
基于Trevni行列混合的分布式嵌套存储研究
2018-09-18 02:11文卫东李文海
计算机工程与应用 2018年18期
文卫东,李 鸯,李文海
1.软件工程国家重点实验室,武汉 430072
2.武汉大学 计算机学院,武汉 430072
1 引言
伴随互联网相关技术的快速发展和分布式计算方法在数据密集型应用的逐步深入,越来越多的数据库平台在面对半结构化数据的查询中引入存储和计算并行化。近年来,相关并行化技术主要沿MapReduce[1]和MPP[2](Massive Parallel Processing)两个维度展开,二者显著的不同在于数据库算符与Map和Reduce两个阶段之间的转换。其中,MPP更加侧重于在不同计算阶段之间尽量减少阶段化的持久化操作,从而实现算符之间的管道工作(Pipelining)模式。一种折衷的方式[2-3]是将数据库中无法管道化的操作分解成一个操作符超集(Super Cluster of Operators),从而实现超集内管道化执行,超集间持久化执行。这一方式使得数据库查询的负载较传统基于MapReduce的开源实现(如Hive[4])更多依赖底层存储和数据组织方法。
为提高数据访问效率,列存储技术自20世纪末被逐步引入,其常见的存储[5]和组合[6]方式先后得到较为深入的研究。列存提升数据库应用的前提是查询的局部性特征,即单个查询在某个执行阶段上往往仅访问数据模式中的一个子模式。通过引入列存,已有数据库应用中OLAP[7](OnLine Analytical Processing)负载的可用性得到了保障。然而必须指出,OLAP的星型模式以减少数据冗余为目标,引入了代价高昂的连接操作。早在20世纪80年代[8-9],就有研究指出这些连接操作可以通过嵌套建模方式予以优化,通过迭代遍历嵌套记录既保证数据的低冗余又通过线性扫描嵌套元组降低操作执行代价。该思想直到近年仍然受到学界的广泛重视[10-11],同时有大量的开源框架[12]在持续开发。
列存储和嵌套模型的混合催生了大量极具现实意义和研究价值的问题[13-16]。而其中一个核心问题在于如何在保证列存数据局部性的同时降低其高昂的装配(Assembly)代价。这里的装配可以解释为将分散于各列的数据单元进行封装、形成满足给定数据模式的各个记录。传统行存中的这一代价表现为连接被广泛研究,而列存在去除连接后的代价主要集中于迭代遍历单元以及依据模式构建元组上。后者的代价更加侧重于这样一个事实:当元组依据列存方式加载到内存后,列和列之间的同属一个元组的单元在内存中不再连续,从而对其访问在L1/L2缓存中的访问效率也大大降低。此外,在嵌套模式下这一问题显得更加突出:由于嵌套模式需要在不同层级之间维护一对多关联关系,因而常用嵌套框架在跨层关联时的表现不能让人满意[14]。
有鉴于此,本文研究并给出一个行列混合式存储设计。该存储方法的核心在于通过将经常聚集访问的属性列按照行的方式与其他列等同建模和组织,形成空间上局部的若干列组、进而保证数据交换的有效性和装配的内存局部性。为该设计目标,研究深入分析了主流开源框架的模式和存储构成,通过特殊设计union结构实现复杂类型的嵌入。研究设计并给出了一种特殊类型Group,并将该类型与普通列统一存储。从而在当查询仅涉及到若干属于某列组的单元时以行方式反序列化(Deserialize)元组,提高了列存的装配性能。
2 相关研究
近年来,面向嵌套列存的研究伴随Dremel[10]在Web级数据上的逐步深入应用而被广泛重视。该方法在数据库领域曾得到深入研究,大量有关模式[8]、互操作[9]和存取方法[13]的优化成果先后被提出。
Dremel的核心特色在于通过引入定义层(Definition Level,DL)和重复层(Repetition Level,RL)的嵌套抽象,使得任意嵌套记录的层级映射可以通过状态机转换方式在两个层次的数组上得到。即连续的子层元组通过列上对应的重复层指示器得到层级,通过其定义层指示器得到单元是否为空值。该方法的优势在于通用,但每个可为空(nonrequired)的嵌套列均需要进行转换、降低了其装配效率[14]。
Avro的列存核心组件Trevni[12]采用了层映射方法,即同一嵌套层次共享一个映射单元。该策略的优势在于装配复杂度较Dremel低,但逐一计数的方式使得该存储格式仅支持迭代方式。同时,Trevni的变长字段采取单元块内偏移与数据负载混合存放,进一步降低了列映射的效率。已有研究通过引入Dremel设计思想改写Trevni,如Parquet等。如上述可知,引入Dremel需要对嵌套列的每行增加RL和DL,从而增加了逐列进行状态转换的代价。因而如何在保证列存优势的同时减少装配代价仍然是Trevni和Dremel研究中的一个开放问题。
已有研究在上层模式上侧重平坦化(Flattening)[13]和共享优化设计[14]。平坦化研究分析并给出了避免上层高代价平坦化装配操作的场景,与本文研究正交;而共享优化仅限于单个映射节点,难以适用于具有任意级联层次的即席(ad-hoc)查询[6,15-16],如富含嵌套连接条件的关系子查询[17]或对象模型下[18]面向嵌套模式的多选择条件查询。
3 行列混合存储设计
本章给出嵌套模式列存架构样例,分析模式构造与装配的通用过程,进而研究提出列组物理结构。
3.1 通用嵌套行列混合模式
主流列存框架(如Trevni和Parquet等)将每个列存放于连续的物理块中实现高效的按列提取。其中,Trevni的思路是同一个列的所有单元(unit)具有全局连续的偏移量,其表示为块号和块内偏移;而Parquet采用Dremel架构,基于定义层(Definition Level)表示某列的某个单元是否为空、基于复制层(Replication Level表示层级)。此外,Google的数据交换格式Protobuf也被广为接受,其提供与JSON兼容的模式定义方法用于数据交换。Parquet与Trevni均采用计数原理完成不通层级之间的关联。
图1给出了Trevni和Parquet建立层级关联的过程。该过程通过计数(Trevni采用图1(a)所示方式)或复制层遍历(Parquet如图1(b)所示)对各个列独立存储的方式重建上下层之间的一对多关系。如果发生一个上层实体对下层的映射,可以根据行标或复制层计数进行装配,模式的层级可以通过类似JSON的格式进行定义。该方法的潜在不足之处在于:当需要一对多重建嵌套记录时,频繁在列间进行计数和状态切换会带来大量的装配开销。为此,研究给出一种新的逻辑模式定义与物理存储分离的行列组织策略,迭代定义嵌套模式如下。

图1 嵌套元组用例和两种典型列存框架组织示意图
定义1(逻辑嵌套模式)任意一个嵌套模式可基于树结构[13]递归定义如下。

该定义通过基本类型primary及集合类型array构造了两类高层对象object和value,并在这两类高层对象基础上递归定义了对象类型record和group。其中,record类型可递归通过primary、array或group分组构成;group只能递归由array或primary构成。考虑到规范化嵌套模式均可通过一个模式根Troot表达成上述定义中的record类型[13],通过对不同类型定义列映射,建立如下行列混合存储约束。
定义2(行列混合存储)任意独立存储的连续物理单元必须由primary和group两种类型的同构实体或array类型的映射数组构成。
该定义通过约定可连续存储的单元类型,为混合存储构建了通用模式要素。这里任意模式根节点可以由多个列(集)的record构成,其中每个列可以由三种类型构成,三种类型数据实体按列连续存放(array的映射数组与primary等价处理)。下面给出一个典型的模式实例,其中record与group类型在“组”中取一种即可。当选定group类型时,其下属三个域需要作为整体连续存放。


3.2 基于Trevni的列组构造
上述模式及其约束适用于主流嵌套列存框架,下面以Trevni为例对嵌套模式的列式存储给出构造方法。在该存储框架下,以支持嵌套的模式元数据为基础,该框架为列存数据库提供了两层描述。通过特别构建列存映射数据块形成不同层次的数据映射关系。模式中的每个叶子节点的数据连续保存于若干数据块中,保证数据按列访问的效率。在实现上,Trevni提供一组用于持久化基本类型的单列载入类ColumnFileReader,通过依次顺序扫描维护在缓冲区InputBuffer中的单个列的所有实例,实现按列载入。能够支持的基本类型有:长整形、布尔、整形、字符串、字节数组、浮点和定长类型等。
如图2所示,Trevni的数据由一个文件头和连续的列数据块构成,其中文件头的核心结构由版本号、基于JSON的模式信息和块偏移量数组构成。每个数据块原则上被设计为定长的数据块,每个块的实际长度被保存于文件头的偏移量结构中,其中记录每个块的实际维护的单元(同属于一个列的实例)数量。一个模式根节点下的子节点间关联关系通过JSON格式的模式信息描述,模式特别对存在嵌套的字段构建一个容器,所有同属于一个父亲的孩子节点共享一个一对多的映射结构。图2示意了这两个核心结构与所面向的数据块之间的关系。其中,JSON格式给出了一个具有两层级联(Cascading)的嵌套关系:作者(Authors,简称A,下同)节点包含三个属性,即名(F)、姓(L)和联系地址(C)。

图2 行列混合存储示意图
上述模式及其约束中,record类型为嵌套结构,即一个父亲下面可以有多个孩子节点,但是不经array解释,每个孩子在一个父亲实例下仅有一个实例;array为行迭代类型,即一个父亲实例可以有多个孩子实例。二者可以结合,用以描述具有层次嵌套关系的复杂实体。例如,一个文献若有多个作者,则通过在作者映射数组中保存该文献的作者数量,最终装配过程中根据作者数量确定该文献的作者。这一方法的优势在于当查询需要少量的列时,装配仅发生在这些列上,有利于减少IO代价和记录宽度。然而,由于多个同属于一个父亲的列,如上例中A到F、L、C三个子节点,在封装对象时需要依次访问对象数组元素、增加了装配代价。
上例给出文献的一个模式定义,其中作者信息依次由array和group嵌入类型构成。原始Trevni给出的模式定义通过在group的位置定义record,从而使得顶层四个属性和“作者”下属三个属性形成独立的列,以构成物理存储结构。通过引入例子中给出的group类型,将列组类型作为一种普通bytes类型与Trevni其他基础类型采用相同的方法读写,并在装配时根据每个group的变长实例的模式信息进行反序列化。这样同一顶层实体的下属被频繁聚集访问的属性列能够以一个整体对每个实例反序列化,从而有利于提高装配效率。
3.3 级联存储结构
上述group构造的基本原理是通过聚集group节点的数据存储和解析,从而在存储阶段以普通字节数组方式存取这些实体。而解析阶段,依据该类型字段的读写对象、基于模式对字节数组进行反序列化。下面针对上述过程详述存储方法。
设计解析group类型的GenericGroupReader,该类与ColumnFileReader和InputBuffer的转换功能同构,根据模式信息调用已读入到内存的group类型对象的反序列化接口。GenericGroupReader除了能够支持上述基本类型外,还提供对array和record的嵌套反序列化。实现对这三类复杂结构的嵌套调用,并对叶子节点的基本类型的实例进行嵌套定义。不同于record,group将下属所有节点按照行方式在磁盘块中以字节数组方式存储,从而保证了应用中被连续访问的字段能够在空间上连续存放,从而可以保证反序列化和装配的效率。
基于字节数组方式保存模式化group实例的块分布如图3所示。通过将图2中的数据库展开,可以看到采用group方式存储的字段集与其他独立存储的字段之间在物理结构上的差别。由上述模式样例可知这里的作者信息包括姓、名和联系三个字段,与其他字段共同构成模式的顶层节点。
从图中可以看到作者信息包含一个映射字段,用以维护文献与作者之间的一对多映射。与该节点处于同一层次的关键字、修订日期等字段采用列存储(如上述模式定义所述),每个列分别占用连续的磁盘块。其中,关键字信息也包含一个映射字段,用以描述一个文献对多个关键字的约束。值得注意的是,这里的映射字段采用全局连续的偏移量进行记录,以方便快速定位一个字段的实例。在图中,文献[1]的两个作者“张,三,武汉”,“李,四,北京”被连续存放于块2和块3,当某查询需要访问这些作者信息的时候,该聚集存储方法可以依次获得同一作者的三个字段,从而有利于提高系统效率。对于其他列信息,查询必须逐列序列化后再依据映射列的一对多关系分别装配。
4 模式关联方法
为进一步加速反序列化过程,设计了变长字段块内聚集存储策略,通过高效保存空值、偏移量和变长数据的字节数组,提高块内数据访问效率。
4.1 块内聚集存储
从图3可知,对某属性列(组),行列混合存储面对三类对象存在不同的访问方式,即叶子节点中基本类型的对象数组、叶子节点中group类型对象的字节数组和映射关系中的偏移量数组。可以通过块偏移量描述符对各个块进行定位,但在块内数据进行反序列化的时候按照偏移量逐次确定列实例的边界,使得查询无法跳过无用的记录。这在很多应用中无法保证对空值的高效处理。基于这一问题,研究给出了块内数据的一种快速访问方法。

图3 组按行关联与不同层次之间列关联示意图
如图4所示,综合考虑空值和变长字段,给出一个优化块内数据组织方法将每个数据块分割为三个区。其中,指示器(Indicator)区以1位指示一个实例是否为空;偏移量(Offsets)区存放该实例在块内的开始地址;对于一个开始地址,数据区存放该实例的变长字节数组。默认地,如果字段在模式定义中未声明为null,则该字段不能为空,存储结构中不为该字段设置指示区。图中给出了第3章模式的块内数据形式。对于“摘要”字段,模式定义为可以为空,因而该字段的每个数据块采用三个区域对数据进行组织。如果要访问该块中的第二个记录(该记录对应第二个“文献”)的“摘要”,反序列化过程首先根据模式找到指示器的第二位得到该实例不为空。然后基于偏移量区域的第二个元素定位到内存中cache页面的该实例起始位置,读取该位置到下一个开始位置之前的字节数组。

图4 块内空值—位置—数据三级访问结构
当需要跳过若干字段的时候,可以直接在块内进行二分查找、基于块内计数定位到需要跳转的目的实例位置,完成对中间无用实例的跳过;当发现若干实例为空的时候,同样可以根据指示位“0”决定是否忽略该实例。这对于特殊场景(如选择下推[6,14]或空值字段[13])中的数据装配具有较强的现实意义。同时,对于通常应用中的记录装配,这些聚集存储的指示位对每个实例仅占用一位的存储空间,可以采用选择下推操作提升访问效率。
4.2 组装流程设计
如前所述,列组中的数据在存储时按照普通字节数组方式读写,在模式转换过程中形成与复杂类型record同构的行存嵌套对象。对于一个从模式根节点开始的访问请求,需要以深度优先方式(Breath first)依次访问各层节点的列(组)数据块,将其读入内存中的各个封装器中。然后对其中的一对多的节点进行组装,形成嵌套记录。
如图5所示,深度优先算法的流程以模式的读取和解析作为起始过程,在遍历完一个模式的所有节点后结束一个层次的访问,其中的遍历模式可以是数据模型的一个任意子集。例如,在上一章给出的模式定义中,可以根据用户的查询请求查找所有包含关键字集合{“存储”,“数据库”}的论文题名和作者信息。这一查询模式(Pattern)实际上排除了除关键字和题名以外的其他属性,是数据模式的一个子集。仅需要依次遍历一级节点“关键字”,“题名”和“作者”。其元组组装过程如下:
首先,加载模式根的一级列中的叶子“题名”,根据其对象数组找到第一个记录的“题名”对象。
然后遍历“题名”的兄弟节点,根据“关键字”字段的第一个映射元素找到四个关键字对象,并根据作者的映射关系找到两个作者的三个字段。这一映射过程可以参考图3的映射字段,并在其偏移量2的基础上在图4所示的块结构中找到对应的作者信息。两个字段均包含一个映射数组,但根据模式给定的类型差异分别做如下处理:
(1)“作者”字段为group类型,其对象以字节数组存放,需要在装配阶段反序列化。
(2)“关键字”字段为基本类型string,其对象在装配之前的读取阶段已经是string类型的字节数组了,因而仅需要进行一次类型转换。
(3)各节点均无孩子节点后,一个记录完成;所有记录装配后,程序完成读取。

图5 嵌套分组层级之间关联流程图
4.3 代价分析与MapReduce接口设计
上述按照group装配的特点在于:当模式指定的字段为group类型时,根据映射数组可以一次顺序地装配一个记录的所有字段。传统列存方法下,因为反序列化阶段是按列组织列实例的,因而需要轮转根据映射关系装配所有作者的三个子字段。
对于上述列组的组装方式,当需要的字段信息一定时,一定范围的低层对象的若干个列仅需要顺序进行反序列化和一次扫描装配;与之相反,Trevni需要针对每个列独立反序列化成对象数组,需要轮转依据映射数组进行装配。假定一个包含c列的列组在第l层逐层具有ni:1的映射,则每个顶层记录在Group方式下装配该列的内存代价为:

这里Dj为反序列化和装配某列的代价,D为反序列化一个映射数组中一个元素的代价。通用列存分离存储模式下由于需要根据列组访问,其代价为:
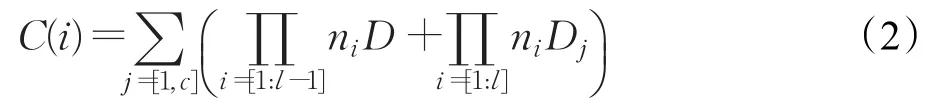
可以看到式(2)的内存操作多出了对每列进行数组映射的代价。进一步的,假定可以在顶层扫描过程中进行过滤,如在反序列化前根据前一个过滤器确定后一个对象是否需要进行反序列化和封装,给定第一个顶层选择率r,则式(1)缩减为:
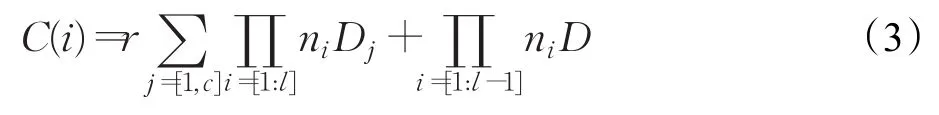
在一个选择过程中,通过度量每个列的装配代价和扫描代价,从而得到下面的总代价:

其中Fj为在给定列(列为第 j层)上执行选择的代价,且反序列化和选择分别具有O(Nnc)和O(Nn)的时间复杂度。因为反序列化复杂度较高、其在式(2)中不会受益于选择率,故式(3)描述的代价显示出所提方法可线性减少下层嵌套列的反序列化代价。行列混合存储合并了原本分离存放的列、不需要额外引入存储空间,因而不会带来额外的存储开销,且内存合并行组与列存分列存储的时间复杂度相同。基于选择率在不同层次之间进行选择下推[5,14]将被作为后续的研究目标。
对于MapReduce下的列存数据库存取,研究给出了相应的实现。基于对Hadoop HDFS的对象读取类RecordReader进行重载,研究引入了上述带有group类型的模式转换实现和块反序列化实现。其核心流程遵循RecordReader的约束,首先通过打开数据分片(Split)得到分布于HDFS中的数据块,然后按照块内进行数据分割。其中每个分割后的小块用以容纳某个列的连续实例的字节数组,其访问方式与本地模式相同,文件的头信息和模式在各个Map任务上保存一个副本。当一个Map任务执行Split的扫描的时候,基于HDFS的访问原则,在本地数据块上进行响应的封装操作。这里需要说明的是,HDFS的数据块默认值是128 MB、上限2 GB,这会使得大规模数据的查询请求被划分成很多小的Map任务,实验可以看到这一条件的影响。
5 实验验证分析
实验基于不同数据规模的TPCH基准进行。通过级联Customer、Orders、Lineitem三个表形成三级嵌套模式COL,生成具有不同选择列和不同选择率的查询条件进行测试和比较,以验证所提基于group方法的优劣。特别的,比较过程中引入了原始的Trevni实现和一个基于Trevni的Deremel实现——Parquet。将在行存Avro和这两类列存框架下进行综合比较。最后给出了真实数据Pubmed,通过对不同框架执行时间比较,分析研究给出了技术的适用性实验分析结果。
实验环境中硬件由一个Dell 720服务器和一套集群系统分别对各类存储框架在单节点和分布式环境下进行比较。其中,Dell 720服务器由2个Intel Xeon ES-2640 8核CPU构成,内存为320 GB,磁盘由180 MB/s的SCSI磁盘构成。单节点实验均在软件设计中采用单线程执行。集群由4节点构成,每个节点配备了24核AMD OperonTM1674CPU,内存128 GB,网络由40 Gb/s的InfiniBand网络连通。
实验1变投影列实验
通过在COL级联表的路径上分别选择不同数量的列验证存储框架的IO和内存效率,其中列的选择要求是级联外建关键字至少被选中。此外,其他的列平均分布于不同的层次上。实验分别选择总共4、6、8、10个列作为投影列进行元组提取验证,最终提取的元组以嵌套方式返回,以查询的平均执行时间作为度量标准。
如图6所示,不同列数对列存影响显著。其中图6(a)为磁盘IO环境下的执行时间,即每次查询需要清空所有系统缓存区,保证数据读取操作对磁盘的访问。显而易见,不管任何情况下Avro的行存结构需要读取所有列,因而其IO时间相对稳定;而几种列存框架仅需要访问所需的列数据,因此其执行时间大致与列数呈线性关系。图6(b)给出了装配时间,即在查询前先执行一次查询,保证第二次的统计时间不包含IO时间(实验内存远大于数据规模)。从图中可以看到上述结果依然成立,即三种列存框架的效率显著优于行存框架Avro。此外,由于同一层次的选择在Group中采用顺序反序列化,因而其效率优于原始Trevni的实现,而Parquet需要对投影的每个嵌套列进行一次较为耗时的装配,影响了其执行效率。

图6 嵌套分组与其他方法在磁盘和内存中执行时间比较
此外,一个显著的现象需要分析:磁盘环境下的执行时间仅比内存下略大。这是由于现有操作系统广泛采用磁盘预取技术,这使得IO和反序列化并行执行。图中的磁盘环境执行的同时内存中也并行执行反序列化,因而统计的时间可理解为IO时间;而没有IO时(图6(b)),统计时间等价为反序列化等内存操作的执行时间。
实验2不同层次上的变选择率实验
分别在同层和嵌套层次下进行变选择率实验,验证所提方法的优越性。
如图7(a)所示,选择在嵌套表的Lineitem层级上进行4列选择,比较行存和三种列存方法。由于该层为嵌套表COL的核心负载,因而可以看到列存较行存节省了大约3/4的执行时间(列存仅需读取Lineitem16列中的4列);同时,Group在这种没有映射的平坦扫描的查询中优势不明显。而图7(b)新增了三个层次中的另外两列,总计构成对COL三个层级一共10列的扫描。从执行结果上看,Group因为较小的级联组装代价,执行时间比Trevni节省了约2/3;此外上一个实验中Parquet的高代价分析在该实验结果中再次得到验证。
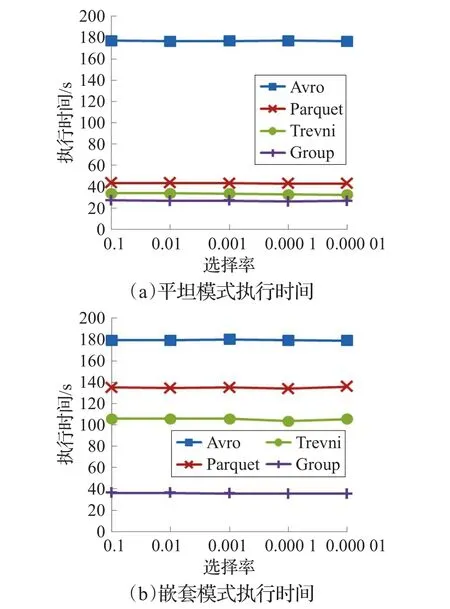
图7 嵌套分组在不同模式下的执行时间比较
实验3分布式环境效率比较
基于MapReduce对上述实验1进行分布式效率比较。由于Trevni的数据转换需要容纳于内存,无法转换160 GB的数据,因而实验引入另一个分布式数据库Asterix(DB)进行比较。对Group数据采用构建—归并方式进行加载,并基于不同Map物理任务限制验证不同任务数量下,4个节点配备时的平均执行时间。
图8和图9分别给出了不同并发度上的执行时间对比。从图中可以看到Group方式的效率在分布式环境下较其竞争对手更优越,其执行时间较次优的Parquet节省了3/5。同时可以看到当访问层次更深的时候Asterix的模式内置方式与Group方式相当。而伴随并发度的提升,Avro行存模式和Group受到的影响不大,均保持了大致线性的加速比;Parquet的执行时间加速比其他几种策略略低。这些都验证了Group方式的优化在分布式环境下的有效性。

图9 总数据量160 GB上16并发任务的执行时间
上述执行过程中,通过不断增加节点数量对上述4个查询的平均执行时间进行统计比较,如图10所示。可以看到不同存储架构和大数据平台的执行时间大致随节点数量增加而减少。其中研究给出的方法在不同规模下具有较好的可扩展性。

图10 总数据量160 GB上变节点数量查询平均执行时间
实验4真实负载执行效率比较
最后通过在Medline网站下载真实的Pubmed数据,共计1 800万嵌套记录,模式包含107个节点,共计80 GB。不同框架在磁盘和内存中的执行时间如图11所示。
图中显示非行存框架Parquet、Trevni和Group的执行结果基本与图6给出的结果一致。该模式较为复杂(模式节点多且层次更深),其中选择仅在很少的列上执行,因而相对于图6,图11中行存框架Avro的执行效率进一步显著降低。此外,可以看到Group较之于其他框架仍具有显著优势。

图11 嵌套分组与其他方法真实负载性能比较
6 结束语
提出一种行列混合式存储方法,通过引入分组形成逻辑上完整但局部上独立的列组物理单元。分析了现有单纯行存储和列存储的优势和潜在不足,并通过模式驱动设计行列混合物理存储结构。基于Trevni对所提方法予以实现以降低列存到元组转换过程中的开销并保证数据交换的有效性。通过union对存储结构进行优化,使得访问能够集中于有效的单元中。实验基于10亿条TPCH数据进行。结果表明所提方法较传统行列存储方法有显著提升。
猜你喜欢
电脑报(2022年13期)2022-04-12
铁道运输与经济(2022年3期)2022-03-17
空军工程大学学报(2021年4期)2021-09-23
甘肃教育(2020年14期)2020-09-11
电脑报(2020年24期)2020-07-15
电脑爱好者(2017年22期)2017-12-04
电影文学(2017年24期)2017-11-16
金融经济(2017年7期)2017-07-15
网络空间安全(2016年3期)2016-06-15
初中生之友·中旬刊(2015年4期)2015-06-10
