
基于加权词向量和LSTM-CNN的微博文本分类研究
2018-10-22 01:48:40马远浩曾卫明石玉虎徐鹏
现代计算机 2018年25期
马远浩,曾卫明,石玉虎,徐鹏
(上海海事大学信息工程学院,上海201306)
0 引言
随着信息时代的来临,各种社交媒体得到了迅速发展。其中,微博作为一种通过关注机制分享简短实时信息的社交网络平台,越来越多的网民选择利用微博来发表自己的观点情感。由于微博文本内容的长度限定在140个字符以内,与传统的评论内容长度相差较大,内容简短,其原创性特别强。因此,对微博文本数据进行分析挖掘,从中发掘出用户的兴趣爱好、发现热点话题、以及开发个性化推荐系统都具有非常大的研究价值。然而,由于微博其庞大的数据信息量以及文本语言信息不规范性等原因,使得要从这些庞大的文本信息中去分析判断人们的情感态度变得非常困难,所以仅仅依靠传统的人工方法进行挖掘分析显然不够准确。因此,想要在最短的时间内挖掘出有价值的文本信息,就需要一些自动化的文本信息挖掘技术的帮助。其中,自然语言处理技术(NLP)是目前解决该类问题的重要途径,通过对微博上用户发表的评论进行分析,可从中判断出用户的主观情感倾向。
自上世纪50年代开始就已经开始了对文本分类的研究。Zhang等[1]利用One-hot Representation对文本进行向量化表示的基础上,借助支持向量机(Sup⁃port Vector Machine,SVM)和反向传播(Back Propaga⁃tion,BP)神经网络实现对文本的高效分类。Hinton等人[2]提出了Distributed Representation概念,通称词向量(Word Embedding)。龚静等人[3]利用改进的TF-IDF算法提取文本特征,并利用朴素贝叶斯分类器进行文本分类。豆孟寰[4]基于N-Gram统计语言模型对文本分类,N-Gram模型根据每个词出现在其前面n个词的概率来表示文本。Bengio等人[5]提出用神经网络来构建语言模型,一定程度上解决了N-Gram模型的问题。上述方法分析过程中对文本进行数值化表示时面临数据稀疏以及建模之间语义相似度较大等问题。
针对上述问题,本文首先利用Google提出的一个NLP工具Word2Vec进行微博文本词向量训练,同时通过TF-IDF模型对词向量进行加权赋值,判断出词语之间的重要程度。其次,对于输入样本数据的序列化,循环神经网络(Recurrent Neural Network,RNN)能够有效地对邻近位置信息进行整合。其中,RNN的子类LSTM(Long Short-Term Memory)模型是为了解决RNN的Gradient Vanish的问题所提出的。因此,本文在上述词向量的基础上,借助LSTM与CNN混合模型对微博文本内容进行自动选择特征,进而实现准确分类。
1 方法
1.1方法流程
首先,文本分类需要对数据集进行必要的预处理。然后,利用Word2Vec模型与TF-IDF模型进行词向量训练;最后,采用LSTM与CNN神经网络进行特征提取,最后用Softmax分类器进行分类预测。其分析流程图如图1所示。
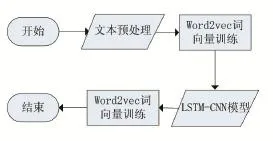
图1 方法流程图
1.2文本预处理
微博上的文本数据带有大量的噪声,例如不规范的字符、标点等,这些噪声会干扰我们对文本信息的挖掘,所以在文本分类前首先要将数据集进行预处理。
因为中文与英文不同,中文以字为单位,单独的字不能表达意思,因此对中文文本分类要进行分词处理。本文采用Python的结巴(Jieba)分词模块,以精确模式进行分词。中文停用词对文本研究没有太大价值,故需将文本中介词、代词、虚词等停用词以及特殊符号去除。
1.3词向量训练
Word2Vec是一款Google开源的词向量计算工具,通常采用CBOW和Skip-Gram两种模型。与传统的词向量相比,Word2Vec词向量的维度通常在100-300维之间,减少了计算的复杂度。
本文采用Skip-Gram模型,Skip-Gram与CBOW正相反,给定input word来预测上下文,而COBW是给定上下文,来预测input word。该模型包括三个层:输入层、投影层和输出层,如图2所示。
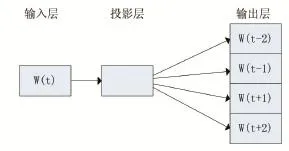
图2 Skip-Gram模型
Skip-Gram模型的训练目标就是使得下式的目标值最大:
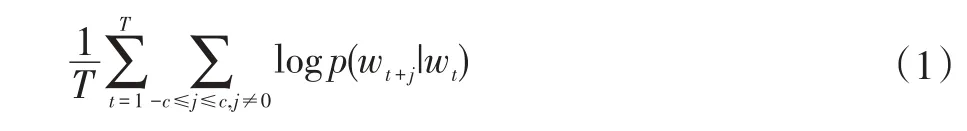
其中,c>0是窗口的大小,T是训练文本的大小。并利用梯度下降法对其进行优化。基本的Skip-gram模型计算条件概率如下式:

其中,vw和v′w分别是词w的输入和输出向量。
1.4 LSTM分类算法
LSTM是长短期记忆网络,是一种时间递归神经网络,属于RNN的一个变种,主要就是在它的算法中加入一个判断信息是否有用的“处理器”,这个结构被称为cell,通过精心设计的结构来去除或者增加信息到细胞状态的能力。如图3所示。
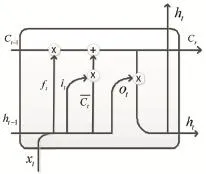
图3 LSTM cell结构
LSTM的第一步是决定我们要从细胞状态中扔掉哪些信息。该决定由一个叫做“遗忘门”的Sigmoid层控制。首先读取ht-1和xt,使用Sigmoid函数输出一个在0-1之间的数。0表示“完全舍弃”,1表示“完全保留”,ft的计算公式为:

式中σ表示sigmoid函数,Wf遗忘门权重,bf遗忘门偏置。
更新值为it,它决定我们要更新什么值。另一部分是tanh层创造了一个新的候选值向量Cˉt,该值会被加入到细胞状态中去。

式中σ为sigmoid函数,wi更新门权重,bi更新门偏置,tanh双曲正切函数,wc更新候选值,bc更新候选值偏置,候选值
最后将旧状态与ft相乘,丢弃我们确定要丢弃的信息,根据我们所需要的状态变化。

其中,Ct表示新状态。最后,我们决定最后的输出,公式如下所示:
式中wo更新输出值的权重,bc更新输出值偏置,ht最终确定输出的那部分。LSTM通过梯度下降法实现损失函数最小化的参数估计。
1.5 LSTM-CNN混合模型
为了有效提高微博文本分类的准确率,本文提出了一个LSTM-CNN的混合模型,模型结构如图4所示:
(1)卷积层
首先,卷积层接受大小为n×d的微博词向量特征矩阵X,矩阵X的每一行为句子中一个词的词向量。然后选取尺寸为m×d的卷积核w∈Rm×d对矩阵X进行卷积操作得到向量值vi。卷积过程如下式所示:

式中f表示ReLU(Rectified Linear Units)激活函数,m表示卷积计算滑动窗口大小,b为偏置项,Xi:i+m-1表示在X的第i行到第i+m-1行范围内抽取的局部特征。ReLU激活函数如下式所示:

(2)池化层
最大池化(max pooling)采用Pooling窗口中最大值作为采样值,能够有效的降低网络训练参数及模型的过拟合程度。因此,在完成卷积计算后采用最大池化的方法。
(3)Softmax层
最后将LSTM层的输出送入Softmax分类器进行分类,公式如下所示:

其中,p(y=i|x;θ)为样本x属于i类的概率。
2 实验结果分析
2.1实验数据
本文所采用的数据来自CSDN(https://www.csdn.net/)下载的微博文本数据,该数据集经过繁简转换、去重、去掉4字以下过短评论,形成最终的数据集。数据集提供了3000条已标注立场类别的训练数据,1000条已知立场标签的测试数据。数据集共分为五个描述主体,分别是:#春节放鞭炮,#深圳禁摩限电,#俄罗斯在叙利亚的反恐行动,#iPhone SE,#开放二胎。
2.2分类评价标准
为了评价本文提出的模型对分类结果的准确性,实验采用了常用的分类评价标准——精确率对模型进行检验,根据实验结果建立两分类结果混合矩阵如下表1所示:
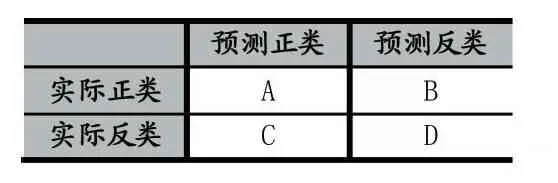
表1 两类分类结果混合矩阵
文本分类评价标准继承信息检索评价指标,一般采用精度(precision)、召回率(recall)、F-score和准确率(accuracy)。根据表(1)可得它们的计算公式如下:


实际应用中,通常使用precision和recall加权调和平均作为一个综合的评价标准,称之为F-score:
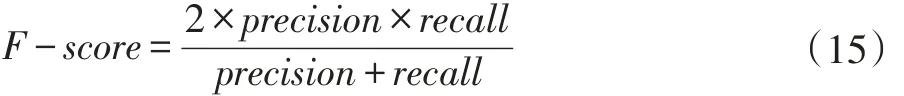
2.3实验结果
为了验证本文提出的LSTM-CNN混合模型的有效性,本文进行了四组实验,分别是基于Word2Vec和SVM,基于Word2Vec和LSTM,基于Word2Vec加权词向量和LSTM以及基于Word2Vec加权词向量和LSTM-CNN,得到了如表2所示的实验结果。
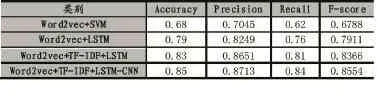
表2 实验结果
从表2中实验结果可知,相比于传统机器学习SVM,LSTM具有更高的准确率。而将Word2Vec词向量加权后准确率提高了3%左右。但是基于本文提出的LSTM-CNN混合模型要比LSTM分类效果更高。由此可以得到,基于Word2Vec与TF-IDF合并模型,可以很好地降低向量的维度和高稀疏性。然后利用LSTM-CNN混合模型对文本特征进行提取,进行微博文本分类具有良好的效果。
3 结语
本文的Word2Vec模型加上TF-IDF模型相比于传统模型,解决了传统向量空间模型的高维稀疏特征,还解决了传统模型所不具有的语义特征,但是因为Word2Vec模型无法识别词的权重,所以引入TF-IDF模型计算词向量的权重,结合两种模型,最后用LSTMCNN混合模型进行特征提取,最后利用Softmax分类器进行分类,取得了较好的结果。但是本文对数据的大小,数据的复杂性没有进行更深层次的研究,还有更多的影响因素影响文本分类的准确性。
猜你喜欢
汽车实用技术(2022年15期)2022-08-19 02:48:32
中国信息化(2022年5期)2022-06-13 11:12:49
作文大王·低年级(2022年3期)2022-03-19 18:09:52
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
小学生作文·小学低年级适用(2018年12期)2018-04-11 03:10:42
北京航空航天大学学报(2016年6期)2016-11-16 01:50:49
校园英语·下旬(2016年2期)2016-03-18 10:23:20
快乐作文·低年级(2014年10期)2015-01-14 23:43:55
