
非对称方向性局部二值模式人脸表情识别
2018-12-04 02:14黄丽雯杨欢欢
计算机工程与应用 2018年23期
黄丽雯,杨欢欢,王 勃
重庆理工大学 电气与电子工程学院,重庆 400054
1 引言
人脸表情识别是对人脸的表情信息进行特征提取和分析,按照人的认识和思维方式加以归类和理解,利用人类所具有的情感信息方面的先验知识使计算机进行联想、思考及推理,进而从人脸信息中去分析、理解人的情绪的技术[1]。人脸所反映的视觉信息是人类情感表达和交流最直接最重要的载体,表情作为形体语言,是最自然表现情感的形式,在人际交往中,可以通过对方面部表情的变化,精确地揣测出其所处的情感状态,及时给予恰当的回应,因此表情识别的研究,不仅是实现使计算机理解并表达人类的情感,且是人工智能、计算机图形学、心理学、计算机视觉、人机交互、生理学等多个学科领域研究的基础,已逐渐成为当前学者们研究的热点。
表情识别的流程大同小异,一般包括人脸检测、预处理、特征提取、特征融合、分类识别这5个步骤,其中特征提取是表情识别的核心所在,目前常用的算法有:基于Gabor小波变换[1]、尺度不变特征变换(SIFT)[2-3]、梯度直方图变换(HOG)[4-5]、局部二值模式变换(LBP)[6]、融合全局与局部特征[7]、多特征融合[8-10],其中Gabor小波变换提取的是多尺度多方向的特征信息,整个过程比较耗时,不适合实时应用;SIFT算法虽对尺度缩放、图像旋转甚至仿射变换保持不变性,但其过程复杂且运算速度比较慢;HOG特征虽能有效地检测图像的边缘信息,但它却忽略了局部特征之间的空间排列信息;而LBP由于其具有灰度不变性,旋转不变性,且具有强大的抗干扰性和纹理判别能力,另外计算简单,对光照有一定的抑制作用,故近年来已被广泛应用于纹理分类、图像检索和人脸图像分析等领域,并且在模式识别领域越来越受欢迎[11]。
传统LBP算子虽有诸多的优点,但也存在缺点:对噪声、灰度变化比较敏感,只是通过比较中心像素与邻域像素的差值获取特征,这样会丢失部分信息,识别效果不理想。为此Tong等人提出了方向性的局部二值模式(DLBP)[12],分别从水平、垂直和对角3个方向对邻域像素进行灰度值比较和二值编码,这样不仅可以提取到比较全面的特征信息,也降低了噪声的干扰,但它并没考虑到局部器官对表情识别的影响,针对这一不足,本文提出了异或-非对称方向性局部二值模式(XOR-ARDLBP)表情识别算法,首先,对人脸表情图像进行预处理。通过人脸检测算法确定出人脸的位置,分割出人脸及表情关键区域(眉、眼、嘴),后进行尺寸归一化操作,再对其进行去噪处理,消除噪声的影响;其次,把预处理后的图像经XOR-AR-DLBP特征提取算法获取整张表情图像和局部(眉、眼、嘴)表情图像的直方图信息;然后用信息熵来计算局部表情图像的贡献度,获得权值分配,对其进行加权并与整张图像特征信息融合;最后用SVM分类器进行分类识别。由于此算法在预处理阶段对噪声进行了处理,并较好地融合了整体和局部特征,结果表明此算法不仅实时性好且识别效果也比较理想。
2 预处理
为了更好地提取整体与局部特征,预处理是一个非常必要的过程,它直接影响最终识别效果的好坏。针对光照变化严重影响人脸图像识别的问题,本文在预处理阶段进行了光照补偿[13]。这里图像尺寸大小统一为64×64,又由于眉、眼、唇对表情识别的贡献比较大[14],故分割出来作为局部特征,眉毛和眼睛、嘴巴尺寸大小分别为64×12,64×30,其预处理过程如图1所示。
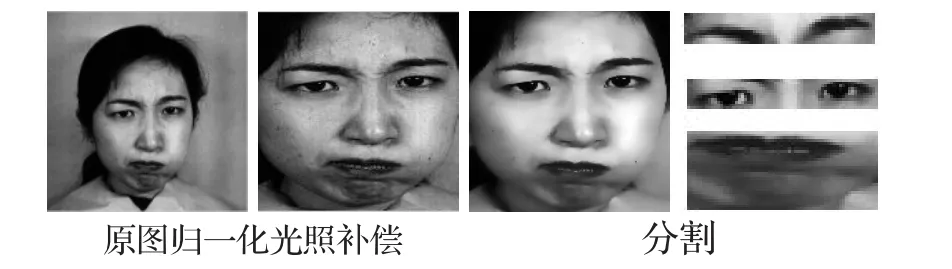
图1 预处理过程
3 XOR-AR-DLBP特征提取
3.1 基于方向性的局部二值模式(DLBP)
局部二值模式(LBP)是一种能有效提取图像局部纹理特征的描述子,它通过比较邻近像素gi与中心像素gc的灰度值大小关系来进行编码。原始LBP算子规定图像中每个像素是以其为中心,值为阈值,3×3大小的窗口范围内,计算邻域像素与中心像素的二值关系,若gi>gc,则为1,反之为0。从左上角开始顺时针依次计算出相邻的8个二进制数,得到LBP编码,再把它们换算成十进制数,得到LBP值。其LBP编码示意图如图2所示。

图2 LBP编码示意图
上面原始LBP特征的计算过程只是针对中心像素与邻域像素进行了比较,并没考虑到邻域像素之间的灰度关系,因此就不能对非局部信息进行提取。针对这个问题,Tong等人[12]提出了基于方向性的局部二值模式(DLBP),分别从水平、垂直、对角3个方向上计算局部像素之间的关系,既简单有效,又能准确地表达图像中各个表情区域的变化情况,这里窗口范围设为3×3,其DLBP编码示意图如图3所示。

图3 DLBP编码示意图
可见,对相同的像素灰度分布,采用不同的编码算子所得的结果也是不同的。
若用数学公式表达DLBP,其算式如下:

式中的s函数为:

式中的g0~g7为图4中3×3大小邻域对应像素的灰度值,其示意图如图4所示。

图4 DLBP 3×3大小邻域模板的灰度值示意图
以JAFFE数据库中的任一表情图像为例,分别用LBP编码和DLBP编码的结果如图5所示。

图5 LBP与DLBP编码图像
从图5可知,由于DLBP考虑到了邻域像素之间的强度关系,故编码处理后的图像面部肌肉的褶皱形变以及眼睛、嘴巴等关键部位的变化情况相比LBP要清晰得多,这就更有利于最终表情的识别。
3.2 异或-非对称方向性局部二值模式(XORAR-DLBP)
3.2.1 非对称方向性局部二值模式(AR-DLBP)
DLBP编码虽考虑到了邻域像素间的强度关系,可以很好地提取图像的纹理特征,但所提算法的模板大小都是3×3的,并不能在高尺度下获取有效的纹理特征,为此Naika等人[15]提出非对称局部二值模式(AR-LBP),解决了原始LBP算子不能用于高尺度纹理分析的问题。Cheng等人[16]提出非对称局部梯度编码(ARLGC),解决了LGC不能在大尺度下提取图像纹理特征的不足,并融合了不同尺度不同梯度邻域间的强度关系。本文在文献[15-16]的启发下提出了非对称方向性局部二值模式(AR-DLBP)。3×3大小,Ri表示每个子邻域,其结果表示如图6所示。
这9个子邻域中,有4个大小为 a×b:R0,R2,R4,R6,2个大小为 b×1:R1,R5,2个大小为 a×1:R3,R7,其中一个中心大小为1×1,为 Rc。

图6 AR-DLBP的3×3邻域灰度值示意图
这里用每个子邻域内所有像素值的和除以该邻域内所含像素的个数,所得的结果作为该邻域的像素值,记为:gRi,数学表达式为:

其中,Ni为第i个子邻域所含像素的总个数,Pij为第i个子邻域第j个像素的值。处理后的示意图如图7所示。
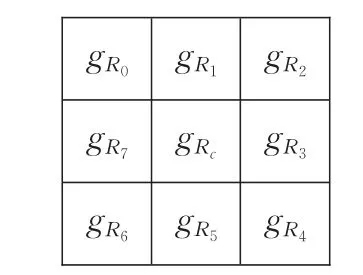
图7 处理后的AR-DLBP 3×3邻域灰度值示意图
编码公式如下,这里的s同式(2):

AR-DLBP算法的模板大小不再是3×3固定不变的,并且可以在高尺度下获取有效的纹理特征,由上面的编码过程可知所得的结果依旧是一个8位的二进制数,并没随邻域大小的变化而变化,故所得特征值的维数是不变的。
3.2.2 异或-非对称方向性局部二值模式(XOR-ARDLBP)
虽然改进后的AR-DLBP可以在高尺度下获取有效的纹理特征,但由文献[16]可知,这也带来了一定的缺点,借鉴文献[16]的方法给予改进,即用数字电路中的异或运算来解决各个子邻域值由求取均值得到而造成纹理特征平滑化的不足,以及邻域大小可变后局部子邻域内的变化情况常被忽略的问题。改进后算法的基本思想为:对于像素点a,采用3×3和5×5两个不同大小邻域的AR-DLBP算子处理,获得两个不同的8位二进制数序列,对其进行异或运算,得到最终的一个8位二进制数,再转换成十进制数,就得到了像素点a的纹理特征值。
用数学公式可表示为:

Ai、Bi为A和B两个序列的第i位,其编码示意图如图8所示。

图8 XOR-AR-DLBP编码示意图
4 特征融合
4.1 表情局部区域贡献图谱
根据香农定理,若离散随机变量X(x1,x2,…,xn)发生的概率为 p(x1),p(x2),…,p(xn),则这些变量的信息熵可表示为:

同理,表情图像 f(x,y)的信息熵可表示为:
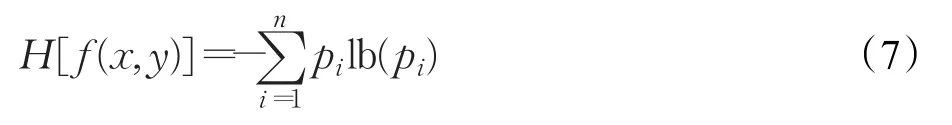
式中 pi为表情图像第i个灰度级发生的概率,n为灰度级的总数。
由于信息熵能够表述表情相应区域信息量的多少,而信息量多少可反映局部区域贡献度的强弱,为此本文用文献[17]已改进的信息熵方法来求眉毛、眼睛、嘴巴这3个局部区域的信息熵,进而得到它们的贡献度。
若定义每个像素的信息熵为:
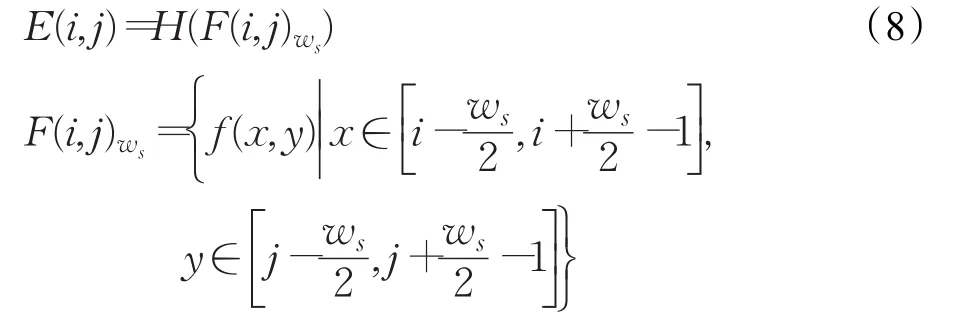
ws为可滑动窗口的范围大小,F(i,j)ws为以(i,j)为中心,ws范围内的子区域,E∈[ ]0,1。
由于每个像素的信息熵与周围其他像素的分布是有关的,为此眉、眼、嘴这3个局部区域的贡献度CMb、CMe、CMm就可通过该区域的平均信息熵来表示:

4.2 特征加权融合
面部表情识别是一个非常复杂的过程,仅仅利用单个特征已不能达到所期望的数值,为此本文提出特征加权融合的方法来提高表情的识别率,其大致步骤为:预处理后,对整张人脸图像和眉、眼、嘴关键区域进行XOR-AR-DLBP特征变换,获取局部纹理直方图特征;由信息熵计算出眉、眼、嘴这3个局部区域的贡献度CMb、CMe、CMm,并对其直方图特征进行加权和级联;最后与整张人脸图像的直方图特征串联,构成所需的融合特征直方图,送入SVM分类器训练识别。其整个识别过程的流程如图9所示。
5 表情识别实验结果及分析
实验环境:Windows 10,MATLAB R2010b,vs2012。数据库:JAFFE和Cohn-Kanade。参数选择:图像尺寸大小统一为64×64,分割出的眉毛和眼睛的尺寸大小为64×12,嘴巴部分尺寸大小为64×30;XOR-AR-DLBP的两邻域大小采用3×3和5×5;在求表情局部区域贡献度时,滑动窗口ws大小取3,5,7等奇数,由识别率及执行时间可知ws取值较小时,局部图像的纹理特征能更好地表现[18];SVM分类器选用多项式核函数,次数d=4。
5.1 本文算法的实验结果及分析
5.1.1 JAFFE库实验
JAFFE数据库来自10位日本女性在悲伤、高兴、惊讶、恐惧、生气、厌恶、中性这七类情况下自发产生的表情图像,共213幅。实验中随机选取每人每类表情2幅作为训练样本,共140幅,在余下的图像中再随机选取每人每类表情1幅作为测试样本,共70幅,循环实验3次,实验结果见表1所示,其中a为整张图像,b为关键区域级联,c为a、b的融合。

图9 整个表情识别的算法流程

表1 JAFFE库中(a、b、c)3种情况的实验结果

表2 Cohn-Kanade库中(a、b、c)3种情况的实验结果
由表1 JAEEE库的实验结果知,本文算法c的平均识别率达95.71%,比加权局部关键区域b高6%,比直接对整张图像实验a高15%左右,可见所提算法能取得很好的识别效果。其中误判比较多的是把恐惧误判为厌恶、悲伤,由于这3者之间的变化比较细微,容易误判。
5.1.2 Cohn-Kanade库实验
Cohn-Kanade数据库的表情图像都来自一个视频序列,一个表情的变化可以通过一个序列前后图像的细微变化体现出来,共210个18~30岁的近2 000张表情图像视频序列,六类表情为:悲伤、高兴、惊讶、恐惧、生气、厌恶。实验中随机选取20个人每类表情1~2幅,共200幅,在余下的图像中再随机选取每类表情1~2幅,共200幅,循环实验3次,实验结果见表2所示,其中a为整张图像,b为关键区域级联,c为a、b的融合。
由表2 Cohn-Kanade库的实验结果知,本文算法c的平均识别率达97.99%,比加权局部关键区域b高7%,比直接对整张图像实验a高17%左右,但都比JAFFE库上的识别效果要好,主要是由于CK库中的每类表情图像都来源于一系列的视频序列,表情特征更容易表达和提取,故识别效果更好。其中误判比较多的是把厌恶误判为悲伤,这2者之间的变化属于微表情,容易误判。
5.2 不同算法实验结果比较
5.2.1 不同算法识别率比较
为了验证本文所提算法的有效性,在上面实验的基础上对不同算法做对比实验,其中a、b为本文算法融合前的情况,c为融合后的情况。与几种常用表情识别算法在JAFFE库和CK库上的平均识别率比较结果见表3所示。

表3 不同算法平均识别率比较 %
5.2.2 不同算法平均识别时间比较
在JAFFE库和CK库上,各随机挑选10幅表情图像,用不同算法进行识别实验,其中a、b为本文算法融合前的情况,c为融合后的情况。平均识别时间结果见表4所示。
由表3和表4的实验结果可知:本文算法c无论是在识别率还是识别时间上都比常用算法的效果要好。如DLBP算法[12]和XOR-AR-LGC算法[16],都是对整幅人脸图像进行直方图分块提取特征再级联各子块直方图分类,故平均识别时间要比本文a、b、c情况慢许多;在平均识别率方面,本文算法融合前的a、b情况虽没文献[12,16]的高,但都在80%~90%左右,还是可接受的,且融合后的c情况在常用几种算法中效果相对是最好的。另外本文算法c在识别率上虽与HCBP、AAM、XOR-AR-LGC、精确局部特征描述相近,但识别时间都比它们要短。由此表明,本文所提算法较传统算法既可取得较高的识别率,又可保持比较理想的实时性。

表4 不同算法平均识别时间比较ms
6 结束语
本文提出了非对称方向性局部二值模式表情识别算法,用XOR-AR-DLBP获取整张表情图像和局部(眉、眼、嘴)表情图像在不同尺度不同方向的特征信息,通过信息熵计算局部表情图像的贡献度,获得权值分配,并与整张图像加权融合,最后输入SVM分类器用于识别。与传统表情识别算法相比,本文算法不仅在识别率上还是在识别时间上都表现出了一定的优越性:
(1)本文算法在预处理阶段,对表情图像进行了光照补偿处理,不仅减少了光照、噪声对后续识别的影响,也增强了图像的细节信息。
(2)XOR-AR-DLBP算法获取整张表情图像和局部(眉、眼、嘴)表情图像不同尺度不同方向的特征信息,不仅考虑到了中心像素与邻域像素的关系,也考虑到了邻域像素间的强度关系,特征维数不变,且对识别具有更好的鉴别能力。
(3)对局部表情图像通过信息熵计算贡献度,获得各子块直方图的权值分配,再与整幅图像融合,即不同尺度不同方向上局部特征与整体特征的融合,这大大地提高了特征的描述和鉴别能力。在与传统算法相比时,本文算法不仅在识别率还是识别时间上效果都是最好的。
猜你喜欢
高技术通讯(2021年2期)2021-04-13
吉林大学学报(理学版)(2020年3期)2020-05-29
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
测控技术(2018年10期)2018-11-25
自动化学报(2018年7期)2018-08-20
中国交通信息化(2018年3期)2018-06-13
计算机技术与发展(2017年12期)2017-12-20
计算机应用(2016年10期)2017-05-12
周口师范学院学报(2016年5期)2016-10-17
