
调整聚类假设联合成对约束半监督分类方法
2018-12-14 05:31郑佳敏钱鹏江
计算机应用 2018年11期
黄 华,郑佳敏,钱鹏江
(江南大学 数字媒体学院,江苏 无锡 214122)(*通信作者电子邮箱qianpjiang@126.com)
0 引言
近些年来,随着互联网的快速发展,在网页推荐、商品个性化推荐、垃圾邮件识别等日常生活应用中存在着大量的无标记样本,而少量标记样本往往需要通过成本较高的手工标记等方式获取。如何通过利用少量标记样本和大量未标记样本来训练模型的半监督方法,便成为众多学者共同努力研究的问题[1-4]。
在半监督应用的热潮下,学者们提出了许多半监督分类方法[5-8], 然而有研究表明,某些情况下半监督方法可能产生比与之对立的监督方法更差的效果[9-10], 这主要是由于以下两类原因造成的:
1)使用了从不可靠的未标记样本中挖掘出的数据分布信息,其错误地指导了分类边界的形成;
2)采用的数据分布假设可能本身就不符合数据的真实分布情况。
本文希望提出一种半监督分类方法解决上述问题,使其性能不会明显差于仅利用少量有标记样本的监督分类方法。
Li等[11]和Wang等[12-13]为解决这方面所存在的问题作出了相应的贡献。基于某些未标记样本提供的分布信息可能存在错误甚至误导分类面生成的猜想,Li等[11]提出了us型半监督支持向量机(Semi-Supervised Support Vector Machine us,S3VM-us)方法,通过层次聚类的方式从未标记样本中选取置信度较高的样本来挖掘数据分布信息,从而避免了不可靠的未标记样本对模型的错误指导;此外,还猜想半监督支持向量机(Semi-Supervised Support Vector Machine, S3VM)对一个数据集可能存在多个低密度划分面,在领域知识不够充分时,算法可能会选取一个错误的低密度划分面,因此导致了性能的严重下降。针对此猜想,Li等提出了安全半监督支持向量机(Safe Semi-Supervised Support Vector Machine, S4VM)方法[11],该方法会构造多个候选低密度划分面,然后在最坏情况下选取最优的划分面以最大化性能提升。Wang等[12]提出的基于类隶属度的半监督分类方法(Semi-Supervised Classification method based on Class Memberships, SSCCM)和调整聚类假设半监督分类方法(Semi-Supervised Support Vector Machine by Adjusting Cluster Assumption, ACA-S3VM)[13],可以有效缓解当不同类别的样本严重重叠在真实分类边界时,基于聚类假设的算法将会错误地引导模型生成的分类边界通过低密度区域的不安全学习情形(此类情况下真实分类边界不在低密度区域)。前者通过引入类似模糊隶属度的方式,提升了算法对边界交叉数据的划分能力;后者通过将每个未标记样本到类簇边界的距离融入到模型的学习中,使得在类簇边界的样本也会被划分到分类边界,模型便会指导分类边界通过类簇边界(真实分类边界)而不是低密度区域。
值得注意的是,Li等[11]和Wang等[12-13]提出的安全半监督分类方法旨在对未标记样本的深耕利用,而忽略了对标记样本所蕴含的监督信息的利用。鉴于此,本文以ACA-S3VM为基础分类器,将成对约束信息与之结合,提出了调整聚类假设联合成对约束半监督分类方法(Adjusted Cluster Assumption and Pairwise Constraints Jointly based Semi-Supervised Classification Method, ACA-JPC-S3VM),它不仅能够有效利用标记样本知识(监督信息),而且能够合理运用未标记样本所蕴含的内在信息,具有以下优点:
1)充分利用了标记样本所蕴含的监督信息;
2)继承了调整聚类假设所具备的优势,能够对边界重叠样本有效划分。
1 相关工作
1.1 调整聚类假设
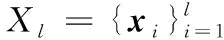
(1)

观察优化问题能够发现,当Vj接近于0时,未标记样本xj就很可能位于类簇边界附近,那么根据式(1), 它的预测值f(xj)就被限制到接近0,于是样本xj将会被划分到分类边界附近的区域;相反的,当Vj较大时,未标记样本xj就会离类簇边界较远,那么根据式(1),样本xj将会被划分到分类边界较远的区域。
ACA-S3VM方法对未标记样本同时寻找决策函数和分类标记。在问题求解方面,可以通过交替迭代策略分别得到决策函数和预测类标,且迭代过程中的每一步都会产生一个闭合解。
1.2 成对约束
本文方法对标记样本的利用是将数据标签转换而来的成对约束项融入算法的损失函数。成对约束[14-17]是一种常见的监督类型信息,它通过将样本的类标签转化为成对约束项来提升模型对标记样本所蕴含信息的利用。一般而言,在训练半监督分类模型时,对于每个标记样本,会给出相应的类标记; 而在一些现实应用中,可能只获得了部分样本类标签的关系,这时就可以将这些类标签关系转化为成对约束信息,将其视为标记样本信息进行半监督模型的训练。
具体而言,如果两个标记样本的类标记相同,则它们是一对必须关联约束,这样的约束对组成了必须关联集MS;相应的,如果两个标记样本的类标记不同,则它们是一对不可能关联约束,这样的约束对组成了不可能关联集CS。假设分类决策函数为f(x),那么对所有样本的预测值可以表示为f=[f1,f2,…,fn]T∈R1×n,于是成对约束可以表示为以下形式:
(2)
其中:i、j、p、q∈[1,n]是样本集里的样本序号;〈i,j〉表示MS集合中的任意一对必须关联约束,同样的,〈p,q〉表示CS集合中的任意一对不可能关联约束;|·|表示MS集合或CS集合中成对约束的数目。

定义1 定义矩阵Qn×n元素如下:
(3)
于是可以得到式(2)的矩阵表示如下:
(4)
U=H-Q
(5)
H=diag(QL)
(6)
式(6)中L是n×1向量且元素全为1。
2 调整聚类假设联合成对约束方法
文献[13]方法主要研究以聚类假设为基础的半监督分类方法,如何避免当不同类别样本重叠在类簇边界时可能形成的不安全学习情形。虽然其通过引入调整聚类假设,有效缓解了这些样本对模型的错误指导,但值得注意的是,该算法没有对标记样本所蕴含的监督信息进行更深一步的挖掘。本文关注于对标记样本的有效利用,将成对约束监督信息与之结合,提出了ACA-JPC-S3VM。
2.1 模型描述
前文介绍了调整聚类假设框架以及成对约束项对监督信息的挖掘利用。现本文将两者结合,提出了ACA-JPC-S3VM方法,该方法不仅能够有效利用标记样本所蕴含的监督信息,而且能够合理挖掘出未标记样本的内在信息,提高算法的性能。
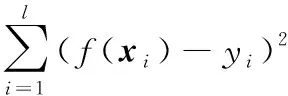
(7)
将式(7)与调整聚类假设框架相结合,即可得到ACA-JPC-S3VM的优化问题:
(8)
其中:第一项主要控制着分类器的复杂性;第二项是对标记样本的利用,由平方损失项和成对约束正则化项共同组成,而参数τ控制着它们之间的平衡,值得注意的是,当参数τ=1 时,算法即退化为ACA-S3VM;第三项是调整聚类假设对未标记样本的探索,用来挖掘数据的内在信息;C1、C2作为正则化参数分别控制着对应正则化项的复杂性。
2.2 问题求解
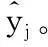
(9)
基于表示定理[18],对式(9)的最小化具有以下形式:
那么,可以得到式(9)的矩阵表示形式:

(10)

由拉格朗日乘子法,将J对α的偏导数取0,解得:
α=(K+C1(τKlTKl+ (1-τ)KUK)+
(11)
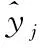
(12)
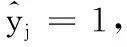
2.3 算法步骤
在本文算法的求解方面,初始化的Yu是由支持向量机(Support Vector Machine, SVM)得到的;迭代终止条件是|Mk-Mk-1|<ε或k>Maxiter,其中Mk表示第k次迭代的目标函数值,ε是一个预设的终止阈值,Maxiter是最大迭代次数。ACA-JPC-S3VM的算法步骤如下所示:
输入:标记样本与未标记样本Xl、Xu,标记样本的类标Yl,正则化参数C1、C2、τ,迭代终止阈值ε,最大迭代次数Maxiter。
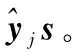
1)通过FCM获得初始聚类中心,然后计算向量V。
2)设置初始化的目标函数值M0=INF。
3)通过式(11)更新α,然后根据表示定理以α更新f(x)。
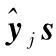
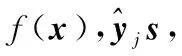
推论1 ACA-JPC-S3VM使用交替迭代策略得到的序列{J(αk,yk)}是收敛的。
证明 首先证明目标函数是单调递减的。由文献[19]可知,目标函数J(α,y)是关于(α,y)双凸的,那么当yk被固定时,目标函数关于α就是凸的,因此可以通过最小化{J(α,yk)}得到最优的α*,即最优化式(9)。由交替迭代策略可得αk+1=α*,于是J(αk+1,yk)=J(α*,yk)≤J(αk,yk);同理,此时固定αk+1,目标函数关于y就是凸的,因此可以通过最小化{J(αk+1,y)}得到最优的y*,即最优化式(12)。由交替迭代策略可得yk+1=y*,于是J(αk+1,yk+1)=J(αk+1,y*)≤J(αk+1,yk),∀k∈N。因此,序列{J(αk,yk)}是单调递减的。又因为目标函数J(α,y)是非负且有下界的,所以序列{J(αk,yk)}是收敛的。
3 实验与结果分析
为了验证本文算法的有效性,本文将其与监督分类方法SVM、半监督分类方法TSVM、Laplacian SVM[7]、Laplacian RLSC(Laplacian Regularized Least Squares Classification)[7]、meanS3VM-iter[6]、meanS3VM-mkl[6]以及ACA-S3VM在UCI数据集以及图像分类数据集[20-21]上进行性能比较。最后,还进行了时间复杂度分析以及参数鲁棒性分析的实验。
特别需要说明的是,对于每个原始数据集,本文都将其随机划分为训练集和测试集。在训练集上,会随机选取部分数量的样本作为标记样本,其余的作为未标记样本参与模型的训练,这样的预处理操作将会被重复10次,最终以模型在测试集上的平均准确率和方差作为实验指标评估每个算法的性
能。此外,所有算法的高斯核参数均设置为样本数据的平均距离。本文算法在优化求解中,最大迭代次数M=200,收敛阈值ε=10-3。
3.1 UCI数据集实验结果与分析
本文在UCI数据集上做了大量实验,其数据集的详细构成见表1。为了体现出标记样本数量对半监督分类算法性能的影响,本文特地在训练集上分别随机选取了10、20、30、40、50个标记样本来训练模型,最终得出不同标记样本数量对算法性能影响的趋势图。此外,表2和表3分别给出了标记样本为10和50时,8种算法的实验结果。

表1 UCI数据集结构

表2 10个标记样本点上8种算法分类结果 %
注:括号中的数字代表该算法在当前数据集上的性能排名;
本文算法右上角的W/T分别表示在ttest测试中与ACA-S3VM算法相比更好/持平。
观察表2与表3,可以发现:
首先,当标记样本数量为10时,ACA-S3VM在3个数据集上的效果都要比经典半监督分类方法TSVM的效果差,而ACA-JPC-S3VM有2个; 当标记样本数量为50时,ACA-S3VM仍旧有在3个数据集上的性能比SVM或TSVM更差,而ACA-JPC-S3VM在所有8个数据集上的性能都优于监督分类方法。更进一步还发现,无论标记样本数量是10还是50,ACA-S3VM在breast和wdbc数据集上的表现都比TSVM差,而ACA-JPC-S3VM在标记样本数量为50时,性能已经反超了TSVM。这体现了ACA-JPC-S3VM不仅继承了ACA-S3VM在安全半监督分类方面的优势,而且在融入了标记样本的知识后,成为了一种更加安全的半监督分类方法。
其次,当标记样本数量为10时,ACA-JPC-S3VM算法在6个数据集上获得了最优性能,仅在其余两个数据集上的性能稍弱于TSVM。而当标记样本数量为50时,ACA-JPC-S3VM在所有8个数据集上的性能都取得了最优,且在8个数据集上的平均准确率远高于其余对比算法。这表明,ACA-JPC-S3VM在保持对边界重叠样本正确分类的同时,随着标记样本的增加,还能对监督信息进行更深一步的挖掘利用,从而在两方面对知识进行极大化利用,最终提升了算法的性能。
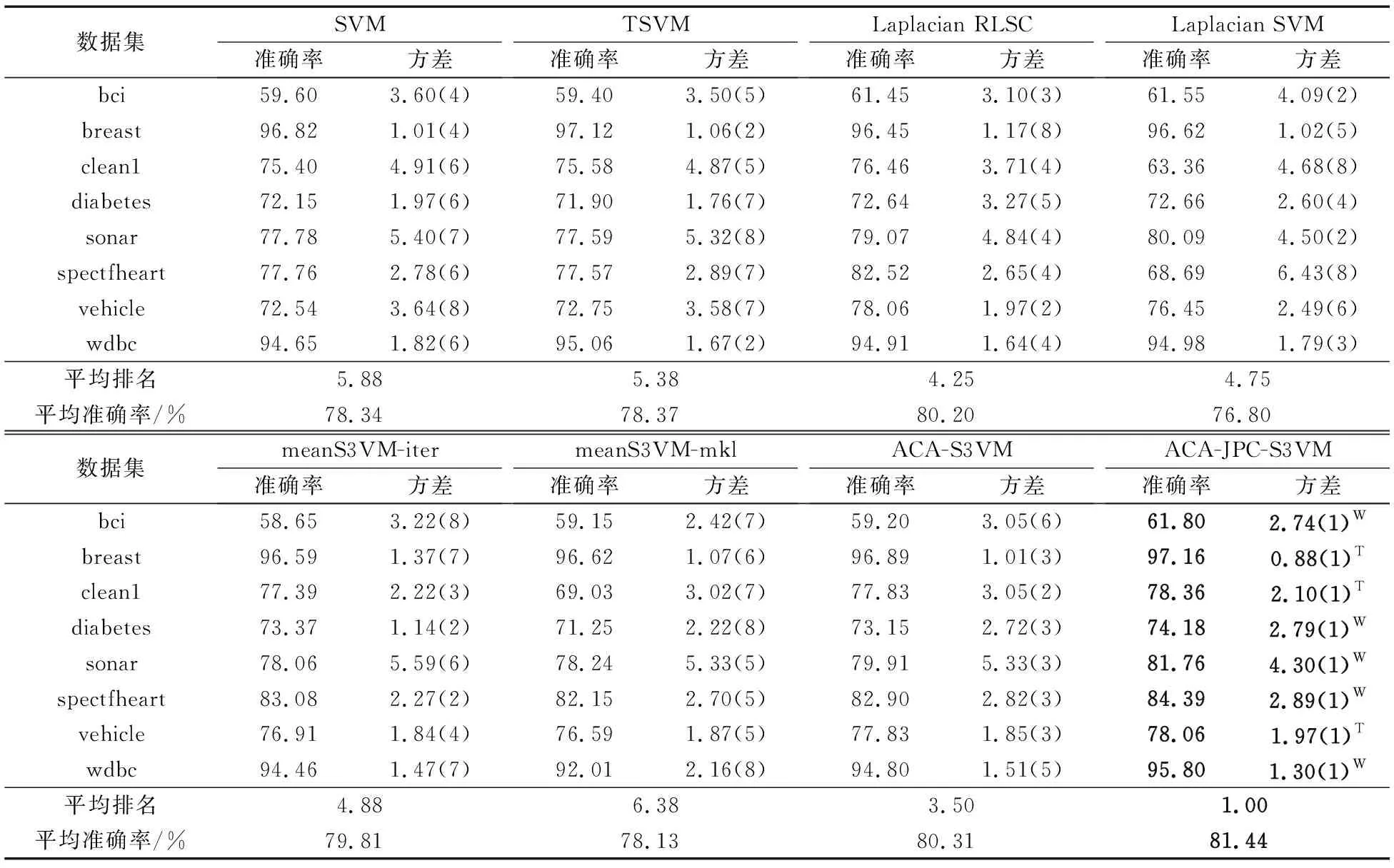
表3 50个标记样本点上8种算法分类结果 %
最后,不难发现在所有8个数据集上,无论标记样本的数量是10还是50,基于ACA-S3VM进行改进的ACA-JPC-S3VM的平均准确率都是优于ACA-S3VM的,这意味着算法的改进是有效、可行的。但就平均准确率这个性能指标而言,有时ACA-JPC-S3VM相较于ACA-S3VM的提升甚微,这只表明了算法在整体上更加稳定。为了更进一步体现算法在改进后的性能优势,本文对这两个算法进行了ttest检验。在标记样本数量为10时,ACA-JPC-S3VM在4个数据集上的性能是优于ACA-S3VM的,在其余4个数据集上持平;在标记样本数量为50时,ACA-JPC-S3VM在5个数据集上的性能是优于ACA-S3VM的,在其余3个数据集上持平,且在两种标记量的情况下,ACA-JPC-S3VM都没有出现改进后性能下降的情况。
观察图1,可以得到如下结论:
就图1(a)中的clean1数据集而言,可以看出当标记样本数量大于10后,Laplacian SVM和meanS3VM-mkl这两种半监督分类方法的性能会弱于SVM以及TSVM,而其他几种算法则不会。这可能是由于随着标记样本的增加,未标记样本的数量在减少,能够选取的可靠性高的未标记样本的数量就减少了,亦或是算法选取了不可靠的未标记样本参与了模型的训练,形成了不安全的半监督学习。ACA-JPC-S3VM在保持始终合理利用未标记样本的同时,通过有效挖掘标记样本信息,使其保持了较高的分类性能,这再次证明了ACA-JPC-S3VM是一种更加有效的安全半监督分类方法。
就图1(b)中的spectfheart数据集而言,Laplacian SVM的性能与其他几种对比算法相差较大。这可能是由于Laplacian SVM方法假设数据分布在由拉普拉斯图表示的低维流形上,根据图的结构来生成模型,而这样的流形假设可能本身就不符合这个数据集的真实数据分布,再次导致了其不安全的半监督学习。
就图1(c)中的vehicle数据集而言,所有半监督分类方法的性能都优于监督分类方法SVM,而且它们的性能都很接近,ACA-JPC-S3VM的性能也没有与其他算法拉开明显的差距。这可能是因为在这个数据集上,未标记样本已经能够很好地反映出数据的真实分布情况,且这些方法都能合理地利用这些数据的内在信息,使得模型都能够正确预测未见样本。虽然不同于其他几种半监督分类方法,ACA-JPC-S3VM高效利用了标记样本所蕴含的监督信息,但由于半监督分类方法的核心在于对未标记样本的内在信息进行合理的利用,而在对监督信息的利用效果方面相对而言没有对无监督信息的利用效果大,所以ACA-JPC-S3VM的效果只是稍好于其他几种半监督分类方法。
就图1(d)中的wdbc数据集而言,在标记样本数量为10时,包括ACA-JPC-S3VM在内的几种半监督分类方法的性能都比监督分类方法差,而当标记样本大于10时,除了ACA-JPC-S3VM以外,其余半监督分类方法的性能仍旧没有超过监督分类方法。虽然,ACA-S3VM能够通过调整聚类来缓解不安全的半监督分类学习,使得它的性能好于除了ACA-JPC-S3VM以外的半监督分类方法,但它依然没能超过TSVM或SVM。而随着标记样本的增加,结合对标记样本进行利用的ACA-JPC-S3VM在性能上超越了监督分类方法,这不仅证明了对监督信息的合理利用可以有效提升半监督分类方法的性能,同时也验证了ACA-JPC-S3VM的安全性与正确性。此外,图(e)、图(g)以及图(h)中,ACA-JPC-S3VM都具有很好的性能;在图(f)中,仍可以观察到一些半监督分类方法出现了不安全的学习,而ACA-JPC-S3VM的性能依然呈现出稳步提升的趋势。

图1 不同数据集上8种算法分类性能比较
3.2 图像分类实验结果与分析
本文图像分类数据集[20-21]包括沙漠、山、海洋、日落、树木共5类2 000张自然景观的图像,其结构见表4。
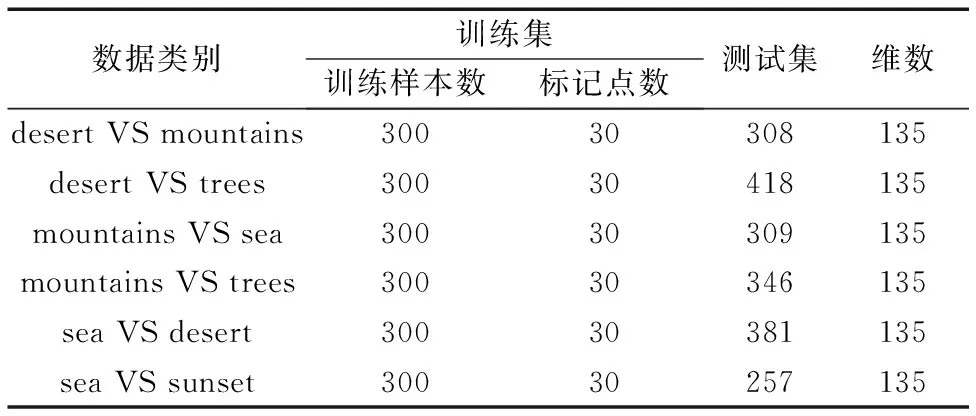
表4 图像分类数据集结构
观察表5,可以得到如下结论:
ACA-JPC-S3VM在4个图像分类数据集上取得了最优性能,而Laplacian SVM和meanS3VM-iter分别在desert VS mountains和mountains VS trees数据集上取得了第一。另外,在desert VS trees、sea VS desert以及sea VS sunset数据集上,一些半监督分类方法出现了不安全的学习情况,其中ACA-S3VM较为严重,在这三个数据集上的表现都不好,而基于它改进的ACA-JPC-S3VM则表现出了很强的竞争力,且在与ACA-S3VM的ttest测试中取得了优秀的表现,这再次强有力地证明了ACA-JPC-S3VM改进的合理性与有效性。
值得注意的是,ACA-S3VM在图像分类实验中的整体表现不是很好,尽管ACA-S3VM在针对聚类假设中的不同类别样本严重重叠在分类边界时的情况进行了专门的优化,但可能由于这些数据的分布本身不符合聚类假设,致使算法不能获得较好的效果。而基于ACA-S3VM进行改进的ACA-JPC-S3VM却获得了较好的结果,归根结底可以归结为其对标记样本所蕴含的监督信息的有效挖掘与利用,不仅填补了ACA-S3VM在对标记样本利用方面的空缺,而且弥补了这种情况下半监督学习基本假设带来的负面影响,最终合理有效地利用了标记样本与未标记样本的知识,形成了一种更加安全有效的半监督分类方法。
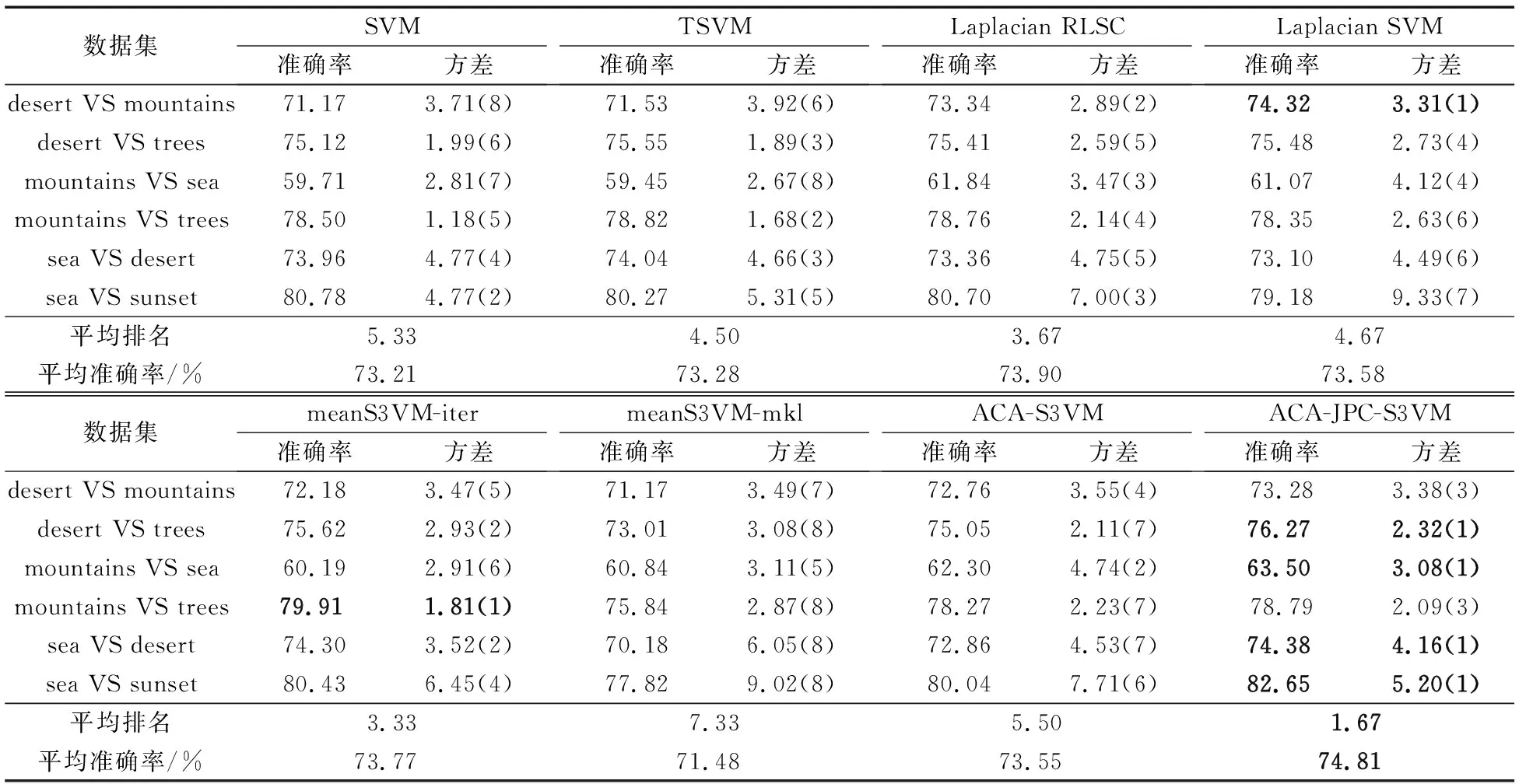
表5 图像分类数据集结果 %
3.3 时间复杂度结果与分析
为了讨论实际应用中的情况,本文在图像分类数据集上对比了ACA-JPC-S3VM与ACA-S3VM模型训练平均用时, 其结果见图2。
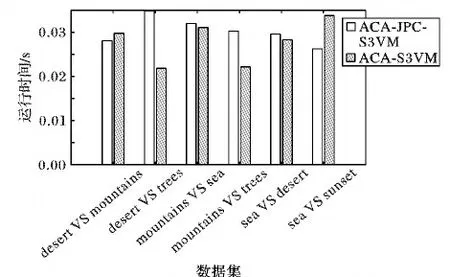
图2 模型平均训练用时的比较
从图2中容易看出,本文算法经过对ACA-S3VM的改进后,其训练时长在大部分情况下相对较长,其主要原因是由于成对约束正则化项的加入,使得优化问题的求解中需要调整对应参数对模型的作用,一定程度上影响了算法的收敛速度。
3.4 参数鲁棒性分析
为了体现成对约束正则化参数τ的作用,本文仍旧以图像分类数据集为例,对参数τ进行了鲁棒性分析实验。参数C1、C2的值固定为每个数据集上的最优模型所对应的值,实验结果见图3。
观察图3可以发现:
1)参数τ对算法准确率的影响很明显, 这体现出其对算法模型的重要性。
2)在sea VS sunset数据集上,当τ=0.95时,算法的预测准确率达到了0.87,相较于其他值有了较大的提升。这表明,若对τ进行精心调校,可以得到令人满意的效果。
3)成对约束信息的加入,可以提升算法的正确率,弥补了算法对监督信息利用方面的缺失。
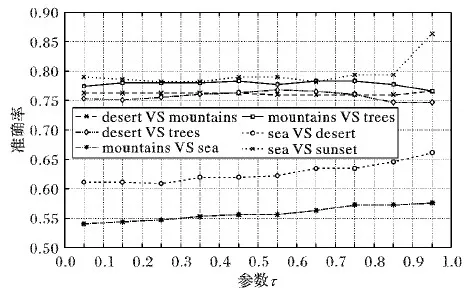
图3 参数τ对准确率的影响
4 结语
本文针对不安全的半监督分类问题,通过有效利用标记样本所蕴含的监督信息与合理运用未标记样本的分布信息,提出了ACA-JPC-S3VM方法。该方法不仅继承了ACA-S3VM缓解不同样本严重重叠在分类边界时可能造成的不安全学习情形的能力,而且在将成对约束信息融入模型之后,能够一定程度上弥补不安全学习对分类器造成的性能损失。在UCI数据集上的实验,表明了本文方法对标记样本所蕴含的监督信息的有效利用,算法性能随着标记样本的增加而逐步上升;在图像分类数据集上的实验,表明了本文方法在不安全的学习情形下,通过对监督信息的运用,一定程度上弥补了算法性能的损失, 最终验证了本文方法的安全性与有效性。
由于加入了成对约束正则化项,需要调整对应参数对模型的作用占比,使得模型的训练时长相对于改进前的ACA-S3VM方法而言更高,如何通过一些启发式的方法来解决此问题将会是以后研究工作的重点。
猜你喜欢
计算机研究与发展(2022年1期)2022-01-19
中学生数理化·高一版(2021年2期)2021-03-19
计算机应用(2020年12期)2020-12-31
现代计算机(2018年27期)2018-10-25
领导决策信息(2018年16期)2018-09-27
舰船电子对抗(2017年6期)2018-01-11
数学学习与研究(2017年3期)2017-03-09
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
文苑(2015年9期)2015-09-10
