
基于LSTM的短时交通流预测研究
2018-10-22 01:48曹博高茂庭
现代计算机 2018年25期
曹博,高茂庭
(上海海事大学信息工程学院,上海 201306)
0 引言
交通流预测主要是对交通量的相关参数进行预测。交通量也叫做交通流量,是指在指定时间段内,通过道路某一地点、某一断面或某一车道的交通实体数[1]。在智能交通系统(Intelligent Transportation Systems,ITS)领域[2],交通控制与诱导系统是ITS研究的热门核心课题,而实现交通诱导的关键是实时准确地预测交通流。即利用现有道路的实时和历史交通流数据,通过建立适合的模型对下一个时段的交通流进行预测。交通流预测分为短期预测、中期预测和长期预测,分别服务于不同的研究领域。而短时交通流预测能预测未来较短时间内交通流状态信息,可满足城市交通控制系统对实时性及准确性的要求,从而得出正确的控制策略,缓解交通堵塞,减少机动车废气排放,降低交通事故发生率。
在短时交通流预测研究中,有两类不同的数据驱动预测方法被频繁使用:一类是基于传统统计理论的方法,另一类是基于神经网络的方法[3]。基于统计的方法主要有卡尔曼滤波模型[4]、时间序列模型[5]、贝叶斯网络[6]和马尔可夫链[7]。它们假设未来预测的数据与过去的数据有相同的特性。,其方法理论简单、容易理解。但是,基于统计的方法大部分是基于线性的,而交通流变化具有随机性和非线性的特点,这使得模型的性能变差。随着深度学习在语音、图像和自然语言处理等研究领域的广泛应用,基于神经网络的方法在交通大数据挖掘方面体现出越来越强大的应用价值。Huang等人(2014)[8]和 Lv等人(2015)[9]分别使用了深度信念网络(Deep Belief Networks,DBN)和堆栈式自编码器(Stacked Auto-Encoder,SAE)来预测短时交通流。但是,以上方法都需要预定义历史输入数据的长度,不能自动决定最优的时间间隔,而且由于全连接神经网络里的每一个神经元都与它上一层的神经元连接,其计算代价高昂。
为了获得更高的短时交通流预测精度,本文提出一种叫做LSTM的短时交通流预测模型。LSTM不仅能更有效地处理交通流的非线性和随机性,而且在解决时间序列预测的长时间依赖问题中展示了优越的能力。LSTM能“记住”距当前时间点较远的历史信息,而且能自动决定时间序列数据的最优时间间隔。实验结果表明,LSTM模型在短时交通流预测中取得了更高的精确度。
1 基于LSTM的短时交通流预测模型
在众多短时交通流预测方法中,神经网络因其处理高维数据的优势,灵活的模型结构,强大的学习和泛化能力受到越来越多的关注。一般,神经网络可分为两种类型,分别为前馈神经网络(Feed Forward Neural Network,FFNN)和循环神经网络(Recurrent Neural Net⁃work,RNN)。两者都能应用到短时交通流预测中,其精确度主要受到交通流时间序列数据的历史输入的长度的影响。对于传统的FFNN来说,其没有时间序列观念,不能记忆早期历史输入信息,也不能决定输入的最优时间跨度。当把FFNN应用到短时交通流预测上时,需要手动确定输入的时间长度。而RNN是时间序列建模的有力工具之一。RNN之所以称为循环神经网络,是因为一个序列当前的输出与前面的输出也有关联,具体表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出[10]。RNN构建的网络会对历史时间点的信息进行记忆,并将记忆留下的信息应用到当前神经元的输出计算中。
对于短时交通流数据而言,同一路段的车流量在时间关系上并不是完全无关的。交通流量有复杂的历史依赖性,此刻的交通流状态与上一时刻的历史交通流状态有一定程度的关联,且可能导致下一时刻的交通流状态产生变化。因交通流时间序列呈现的这个特点,采用循环神经网络则是非常合适的选择。RNNs采用BPTT算法[11]作为训练算法,对于一般的RNN结构而言,其循环结构的特点容易造成梯度消失或梯度爆炸[12],从而使RNN丧失学习连接较远信息的能力。为了解决这个问题,Hochreiter和Schmidhuber提出了LSTM网络结构[13]。
LSTM RNN被认为是一种特殊形式的RNN,其结构由一个输入层、数个隐藏层和一个输出层组成。LSTM的关键在于记忆单元(memory cell),它能克服传统RNNs面临的梯度消失或梯度爆炸问题。如图1所示,LSTM主要包含三个门:一个输入门(input gate),一个遗忘门(forget gate),一个输出门(output gate),这三个门在激活函数的作用下,会产生0到1之间的数,用于把控门的开关。输入门决定了输入层信息如何传递到隐藏层的记忆模块;遗忘门决定了如何对当前时刻该记忆模块的历史信息进行保留;输出门决定了记忆模块的信息如何传递出去。鉴于交通流状态具有随着时间动态变化的特点,结合LSTMs在处理长期依赖方面的优势,可用LSTMs提取交通流里的时间模式信息。

图1 LSTM NN结构图
交通流历史输入序列可表示为X=(X1,X2…,XT)。对于q时刻,各站点的交通流则表示为其中,l1,…,ln代表一条高速公路上的n个站点。代表第n个站点在时刻q的交通流。本文中,交通流预测的目标就是根据[1,T]时间段内的历史流量信息来预测T+a时刻各站点的交通流,a为某个常数。X被作为LSTMs的输入,LSTMs的输出则表示为H=(H1,H2,…,HT),σ(∙)是sigmoid函数,σh(∙)是tanh函数。交通流的时间特征通过式(1)-式(6)迭代计算得出:
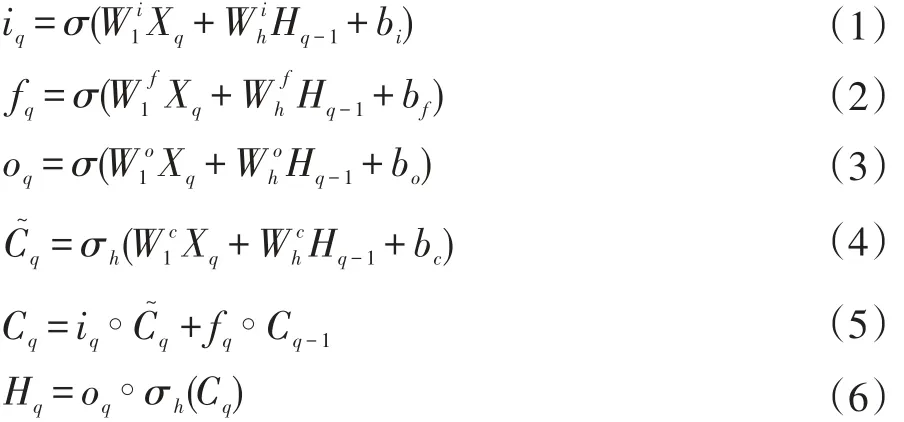
式(5)、式(6)中,“∘”代表向量之间的 Hadamard product。得到LSTMs的输出后,下一步是预测未来时刻的交通状态。HT被作为一个全连接层的输入。交通流的预测值可用式(7)计算,W2和b2分别代表LST⁃Ms的输出层和全连接层之间的权重和偏置,YT+a就是整个模型的输出,也即预测值。全连接层的目标函数是预测值和实际值之间均方误差的和。实验对整个模型进行端到端的训练。

式(7)中,YT+a代表T+a时刻的交通流预测值,a是一个常数,代表时刻T之后的某个时间点。
2 实验
2.1数据集
本文数据集来自美国加利福利亚州交通管理局的Caltrans Performance Measurement System(PeMS)。路段Route 16664:101S Downtown SF to Millbrae的交通流数据将被用来进行试验。该路段沿途共33个观测站点,起止日期从01/01/2017到07/15/2017。交通流数据每隔30秒采集一次,最后聚合成时间间隔为5分钟的聚合数据。根据先前的研究结果[14],5分钟的交通流数据更适合用来预测未来时刻的交通流,因为缺失数据只占整个数据集的一小部分。
对于缺失数据,本文采用相邻数据平均法来填补数据集中的缺失值,即以缺失数据的相邻数据的算术平均数代替。根据实际情况,交通流数据的最小值必定是0,而不可能是负数。观察历史数据,最大值不超过900。也就是说,正常情况下的短时交通流数据处于最小值和最大值之间,偏离这个区间的数据被称为非常规数据。对于非常规数据,可把它视作缺失值,仍然采用相邻数据平均法处理。
交通流数据随时间变化的幅度较大,某些时段比如凌晨的车流量为0,而某些时段比如早晨和傍晚的车流量能达到几百。为了消除数据大小差异给预测精度带来的影响,一般用归一化的方法对数据进行变换。本文用min-max标准化的方法对原始数据进行线性变换。经过归一化处理后,数据序列的相对大小并未改变,整体变化趋势也保持一致。应用归一化后的数据进行交通流预测,得到结果后采用反归一化再对预测值进行还原,最后得到最初量级的交通流数据。
本文数据被分为两个子集:前5个月的数据作为训练集,其他的数据作为测试集。
2.2建立实验
本文设置历史交通流信息的时间长度为8,预测范围为5分钟,即式(7)中T的大小为8,a为1。所以,本文的预测目标是根据前40分钟的历史交通流信息预测接下来5分钟内的车流量。
设置LSTM网络结构为1个输入层、2个隐藏层、1个输出层。在此基础上进行其他超参数的选择。隐藏层中,设置H=(H1,H2,…,HT)在第一个LSTM层中每个时间点的特征维度为64,而在第二个LSTM层中其每个时间点的特征维度为512。具体的模型参数如表1所示。
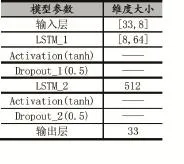
表1 LSTM模型参数
LSTM的训练基于RMSprop优化器[15],因其在RNN模型的训练中表现良好[16]。tanh作为激活函数被用在状态和输出上,目标函数为均方误差(MSE)。批处理数量(Batch Size)设置为64,迭代次数设置为20。Dropout层和早停法(Early Stopping)被用来防止过拟合。Dropout是深度学习模型中的正则化方法,它的原理是在训练过程中随机丢掉某些神经元,减少神经元之间的协同作用,提高模型的泛化能力。本文设置Dropout丢失率为50%。LSTM模型使用Keras深度学习框架构建,callback参数被用来实时保存模型结构、训练出来的权重及优化器状态。实验随机选取10%的训练数据作为验证集。
2.3结果和比较分析
实验中,选择SAEs[9]模型与LSTM模型作比较,并且两种模型都分别选取表现最好的一组。平均绝对误差(Mean Absolute Error,MAE)能很好地反映预测值误差的实际情况,均方根误差(Root Mean Squared Error,RMSE)可以评价数据与预测模型适应性,故实验采用MAE和RMSE比较交通流预测模型的性能:
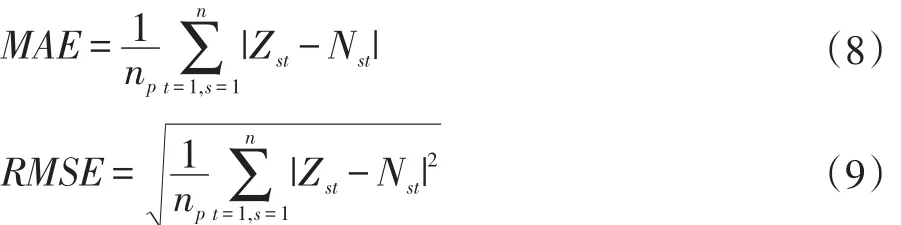
式(8)、式(9)中,Zst表示s站点在第t个时间间隔内的交通流的预测值,Nst代表相应的实际交通流,np是预测值的个数。LSTMs,SAEs模型的预测结果与真实值的比较分别如图2、3所示。
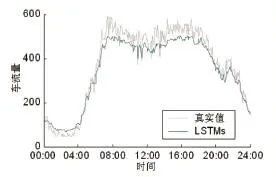
图2 LSTMs交通流预测结果
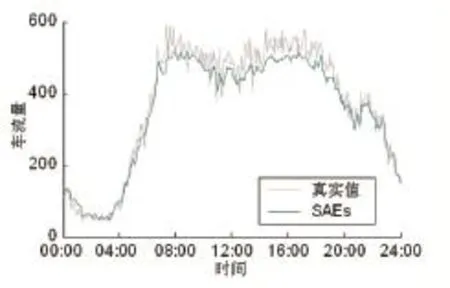
图3 SAEs交通流预测结果
从测试集中随机选取日期07/06/2017,并选择第17个站点在这一天中所有交通流数据从而得到图2、3的结果。从图2、3中可看出,LSTMs和SAEs模型都能正确反映交通流变化的大体趋势。两种模型在交通流处于低峰期时与真实情况吻合得较好,但在交通流高峰期时,两者与真实值相比都有一定差距。LSTMs与SAEs预测结果的比较如图4所示。
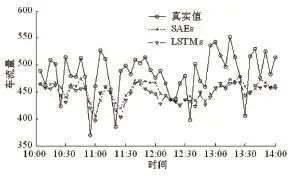
图4 LSTMs和SAEs预测结果比较
图 4 给出了 LSTMs、SAEs在 10:00 到 14:00 时间段内预测值与真实值的比较。从图4可看出,LSTMs和SAEs与真实值之间都有一定间隔,而两者预测值之间的间隔不大,说明LSTMs和SAEs的预测精度比较接近,在交通流高峰期11:00到12:00时间段内,LSTMs的表现比SAEs稍好。为了更准确反映LSTMs和SAEs预测结果的差异程度,表2给出了两种模型的结果比较。
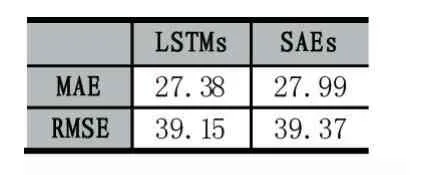
表2 两种模型的MAE和RMSE
从表2可看出,LSTMs的MAE为27.38,RMSE为39.15,而 SAEs的 MAE 为 27.99,RMSE 为 39.37,LST⁃Ms比 SAEs表现稍好。说明LSTMs和SAEs这种state-of-the-art方法一样,在短时交通流预测方面有不错的表现。而LSTMs模型处理时序数据时在一定程度上优于SAEs。
3 结语
本文提出了一种基于LSTM的短时交通流预测模型。LSTM模型考虑了交通流数据的时序特点,能记住输入数据的长期历史信息,并自动决定输入的最优的时间间隔,在短时交通流预测方面表现出了不错的预测能力。与SAEs在同一个数据集上进行的对比实验表明,LSTM取得了更好的预测效果。这表明LSTM模型在交通流预测应用的有效性。
但LSTM模型还有很多需要完善的地方。短时交通流数据蕴含时间特征,也包含空间特征。在空间层面,一条高速公路上的某个观测站点的交通流不仅受到其上下游交通流状况的影响,还受到相邻高速公路的交通流状况的影响。在短时交通流预测中,不能忽视交通流的空间依赖。另外,天气、交通事故、交通管制等因素也对短时交通流有重要影响。在未来的研究中,将进一步考虑这些因素,从而更准确地预测短时交通流。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
中国交通信息化(2022年5期)2022-07-23
现代电力(2022年2期)2022-05-23
今日农业(2021年19期)2022-01-12
电子产品世界(2021年6期)2021-02-10
中国现代医生(2020年2期)2020-04-09
电子制作(2019年19期)2019-11-23
计算机系统应用(2019年6期)2019-07-23
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2017年12期)2017-04-23
