
基于语义感知的图像美学质量评估方法
2018-12-14 05:26杨文雅宋广乐崔超然尹义龙
计算机应用 2018年11期
杨文雅,宋广乐,崔超然,尹义龙,2
(1.山东财经大学 计算机科学与技术学院,济南 250014; 2.山东大学 计算机科学与技术学院,济南 250014)(*通信作者电子邮箱crcui@sdufe.edu.cn)
0 引言
传统的客观图像质量评估方法主要关注在图像的获取、传输和存储等过程中引入的不同类型的失真(如噪声、扭曲、压缩等)以及由此带来的图像质量下降问题。随着图像采集设备的不断升级和编解码技术的快速进步,普通图像的失真问题目前已经得到一定程度的缓解, 因此,一些研究者开始尝试从美学的角度对图像质量进行客观评估,并提出了图像美学质量评估的概念。
图像美学质量评估旨在模拟人类视觉及审美思维,进而对图像进行美学建模,使计算机能够自动地对图像的美学价值进行定量的评价。伴随计算机视觉和模式识别等技术的快速发展,图像美学质量评估技术已经被应用到多个领域,例如: 在图像检索系统中,考虑返回图像的美学质量,为用户提供准确且更有吸引力的检索结果[1];针对用户拍摄的关于同一场景的多张候选照片,筛选最具美感的作品保存和展示,合理地降低数据的存储开销以便节省存储空间的成本[2];图像美学质量评估算法也可以部署在摄像机上,在用户拍照过程中实时地分析取景内容的美学质量[3]。
如图1所示,伴随计算机视觉和模式识别等技术的快速发展,图像美学质量评估通常被简化为一个分类问题,从而达到区分高美感图像和低美感图像的目的。许多数据驱动的方法[4-6]被相继提出,核心在于提取和构造有效的图像特征,进而利用模式识别技术建立图像内容表达和图像美学判定之间的关联。

图1 图像美学质量评估示例
早期的图像美学质量评估研究主要以摄影中的美学规则为先验知识,人为地设计提取图像的视觉特征,利用这些特征对高美感和低美感图像进行分类; 但是,研究人员在设计这些特征时,需要有一定的摄影经验, 同时,这些特征也无法全面地覆盖所有实用的摄影规则,而且为了抽取它们往往需要付出巨大的计算开销。近年来,伴随深度学习在模式识别领域的兴起,一些研究者开始尝试利用深层神经网络自动地抽取图像特征用于图像美学质量评估。
值得注意的是,不论是早期人工提取特征的方法还是当前比较热门的深度学习方法,在对图像进行美学质量评估时都只考虑图像视觉特征这一方面的信息; 然而,在实际生活中,在感受图像的视觉美感之前,人们首先要理解他们所看到的图像内容[5]。现有的大多数方法在进行图像美学质量评估时并没有考虑图像的语义信息,如图像的物体类别、场景类别,从而可能导致评估结果不准确。针对该问题,本文提出了一种新颖的基于语义感知的图像美学质量评估方法。对于每一幅图像,首先设计了3个卷积神经网络(Convolutional Neural Network, CNN)来分别提取图像的物体类别特征、场景类别特征以及美学特征;然后,将这3种特征输入到一个高层次的混合网络中以实现有效的特征融合;最后,利用融合后的网络对图像进行美学质量评估。
本文的主要贡献如下:
1)提出了一种基于语义感知的图像美学质量评估方法,在图像美学质量评价过程中有效地引入图像的语义理解信息。
2)采用迁移学习的思想分别提取图像的物体信息和场景信息,并设计了一个高层混合网络将这些信息与图像的美学信息进行有效的融合。
3)在不同数据集上的实验结果表明,本文方法相比现有方法在分类准确率等测度上有明显提高。
1 相关工作
早期的图像美学质量评估研究主要以摄影中的美学规则为先验知识,人为地设计提取图像的视觉特征。例如,Datta等[7]率先提取了包括亮度、色彩分布、三分构图、景深等在内的56种图像特征,并结合特征选择筛选了最有效的15种特征,利用这些特征对高美感和低美感图像进行分类;Ke等[8]提出了几种用简单性、对比度、亮度等表示图像的特征[9-11],从图像的布局、内容和照明等方面构建了一些高层次的可描述属性; 顾婷婷等[12]从图像主题和布局两方面出发,提出结合深浅景与构图的图像美学质量评估方法。
农村资金互助社的管理人员多数没有较高的金融知识水平,对专业知识的了解少之又少,不熟悉业务,操作失误时有发生。对于贷款过程来说,手续也较为简单,没有严格的规定制度,虽然满足了绝大部分农户的贷款需求,但给储户带来了更多的信贷危机,没有做到有效的监督和管理。
不同于上述工作从整幅图像中抽取特征的做法,一些研究者关注从图像局部区域中抽取有效的特征用于图像美学质量评估, 例如:文献[13]中提出利用模糊感检测技术估计图像的聚焦主体区域,从分离出的主体区域中提取特征,有效改善图像美学质量分类的效果;随后,该研究团队分析了专业摄影照片的相关特点,发现不同类别的图像对应不同的美学评价标准,因而提出将图像分为7个类别,针对每一类别的图像分别提取不同的区域特征[2,14]。国内研究方面,王伟凝等[15]通过显著区域检测将图像划分为整体区域和关键区域,在进行美学质量评估时抽取并融合图像的低层视觉特征、高层美学特征和区域特征。
为了提升特征的判别性和鲁棒性,基于中间语义特征的美学建模方法逐渐得到广泛关注, 例如,Dhar等[9]首先利用训练数据提取图像在布局、内容、光照方面的中间视觉属性(visual attribute),进而再利用这些属性实现对图像美学质量的判定;类似地,Marchesotti等[16]提出利用与图像相关的文本信息来挖掘有效的中间视觉属性;Zhang等[17]通过融合多种低层视觉特征构造图基元(graphlet)来描述图像的空间结构,采用高斯混合模型学习图基元的分布,并基于此实现图像美学质量评估。
近年来,深度学习在模式识别领域兴起,一些研究者开始尝试利用深层神经网络自动地抽取图像特征用于图像美学质量评估。例如,Lu等[18]采用CNN来分别抽取图像的局部特征和全局特征,并利用图像的风格和语义标签进一步提升图像美学质量评估的性能。国内研究方面,中国科学技术大学的田新梅研究组利用在大规模图像数据库上预训练得到的卷积神经网络模型来提取图像特征,并将其与人工设计的特征进行融合,用于高低美感图像分类,取得了较好的效果[19];Wang等[20]提出基于并行CNN的图像美感分类方法,从同一图像的不同视角出发,利用多个卷积神经网络自动完成特征学习。
总体而言,现有方法纯粹基于图像视觉内容提取美学特征,而忽略了对图像语义信息的理解; 与之相反,本文结合图像的物体类别信息以及场景类别信息,提出了一种基于语义感知的图像美学质量评估方法。
2 方法介绍
基于语义感知的图像美学质量评估方法的思想是通过构建一个由三层神经网络组成的混合网络,将图像的美学信息、物体类别信息以及场景类别信息进行融合后再对图像进行美学质量评估。它的输入是对每幅图像提取的3种特征:1)物体类别特征,2)场景类别特征,3)美学特征。3种特征的提取都基于卷积神经网络,并最终通过混合网络进行融合。
2.1 问题形式化
张量Xi表示一幅输入图像,yi表示该图像的美学类别标签,yi∈{0,1}。具体来说,当yi=1时,认为这是一幅高美感图像;当yi=0时,认为这是一幅低美感图像。
本文采用深度神经网络作为方法的主框架,将图像美学质量评估看作一个二分类问题,故网络的最后一层有2个神经节点,a=Φ(Xi;θ)表示它们的激活值,其中θ为模型参数,利用softmax函数将激活值转化为概率分布值:
(1)
本文采用监督学习的方法来确定权重θ。假定有一组训练样本D={(x1,y1),(x2,y2),…,(xN,yN)},其中N表示训练样本的个数。在训练过程中的目标是优化以下损失函数:
(2)
在网络训练过程中,使用随机梯度下降(Stochastic Gradient Descent, SGD)算法来求解上述优化问题,进而得到模型参数θ。
2.2 语义感知
本文认为在进行图像美学质量评估时,应该充分考虑图像的语义信息。为此,对于每一幅输入图像,分别提取其物体类别特征、场景类别特征以及美学特征。在此,本文使用ResNet50[21]卷积神经网络模型进行特征提取。它的网络结构如图2所示,首先是若干连续卷积层,紧接着为全局平均池化层,最后为全连接层,该网络已被证明在很多计算机视觉分类任务中都取得较好性能。接下来,将对每种特征的提取作简单介绍。

图2 ResNet50网络图像特征提取及分类示例图
对于每一幅图像,物体类别特征旨在提取其在图像美学评估中相关的物体信息。采用迁移学习的思想,利用由120万幅图像组成的并且具有1 000个物体类别的ImageNet数据集上预训练的ResNet50网络模型来抽取每幅输入图像的物体类别特征,并将该模型最后完全连接层的输出作为混合网络的输入,这样对于每一幅图像就得到了一个1 000维的物体类别特征。
对于每一幅图像,场景类别特征旨在提取其在图像美学评估中相关的场景信息。类似地,采用迁移学习的思想,利用由180万幅图像组成的并且具有365个场景类别的Place365数据集上预训练的ResNet50网络模型来抽取每幅图像的场景类别特征,并将该模型最后完全连接层的输出作为混合网络的输入,这样对于每一幅图像就得到了一个365维的物体类别特征。
对于每一幅图像,美学特征旨在提取其在图像美学评估中相关的美学信息。利用在ImageNet数据集上预训练的ResNet50模型架构,将其最后一层改为由2个神经节点组成的全连接层,在AVA数据集[22]上利用反向传播的方法将其训练为一个专门用来进行美学分类的网络模型,并在训练过程中更新其权重,这样就生成了一个专门用于美学分类的新的ResNet50网络模型,并将此模型倒数第二层的输出作为混合网络的输入,这样对于每一幅图像就得到了一个2 048维的美学特征。
2.3 混合网络
本文构建了一个混合网络,如图3所示。该网络包含2个隐藏层和1个输出层,它被设计用来融合以上提取的3种特征。首先,对3种输入特征作降维处理, 对于物体类别特征和美学特征,通过全连接的方式将其馈送到有128个神经节点的第一隐藏层;考虑到场景类别特征维度相对其他两者较低,故通过全连接的方式将其馈送到有64个神经节点的第一隐藏层;第一个隐藏层有助于保留每个特征的关键信息,并减少后续的计算负担。其次,对所有特征的第一隐藏层的输出由共同的全连接层进行融合,该层共包含128个神经节点。它可以被看作是一个共享嵌入式空间,将来自不同特征的信息组合为统一表示。最后,将第二个隐藏层的输出作为综合特征输入到具有2个神经节点的全连接层中,产生最终的预测美学分布。
2.4 实现细节
在构建混合网络时,使用Keras(https://github.com/fchollet/keras)的深度学习库实施网络培训和测试,使用Xavier[23]来初始化网络权重,即所有的偏差均被初始化为零。为了解决过度拟合问题,从每个图像或其水平翻转中随机抽取224×224的裁剪子图像,使其每个像素减去在训练集上计算的像素平均值来对其作处理。对于最小批量随机梯度下降(SGD)算法,将批量大小设置为16,所有层的初始学习率均为0.001,并且每当验证集的损失函数值在10个epoch内不再下降时,学习率就变为原先的0.1倍。使用10-6的学习率衰减因子和0.9的动量。当学习率下降到10-7时,训练阶段会提前停止。在测试时,对每个测试图像中的10个224×224裁剪子图像进行预测,并将所得平均值作为最终预测结果。
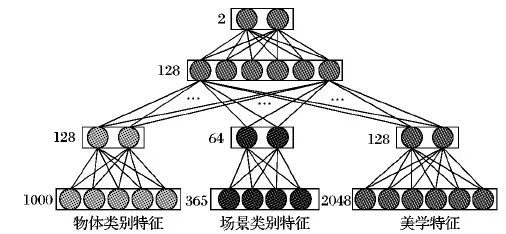
图3 基于语义感知的混合网络
3 实验与分析
3.1 数据集
本文对图像美学评估的实验是在两个基准数据集上进行的,即AVA[22]和CUHKPQ[2]。AVA数据集包含大约255 530幅图像,每幅图像平均得到210个美学评分,评分范围从1分到10分。按照与之前研究相同的程序[5-6, 22,24]为每幅图像分配一个二值美学标签。具体来说,平均评分小于5-δ的图像被标记为低美感图像,平均评分大于5+δ的图像被标记为高美感图像,其他被认为是高低美感分类不明确的,并将其丢弃。在本文的实验中,取δ=1,随机选取70%的图像进行训练,10%用于验证,剩下的用于测试。
CUHKPQ数据集由17 690幅图像组成,分为7类,即动物、建筑、人类、风景、夜晚、植物和静物。在CUHKPQ数据集上,每个图像已被10个不同观众中的至少8个标记为高美感或低美感两种标签。为了验证不同方法的泛化能力,按照文献[25]的建议进行了交叉评估。换言之,在AVA数据集上训练了一个模型,但同时在AVA和CUHKPQ数据集上进行了测试,即CUHKPQ数据集仅用于测试。
3.2 评价指标
本文采用分类准确率来评价本文方法在图像美学质量评估中的表现, 通过将阈值设为0.5的二值化的输出结果与图像的ground-truth二值美学标签相比较来获得分类准确率; 此外,由于正例和负例测试图像之间的不平衡,绘制了刻画分类性能的接受者操作特征(Receiver Operating Characteristic, ROC)曲线。为了定量比较不同的方法,本文还计算了ROC曲线下的面积(Area Under Curve, AUC)。
3.3 方法对比
在此比较了本文方法SAAN(Semantic-sensed image Aesthetics Assessment Network)与几种最先进的图像美学质量评估方法。具体而言,对比方法包含以下几种:
Customized[8]该方法从简单性、对比度、亮度等角度采用7种特征来对图像进行美学质量评估。
Generic[3]该方法利用通用视觉描述符(包括视觉词和Fisher矢量)来预测图像的美学类别。
Efficiency[26]该方法使用了几种可以高效计算的手工美学特征。
DMA-Net[24]该方法利用从一个图像中提取的多个补丁提出了一个深度多方面汇集网络。
3.4 AVA数据集实验结果与对比
图4绘制了AVA上不同方法的ROC曲线,表1列出了不同方法的分类准确率和AUC方面的表现, 可以看出,SAAN在不同指标上优于其他方法, 例如,它在分类准确率和AUC方面的平均改善分别为5.6%和19.9%。此外,传统的提取图像特征的方法,如Customized、Generic和Efficiency,大大落后于基于深度模型的方法DMA-Net和SAAN。分析结果表明深度学习方法在图像美学质量评估任务中的潜力, 在基于深度模型的方法中,SAAN比以上最好方法DMA-Net在分类准确率提升了2.5个百分点。一个可能的原因是SAAN从语义感知的角度出发对图像进行美学质量评估,这在图像美学质量评估过程中起着至关重要的作用。

图4 AVA上不同方法的ROC曲线
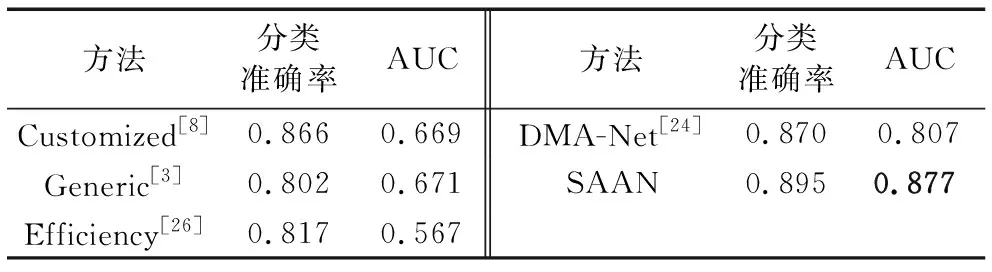
方法分类准确率AUC方法分类准确率AUCCustomized[8]0.8660.669DMA-Net[24]0.8700.807Generic[3]0.8020.671SAAN0.8950.877Efficiency[26]0.8170.567
3.5 CUHKPQ数据集实验结果与对比
CUHKPQ的比较结果分别显示在图5和表2中。正如预期的那样,SAAN仍然取得最佳表现。值得注意的是,所有方法都是在AVA上进行训练,在CUHKPQ上进行测试。在这种情况下,其他方法的分类准确率急剧下降,而SAAN保持相对稳定的表现。更确切地说,SAAN在CUHKPQ的分类准确率上最小提升为19个百分点。结果表明本文提出的图像美学评估方法具有优越的泛化能力。对于表2中Customized和Generic方法性能较差的原因,简要分析如下:首先,Customized和Generic是传统的分类方法,并不是深度学习的方法;其次,在CUHKPQ数据集上验证的是模型的泛化能力,由于模型是在AVA数据上训练得到的,故其在CUHKPQ数据集上性能表现较其在AVA数据集上差些。
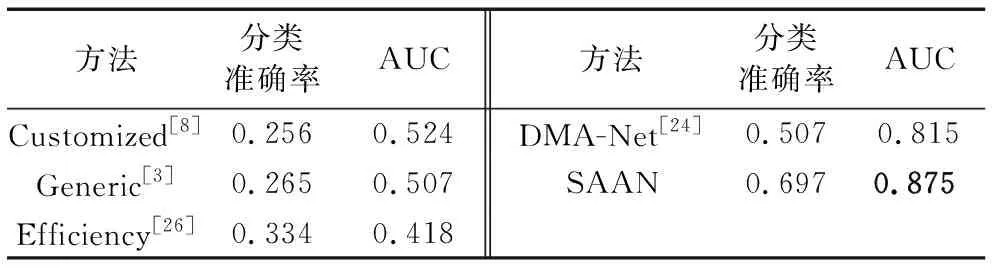
方法分类准确率AUC方法分类准确率AUCCustomized[8]0.2560.524DMA-Net[24]0.5070.815Generic[3]0.2650.507SAAN0.6970.875Efficiency[26]0.3340.418
4 结语
图像美学质量评估在图像处理和计算机视觉领域一直是一个长期存在的问题。本文提出了基于语义感知的图像美学质量评估方法,从一个新的视角对该问题进行了研究。实验证明,基于语义感知的图像美学质量评估方法相较于现有的仅仅基于图像的视觉信息的美学评估方法在分类准确率上有了很大提升。未来,在对图像进行美学评估时,也应考虑人类认知和行为的相互影响,可以从他们的社交行为中感知用户对图像的认知,进一步更好地完成图像美学评估这项工作。此外,未来研究也可以从实现个性化图像美学评估方面着手,针对具有不同审美偏好的用户对同一图像进行不同评估。对于这个问题,如何理解个人用户的审美偏好是一项艰巨的挑战。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
陶瓷学报(2021年4期)2021-10-14
少儿画王(3-6岁)(2020年4期)2020-09-13
VOGUE服饰与美容(2019年10期)2019-12-02
活力(2019年21期)2019-04-01
家庭影院技术(2018年5期)2018-06-29
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
散文百家(2014年11期)2014-08-21
