
基于相似重复记录的N-Gram算法的改进与应用
2018-10-22 01:48:46王旭东段敬温志坚楼颖稚陈伟孔德云黄豆豆
现代计算机 2018年25期
王旭东,段敬,温志坚,楼颖稚,陈伟,孔德云,黄豆豆
(1.国网山西省电力公司信息通信分公司,太原 030001;2.北京中电普华信息技术公司,北京 110000)
0 引言
随着大数据时代的快速发展,数据的质量问题无疑成为相关人士的研究重点之一。由于数据量特别庞大,导致人们在使用数据的过程中发现了诸多的质量问题,例如脏数据,其中最突出的问题之一就是存在很多相似重复数据,为此,本文将针对数据的相似重复性展开深入地研究。
本文通过研究N-Gram算法,发现了其存在两个缺陷,一是其只针对英文数据库,缺少对汉字的处理;二是对待清洗数据进行相似去重操作时,由于比较时采用特定大小的滑动窗口,降低了去重效率。基于以上两个问题,特提出了一种改进的N-Gram算法,不仅引入了适合中文数据库的算法,而且在对相似度高的数据记录进行去重操作时,采用动态滑动窗口策略,大大提高了算法的精确度。
1 数据预处理
(1)对待清洗的数据记录进行预处理时,需要去掉记录中的所有的空格、换行、&、*、/等特殊符号以及一些难以辨识或无任何含义的字符。
(2)例如一些不能公开的数据(身份证号、银行卡号、手机号等)或者在数据库中存在的大量的相同的字符串(如金额单位),通常用特殊字符******、¥等代替。
(3)对于数据记录中的所有大小写不一的字母,统一大写或小写,便于比对。
(4)对于一些人名、地名、机构名等,通常用众所周知的简称进行替换,如地名“上海”与“沪”可以相互替换。
(5)例如对电网PMS系统的数据进行预处理时,首先删除掉扩展字段(在对数据进行迁移过程中所设定的标志字段),然后仅对PMS系统的业务字段进行一一匹配,并计算出相似度。
2 算法过程描述
2.1 N-Gram算法过程(适用于英文和数值)
(1)思想:
任何一条数据记录与构成其的每一个词都是息息相关的,因此,我们可以根据每个词出现的概率,通过计算得出整条记录的概率,即N-Gram值。该值代表了该条记录的属性,如果任意N条记录的属性值越相近,说明这N条记录的数据相似度越高,即N条记录的数据重复的可能性越高,有助于我们进行去重操作。
对预处理后的某条记录进行二元分割,即列出该条记录所有长度为2的子字符串,假设该条记录的字符总长为S,那么它的二元子字符串的个数就是S-N+1(其中N为固定窗口大小,此处N=2)。首先通过统计语料库得出所有二元子串和单词的数量,然后利用马尔科夫概率计算公式,得出每条记录的N-Gram值并将其作为自身的键值,最后对所有记录按照既定的排序算法和排序规则进行排序。
所谓二元,即每条记录的所有的词,只与它前面最相近的那个词有关,概率公式如下:

由于 P(W3|W1W2)比较难算,P(Wn|W1W2…Wn-1)更加难算,马尔科夫提出一个假设,即每条记录中下一个词的出现仅仅依赖于前一个词的出现,从而将N-Gram的概率公式简化为
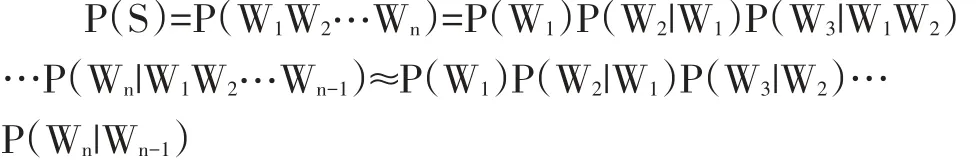
(2)N-Gram算法流程
N-Gram算法流程大致分为三步,一是遍历整个待清洗的数据库,进而得到该数据库的语料库和重复矩阵M;二是利用重复矩阵M计算数据库中所有记录的N-Gram值;三是根据N-Gram值的大小对所有数据记录进行合理排序。
2.2中文数据清洗过程
中文数据清洗采用的是中文字段匹配算法,该算法使用了典型文本字段的回归结构。算法的基本思想是先将A、B两个字符串进行分词操作,生成各自的子字符串,然后将A的各个子串与B的子串进行一一匹配,同时记录两个子串匹配度的最高情形。如果A的一个子字符串和B的一个子字符串是完全一样的或者其中一个子串是另一个子串的简写形式,则相似度定为1,否则是0。依次递归匹配A的下一个子串,最后利用以下公式计算出字符串A和B的相似度,从而判定其相似性。A和B的相似度计算公式如下所示:
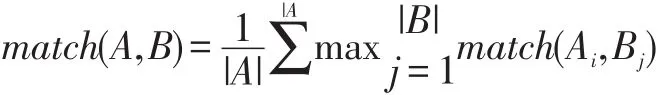
对于中文而言,其缩写通常仅有一种形式,即分词首汉字的组合,例如:“山大”是“山东大学”的简称。本文采用Word 2000中的汉语自动分词系统对要匹配的字段进行自动分词,或者说是在字段文本中通过调用Word 2000来达到对分词进行切分标记的目的。如“山大和北大都是大学”,该句自动分词后变为“山*大*和*北大*都是*大学*”。由此推出,“山大”被定为多个词,而北大是一个词。因此在对北京大学和北大进行匹配时,可以使用外部文件处理替换后再进行匹配,而对“山东大学”和“山大”的匹配,需要用算法对其进行特殊处理。回归的中文字段匹配框架如图1所示:
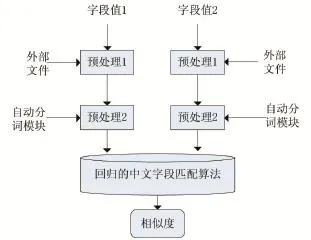
图1 回归中文字段匹配框架
(1)预处理1:首先用外部文件(表示领域知识的文件)对待匹配的字段值进行处理,例如地址名词“沪”即表示“上海”,在下一步分词时,将不对其进行任何操作。
(2)预处理2:利用汉语自动分词技术,对经过预处理1步骤后的结果字符序列进行二次处理,如此一来,进行过两次预处理的字段值就会演变成含有分词标记的字符。
(3)经过图1所示的两次处理后,便可以用回归的中文字段匹配算法对字段值进行进一步的匹配。利用算法的相似度公式,计算出两个字段值的相似度,也叫相似性。
3 算法改进与效率优化
改进的N-Gram算法流程图如图2所示。
3.1本文算法原理
由于N-Gram算法是针对英文数据库的,整个数据库中只含有英文字符和数值,而实际上数据库里的数据记录除了英文和数值还有中文,因此需要引入中文数据库的清洗算法,例如第2节提到的回归中文字段匹配算法。假设有两条记录A和B,通过N-Gram算法所求得的概率分别为 P(SA)和 P(SB),通过回归的中文字段匹配算法所求得的两条记录的相似度为match(A,B)和 match(B,A)(理论上 match(A,B)等于match(B,A))。
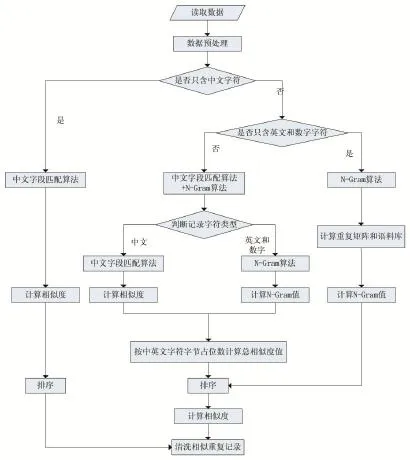
图2 改进的N-Gram算法流程图
对N-Gram算法和回归的中文字段匹配算法进行合并,为了精确计算相似度,我们采用加权法(权重值的计算是按字节数占比计算的,一个中文占2个字节,一个英文或数值占1个字节),记录A的相似度P(A)=1 match(A,B)+2 P(SA),记录 B 的相似度 P(B)=3 match(B,A)+4 P(SB),其中1是记录A中文所占比例,记录A英文或数值所占比例,3是记录B中文所占比例,4是记录B英文或数值所占比例。最后,通过比较P(A)与P(B)的值来得出相似重复记录。
3.2动态滑动窗口策略
N-Gram算法在进行相似重复记录去重操作前,采用滑动窗口的方法对待清洗数据进行组内比较。假设待清洗数据记录数为W,N为窗口大小,则每次只比较窗口中的N条数据,而不是把每一条数据和剩余的其他所有数据进行一一匹配。当使用N-Gram算法时,滑动固定大小窗口的次数为W-N+1,同时形成W-N+1个大小均为N的且相互重叠的窗口,具体如图3所示。
由于N-Gram算法的滑动窗口大小难以确定,而且要对窗口内的所有记录进行比对,所以效率比较低,从而影响去重的准确度。例如待清洗数据用W表示,则|W|为数据的长度,如果将W分割成二元字符串集,其时间复杂度为O(|W|)2,如果将其分割成三元字符串集,则它的时间复杂度变为O(|W|)3,如此的话,当窗口大小越大时,分割后的字符串就会越大,所计算出的相似度就会愈加精确,对应的时间复杂度就会随之增大;相反,如果窗口大小选择的越小时,其相应的时间复杂度就会愈小,造成的花销也会随之降低。但是这样的话,会因为字符串过小,导致后续进行排序合并的时候,难以有效地聚合相似重复记录,进而导致部分数据记录被遗漏,影响相似度值的计算结果,进而影响到算法的精确度。
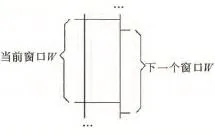
图3 滑动窗口扫描排序数据集示意图
针对这一缺陷,本论文采用动态滑动窗口的NGram算法,窗口的大小由当前窗口的大小、窗口内第一条和最后一条记录的距离以及最短记录阈值确定。在算法开始运行的时候,为窗口设置一个最初的值,后续窗口的大小则在算法执行中动态得出。我们一般把窗口中的第一个和最后一个记录之间的距离,即为窗口的大小。这样可以去掉很多无用的比较操作,提升数据清洗效率。如果窗口内第一个和最后一个记录之间的距离等于距离阈值φ,这里我们默认取φ=2,我们称其为最理想状态。窗口是当前正在处理的窗口Win⁃dow1,记录r1和rw1分别表示窗口内的第一条和最后一条记录,二者之间的距离满足distance(r1,rw1)<φ,此时窗口Window1内各记录之间的平均距离为下一步窗口的大小需要通过以下公式推理:
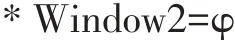
推理得出:

4 实验结果与讨论
(1)实验环境
硬件:一台PC,操作系统:Windows 7 64位操作系统
软件:GBase 8a MPP Cluster,GBase client 8.6.2.18-R2.82869
(2)实验数据分析
为了确保实验效果,以PMS系统的部分表数据作为实验数据,实验的总记录条数为10326。在对数据进行清洗前,首先对字段进行合理地分类并进行预先处理;然后采用二元算法,分别计算不同数据类型之间的N-Gram值,并对其进行合并,获得整条记录的N-Gram值;最后根据N-Gram值对其进行合理排序后,筛选出相似度大于某一阈值的数据记录并进行清洗,从而实现清洗数据的目的。本次试验数据来源于PMS系统,具体如表1-3所示(由于篇幅有限,在此仅列出部分数据):

表1 实验数据表

表2 实验数据表

表3 实验数据表
(3)实验结果分析
通过对PMS系统中的10326条实验数据进行预处理,并且去掉难以辨识的字符和特殊符号,分别计算它们的N-Gram值,结果如图4所示:
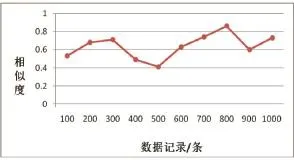
图4 数据相似度
通过对图4进行分析,我们取出相似度大于0.8的所有数据并将它们作为待清洗的数据,去除相似重复记录,保留准确数据,并按照清洗结果,对待清洗数据库进行更新和格式化。
在此处,通过实验模拟,对本文提出的改进的NGram算法与第2节所提到的传统的N-Gram算法、回归的中文字段匹配算法进行比较,具体从查全率、查准率、运行时间等三方面展开。查准率和查全率的计算方法为:

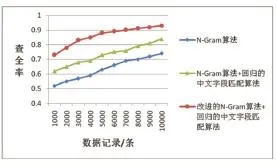
图5 各算法查全率比较
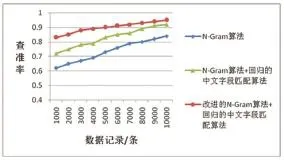
图6 各算法查准率比较

图7 各算法运行时间比较
5 结语
本文针对N-Gram算法进行了优化,先是基于NGram是针对英文数据库的特点,将回归的中文字段匹配算法引入其中,无论是查全率还是查准率,都在一定程度上得以提高;然后为了在对待清洗数据进行相似度比较后,能够快速且准确地删除掉相似重复数据,特别引入了动态滑动窗口的想法,大大减少了比较次数,减少了算法的运行时间,提高算法的运行速率。
猜你喜欢
智富时代(2019年6期)2019-07-24 10:33:16
制造技术与机床(2018年11期)2018-11-23 01:08:02
意林(绘英语)(2018年1期)2018-04-28 01:21:42
高中生·天天向上(2016年9期)2016-11-22 09:10:34
城市轨道交通研究(2015年11期)2015-02-27 11:02:50
雷达学报(2014年4期)2014-04-23 07:43:07
燕山大学学报(2014年1期)2014-03-11 15:28:11
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
测绘科学与工程(2013年6期)2013-03-11 15:07:57
网络安全与数据管理(2011年17期)2011-07-25 00:33:50
