
基于Q-强化学习和Adaboost算法的自适应谈判方法
2018-10-11 01:13郭绍永何喜军蒋国瑞
江苏科技大学学报(自然科学版) 2018年4期
庞 婷,郭绍永,何喜军,蒋国瑞*
(1.新乡医学院 现代教育技术中心,新乡 453003)(2.北京工业大学 经济管理学院,北京 100124)
商务谈判是解决冲突的有效沟通手段,随着谈判主体个性化需求增多,人工智能技术不断发展,商务谈判迈进了个性化、智能化阶段[1].自适应谈判是智能商务谈判的一种,在谈判过程中谈判主体学习动态变化的环境知识、对手行为及偏好等,不断调整自身信念,增大双方的利益[2].
目前已有很多学者研究将自学习算法引入谈判中,结合某些谈判策略,丰富了自适应谈判理论方法.例如,文献[3]中将遗传算法和马尔科夫预测综合运用到了自动谈判系统当中;文献[4]中结合人工蜂群算法的原理及求解流程,给出一种电子商务谈判模型;文献[5]中提出了一种采用基于案例推理技术的自动信任协商策略;文献[6]中应用人工免疫算法设计软件Agent的谈判策略;文献[7]中提出径向基函数神经网络优化Actor-critic学习算法的协商策略.但这些研究中的算法容易使得谈判时间长,易于陷入局部最优,导致谈判效用值低,同时较少考虑对手行为信息,自适应性较差,无法达到利益最大化.针对上述谈判算法存在的问题,文中提出一种自适应谈判方法来解决这些局限性.
Q-强化学习算法是重要的自学习方法,可以学习环境知识,经常用于自适应谈判[8].但普通Q-强化学习算法缺乏对对手行为的考虑,导致很快妥协.自适应增强(daptive boosting,Adaboost)算法是文献[9]中提出的一种增强学习算法,具有适应性强、精度高的学习优点.因此,文中结合Q-强化学习和Adaboost算法,形成一种新的自适应谈判方法,在让步谈判过程中考虑对手行为,不仅减少谈判次数,而且达到更优效果的谈判双赢.
1 问题描述
1.1 谈判协议
谈判协议是谈判参与者在谈判过程中必须遵守的一组规则集,旨在规范谈判参与者的行为,提高谈判效率.双方在谈判过程中应遵守以下规则:① 谈判双方有诚意通过谈判方式就议题达成一致;② 谈判双方均采用交互提议方式进行,任意一方在接收到对手提议之后,需做出回应;③ 谈判双方不允许提出比上一轮更差的提议;④ 若谈判成功,应确保尽快达成交易,消除冲突.
1.2 谈判流程
假定谈判双方为货物供给方和需求方,双方按照图1所示流程进行谈判.
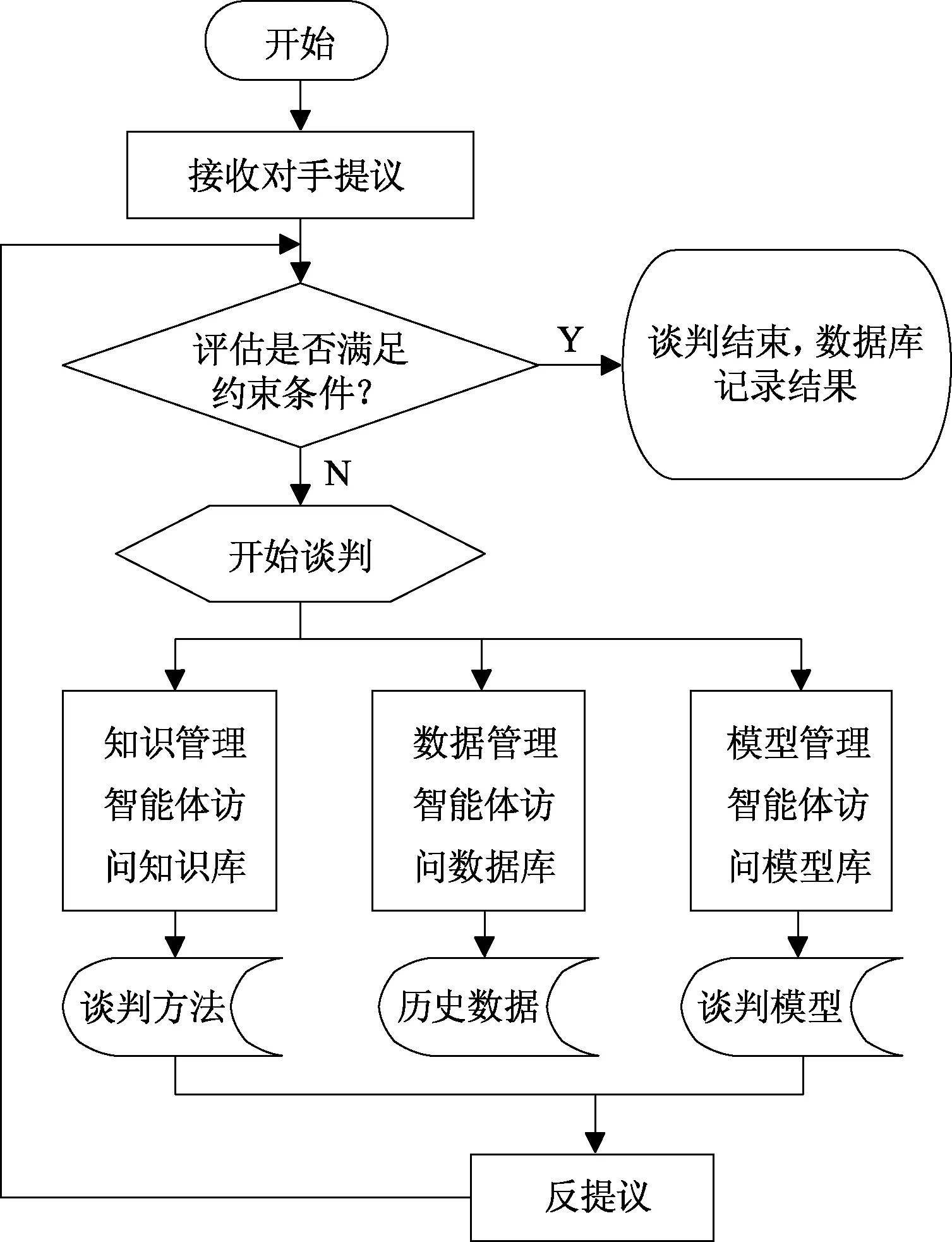
图1 谈判流程Fig.1 Negotiation process
当一方接收到对手提议,使用约束条件对提议值综合评估,如果达到要求,谈判成功;否则,采取基于Q-强化学习和Adaboost算法的自适应谈判方法,提出反提议.然后对手再重复上述流程,直至双方都满足评估条件,谈判成功,达成协议.
1.3 谈判模型
用一个六元组F表示该谈判模型,将其定义为F={A,C,O,W,θ,E},各个元素的具体定义:
(1)A表示谈判主体集合,设m为供给方,s为需求方,则A={m,s}.
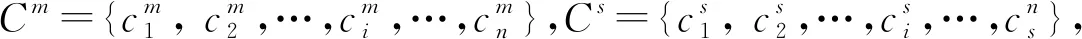

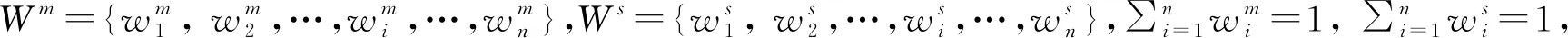

(6)E表示综合评估值集合,设Em、Es分别为供给方和需求方对对手提议的评估值,如式(1),则E={Em,Es}.
(1)
假定σm、σs分别为供给方和需求方接受对方提议评估值的阈值,当Em≥σm或Es≥σs时,接受对方提议,结束谈判,否则提出反协议,继续谈判.
2 谈判方法
2.1 基于Q-强化学习的让步谈判
Q-强化学习的原理是主体依据目前的状态执行动作,然后依照下一状态和策略执行下一动作,再次作用于上一状态和执行的动作,从而不断获得累积奖励值,用Q函数表示,基本形式为:Q(S,a)=r(S,a)+γmaxQ(S′,a′).其中,S,S′为目前的状态和下一时刻状态;a,a′为相应状态下执行的动作;r函数为从状态S转移到状态S′,主体获得的立即奖励值,可以为正值、负值或零;γ为折扣因子,γ∈[0,1],影响着Q值的变化速度[10].因此,Q值函数由当前状态的立即奖励值和后一状态的最佳奖励值构成,并不断获取更优Q值.

(2)
定义双方获得的立即奖励值:
(3)
定义双方的折扣因子值:
(4)
假定供给方针对议题进行让步,提议值在接受最大值基础上不断减小,需求方针对议题进行让步,提议值在接受的最小值基础上不断增大,则双方的提议值计算:
(5)
2.2 基于Adaboost的对手提议预测
Adaboost算法的原理是最初赋予各个训练样本权重,表明将它归为某个分类器训练集的概率.进行若干次迭代,若某次某个样本已准确分类,则它被选入下一个分类器的概率降低,权重下降;反之,概率提高,权重提高.目的是关注信息更为丰富却更难分类的样本,直至达到预定的足够小的误差率,将弱分类器函数最终生成强分类器函数[11].

(1) 输入供给方的样本数据序列,包括谈判双方针对议题的历史成交值集合、数据库记录的对手需求方在前几轮的提议值集合,并进行预处理,将不完整数据记录除去;
(2) 设总迭代次数为K,k表示第k次迭代,设第k次迭代共有L个样本数据,l表示第l个样本数据,值设为yk(l);
(3) 设样本的权重值为ωk(l),为各个样本赋予相同的初始化权重,计算为:
(6)
(4) 进行迭代计算,则从k=1到K进行迭代:
设εk为样本数据序列的预测误差和,计算为:
(7)
设φk为样本数据序列的权重调整控制因子,计算为:
(8)
设ρk为yk(l)的平均值,计算为:
(9)
调整样本数据序列的权重,计算如下:
ωk+1(l)=ωk(l)×exp(-yk(l)φkρk)
(10)
令k=k+1,每次迭代后当ωk(l)≤∂,从样本数据序列中去掉该样本,计算至εk≤μ时,停止迭代;
(11)
2.3 自适应谈判方法步骤
为了尽快消解冲突,融合Q-强化学习算法和Adaboost算法,通过预测让步,形成自适应谈判方法,双方不断更新提议,交互提出.整个谈判方法步骤描述如下:
(1) 供给方和需求方共同确定议题i,分别初始化提议边界值Om、Os,议题权重Wm、Ws,提议评估值阈值σm、σs;
(2) 一方发出提议,对手接收后,将对方的提议值记入数据库,并将提议值和议题权重值代入式(1),若超过阈值,则谈判成功,退出谈判,转入(9),否则转入(3);
(3) 初始化L、∂、μ,预处理历史成交提议值、数据库记录的对手前几轮提议值组成的样本数据序列yk(l);
(4) 根据式(6)初始化样本权重ωk(l),根据式(7、8、9),从k=1到K进行迭代计算;
(5) 每次迭代后,当式(10)计算结果不超过∂,从样本数据序列中去掉该样本,直至式(7)的计算结果不超过μ时,停止迭代;
(9) 将最终成交值记入数据库,达成协议.
3 仿真算例
3.1 算例及参数设定
为了更好地说明该自适应谈判方法的适用性,接下来对其进行有效性测试.设定某一汽车制造业供应链上的制造商为供给方,销售商为需求方,销售商向制造商订购一批轮胎上的配件,并提交了订货单,包含价格和数量,但是制造商不满意,二者发生冲突,为避免陷入僵局,决定通过谈判解决问题[12].将订单的价格和数量视为两个谈判议题,根据谈判模型,假定双方的谈判议题相关数据值如表1,根据自适应方法步骤,定义该方法涉及的相关参数值,如表2,限于篇幅,输入的样本数据序列不再一一列出.
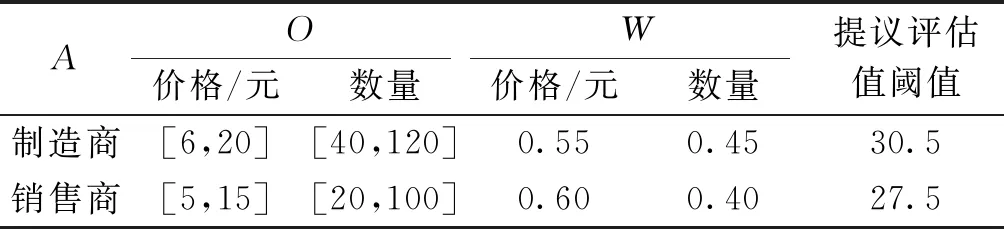
表1 谈判议题相关数据Table 1 Related data of negotiation issues

表2 谈判相关参数Table 2 Related parameters of negotiations
3.2 仿真结果
首先,基于文中提出的自适应谈判方法进行仿真,谈判过程及结果如图2.第1轮销售商提交订单(6,57),制造商对提议代入式(1)进行评估,Em=28.95<σm,因此制造商不满意,提出提议(6.6,58),销售商进行评估,Es=27.16<σs,销售商不满意,然后进行第2次谈判.制造商和销售商不断作让步,最后在第5次谈判时,销售商提议(6.4,60),Es=27.84>σs,制造商经过综合评估,Em=30.52>σm,双方都满意,谈判结束.
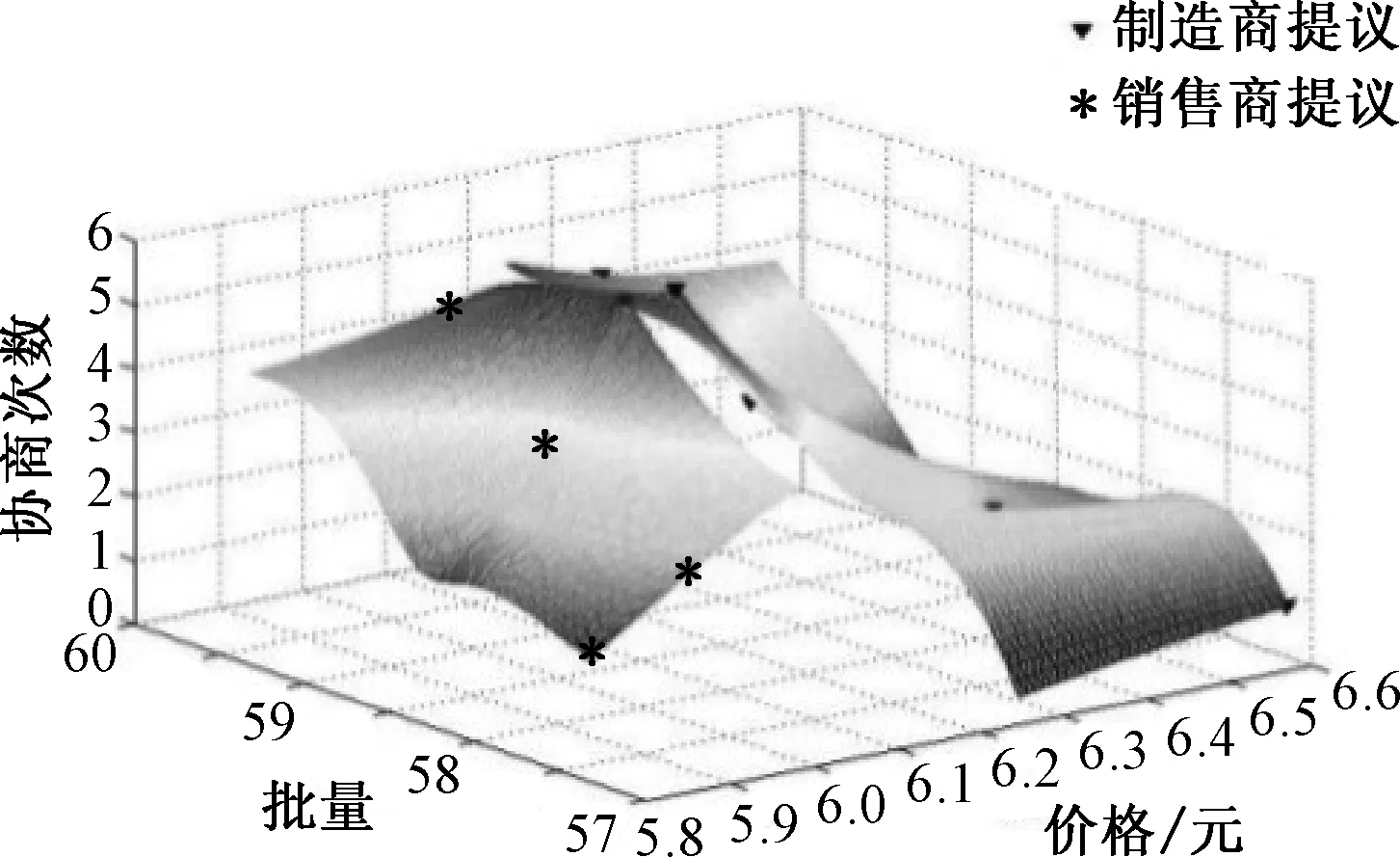
图2 自适应谈判方法的仿真结果Fig.2 Simulation results of adaptive negotiation method
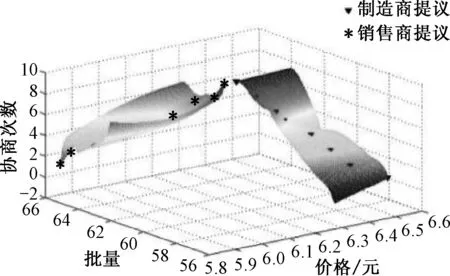
图3 使用Q-强化学习方法的仿真结果Fig.3 Simulation results of using Q-reinforcement learning method
对比图2、3可知,尽管都可以使双方满意,但文中提出的自适应谈判方法,比Q-强化学习方法能达到更理想效果:① 谈判次数较少,提高谈判效率;② 谈判结果不易陷入局部最优,增强自学习能力;③ 综合评估值高,满意度高,谈判结果更优.
4 结论
传统谈判效率低,主体自学习能力较差,导致最终无法获得满意结果,从而使得谈判效果不理想.为了改善传统谈判效果,文中研究一种优化Q-强化学习的自适应谈判方法,该方法考虑对手行为,提高智能化程度.首先利用Q-强化学习算法进行让步谈判,计算出Q值作为让步幅度,并引入对手提议预测值,再使用Adaboost算法通过迭代计算该预测值,从而调整让步幅度.演算结果表明,该方法不仅可以减少谈判次数,而且不易陷入局部最优,谈判结果更优.文中提出的谈判新方法,只是一部分工作,下一步将建立具有自适应能力的谈判机制和谈判框架,应用该方法系统全面地研究自适应谈判过程,将更进一步提升谈判的智能性.
猜你喜欢
——基于供需双方的进化博弈
乡村科技(2022年1期)2022-04-11
运筹与管理(2022年2期)2022-03-15
制造业自动化(2022年1期)2022-02-11
黑河学院学报(2021年10期)2021-12-10
现代计算机(2021年19期)2021-09-09
商情(2020年2期)2020-02-14
文萃报·周五版(2019年36期)2019-09-10
环球市场(2018年4期)2018-09-10
统计与决策(2018年7期)2018-04-26
支部建设(2010年13期)2010-08-15
