
信用债内部评级方法:构造与运用
2018-11-14 10:34:20管超毕盛
西南金融 2018年11期
管超 毕盛
(中国人民银行深圳市中心支行 广东深圳 518001 中国农科院经济与发展研究所 北京100081)
引言
金融市场普遍存在信息不对称问题,由此导致融资成本增加、投资者风险上升、资源错配等现象出现。为了减缓或消除投资者与债券发行方的信息不对称,债券市场引入第三方(外部)信用评级。信用评级机构发布的能够描述发行方信用品质的评级结果,将作为投资者债券交易和制定信用策略的重要参考。过去研究表明,信用评级作为债券市场信息中介,具有重要的信息价值和显著的风险揭示功能(Ederington等,1984;Partnoy,2002;Boot & Milbourn,2006;Rhee,2015)。在当前中国市场环境下,信用债发行需进行评级,信用等级对债券性质划分(投资级、投机级)、债券定价以及债券的市场流动性均十分重要,这佐证了信用评级的作用和经济价值。除此之外,中国监管当局还设置了有关评级等级的其他制度要求,如对保险公司、部分金融机构购买债券时最低评级等级限制①,以及交易所债券市场质押式回购最低评级等级限制②。因此,信用债信用评级既包含自身携带的信息功能,还具有监管赋予的职能。Jorion等(2005)、Kisgen& Strahan(2010)、Opp等(2013)研究证明监管倾向及制度规则对信用评级具有显著影响。
20世纪初,穆迪公司最早将信用评级引入美国债券市场,率先用简易符号表示各个债券的信用风险水平。相较于美国100多年的评级发展史,信用评级在中国发展时间并不长。但是,随着国内债券市场和评级机构的发展,以及本土评级机构与国际三大评级机构开展密切合作,中国的信用评级市场发展迅猛。2014年之前,由于“刚性兑付”的存在,没有发债公司出现实质性违约,违约基础数据匮乏,违约率曲线不能进行描绘。2014年之后,中国信用债市场违约步入常态化,违约主体数量不断增加,2016年违约主体数量达到新高,违约范围也从私募扩展到公募,银行间以及交易所债券市场均出现不同行业的发债方违约。信用风险的逐步累积、释放也为信用评级机构进行违约率统计提供了基础数据。尽管如此,我国现有违约数据积累仍不充分。如下图所示,中国公募债券市场的违约率曲线间断、跳跃,而穆迪的一年期债券违约率曲线是一条平滑的曲线。也就是说,目前中国的外部评级等级无法与违约率形成合理的对应关系,也无法从违约率角度评判信用评级的有效性。寇宗来等(2015)、钟辉勇等(2016)研究结果均表明,中国信用债市场第三方信用评级③有效性不足。
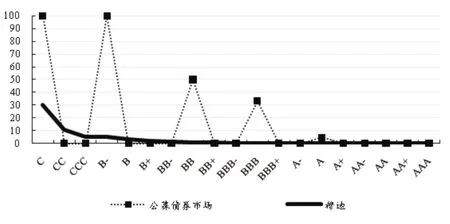
中国公募债券市场、穆迪一年期违约率曲线图
为了应对违约数据积累不充分、违约率曲线间断和跳跃问题,本文构造了一个参考外部评级,但有别于外部评级的内部评级体系。运用转换方程、回归拟合以及最优算法,从违约率这个最终检验标准出发构造内部评级,并通过一个实证例子进行实践,最后将其与外部评级体系对比分析得出这种构造方法的经济价值。与银行信贷风险评估体系和现有外部信用评级体系所不同的是,本文从直接融资债券市场切入(而非聚焦银行间接融资),参考现有外部评级体系,通过风险评估模型重新计算了被评方信用风险得分值,并将“是否违约”作为桥梁和评判标准,通过得分、转换、拟合、最优化几个步骤,形成新的评级系统,以期弥合违约率曲线跳跃和间断问题,更好地揭示信用风险状况。本文所指的“内部”并非狭义上投资者自己做的评级体系,而是与外部相对应的、广义上的非第三方(外部)评级体系,因此,后文将介绍内部、外部信用评级体系以及如何将外部评级与内部评级进行关联。
研究目的方面,本文不是为了推翻现有的评级体系,而是针对目前外部评级体系存在的问题和不足,从违约的角度重新思考,比较几种拟合方法并与转换方程进行组合,重新切分最终形成新的评级等级,这能对现有信用评级体系提供一种可能的改进方向,而该内部评级体系的经济价值也是未来评级市场不断完善的动力和依据。研究意义方面,违约率的独特视角、外部到内部评级的连贯逻辑、嵌套的实证技术是本文的创新之处,而有效性和经济价值的检验也赋予了本文重要的现实意义。研究内容和框架方面,本文主要分为内部评级体系的构造、运用及检验三个部分。首先介绍了如何构造一个可以连续化违约率曲线的内部评级体系,即构造环节;其次通过采用中国债券市场经验数据,展示内部评级的具体操作流程,即运用环节;最后是对该内部评级体系有效性和经济价值进行测度,即检验环节。
一、信用评级体系分析
(一)内、外部信用评级体系介绍
无论是间接融资信贷市场,亦或是直接融资债券市场,内部评级和外部评级一般是以评级方是否为资金供给方进行区分,如银行进行评级、债券投资者进行评级称为内部评级,资金供需双方以外的第三方进行评级则称为外部评级。
内部评级概念最早来自银行开发的信用评估系统,是对信贷客户进行风险评估及对银行风险资产进行监测的信用管理活动,银行信贷业务开展过程中普遍要求客户经理在放贷前进行尽职调查,实践内部评级操作流程。银行内部评级操作模式流行的主要原因在于银行本身具有充分的贷款客户数据和信息。随着直接融资市场的发展,内部评级概念也逐渐延伸至债券市场。债券市场的内部评级是指一定规模的基金公司、财务公司等机构投资者会开发自己的债券信用风险评估体系,通过独立收集数据、构建模型、评判定级,最终对目标债券发行公司和所发债项进行风险评估。但与银行所不同的是,债券投资者往往不具备充分的贷款客户数据和信息,内部评级的质量无法得到保证,因此债券市场外部评级应运而生。
从美国债券市场的实践来看,第三方外部信用评级出现较早,主要弥补投资者在专业性、时间和精力等方面的限制。美国外部评级得到了广泛运用,很多发债企业都希望得知名评级机构(如穆迪)的评级,以此作为一种承认或推介的信号,传递给投资方。同时,一旦评级机构下调评级后,发债公司将遭遇无可比拟的困难处境(White, 2010)。外部评级能凭借“入场”调查的优势,要求被评公司提供其认为重要的报表和数据(如索要其提供给监管机构的非公开独立报告)或者对公司某方面问题进行解释和陈述,从而挖掘发债公司公开信息以外的资讯。此外,信用评级还能向市场提供额外信息功能,包括协调机制和联络点的作用,帮助协调投资者的投资理念,以及监督被评企业。评级机构还能在信用市场上对风险和信息进行整理和分类(如投资级和投机级分类),这有助于投资者进行类别选择,降低投资者的研究和分析成本。
但在中国债券市场中,外部评级等级集中度较高,与国外评级结果分布差异明显,部分投资者对信用评级的有效性和公信力存疑,转而研发和构建针对债券市场的内部评级体系。中国四大评级机构之一的大公受到监管处罚,遭遇两部门严重警告处分暂停证券评级一年,该事件也将质疑中国外部信用评级的情绪推至峰值,内部评级关注度迅速提升。
(二)外部信用评级体系的内容
当前主流的外部信用评级体系是国际三大评级机构:标普(Standard & Poor's Financial Services)、穆 迪(Moody’s Investors Services)、惠誉(Fitch Ratings)所实行的评级模式,中国信评市场基本沿用了该体系。评级体系主要内容包括:违约的认定、受评对象的分类、评级等级的划分、评级等级的决定因素和评级方法。
1.债券违约的认定。国际三大评级机构对债券违约的认定基本一致,都将已经发生或者即将发生无法依据合同规定偿付本息的事实作为债券违约的认定标准。但穆迪和惠誉认定标准略严于标普,因为标普认为宽限期内不算违约。中国信用评级基本沿用了国际主流评级机构对违约的认定,《公司法》第107~108条也明确指出:不履行合同或表明将要不履行合同都视为违约。
2.受评对象的分类。中国评级体系受评对象的分类与国际三大评级机构一致。受评对象可分为发债主体和所发债项,即信用评级可分为主体评级和债项评级两类。根据时间长短又可分为长期评级和短期评级,长期与短期的评级符号有所不同。
3.评级等级的划分。国际三大评级机构在评级等级划分上基本一致,但在评级符号代表的含义上存在细微差别。具体来看,标普和惠誉的符号一致,长期信用等级分为:AAA、AA、A、BBB、BB、B、CCC、CC、C和D级,其中 BBB(含)以上为投资级,BBB以下为投机级。惠誉在此基础上还将D级细分为DDD、DD和D级。在标准评级上为了更精确地显示级别内部的区别,标普和惠誉在各个等级前加上了微调(notch)符号:“+”或者“-”号,表示略高或略低于本等级。穆迪的长期信用等级分为:Aaa、Aa、A、Baa、Ba、B、Caa、Ca和 C,其中 Baa(含)以上的为投资级,Baa以下是投机级。对于微调级别的划分,穆迪则是在各等级加上数字1、2、3以示级别内的区别。中国中长期信用评级等级的划分基本沿用了标普和惠誉的符号和含义,但只到C级,未包含D级别,详见表1。实践中因为信用风险具有一定的复杂性,所以评级体系都要在稳定性和准确性上取得一个平衡。
4.评级等级的决定因素。国外和国内的评级等级决定因素均由定量部分和定性部分构成,不仅考察了历史与未来预测的统一,也结合了公司个体实力和外部支援。个体实力水平和外部支援决定了主体评级等级,主体评级等级与增信条款则决定了债项评级等级,详见表2。
5.评级方法。从外界看评级过程就是一个黑箱,被评方的资料信息经过评级机构专家定性与定量的综合分析,得出一个评级等级,等级描述的是发债公司(主体)或对应债券(债项)特定的信用风险状况。信用评估方法主要分为定性方法、定量方法、神经网络方法和其他方法(见表3)。其中,定性方法不适宜量化分析,而神经网络则稍显复杂,加上2014年之前,实质性违约事件并不多,因此学者们普遍使用的是多元线性回归分析法。随着中国债券市场违约事件不断增加,Logit、Probit等方法逐渐成为主流信用评估方法。
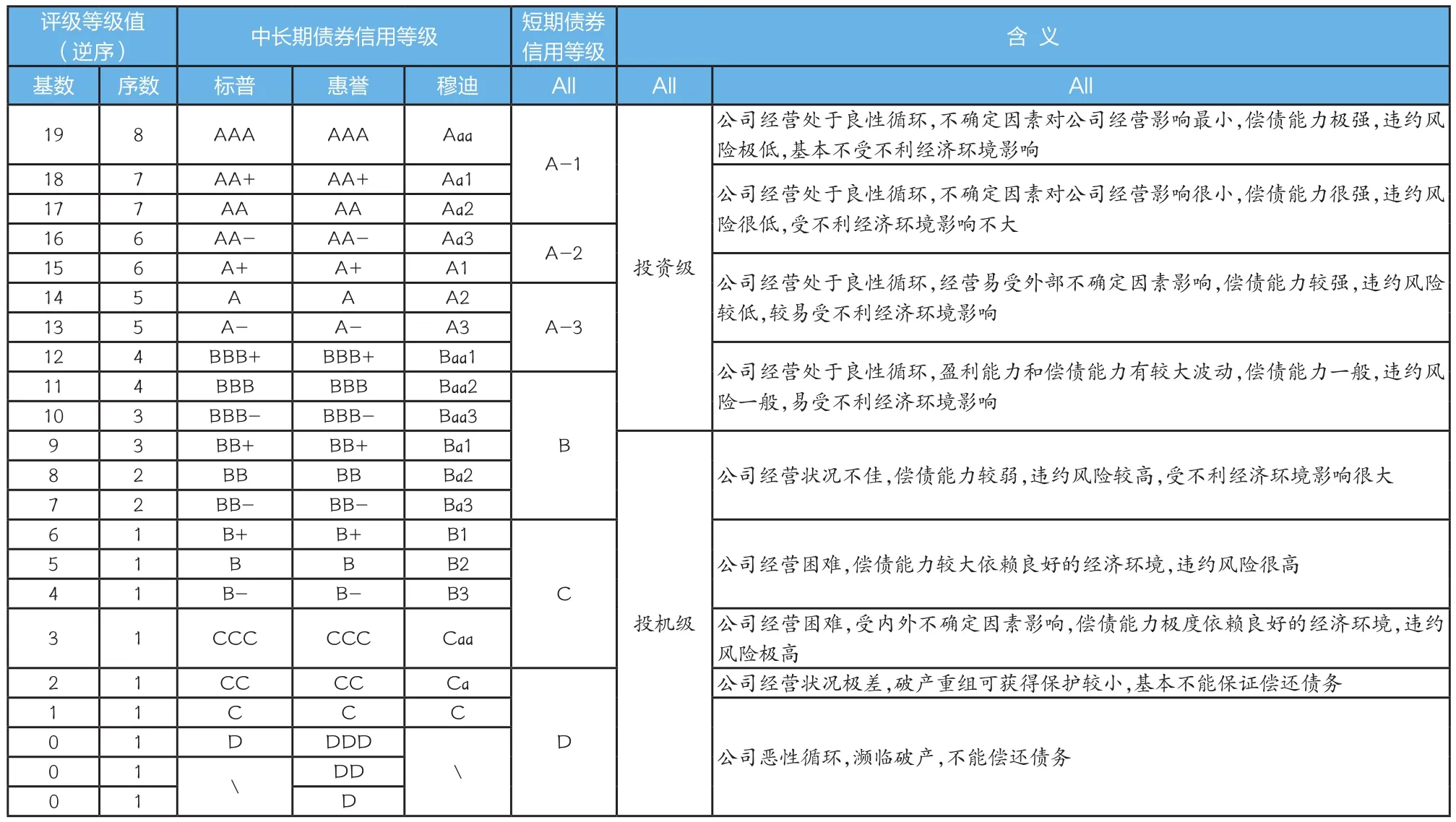
表1 国际三大评级机构关于评级等级的划分与对应符号和含义

表3 主要的信用评级技术
(三)外部信用评级体系提炼核心因子
通过借鉴外部评级操作框架有助于构造内部评级体系。无论内部评级还是外部评级,根本目的都是判断债券发行方的偿债意愿和能力,因此在构造内部评级体系过程中,也需参考外部评级体系中重要的评级决定因素和评级方法。
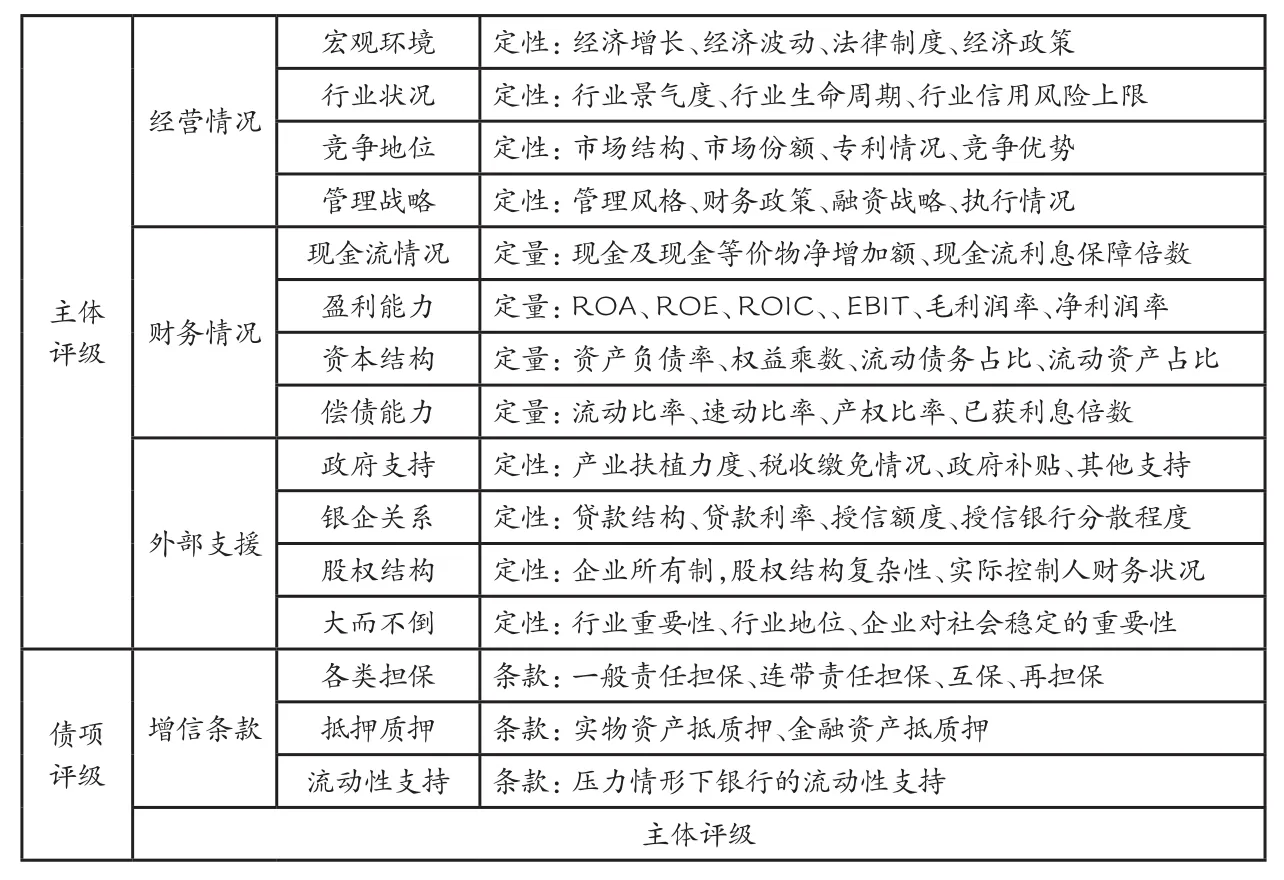
表2 评级等级的基本决定框架
宏观至微观一系列因素共同决定了信用评级等级。评级决定因素的定量部分也是学者重点考察的内容,许多学者对此进行了实证研究(Srivastava & Hung,2015;高媛和卞直巍, 2003;沈中华等,2016;吴凤和吴义能,2017),本文也将重点考察这些定量因素。对于其他重要的决定因素,以及对定性部分的纳入,一些学者同样进行了相关研究:Shen等(2012)、Huang & Shen(2015)、那明(2014)认为主权因素对评级影响较大;Shen和Huang(2014)、李琦等(2011)、刘娥平和施燕平(2014)发现盈余管理对评级影响较大;朱松等(2013)、陈超和李镕伊(2013)发现审计费用及审计可靠程度对评级影响较大;武恒光和王守海(2016)、吴育辉等(2017)、陈益云和林晚发(2017)则认为规模、产权属性、管理层能力、企业社会责任等对评级的决定具有显著作用。本文借鉴这些研究,引入企业规模、所属行业、产权属性、审计质量、担保方式这几个指标。
截面数据有助于排除经济波动和主权因素对评级的影响,本文搜集了银行间债券市场2016年存续的中期票据、短期融资券、企业债发债公司(主体评级)横截面数据作为研究样本。剔除数据严重缺失样本、发行人主体重复样本、城投债样本,最后获得样本总数1105个,其中违约样本22个。参考外部评级的决定框架,本文将发债公司的微观财务信息分为经营能力、成长能力、偿债能力、现金流情况、资本结构以及其他这几大类。每块内容都包含若干个指标,共搜集整理了54个指标。随后使用主成分分析法进行降维,通过比较偏最小二乘回归的Mean Squared Error of Prediction(MSEP)来确定主成分的因子数量。MESP的检验结果指向的是3个主成分因子:PC1、PC2、PC3,即3个因子使得偏最小二乘回归的MSEP最小,且模型最简约。由于主成分分析过程中,样本的财务变量需要保证无空缺,而原数据部分指标数据值缺失,因此在获得主成分因子后,样本总量将有所损失。
最终的解释变量为主成分分析方法确定的几个因子,财务指标均用2015年公司年度财务报表数据,描述发债企业的偿债能力和意愿;被解释变量为2016年外部评级等级(不区分评级机构),描述的是公司一年期违约可能性的大小,并将其转化为数值,数值越高代表评级等级越高④本文对评级等级的赋值包括0~19的基数赋值法和1~8的序数赋值法,分别代表基数概念和序数概念。。回归前我们对数据进行了标准化处理()和1%的截尾处理,表4是回归结果。
结果显示,54个财务指标构成的3个主成分因子PC1、PC2、PC3均非常显著,模型整体拟合优度较好,说明这三个主成分对发债公司信用风险的评定非常重要,后文中我们也将采用这三个主成分因子,构造内部评级体系。
二、内部评级体系的构造
本文构造的内部评级体系聚焦违约率,将发债公司是否违约作为核心变量,并纳入了不同间距的违约率(Empirical DR)、违约概率(PD)⑤本文有两个违约“率”的表达:违约率(Empirical DR)和违约概率(PD),一个是计算的比例值,一个是拟合得出的概率值,由于中文表达无法有效区分,后文对此都用英文固定表达,以免混淆。以及目标违约率(Target PD),通过评级等级划分能最终形成平滑的违约率曲线。具体来说,内部评级体系的构造分为三个步骤。
步骤一:计算被评方内部信用风险得分值Score,平均分割后计算每个等距的Empirical DR。参考外部评级的决定因子,使用Ordered Logit Model(简称Ologit)信用风险评估模型,得出模型的预测概率,Ologit模型回归后获得每个样本的得分值Score(0<Score<1),得分值指向各个样本未来一年期的信用质量高低,作为后文的信用质量指标。随后将得分值从小到大按序排列,设置得分值的均匀分割点,按照12.5%的百分位数划分为8个间距(这里间距划分可任意选取,对后文无影响)。每个间距中都有固定的样本量,包括有违约的和无违约的。计算每个间距的违约率(违约券数/区间总券数)得到Empirical DR。
步骤二:将得分值纳入转换方程中,采用几种模型分别进行拟合,并通过Hosmer-Lemeshow(简称H-L)统计量选择最优的拟合方法。这一步需要运用风险评估模型,模型的解释变量为上一步计算出的信用风险得分值,将是否违约作为被解释变量,拟合求得不同得分值的违约概率PD。
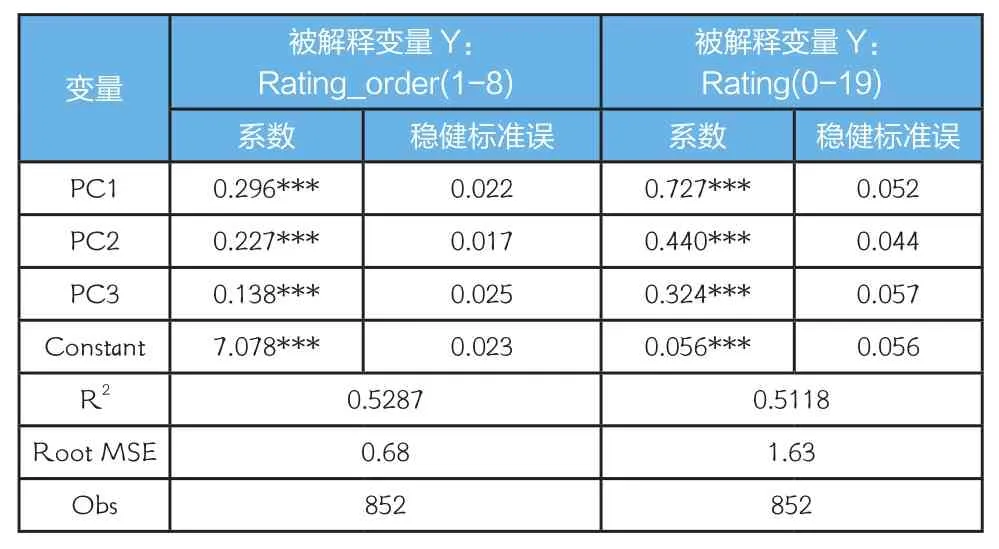
表4 评级决定因素的回归结果
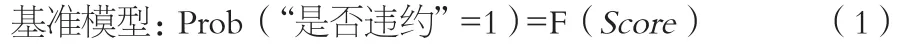
信用风险评估模型将使用几种方法逐一实施并进行比较,F函 数 分 别 为:Probit、Logit、Complementary Log-Log(简 称CLL)、Piecewise。
经验显示,第一步求出的信用风险得分值以及Empirical DR将会出现较大的偏度,这会影响步骤二中信用风险评估方法的运用以及随后的优化计算。因此,参照Granger and Newbold(1986)以及Fox(1998)的研究,我们引入两种转换方程:Box-Cox Transform(简称B-C转换)、Box-Tidwell Transform(简称B-T转换)。这两种转换方程能在一定程度上对等级偏差进行校正。此外,由于Logit和Probit风险评估模型会在1/2处对称,这两个转换方程在大多数情形下能使拟合度整体提高。转换方程中的转换系数λ、α是经校准(Calibration)后的所得值,两种转换方程形式为:

Piecewise模型拟合需要选取一个分数门槛St,门槛左右两侧采用两种转换模型形式,需要特别指出:第一,得分数据变成了左右两个数据子集,两边可用同一个模型;第二,两个模型产生的PD连接阈值St时具有一定程度的非光滑性,即可以是非连续的连接。因此Piecewise模型可以某种程度将两个模型“合二为一”,最终映射到一个基于PD的评级等级表中。对于St的选择主要是通过一个迭代算法:识别其中一个模型与经验数据结合点,在该点附近寻找一个最优分割位。我们在这里引入了B-C和B-T转换,并将两者运用到不同的数据子集中,然后检验最优分割点。

上式中PD1是模型一运用在阈值St左侧;PD2是模型二运用在阈值St右侧。如果差值大于选定误差Epsilon,则需要重新进行该操作过程。实际上,由于我们对于两个数据子集都用了同一拟合模型,因此PD1和PD2具有非常接近的Empirical DR,随后我们将违约概率PD与得分值Score联系起来。
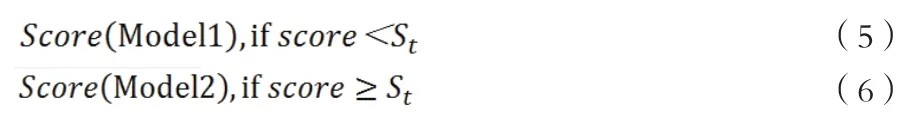
经过转换后,我们能较顺畅地将得分值Score与违约概率PD联系起来。随后通过比较H-L统计量(Hosmer和Lemeshow, 2004)来判别哪种信用评估方法更优,即Empirical DR与PD呈现出了最大的似然性(Max Likelihood)。
步骤三:将信用风险得分值Score非均匀地划分为若干个等级,代表了内部评级体系的等级数。划分依据是通过最优化算法,使PD与Target PD差值降到最小,每个等级能较好地描述理论违约率信息。首先拟合得分值,获得PD,如果模型是单调的,那么数据排序与PD排序值将同升同降。对于给定的N个观察值,我们可以获得分值S向量和与违约概率PD向量。

假设d(i)是评级等级i和i+1的分割点,则对于第一个评级等级来说,平均违约率可以写成:

评级等级i(i不是首尾时)的平均违约率为:

尾部(最后一个)评级等级平均违约率为:

最优方程为:
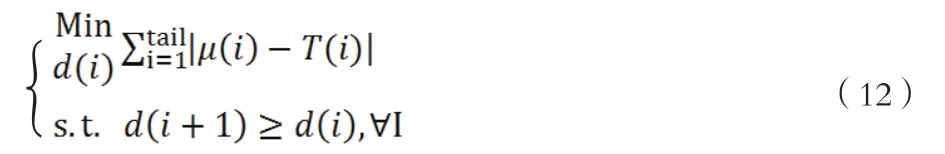
这是一个整数规划问题,目标是解出d(i)。由于划分点非常多,计算量非常大,需要用统计软件来求解,我们这里使用R软件进行求解,结果描述了得分值Score与PD的关系。
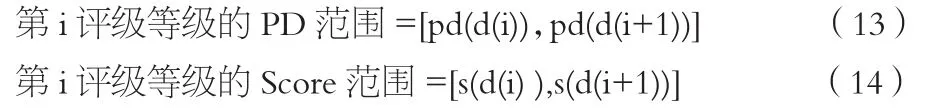
下一部分我们将采用中国债券市场数据作为例子进行具体展示。
三、内部评级体系的运用
笔者采用前文介绍过的银行间债券市场中期票据、短期融资券、企业债的发债公司(主体评级)横截面存续数据,对内部评级三个操作步骤逐一执行。
一是获得内部评级得分值Score。对外部评级进行赋值(0~19)⑥基数赋值法:AAA=19,AA+=18,AA=17,AA-=16,A+=15,A=14,A-=13,BBB+=12,BBB=11,BBB-=10,BB+=9,BB=8,BB-=7,B+=6,B=5,B-=4,CCC=3,CC=2,C=1,其他 =0。,数值越高,评级等级越高;纳入前文提炼的3个主成分因子,采用Ologit Model进行回归。回归后得分值需要先计算各个数据的概率分布,并将其标准化,使得分值位于(0,1)区间,这样操作有利于提高后文拟合的准确性。
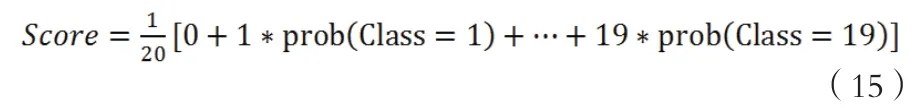
得分值计算公式如下所示:Ologit回归结果如表5所示:
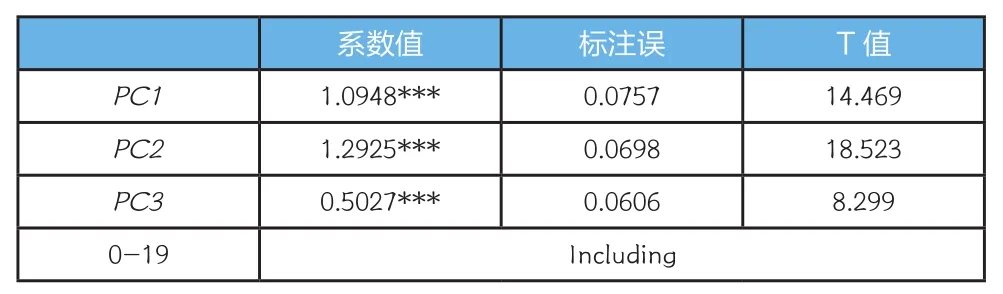
表5 Ologit回归结果
获得Score后将其排序,按照12.5%的百分位数分割点均匀划分为8个间距,计算每个间距内的违约券个数占总券数比率,该比率为Empirical DR。
二是分别采用Probit、Logit、CLL、Piecewise以及加入转换方程后的模型作为F函数,与“是否违约”虚拟变量进行逐一拟合。“是否违约”的认定标准为:当2016年该券出现到期未能偿付本息或宣布无法偿付本息,则认为该券发生风险事件,令虚拟变量“是否违约”=1。拟合后比较不同模型的H-L统计量,以此来选择使PD呈现最大似然的方法。
首先拟合的是未经转换的Probit、Logit、CLL模型,得到H-L 统计量分别为 35.339、35.464、35.774,初步判断 H-L 具有改进空间。随后纳入转换方程,测试了B-C转换以及B-T转换,目的是为了“扭正”得分值较高的偏度,如违约曲线存在的翘尾效应。但我们在转换过程中发现B-T转换经校准(Calibration)后自动选择的最优的α值过小(-1.54),以至于曲线“扭正”过头了。这种修正“超调”的原因可能是B-T转换方程与中国数据具有较大的违背性,所以在后文中只进行了B-C转换并展示。对于B-C转换方程,我们同样先用校准方法求出最优λ(这里求得系数λ=6.15),将其代入模型中进行拟合。结果发现,经B-C转换后三个模型H-L统计量均呈现出一定改进。Probit、Logit、CLL三个模型经B-C转换后的 H-L 统计量分别为 40.501、14.848、12.187。最后使用Piecewise Model进行拟合,阈值两边采用同一种拟合方法。我们使用R软件循环迭代分别对Probit、Logit、CLL进行测试,得出Probit模型的Epsilon最小值发生在第9、第10交汇处,Logit模型的Epsilon最小值发生在第10、第11交汇处,CLL模型的Epsilon最小值发生在第10、第11交汇处。
至此,我们使用了未经转换的三个拟合方法、经B-C转换后的三个拟合方法与Piecewise方法,为了选出效果最佳的方法,我们比较整体的H-L统计量(见表6)。结果显示B-C转换具有一定的改进效果,但Piecewise模型的改进效果更为明显,整体是最佳的。
三是重新划分等级。首先需要对PD序列进行排序并确定分割点,最终使得分值都归整于一个标准的评级系统。为了简约,我们并不采用主流的AAA-C的评级符号体系,而是直接使用C加数值的形式,每个数值将代表一个评级等级,数值大小表示信用风险水平高低。具体分割需要使用最优化算法,即该分割方式能使某个等级的平均违约概率PD尽可能趋近于目标违约率Target PD。Target PD采用穆迪一年期平均累积违约率,主要考虑到三点:第一,穆迪是信用评级的创始者;第二,穆迪的违约率曲线相当平滑;第三,穆迪投机级部分也有对应违约率值,而标普和惠誉没有。这里还蕴含了违约率曲线的一个方向:随着违约事件的持续积累,中国间断、跳跃的违约率曲线将会不断向平滑的三大评级机构违约曲线靠近,这并不意味着经济环境趋同或者企业经营的趋同,而是概率分布使然。
通过前文的比较发现,Piecewise-CLL是最优拟合模型,因此我们使用的PD是该拟合方法的回归结果。但由于数据限制(主要是下限),PD将不能充分匹配Target PD,即趋近于0端的数据部分无法分割形成穆迪的特定目标违约率。为解决这个问题,本文先用模拟方法延展PD。
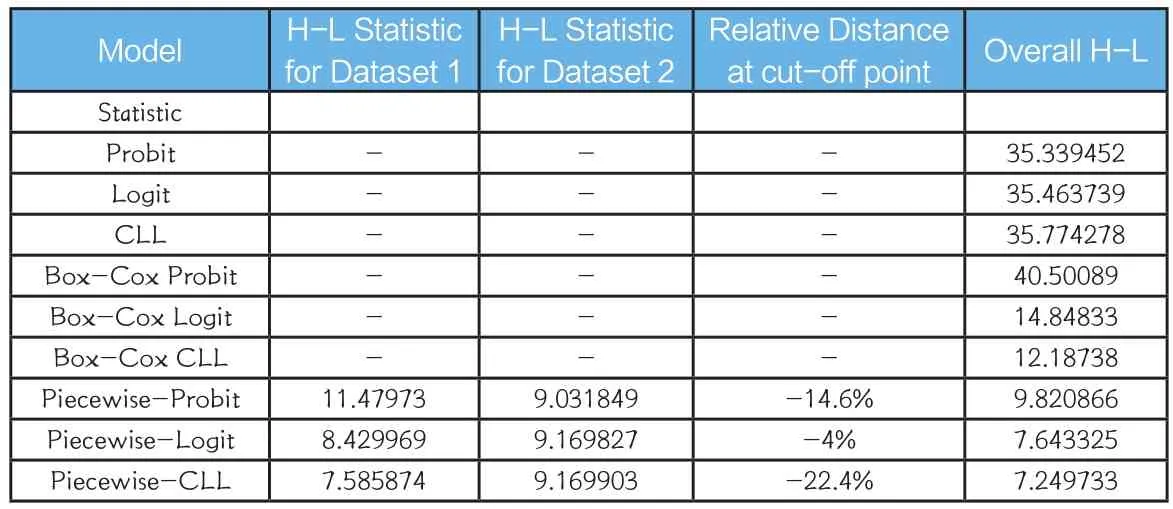
表6 各拟合模型H-L统计量值
无论是PD还是Target PD,数据特征上都呈现出类似“L”的曲线形态,这与经济现实和符号设置相呼应:投机级违约率将显著高于投资级,最高信用级别意味着信用风险非常小,各等级整体存在一定偏度,因此判断PD可能符合某种分布形式。我们将样本的峰度和偏度(高阶矩)以及不同模型拟合后的概率分布通过Cullen&Frey图表示出来,匹配了几个形态近似的分布。其中 Normal、Uniform、Exponential、Logistic的偏度和峰度只对应图上的一个点;Gamma、Lognormal对应的偏度和峰度是一条直线;Beta对应的偏度和峰度是一块面积。由于从数据样本中估计得到的峰度和偏度值会有统计偏差,这里通过Bootstrapping方法重新抽样,来提取出峰度和偏度的可能分布。结果显示,最合适的分布是 Beta分布,即 B(α=0.34,β=11.96)覆盖了所有抽样点,同时Beta分布又是针对连续比例和概率的分布,符合PD的特征。
随后我们按照这个特定的Beta分布形式进行模拟,构造出与原PD类似分布的额外5000个样本,并与原样本放在一起。将扩展后的样本代入最优化算法中,求出与Target PD距离最短的分割点d(i),每个分割点的上限和下限就是内部评级等级的划分间距。使用Piecewise-CLL方法获得的PD,其与Target PD拟合性非常好,基本上只有C19、C18、C16有一定的误差偏离,其他均在95%置信范围内。值得注意的是,目前等级排序与外部评级符号的顺序是相反的,所以我们命名的时候也将其进行倒序处理,以期达到数值与其描述的信用风险水平方向一致。
通过一个实证例子实践了内部评级的具体构造流程,从公司财务指标开端,使用B-C转换方程和Piecewise-CLL模型进行拟合,通过最优化算法,将PD对应到特定等级范围内,即可获得一个描述公司信用风险水平的对应等级(C1~C19),等级排序也意味着信用风险从低到高的排序。这个内部评级等级相较于外部评级来说,由于其特殊的构造方式,能更好地描述违约率和信用风险状况。接下来本文将使用两个测度方法评判内部评级体系的有效性和经济价值。
四、内部评级体系有效性测度
本文构造并运用了一个内部评级体系,找到了适合目前中国数据的最佳拟合方法,以及最优等级分割点。内部评级形成的等级体系不仅能像外部评级一样,通过有顺序的数值排列出被评方信用风险大小,还能通过一种未来趋近的形式(即与穆迪的最优化过程)更好地描述样本公司未来一年内的违约率水平。从这个层面来看,内部评级应比外部评级具有更高的有效性,具有一定的经济价值,本文也将从信用利差和组合收益两个角度进行测度。
(一)信用利差测度
关于信用评级的有效性,许多学者使用信用利差进行评判,利差同时还是实务界研究信用风险的关键指标。信用利差指信用债收益率与市场无风险收益率之间的差值,是信用债相对于无风险利率的风险补偿,也即投资者承担的违约风险补偿。许多学者研究均表明,预期违约损失、流动性溢价、其他风险溢价对信用利差具有良好的解释力(Lando and Skodeberg,2002;Amato and Remolona,2003)。与违约风险相关的因素影响预期违约损失,这主要是通过评级差异体现。中国由于实质性违约仍较少,违约风险显著影响信用利差的时期并不多,但一旦发生违约,对信用利差的冲击幅度要远远超过其他负面因素的影响。所以当违约风险集中到来时,风险溢价会显著提升、评级利差会显著扩大,而且风险溢价的波动幅度可能远大于实际违约率的波幅。
因此信用利差的决定因素中,信用风险溢价可以说是最主要的因素,而信用评级是信用风险的核心代理指标,评级与违约率呈单调关系,并且随着信用评级降低,违约率的均值和标准差都呈指数递增。我们从利差角度测试信用评级的有效性,即分别考虑内部评级与外部评级,将两者利差与信用评级的拟合程度(MSE)进行对比,MSE更小意味着该评级体系的评级结果能更好地描述信用风险,评级有效性更强,信评将具有更高的经济价值。
信用利差测度采用的检验模型如下式所示:
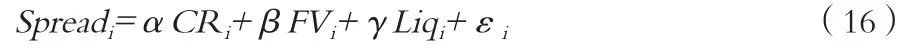
其中,信用利差Spreadi=Ri-Rf ,Ri为个券的收益率,Rf采用同期限国债到期收益率。信用评级CRi我们分别用外部评级CRiexternal与内部评级CRiinternal进行回归。外部评级直接采用评级机构给与的评级等级,按照前述的赋值方法赋分(AAA~C→0~19),内部评级则是前文所得的评级等级(C1~C19 → 1~19);FVi为债券面值;Liqi为流动性指标,采用的是2016年期间个券成交金额的对数值。样本仍为前文所述的银行间市场的短期融资券、中期票据、企业债数据,回归之后我们比较两者的MSE,其余数据从Wind数据库整理而来,回归结果如表7所示。
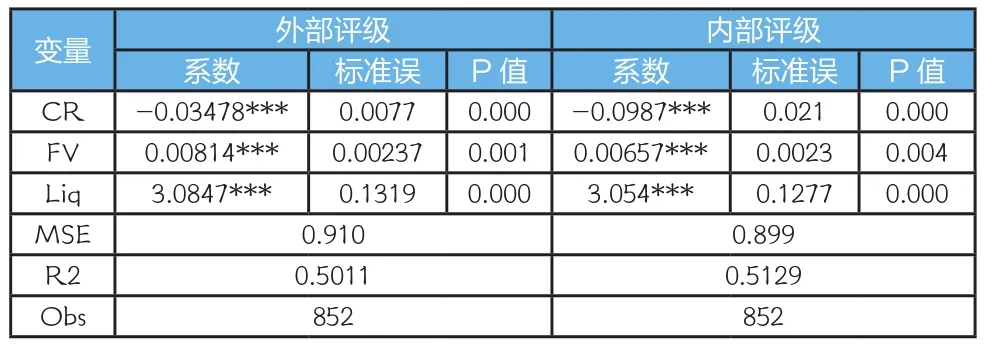
表7 信用利差有效性测度
MSEinternal<MSEexternal,即内部评级有效性高于外部评级;
MSEinternal>MSEexternal,即内部评级有效性低于外部评级。
结果显示,各主要变量回归系数均显著,且符号与预期一致。我们还进行了稳健性测试,将Rf设置为同期限国债的发行利率,结果也并未发生太大改变,这里不再进行展示。可以发现,使用内部评级体系之后,拟合误差MSE更小,评级结果对信用利差的解释度上升,支持内部评级体系在有效性方面具有改进的结论。从利差角度看,内部评级具有一定的经济价值。
(二)组合收益测度
Jankowisch et al(2007)构造了一个评级经济价值模型,模型区分了不同消费者的弹性系数,在一期竞争框架测度了逆向选择效应,通过组合收益率的高低进行评判,很适合组群角度的改进测试。内部评级最优化过程即为组群设置过程,适合Jankowisch提出的组合收益有效性测度法。本文将采用这个方法对内部评级有效性进行再检验。
与信用利差测度所不同的是,组合收益测度只聚焦内部评级,不作对比分析,旨在量化内部信用评级体系带来的经济表现损益额。通过研究逆向选择效应,即真实信用水平高于评级等级的发债公司将会离开,留下的是真实信用水平低于评级等级的发债公司,结合逆向选择后的组合溢价情况来判断评级的有效性和经济价值。
由于Probit模型并不能满足数量模拟所采用的分布形式(Probit峰值部分靠近1,而不是0),并考虑H-L统计量的大小,我们只选用了B-C转换后的CLL方法以及Piecewise-CLL方法的PD代入到组合收益模型中,同时令实际PD为上述Target PD。参照Jankowitsch的数量模拟结果,选取r=3%、违约损失率LGD=45%。弹性系数α⑦α为弹性系数,当α→0时,所有发债公司将不会选择离开,当α→∞时,所有被高估PD的发债公司将会选择离开。我们分别选用α=1、5、10、15进行验证,结果如表8所示。
结果显示,总平均收益率基本在r=3%附近,根据r的定义式可知,内部评级得出的PD应趋近真实PD值,投资者基本上都能获取一个近似r的收益;弹性系数α对收益率具有显著影响,随着α的升高,组合期望收益率下降,甚至会使组合期望收益率小于基准r;内部评级体系指出Piecewise-CLL为最佳拟合模型,但是只有在弹性系数α较小的时候,Piecewise结果才优于CLL模型,内部评级的组合收益率才会出现正的溢价。α较小意味着所有发债公司将不会选择离开,而这较符合目前中国评级市场的现状,即严控评级牌照下四大评级机构寡头垄断的卖方市场格局,对于内部评级我们同样进行此推演,因此认为市场现实就是α较小的局面,依此可见,内部评级在组合收益角度确实有显著的改进效果。
可见,相较于外部评级而言,本文构造的内部评级体系有效性得到了改进,具有一定的经济价值。通过直接信用利差的拟合优度测度以及组合收益的溢价测度,均支持此观点。
五、结论与政策启示
(一)研究结论
基于中国信用评级市场现状和存在的问题,本文解剖了外部评级体系,构造了能够将公司对应得分值转换为一个通用评级等级的内部评级体系。具体来说构造过程包含三个步骤:得分值的获取以及DR的计算、得分值的转换以及拟合、最优算法以及分割点的确立。本文还将该内部评级运用到了一个具体实证例子中,并验证了内部评级的有效性和经济价值,得出以下几个主要结论。
1.现有的评级体系是一种“最坏打算”的预测,即在过去的基础上对未来的预期。通过定性和定量两个部分来分析发债公司,能够得出被评方未来违约率水平或信用风险水平的结论。定量部分在分析中较为重要,主成分分析法有助于提炼核心影响因子,无论是外部评级还是内部评级,发债公司数据是基本切入点和核心关注点。
2.内部评级体系同样基于公司过去的数据来预测未来,但同时还纳入了过去违约率的情况,这是外部评级不具有的。评级等级不仅可以描述未来违约率水平,还直接进行拟合获得概率分布PD。这种进一步将评级等级与违约率挂钩的方法,对于不断成熟、违约事件不断积累的中国债券市场而言,是很好的操作方法。
3.使用B-C转换方程能提高信用评估模型的拟合效果,但Piecewise模型的改进效果最佳。对于目前中国评级市场而言,Piecewise-CLL是最佳的风险评估模型。
4.中国目前违约率曲线仍不够完善,三大评级机构的平均累积违约率数据将是我们的重要参考,这是评级符号最初定义和概率分布的使然。此外,本文发现,拟合的PD更倾向于服从特定的Beta分布。
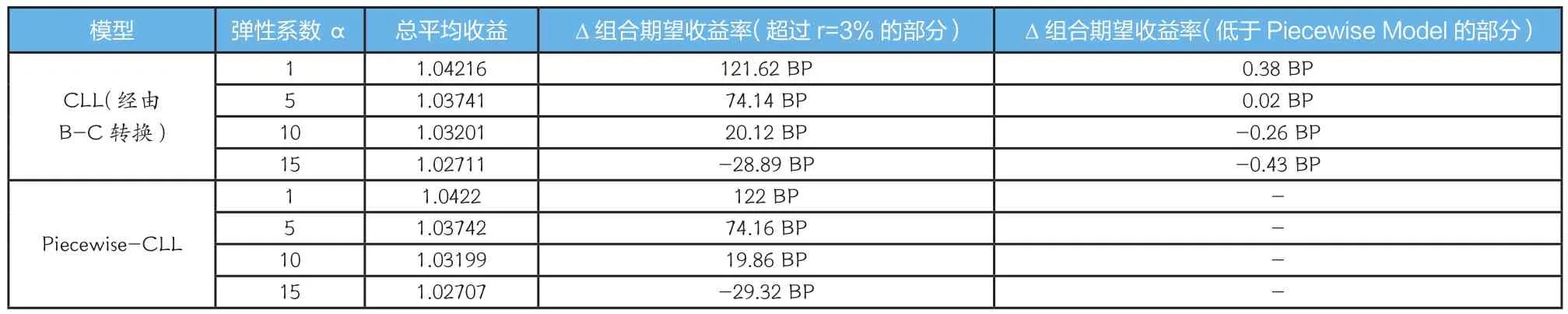
表8 组合收益测度
5.本文构造的内部评级体系有效性得到改进,展现出一定的经济价值。通过分析内外部评级信用利差和组合收益后,发现相较于外部评级,内部评级体系能更好地描述利差,其拟合偏差更小,并在现实经济条件下,有正的组群投资超额期望收益,这也体现了这种构造方法的科学性和应用价值。
(二)政策启示
1.中国评级市场仍处于发展阶段,信用评级的重要性不断提升,评级体系也应继续完善。对于评级精确性或是稳定性而言,最终都将归于违约率这个评判角度,可以说,违约率是检验评级质量的核心工具,评级有效性将决定评级市场质量和发展空间。一方面评级机构应从“刚性兑付”的思维中脱离出来,将违约率纳入分析框架中,不断完善和改进现有的评级体系;另一方面,业内应加速推动违约率统计标准的研究,调整评级等级迁移矩阵,为未来逐步积累违约数据奠定基础。本文提供的内部评级构造思路可以作为修缮外部评级的有效参考。
2.大公被监管处罚后,对国内信用评级有效性的批评增多,投资者开始关注有牌照的信用评级机构的评级质量,但目前只能通过探讨评级信息价值来验证评级有效性,违约率角度的评判仍无法开展。本文提出的内部评级构造方法,指明了一条间断、跳跃违约曲线向连续曲线转换的可行路径,未来可能的研究方向更多的是改进和应用。改进主要是关于得分值的处理方法,让其蕴含尽可能全的外部评级信息;应用上是区分不同信评机构的评级结果,将各机构外部评级等级与内部评级等级一一对应,通过观察内部评级等级的违约率分布,帮助投资者掌握预期违约值数据。此外,还能通过对存量券的内部评级转化,评判信评机构在过去评级业务开展中的规范性和合理性,从而在金融去杠杆环境下降低信用评级机构不当评级导致的踩雷事件风险。
猜你喜欢
工会博览(2022年8期)2022-06-30 12:19:30
辽宁经济(2017年6期)2017-07-12 09:27:35
股市动态分析(2016年22期)2016-12-27 17:06:46
当代经济(2016年26期)2016-06-15 20:27:18
新疆财经大学学报(2015年3期)2015-12-10 03:49:13
IT时代周刊(2015年8期)2015-11-11 05:50:22
特区实践与理论(2014年5期)2014-07-24 14:02:08
江苏卫生事业管理(2014年2期)2014-02-28 01:59:36
江苏卫生事业管理(2014年2期)2014-02-28 01:59:35
投资与理财(2009年8期)2009-11-16 02:48:40
