑到计算复杂度,n确定为10。
确定T-FCN与全连接CRF参数后,本文方法与几种分割方法[9, 23-24]的对比结果见表2。其中,文献[23]主要运用了多尺度分水岭与二分类等方法,文献[24]则主要运用了放射梯度向量流(Radiating Gradient Vector Flow, RGVF)与聚类等方法。表2中,从Herlev数据集中917张细胞学图像的平均分割指标来看,本文是四种算法中唯一一种在查准率、查全率以及ZSI三个指标上,均达到0.90以上的算法。
文献[23]在查准率与查全率上有一个较好的权衡,因此在ZSI上领先RGVF。RGVF则由于过度侧重于查全率,导致其在查准率上仅为0.83,表明其虽然对细胞核的漏检较少,但是误检较多,因此不能为后续细胞学图像的诊断提供较为可靠的分割结果。本文算法兼顾了查准率与查全率且二者均表现较优,在ZSI上表现最好。
对于异常细胞而言,随着异常程度的增大,传统算法很难克服染色质分布不均匀以及细胞核形状的高度不规则等困难,因此在查准率或查全率上具有一定取舍,实验结果的三个指标无法做到全部都表现良好。而在本文中,T-FCN对细胞核像素级先验知识的运用与全连接条件随机场对空域信息的运用都非常充分,提取到不同层次不同尺度的众多特征,因此实验结果的三个指标不仅不受细胞核形状不规则程度增大等因素的影响,反而更好。实验结果表明本文方法对异常细胞的筛查更加有效。

表2 4种方法分割结果对比
4 结语
本文根据Herlev数据集的特点,为了提高细胞核分割的查全率,结合VGG16的D结构,搭建出适合Herlev数据集中较小细胞核语义分割的T-FCN, 但是T-FCN在分割数据集中大尺寸的细胞核时,存在将部分细胞核区域分割为背景的情况,同时可能将细胞图像中尺寸较小的杂质分为细胞核。对此,本文通过细胞核子图的确定来排除部分误分割结果,得到最终粗分割结果;将粗分割结果输入到包含有全图像素标签信息、位置信息和色彩值信息的全连接CRF中,通过最小化全连接CRF的能量函数来优化分割结果,进一步剔除了粗分割结果中的误分割区域,同时细化了分割的边界。临床细胞图像的采集具有固定背景、光照以及更为稳定的苏木精-伊红(Hematoxylin-Eosin, HE)染色法等优点,而Herlev数据集中的细胞学图像背景复杂、对比度变化范围较大且染色效果不够稳定。由于临床数据集的缺乏,本文未能完成临床性能的评估。但是在Herlev数据集上的实验结果显示,本文提出方法的查准率、查全率和ZSI三个评价指标均超过0.9,表明细胞核分割结果与GT图中的细胞核高度匹配,相较其他三种方法具有明显的优势。本文算法表现出的较优的鲁棒性和较强的泛化能力有望在临床取得更好的细胞核分割结果, 且本文算法对异常细胞核分割的优秀表现也更加契合计算机辅助宫颈癌细胞学筛查系统的需求。
从最终实验结果来看,本文的T-FCN满足了优化阶段的精度需求,极大提升了粗分割效率,且粗分割存在的问题在全连接CRF中基本得到解决。但是T-FCN是一个相对简单的模型,如何将更加优秀的语义分割技术整合进来并提升分割精度是进一步努力的方向。
猜你喜欢
中学生物学(2022年3期)2022-05-13
中草药(2022年9期)2022-05-06
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
数码世界(2018年1期)2018-12-23
现代电子技术(2018年20期)2018-10-24
北京航空航天大学学报(2018年1期)2018-04-20
新教育时代·教师版(2018年48期)2018-01-24
现代情报(2018年11期)2018-01-07
