
基于图形处理单元加速的磁共振重建算法研究进展
2018-12-01 08:30刘燚张宁
中国医学装备 2018年11期
刘 燚 张 宁
在当今磁共振成像(magnetic resonance imaging,MRI)的应用中,其扫描速度已成为制约其发展的一大瓶颈,缓慢的扫描速度导致运动伪影的产生,也使动态成像难以实施。20世纪90年代,研究者为提高扫描速度,通过高速切换梯度磁场来实现快速成像序列,但是过度密集的射频脉冲序列导致人体内射频能量聚积,对人类的健康造成威胁,因此依赖梯度场切换速度来提高成像速度基本上达到极限[1]。
有研究已将提高成像速度的重点放在减少采样数据,改进重建算法的领域,如螺旋数据采样网格化数据[2]重建,并行成像[3]等方法已经为业内人士所熟知。但是,这些早已成熟的算法重建速度却难以接受,主要因为这些算法中包含大量的浮点运算,当前常见的中央处理器(central processing unit,CPU)的浮点运算能力均不尽如人意,密集运算性能的提高范围有限,即使利用多线程并行处理技术,在微型计算机上不能带来很明显的速度提升。虽然超级计算机和集群计算在浮点运算方面有着出色的表现,但是对于研究者和应用者这种选择过于昂贵。
1 CPU与图形处理单元的结构差异
由于CPU和图形处理单元(graphics processing unit,GPU)在微结构上的巨大差异,CPU中大量的晶体管用作高速缓存(cache)、逻辑控制单元(Control),只有少量的用作计算的算术逻辑单元(arithmetic logic unit,ALU)。而GPU则把更多的晶体管用作了计算单元,只有少量晶体管用作了高速缓存(Cache)和逻辑控制单元(Control),这使得GPU比CPU更适合完成密集计算任务。因此在浮点运算能力方面,图形处理器(graphics processing units,GPUs)正逐步表现出优越的性能(如图1所示)。
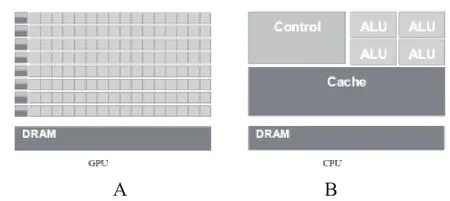
图1 GPU和CPU微结构示意图
早在2003年,中央处理器(central processing units,CPUs)和GPUs关于浮点运算的能力已经开始进行了比较,2006年,美国英伟达[4]的G80 GPU在浮点运算能力方面已经最大达到英特尔Core 2 Duo的60倍。随着GPU技术的不断发展,在每秒浮点运算的次数以及带宽的表现,GPU都表现出很大的优越性,如此巨大的计算效率的提升,使研究者开始将医学成像的算法转向GPUs实现(如图2所示)。

图2 CPU和GPU浮点数运算能力对比图
2 基于计算统一设备架构的GPU通用计算
近年来,研究者已经尝试将MRI的重建算法移植到DirectX和OpenGL等图形化的语言,而且在整体性能上的提升也已经表现出巨大的潜力[5]。为了进一步鼓励使用者将GPUs作为重要的计算引擎,英伟达公司在2007年发布了计算统一设备架构(compute unified device architecture,CUDA),并向GPU的开发者提供了标准化的体系模型和框架。
目前的CUDA中包括cuSPARSE、cuFFT、cuBLAS和cuDPP等常用函数库。cuSPARSE主要针对稀疏矩阵操作的线性计算库;cuBLAS是针对传统线代计算的函数库,只支持稠密矩阵和向量的使用;cuFFT库是利用GPU进行快速傅里叶变换(fast Fourier transform,FFT)的函数库;cuDPP库提供了很多基本的常用并行操作函数,如排序、搜索等基本运算组件,用于快速搭建并行计算程序。
在CUDA中,所有的线程由线程格表示,线程格分为若干个线程块,每个线程块有若干个线程。在具体运算时,每个核函数针对不同的数据同时被大量的线程执行,这些线程被组合成具有相同大小的线程块,具有相同大小,执行同一个核函数的线程块组成一维或二维的网格,因此CUDA非常适合需要大规模并行计算的场景(如图3所示)。
3 并行采集重建算法的GPU加速
3.1 算法简介

图3 CUDA线程结构模型图
全面自动校准部分并行采集(generalized autocalibrating partially parallel acquisitions,GRAPPA)[6-7]概念是Griswold在2002年所提出,相比之前的基于K空间的并行成像算法,GRAPPA采用了多区块重建的方法,一个线圈中未采样相位编码由多个线圈、多个区块中已采集相位编码进行线性求和得到。
GRAPPA重建算法是一种更通用的基于K空间域的图像重建方法,该算法不再将各个线圈的数据直接拟合到全K空间,而是拟合到每个线圈的自动校准信号(auto-calibration signal,ACS)行,然后求出权系数wi(m),S是重建通道j的第ky+mΔky行,x列的数据,其计算为公式1[8]:
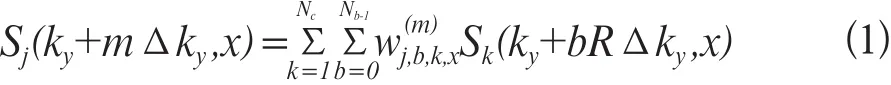
式中R为加速因子,Nb是用于重建的block的大小,Nc是线圈数,W为权重系数。
在GRAPPA重建算法的整个过程中,大量的计算消耗主要在W权重系数矩阵的求取上,而W的计算步骤为:利用ACS行数据建立矩阵A,B;对矩阵A,B进行归一化,按照公式2、公式3、公式4进行计算:

式中U及V均为中间计算结果;W为系数矩阵。
通过分析具体的每一个计算步骤的特点,对算法的结构进行调整,以更好的利用CUDA对其进行加速。
3.2 GRAPPA算法的使用CUDA加速
(1)利用CUDA进行矩阵相乘运算。由于在GRAPPA算法中,复数矩阵的乘法运算是非常消耗时间的运算,而在该运算中,可以使用GPU运算来解决这个问题,提高复数矩阵相乘的运算速度。调用cuBLAS中cublasCgemm()函数,实现单精度复数矩阵运算核函数。
(2)利用CUDA实现矩阵转置。从算法实现过程可以看出,在第二步中可以使用线程同步进行操作,其算法具体实现步骤如图4所示。

图4 矩阵转置计算流程图
(3)矩阵求逆。在矩阵的求逆运算中使用的是柯列斯基分解,而该算法并不适用于并行化的计算,故该算法应在主机CPU下进行计算。
通过上述3个部分优化,重新调整算法结构,在计算机上对优化前和优化后的两种方法分别进行运算,在鑫高益公司SuperScan1.5T型MRI上扫描志愿者得到采样数据,采集矩阵为276×276,共采集8个通道19层数据,从中取出8个通道的一层数据进行测试。测试过程是在配有8 G内存,Intel Core i5-3230M CPU(主频为2.60 GHz),Navida NVS 5400 M(核心频率为600 MHz,最大显存为2048 MB)的计算机上进行(如图5所示)。

图5 GRAPPA运算执行时间对比图
图5显示,在GRAPPA算法中需要大量消耗计算时间的具体环节上,使用CUDA进行计算,利用CUDA的多线程block,以及出色的浮点计算能力,通过在算法中加入CUDA运算,极大的提高了GRAPPA算法的运算速度,从而极好的解决了GRAPPA算法运算时间过长的瓶颈,而且重建效果基本一致,GPU加速为GRAPPA算法在并行重建中的应用提供了更好的发展前景(如图6所示)。

图6 CPU和GPU重建后的MRI结果图像
并行采集的重建算法中,常规的SENSE算法也可以使用GPU进行计算,且在其他的SENSE扩展算法中也有GPU的应用[9]。
4 Griding算法的GPU加速
4.1 算法概述
网格化(Griding)算法[10]是一种当前非常流行的基于非笛卡尔采样轨迹的MR图像重建技术,射线型、螺旋型采样[11]相比笛卡尔型采样有其他的优势,如采集速度快,对运动伪影不敏感,如果采用此种采样就不能直接使用FFT重建图像,因此采用网格化的算法可以将非笛卡尔网格通过插值变成笛卡尔型,然后可使用FFT进行图像重建[12]。对于放射型K空间采用的重建,对一些关键的步骤使用CUDA加速,取得比较好的效果(如图7、图8所示)。

图7 笛卡尔型K空间采样示图

图8 非笛卡尔型K空间采样示图
4.2 算法加速
在具体算法实施过程中,其中插值这一步中使用特定的插值窗函数Kaiser-Bessel窗,在一步中由于特定计算结构,笛卡尔网格中的所有元素C(Kx,Ky),可以使用GPU进行加速计算,其卷积插值计算为公式5:
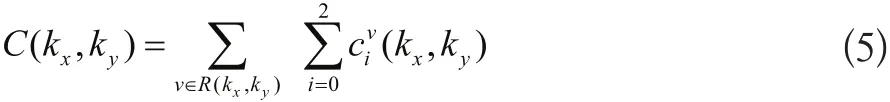
通过使用CUDA对卷积插值方法进行优化,以采集到的K空间轨迹上非均匀分布采集点为中心,CUDA中的每个线程负责一个采样点或一组采样点的计算,根据采样点与卷积窗内的网格点的距离,计算采样点对这些网格点的贡献,相当于把采样点的值“分配”到各个网格点上。测试结果也表明,网格化算法使用GPU计算,相比CPU计算GPU可以达到3.5倍左右的加速,且两者的计算结果基本一致,呼吸运动伪影明显减弱,表明在使用网格化的相关重建算法中都可以用GPU来进行加速[13]。在对螺旋采用的K空间进行网格化,且使用GPU加速,也取得很好效果(如图8、图9所示)。
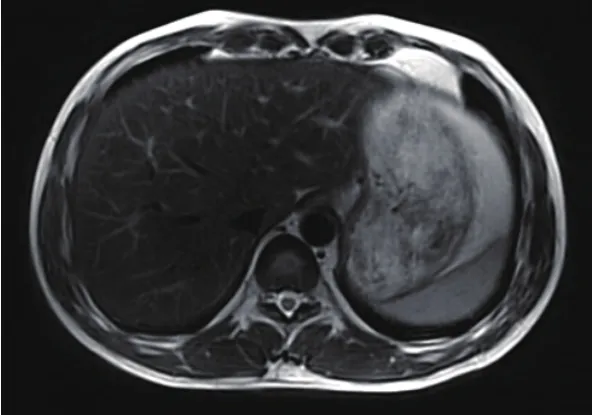
图9 网格化算法CPU重建MRI图像

图10 网格化算法GPU重建MRI图像
5 FFT的GPU加速
FFT是一种重要的算法,几乎在所有的磁共振图像重建算法中都有应用,同样FFT算法的快慢也将对磁共振图像重建算法的速度有着非常重要的影响。传统计算FFT通常会选用FFTW库,或是Intel MKL,这两个函数库都是经过高度优化的数学计算库,对于计算FFTW,这两个库都可以充分发挥CPU的运算能力。但是,随着GPU的出现,基于GPU的浮点运算表现出强大的能力,所以在目前的磁共振图像重建中使用基于GPU的FFT已经广泛应用,尤其是英伟达公司推出CUDA以后,基于CUDA的FFT库[14](cuFFT)使得FFT计算速度有了大幅度的提升,相对于FFTW和Intel MKL,都有很大的速度优势。实验表明,cuFFT对MKL在单精度和双精度的计算上都有着非常明显的优势,其他测试也表明,在不考虑数据拷贝的情况下,cuFFT的运算时间远低于FFTW的运算时间[15-18](如图11所示)。

图11 cuFFT与MKL单精度和双精度运算速度对比示图
在SuperScan1.5T型MRI上扫描志愿者得到采样数据,采集矩阵为276×276,共扫描17层。重建过程是在配有8 G内存,Intel Core i5-3230M CPU(主频为2.60 GHz),Navida NVS 5400 M(核心频率为600 MHz,最大显存为2048 MB)的计算机上进行,分别使用MKL进行FFT运算和cuFFT进行运算,测试结果表明,使用MKL计算时间为112 ms,cuFFT计算时间为72 ms,运算时间可以减少40%,加速效果比较明显,且计算结果基本一致。在一些磁共振重建的算法中会反复大量用到FFT运算,所以累计减少的运算时间比较可观,基于GPU的FFT计算所表现出来的强大优势,使得该技术在磁共振重建中发挥着重要的作用(如图12、图13所示)。
6 展望
自从GPU出现以后,其在科学计算方面所展现出强大的运算能力,随着GPU显卡高速发展,该技术已在医学MRI领域得到了广泛的应用,对算法的加速也取得了非常显著的进步,从而使得许多优秀的重建算法得到更好的应用,从整体上加快MRI速度,某种程度上也提高了图像的质量,为医学MRI技术添加了新的发展动力。

图12 MKL重建结果图像
图13 cuFFT重建结果图像
对3种常见的磁共振重建算法使用GPU加速,验证了GPU的加速性能,这些只是在该领域的尝试,如基于深度学习的MRI图像重建加速、基于MRI扫描图像的药理分析模型、MRI实时扫描重建[19]以及大数据量的3D图形加速重建等等都可以使用GPU加速运算[20]。由于显卡显存的限制,目前只能满足二维和部分三维图像的重建加速,对于更高维度、更大数据的计算将是巨大的挑战。但是,随着GPU技术的进一步发展,相信该技术在磁共振领域也一定会有更多更广泛的应用。
猜你喜欢
传奇·传记文学选刊(2021年10期)2021-10-20
山西电子技术(2021年3期)2021-06-28
小天使·一年级语数英综合(2021年3期)2021-05-08
科学(2020年3期)2020-11-26
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
中国环境监察(2017年3期)2017-05-14
哲学评论(2017年2期)2017-04-18
中国市场(2016年12期)2016-05-17
现代计算机(2016年17期)2016-02-28
