
基于多面部特征融合的驾驶员疲劳检测算法①
2018-10-24 11:06刘炜煌钱锦浩姚增伟焦新涛潘家辉
计算机系统应用 2018年10期
刘炜煌, 钱锦浩, 姚增伟, 焦新涛, 潘家辉
(华南师范大学 软件学院, 佛山 528225)
1 引言
根据美国国家公路交通安全管理局报告, 有22%到24%的交通事故是由驾驶员疲劳所引起的, 在驾驶途中驾驶员打瞌睡更会使发生车祸的风险提高4到6倍. 交通事故频发, 严重威胁到人们的生命财产安全, 因此, 驾驶员疲劳检测的研究有着重要意义.
目前已经有各种技术来测量驾驶员困倦. 这些技术可以大致分为三类:基于车辆的驾驶模式、基于司机的心理生理特征、基于计算机视觉技术. 驾驶员疲劳检测近年来一直是计算机视觉领域的一个活跃的研究课题. 相较于借助脑电设备采集脑电数据[1,2]进行驾驶员疲劳检测, 它为检测驾驶员状态提供了非侵入性的机制, 对比检测车辆运行状况、方向盘状况[3,4]的方法, 计算机视觉技术有更好的检测效果. 在现有的基于计算机视觉技术的驾驶员疲劳检测技术中, 有人通过模板匹配、几何特征定眼睛、嘴巴, 计算眨眼率和嘴部动作频率作为判断疲劳驾驶的依据[5], 也有人主要针对眼镜遮挡以及光照变化, 采取级联回归定位特征点,提出了一种更具鲁棒性的算法[6].
人脸包含了非常重要的信息. 作为驾驶员疲劳指标之一, 脸部动态地表示困倦的特征是打哈欠, 这种行为通常与大脑中缺氧有关. 在这种情况下, 人类的自然反应就是张大嘴巴, 试图呼吸更多的氧气, 这是可以用作疲劳预警的一个面部特征. 另一个面部特征是眨眼率, 眨眼率表示一段时间内眨眼的次数. 在昏昏欲睡的状态下, 一个人的眨眼率会改变, 这个特征可以用来表示疲劳水平.
基于计算机视觉技术的驾驶员疲劳检测是通过安装在仪表板上或镜子下方的低成本摄像头获得驾驶员图像, 包含驾驶员的脸部, 身体的上部, 手部, 座椅的后部或车辆的其他内部部件, 从中获取重要信息如人脸等进行判断.
本文提出了一种使用多任务级联卷积网络(Multi-Task Cascaded Convolutional Networks, MTCNN)提取嘴部、左眼区域, 结合嘴部、左眼区域的光流图, 使用卷积神经网络(Convolutional Neural Network, CNN)提取特征进行驾驶员疲劳检测的方法, 在NTHU-DDD数据集上取得了不俗的效果.
2 人脸检测与关键点定位
真实驾驶视频中的驾驶员嗜睡检测是具有挑战性的, 因为人脸可能受到许多因素的影响, 包括性别、面部姿势、面部表情、光照条件等, 但是车内低成本摄像头只能拍摄低分辨率视频, 因此需要一个高性能的人脸检测器. 即使有了特定的脸部, 定位嘴部、眼部区域也是非常重要的, 这些区域是驾驶员疲劳的面部特征重要区域.
基于人脸正脸的Haar特征的AdaBoost人脸检测算法[7]在实际复杂多变的环境下效果并不好, 而且无法确定眼部、嘴部区域. MTCNN[8]被称为最快和最精确的人脸检测器之一. 利用级联结构, MTCNN可以实现联合高速化的人脸检测和对齐. 作为脸部检测和对齐的结果, MTCNN获得了脸部边界坐标和包含左眼, 右眼, 鼻子, 左唇端和右唇端的位置的五个界标点. 本文使用MTCNN进行人脸检测和关键点对齐任务
MTCNN由3个网络结构组成(P-Net, R-Net, ONet), 当给定一张照片的时候, 将其缩放到不同尺度形成图像金字塔, 以达到尺度不变. 第一阶段, 浅层的CNN快速产生候选窗体;第二阶段, 通过更复杂的CNN筛选候选窗体, 丢弃大量的重叠窗体;第三阶段,使用更加强大的CNN, 实现候选窗体去留, 同时显示五个面部关键点定位.
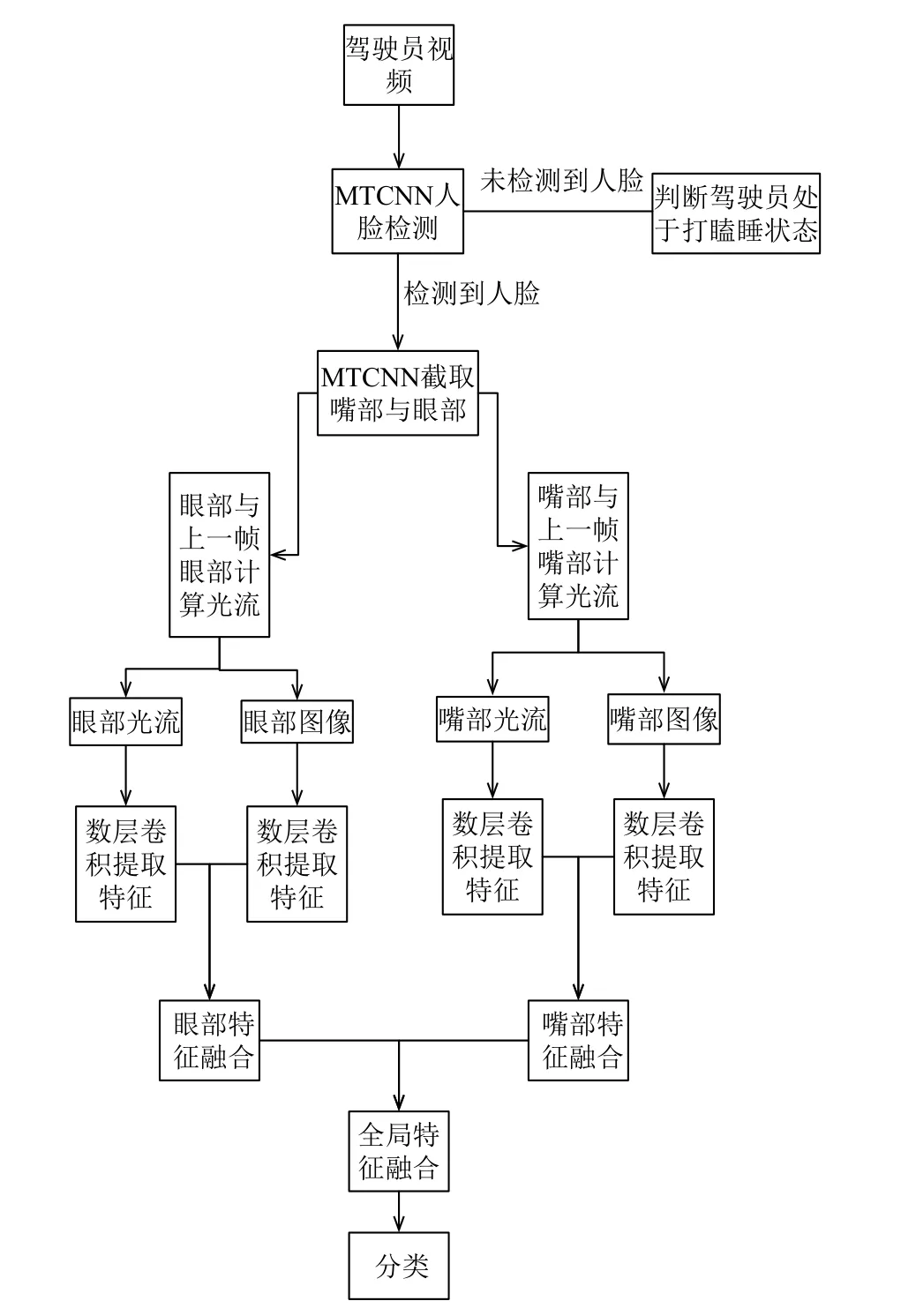
图1 本文的算法流程图
Proposal Network (P-Net):该网络结构主要获得了人脸区域的候选窗口和边界框的回归向量. 并用该边界框做回归, 对候选窗口进行校准, 然后通过非极大值抑制来合并高度重叠的候选框.
Refine Network (R-Net):该网络结构还是通过边界框回归和非极大值抑制来去掉假阳性区域, 但是是由于该网络结构和P-Net网络结构有差异, 多了一个全连接层, 所以会取得更好的抑制假阳性的作用.
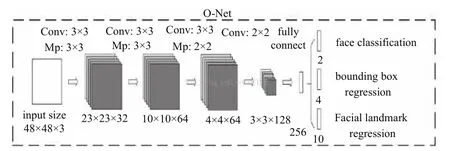
图4 O-Net
相比于基于局部区域的卷积神经网络(Regionbased Convolutional Neural Network, RCNN)系列通用检测方法, MTCNN更加针对人脸检测这一专门的任务, 速度和精度都有足够的提升.
只确定出关键点的坐标是不够的, 需要确定眼部、嘴部区域. 人脸面部器官的分布遵循一定的规律.根据“三庭五眼”规律, 人脸横向分为三个等分, 额头到眉毛是上庭, 眉毛到鼻头是中庭, 鼻头到下巴是下庭;人脸纵向分为五个等份, 以一个眼睛长度为一等份, 两眼间距为一等分, 眼睛到太阳穴也是一个等分. 由此可知, 眼睛宽度与嘴巴宽度大致相等.
考虑到嘴部、眼部在打哈欠、眨眼等动作时大小会在一定范围内变化, 本文以眼部坐标为中心、左右唇端距离为长度, 确定一个矩形框, 作为眼部区域;以左唇端、右唇端中点为中心、左右唇端距离为长度,确定一个矩形框, 作为嘴部区域.
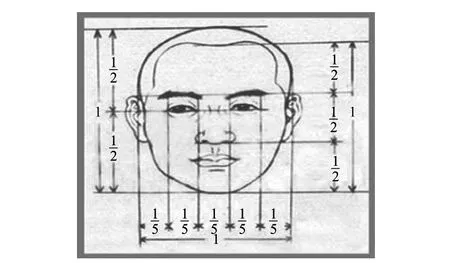
图5 三庭五眼

图6 MTCNN检测人脸与关键点定位
3 光流计算
作为驾驶员疲劳的指标, 打哈欠、眨眼等并不是一种静态状态, 而是一种动态动作, 因此只有静态的图像是不够的. 光流是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系, 包含了连续帧之间的动态信息. 不同于使用长短时记忆网络(Long Short Term Memory Network, LSTM)、3D卷积神经网络(3D Convolutional Neural Networks, 3DCNN)这类使用连续帧进行动作识别, 本文使用光流图中包含的动态信息代替连续帧所提供的动态信息. 本文将静态信息与动态信息中的特征融合, 相较于只使用静态图像, 可以更好地进行驾驶员疲劳检测.
真实的三维空间中, 描述物体运动状态的物理概念是运动场. 在计算机视觉的空间中, 计算机所接收到的信号往往是二维图片信息. 由于缺少了一个维度的信息, 所以其不再适用以运动场描述. 光流场就是用于描述三维空间中的运动物体表现到二维图像中, 所反映出的像素点的运动向量场.
光流是空间运动物体在观察成像平面上的像素运动的瞬时速度, 是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系, 从而计算出相邻帧之间物体的运动信息的一种方法. 假设每一个时刻均有一个向量集合 (x,y,t), 表示指定坐标(x,y)在t点的瞬时速度. 设I(x,y,t)为t时刻(x,y)点的像素亮度, 在很短的时间∆t内,x和y分别增加∆x,∆y, 可得:
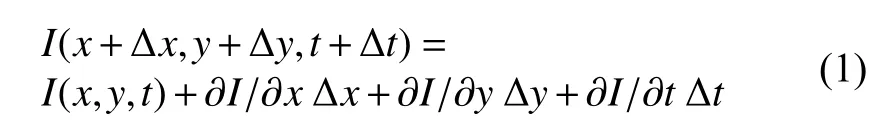
同时, 考虑到两帧相邻图像的位移足够短, 即:
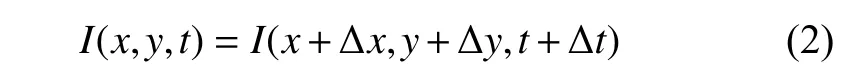
因此可得:
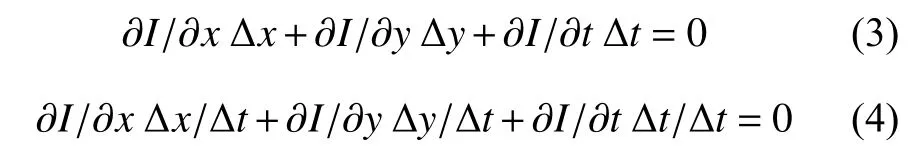
因:

最终可得出结论:
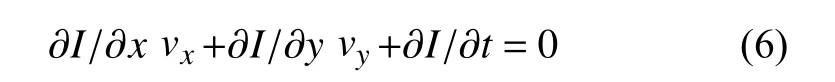
这里的vx,vy是x和y的速率, 或称为I(x,y,t)的光流.
Farneback算法是一种计算稠密光流的方法. 它首先用二次多项式来逼近两个帧的每个邻域, 这可以用多项式展开变换来有效地完成, 然后通过观察一个精确的多项式如何在平移下进行变换, 从多项式展开系数中导出一个估算光流的方法. 通过这个稠密光流,可以进行像素级别的图像配准, 所以其配准后的效果也明显优于稀疏光流配准的效果.
在汽车行驶途中, 由于摄像头是固定在车上的, 驾驶员脸部光流是由场景中驾驶员脸部运动所产生的,本文通过Farneback算法计算前后两帧眼部、嘴部的稠密光流反映驾驶员脸部动态变化.
图7中, (a)、(b)是视频中连续的两帧, 视频中驾驶员正在打哈欠;(c)表示位移矢量场的水平分量;(d)表示位移矢量场的垂直分量;(e)是使用Farneback光流算法计算出的稠密光流的特写.
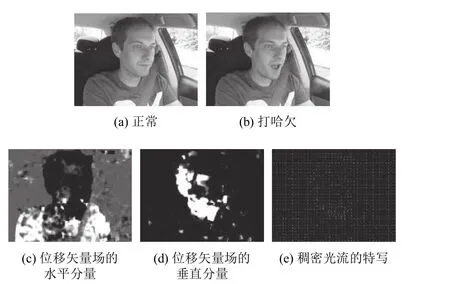
图7 Farneback光流计算相关图像
4 疲劳检测
CNN避免了对图像的复杂前期预处理, 可以直接输入原始图像, 以其局部连接和权值共享的特殊结构提取特征, 在语音识别和图像处理方面有独特的优越性.
视频可以分成空间与时间两个部分, 空间部分指独立帧的表面信息, 关于物体、场景等;而时间部分信息指帧与帧之间的光流, 携带着帧与帧之间的运动信息. 参考文献[10]所提出的网络结构由两个深度网络组成, 分别处理时间与空间的维度. 将视频分帧送入第一个卷积神经网络进行训练来提取静态特征, 同时将从视频中提取出的光流图送进另外一个卷积神经网络来提取动态特征. 最终将两个网络Softmax层输出的分数进行一个融合.
由于在自然状态下, 人的左眼和右眼的运动状态是一致的, 因此参考文献[11]提出了一种只将人脸的嘴部区域与左眼区域输入进网络进行驾驶员嗜睡检测的算法. 与输入人脸相比, 这个算法不仅简化了输入, 而且取得了更好的效果.
本文的算法首先对驾驶员进行人脸检测.MTCNN的三个网络均设置了一个阈值, 这个阈值代表非极大值抑制中的人脸候选窗口的重叠程度. 在设置严格的阈值的情况下, MTCNN在驾驶员低头, 即嘴部未出现的情况下不会检测到人脸. 如果MTCNN未检测到人脸, 则判断驾驶员处于打瞌睡状态. 如果检测到人脸, 则将左眼、嘴部区域进行截取, 送入疲劳检测网络, 结合眼部、嘴部光流图, 判断驾驶员在非打瞌睡状态的时候, 是处于普通、讲话还是打哈欠状态. 不同于使用LSTM、3DCNN从视频上截取的连续帧来进行动作识别, 本文使用CNN对原始图像提取静态特征、对光流图提取动态特征, 对一个短时间的动作变化进行分类.
疲劳检测网络包含四个子网, 第一个子网是左眼光流特征提取子网, 第二个子网是左眼特征提取子网,第三个子网是嘴部光流特征提取子网, 第四个子网是嘴部特征提取子网. 经过嘴部、眼部检测后得到的嘴部、左眼区域和经过计算得到的嘴部光流图、左眼光流图对应输入进四个子网, 经过数层卷积、池化后, 首先将左眼与左眼光流图子网融合, 得到进一步的左眼区域特征, 再将嘴部与嘴部光流图子网融合, 得到进一步的嘴部区域特征, 然后融合后的两个子网再融合输入进全连接层, 得到全局区域的特征, 经过降维, 再输入Softmax层进行分类, 得到最终结果. 为了避免过拟合, 在每个卷积层添加了L2正则项, 在全连接层前添加了Dropout层.
5 实验结果及分析
5.1 NTHU-DDD数据集
NTHU-DDD数据集是台湾国立清华大学所开发的数据集, 被用于2016年亚洲计算机视觉会议的视频驾驶员瞌睡检测国际研讨会. 数据集在模拟驾驶场景下使用主动红外照明来采集正常驾驶, 打哈欠, 瞌睡、讲话等各种视频数据, 整个数据集(包括训练、验证、测试数据集)包含36个不同种族的戴/不戴眼镜、在白天/夜晚的照明条件下的数据. 数据集包含了很丰富的各种情景下的正常、瞌睡、讲话、打哈欠的人脸数据, 可以提高本文算法的鲁棒性.
本文将数据集分为两部分. 一部分视频具有打瞌睡动作与正常动作, 用于打瞌睡检测;一部分视频有正常、讲话、打哈欠动作, 用于疲劳检测网络. 输入进两个网络的图片都先压缩成50×50大小.
图9中四幅示例图像均来自于实验数据, (a)是打瞌睡图像, (b)是正常图像, (c)是打哈欠图像, (d)是讲话图像.
5.2 实验结果
表1是几种不同的方法进行打瞌睡检测的对比实验结果, 可以看出, 采用文献[10]的方法, 使用全局图像结合光流图进行检测的效果并不好. 不对图像进行预处理, 直接输入全局图像, 输入图像会包含许多无用的信息, 这会带来噪声. 人打瞌睡的特征最重要的表现就是头会低下来, 而实际摄像头拍摄出来的640×480图像中驾驶员脸部只占200×150左右, 进行压缩后送入CNN的图像中携带的人脸信息将会更少, 将很难从中学习到特征. 直接以MTCNN是否检测到人脸作为打瞌睡检测的标准效果更好. 从表 2实验结果可知, 在测试集中, 大部分正常状态都可以被正确检测, 相对来说打瞌睡的检测正确率稍低, 这是因为在测试集中, 有些稍稍低头的状态也被标记为打瞌睡, 这种状况是比较难以识别的.
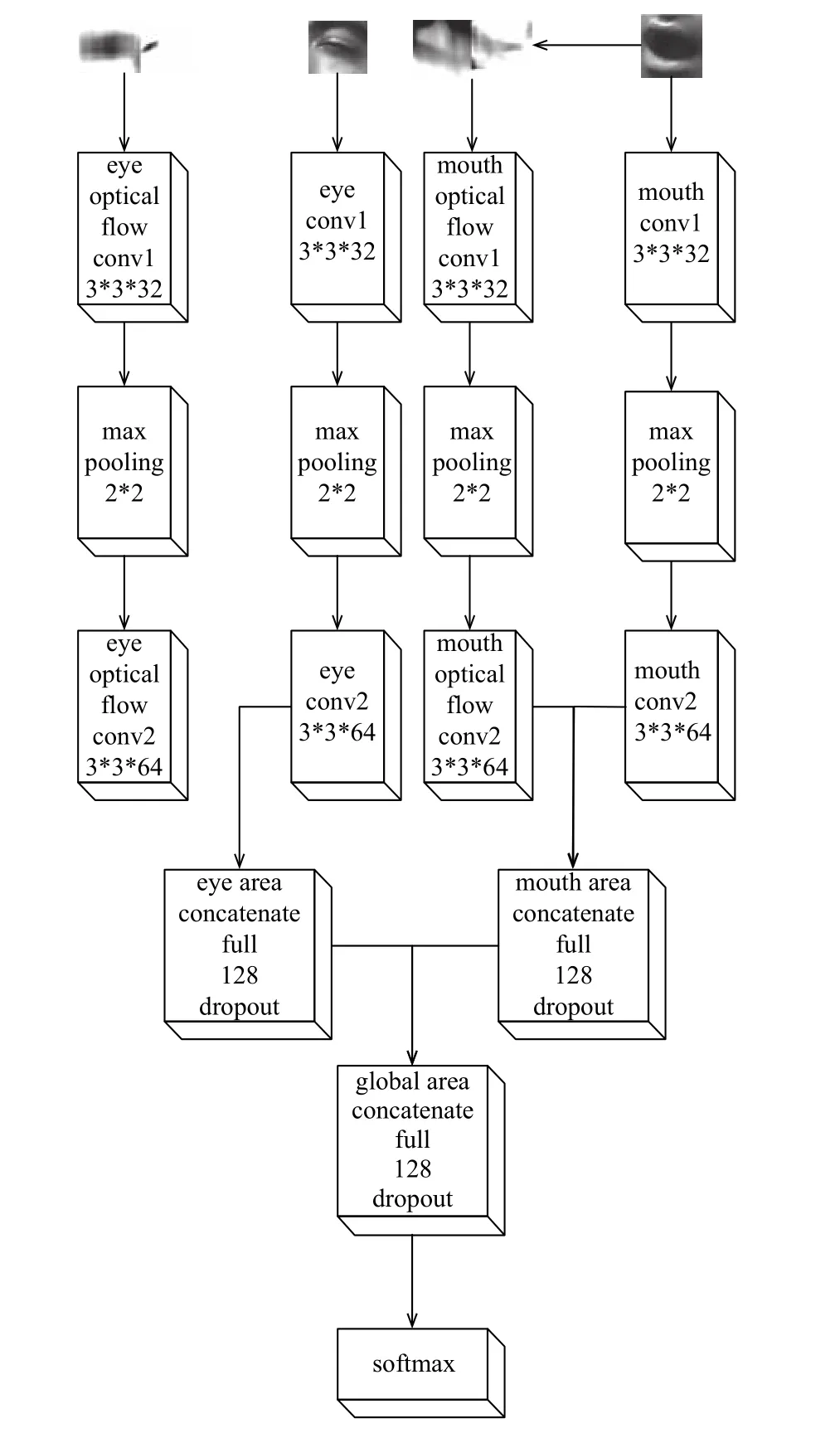
图8 疲劳检测网络
表3是使用两种不同方法进行疲劳检测的对比实验结果. 采用参考文献[11]的方法, 使用嘴部以及左眼作为网络的输入, 没有使用到帧与帧之间的动态信息,效果不如结合光流图的算法好. 对于一个短时间的动作变化识别任务, 仅仅使用静态图像是不够准确的, 如打哈欠与讲话时, 人都是张着嘴的, 静态图像无差异,而光流图则能体现差异. 结合包含动态信息的光流图可以获得更好地效果. 从表 4的实验结果可知, 讲话和打哈欠这两种在静态图像中很相似的图像, 结合光流图后可以有很好的区别效果.

图9 数据集示例图像

表1 打瞌睡检测准确率对比实验(%)

图10 稍稍低头的打瞌睡图像

表3 疲劳检测对比实验(%)
6 结束语
本文提出了一种基于多面部特征融合的驾驶员嗜睡检测技术, 不仅避免了对驾驶员身体造成侵入性, 准确率高, 而且将卷积神经网络与光流图结合应用到视频理解中, 取得了不俗的效果. 从实验结果可以看出,本文的算法具有更高的鲁棒性和准确率, 对于各种不同情景如不同肤色、有无眼镜、不同光照等均适用,尤其可以很好地区分在静态图像中相似的讲话、打哈欠两种动作.

表4 使用左眼、嘴部结合光流图测试疲劳检测结果
猜你喜欢
导航定位学报(2022年5期)2022-10-13
导航定位与授时(2022年4期)2022-08-05
小型微型计算机系统(2021年12期)2021-12-08
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
计算机应用(2020年10期)2020-10-18
导航定位与授时(2020年4期)2020-07-29
中国新通信(2019年21期)2019-03-30
动漫星空(2018年9期)2018-10-26
航天器工程(2018年2期)2018-04-24
