
基于CUDA的多角度平面波复合算法研究
2018-10-11 08:41:14伍吉兵焦阳张德龙徐杰杨晨崔崤峣
中国医疗器械杂志 2018年5期
【作 者】伍吉兵 ,焦阳,张德龙,徐杰,杨晨,崔崤峣
1 中国科学院苏州生物医学工程技术研究所,苏州市,215163 2 中国科学院大学,北京市,100049
在现代医学临床诊断中,超声成像诊断由于其具有无副作用、成本低等优点,成为了不可替代的重要技术手段,因此,超声成像技术越来越受到医学界和工程界的重视。在临床环境中,高效且能够保证图像质量的算法将会扩展超声成像技术的应用范围,进而发展成为一种实时监控诊断技术。在提高成像质量方面,传统的超声成像需要成像区域进行多次聚焦,形成多条扫描线用于保证成像每个区域的分辨率。但是由于在这一过程中超声换能器需要进行多次发射聚焦和信号接收,成像耗时较长。所以成像速度这一瓶颈使得传统聚焦超声在快速成像领域(比如跟踪血流成像中)具有先天缺陷。而超声平面波成像通过控制超声换能器同时发射和接收信号,再通过算法合成聚焦,避免了多次物理聚焦过程,成像耗时大幅降低[1-2]。
随着科学技术的发展,计算机已经进入到了具有革命性质的多核时代。GPU的架构特别适合于解决大规模并行数据计算问题,使其相对于CPU更适合于信号与图像处理计算[3]。由于超声成像中的波束合成是计算密集型任务,所以当前高速发展的GPU软硬件提供的高性能并行运算能力能够帮助超声成像技术大幅度提高计算效率。同样,在超声平面波技术方面,平面波复合成像的计算过程可以分解为大量独立的子任务,非常适合进行GPU加速运算。
本文首先介绍了超声平面波成像技术原理,分别详细分析了单角度和多角度条件下的平面波复合算法。然后通过Matlab和Field II进行了平面波复合成像的仿真验证工作,并通过实验结果指出,多角度平面波算法相对于传统聚焦超声的优势。在CUDA加速方面,本文简单介绍了CUDA架构,然后详细介绍了CUDA架构实现该算法的关键计算模块,最后得出,通过GPU并行计算可以在保证图像质量的前提下大幅提高多角度平面波合成计算的计算效率的结论。
1 平面波成像算法
1.1 平面波超声成像
在传统超声成像过程中,一幅完整的超声图像是通过聚焦于不同的点来提高图像质量的。聚焦模式分为发射聚焦和接收聚焦,发射聚焦模式下每聚焦一次都需要控制换能器重新扫描,而接收聚焦则是通过软件计算完成[4]。重复扫描过程会大幅度降低超声图像的帧频,在帧频要求高的领域会出现扫描不同步等问题。
与传统的聚焦超声成像不同的是,平面波超声成像是通过平面波扫描检测区域,换能器控制所有阵元同时发射并同时接收信号,再通过算法实现成像区域内不同点的聚焦,从而达到和传统方法类似的聚焦效果。由于平面波成像算法并不需要实现物理层面的逐点聚焦,对同一成像区域只需要扫描一次,所以平面波图像的帧频为,Fpwi=c/2z,c为声速,z为成像深度,而传统聚焦超声的帧频为Fb=Fpwi/n,n为聚焦线数。
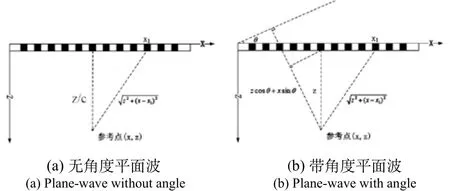
图1 超声平面波时延计算方法示意图Fig.1 Time delay calculation for ultrasound plane wave
如图1(a)所示,换能器设于被扫描区域的正上方。X轴为换能器阵元排列方向,Z轴为超声波发射方向,换能器上所有阵元同时发射,超声波传播沿发射方向传递到参考点(x, z),进而被换能器上X1阵元接收到该点反射回的信号。传播时间为:

通过上述几何关系,由传播时间可以确定该点反射的超声波对应于X1阵元接收信号的索引,再将相应阵元上的数据进行叠加,就可以得到图像上该位置像素点的强度。
单角度平面波合成虽然可以大幅度提高帧频,但是由于缺失了物理聚焦过程而只通过算法合成聚焦,成像区域各点之间的回波干扰会导致最终得到的图像对比度和分辨率相对较低。为解决这一问题,FINK等[5]提出了多角度平面波复合成像,通过多个角度的平面波发射并接收,并将多个角度得到的图像相干叠加从而提高最终图像的分辨率和对比度。
如图1(b)所示,通过对换能器上阵元设置不同的延时,使得超声波束形成一定的发射角度。相应的接收延时为:

通过不同角度和不同阵元的数据叠加,得到最终图像上每个点的像素强度:
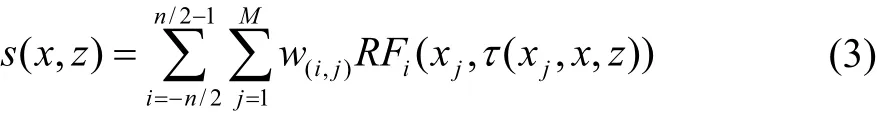
FINK等[5]还给出了获得等效聚焦超声图像质量的平面波复合角度数量和偏转角度:

其中L为换能器总长度,λ为超声波长,2a为成像孔径,z为成像深度,F值在超声成像中一般定义为常量。由于多次发射和接收不同角度的平面波,最终图像的帧频会依据角度数量而降低相应的倍数。
1.2 仿真验证
本文使用的仿真平台Field II是一款基于线性声场理论的超声成像系统仿真平台[6]。它可以通过Matlab函数仿真不同类型的超声探头和仿体,能够动态控制探头的聚焦模式以及变迹,并计算得到探头所接收到的RF数据。
为了验证多角度平面波复合成像方法的效果,使用Field II仿真平台分别得到聚焦模式、平面波模式以及多角度平面波模式下的超声回波数据。程序中超声探头设置为128线阵探头,中心频率为11.25 MHz,采样频率设为100 MHz,阵元宽度和间隙分别设为0.18 mm和0.02 mm。所使用的仿体采用点散射模型,且设置如下:在阵元中心线下,每隔5 mm设置一个散射子,仿体深度为40 mm,仿体内其余点幅值均设为0。在传统聚焦模式下,通过Field II自带函数设置阵元分别聚焦于不同的聚焦线,并设置激活阵元的变迹。在单个角度模式下控制阵元同时发射和同时接收且不设置变迹,形成0角度平面波。在多角度平面波模式下,在单角度平面波模式的基础上再分别设置每个阵元的延迟,形成不同角度的平面波。
由图2可以看出,传统聚焦模式下图像中对焦深度(20 mm)所在的亮点非常清晰,而对焦点之外的位置则会出现伪影。而在单角度平面波模式下,波束合成后的图像会在散射子所处位置处出现少量伪影。而通过-9°到9°共11个不同偏转角度的平面波复合图像中,这些伪影基本消失,且散射子所在位置亮点非常清晰。从这几幅图像中可以明显看出,经过多角度平面波复合方法,超声图像的质量大为改善。织[9]。CUDA将存储空间分为多个层次,包括全局内存、共享内存和寄存器等,分别行使不同的内存管理功能。

图2 传统聚焦模式、单角度平面波成像(0o和-9o)以及多角度平面波复合成像结果示意图Fig.2 The result of traditional focused ultrasound, single-angle plane-wave (0o and-9o) and multi-angle plane-wave
2 多角度平面波复合算法的并行计算
2.1 CUDA编程模型
CUDA是NVIDIA公司针对其产品发布的一款促进高性能并行计算的普及所创建的支持并行计算的软硬件平台[7]。CUDA的硬件方面涉及显卡上配备的一个或多个兼容CUDA的图形处理器(GPU)。CUDA提供了基于C/C++编程语言的开发环境,对于熟悉C/C++编程的开发者来说可以很快地掌握CUDA环境下的编程[8]。
GPU能够进行并行化的关键属性在于其具有成百上千倍于CPU的计算单元,独立子任务分别被大量的计算单元并行执行从而大幅提高计算速度。CUDA代码是由两个部分组成的,运行于CPU上的代码被称为host部分,运行于GPU上的被称为device部分。运行在GPU上的CUDA并行计算函数被称为核函数(kernel function)。CUDA有一个很重要的特点就是它的线程层次管理,分为三个层级:线程网格(grid)、线程块(block)和线程(thread),所有的线程块和线程都是以三维或三维以下的方式组
2.2 运算关键模块
在本文中,整个多角度平面波复合计算程序包括以下步骤:读取RF数据、拷贝RF数据至GPU端、多个角度平面波并行运算、多角度图像像素叠加和拷贝图像数据至CPU端。以下是对该方法中和CUDA计算相关流程的详细介绍:
(1)在GPU端通过cudaMalloc开辟全局内存,包括RF数据内存和计算结果内存,通过常量内存保存计算参数,包括角度大小和角度数量等。在接下来的运算中由于要用到纹理内存(texture memory),所以在这一步需要通过cudaBindTextureToArray函数提前将RF数据与相应的纹理内存进行绑定。纹理内存是CUDA内置的一种方便进行内存索引以及插值计算的一种内存类型。
(2)这一步是该并行计算过程的核心部分,包括分别计算各个角度对应的平面波图像和各个图像相同位置像素的叠加运算。首先设置线程网格和线程块的大小,线程网格的宽度设为阵元接收到信号的长度,而线程网格的高度设为角度数量乘以阵元数量。在核函数内调用每个线程分别计算图像上每个像素点对应不同阵元接收信号的索引,然后通过二维纹理内存tex2D直接提取该信号数据,再将不同阵元的信号数据进行叠加。在这一步的核函数计算过程中,每个线程的计算过程包括对不同阵元的循环计算。结束本次核函数运算后,再次设置线程网格和线程块的大小,此次线程网格的宽度和前一次一致,而高度设为阵元数量。第二次核函数的计算过程是将多个角度分别得到的图像像素直接叠加,计算过程比较简单。这两个部分计算的线程块的大小不受限,可以通过多次测试得到最优值。
(3)通过CUDA自带函数cudaMemcpy将上一步骤得到的结果传回CPU,并与CPU计算结果相比较。将步骤(1)中开辟的各种不同类型的内存通过cudaFree进行销毁,并通过设置GPU计时函数cudaEventElapsedTime对步骤(2)的计算耗时进行评估。在调试阶段,所有的内存开辟、核函数调用与内存销毁过程都需要设置错误检查函数checkCudaErrors,方便查看不同类型的函数使用错误。
2.3 运算结果比较
本次CUDA并行计算的开发环境为:计算平台的操作系统是Win10 64位专业版;相关软件包括Matlab 2014a;Visual Studio 2015和NVIDIA CUDA 8.0;计算CPU为Intel(R) Core(TM) i7-4790k @2.4 GHz;计算GPU为NVIDIA GeForce GTX960 (4 GB)。
为了测试提出的CUDA并行实现多角度平面波复合成像算法的成像效果,我们将通过仿真工具Field II 生成的RF数据作为实验数据。图4分别为在CPU和GPU的11个角度下平面波复合计算得到的图像,从图4中可以看出CPU和GPU的计算结果保持一致。在计算效率方面,我们多次测试了在CPU和GPU环境下对不同数据量的计算耗时。如表1所显示的结果可以看出,使用CUDA对多角度平面波合成进行并行运算可以在保证成像质量的前提下,相对CPU计算速度的加速比达到28倍左右,大幅度提高了成像速度。

图4 多角度平面波算法的CPU和GPU计算结果图像示意图Fig.4 The results of multi-angle plane-wave calculated by CPU and GPU

表1 不同角度数量下CPU和GPU计算耗时表Tab.1 The execution time on diあerent amount of angles
3 结果与讨论
本文利用GPU并行计算实现了基于多角度平面波复合算法的超快速超声成像技术。首先利用多角度平面波复合算法改善传统聚焦模式超声图像帧频和分辨率。然后为了提高成像效率,本文进一步根据GPU并行计算架构,首先将多角度平面波复合算法中复杂的计算任务分解为独立的子任务,并通过大量GPU计算核心同时进行计算,减少计算时间。最后通过实验比较CPU与GPU计算内核在多角度平面波复合成像算法中耗时情况,验证了基于CUDA架构下的GPU并行计算可以大幅度减少相关算法的计算时间。由于本文介绍的多角度平面波复合方法基于时域计算,在计算效率和成像质量上相对于频域算法还有较大提升空间,所以下一步的研究将会是基于频域的多角度平面波复合方法以及对它的GPU加速,使得超声成像获得更好的成像速度和成像效果。
猜你喜欢
光学精密工程(2023年1期)2023-02-06 14:08:20
中学生数理化·高一版(2021年4期)2021-07-19 09:00:56
数学物理学报(2021年3期)2021-07-19 06:02:26
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09 08:43:02
新世纪智能(数学备考)(2021年11期)2021-03-08 01:08:08
电影新作(2020年1期)2020-11-14 19:01:11
中学生数理化(高中版.高二数学)(2020年10期)2020-11-10 08:48:58
小学生作文(中高年级适用)(2018年5期)2018-06-11 01:22:54
电影新作(2016年6期)2016-11-20 09:04:28
电子制作(2016年11期)2016-11-07 08:43:45
