
基于MC-UVE、GA算法及因子分析对葡萄酒酒精度近红外定量模型的优化研究
2018-09-10 08:02:04王怡淼朱金林赵建新顾小红朱华新
发光学报 2018年9期
王怡淼, 朱金林, 张 慧, 赵建新, 顾小红, 朱华新
(1. 江南大学 食品科学与技术国家重点实验室, 江苏 无锡 214122; 2. 江南大学 食品学院, 江苏 无锡 214122;3. 浙江大学 控制科学与工程学院, 浙江 杭州 310027; 4. 张家港出入境检验检疫局, 江苏 张家港 215600;5. 食品安全国际合作联合实验室, 江苏 无锡 214122; 6. 江南大学 理学院, 江苏 无锡 214122)
1 引 言
葡萄酒在我国起源较早,有着悠久的历史。随着人们生活条件的改善以及我国酿酒技术的提高,葡萄酒越来越被大众所接受,成为餐桌上的必备饮品。葡萄酒的主要成分包括酒精、糖类、醇类、有机酸、维生素、多酚类物质等,每天适量饮用能够增强免疫力,抗氧化[1],预防癌症、动脉硬化[2]、糖尿病等。葡萄酒的品质鉴定主要依靠专业的品酒师进行感官评定或是对其进行理化检测,但是这两种方法不仅耗时耗力,而且前期投入大,对样品预处理要求高。因此为了快速智能地对葡萄酒品质进行检测,维护葡萄酒市场的稳定,亟需一种快速无损精确的检测方法。
近年来,国内外已有许多针对葡萄酒快速检测的研究。主要利用红外光谱技术[3-4]、高效液相色谱法[5]、气相色谱-质谱联用[6]等方法结合化学计量学对葡萄酒中的一些成分进行快速检测,其中又以红外光谱技术最为简便快速,能满足工业生产在线无损检测的要求。目前,红外光谱技术已经作为一种常用手段应用于产地溯源、多组分检测、过程控制等领域。吴正宗等[7]利用傅里叶红外光谱技术实现了黄酒中17种自由氨基酸浓度的快速检测;Basalekou[8]使用傅里叶红外光谱技术作为检测葡萄酒成熟的工具;Urbano-Cuadrado等[9]利用近红外光谱技术对葡萄酒样本的15个参数分别建立了PLS模型,大部分模型效果良好;Cozzolino[10]使用近红外光谱结合化学计量学对葡萄酒中的酚类化合物浓度进行预测。
通常,在建立葡萄酒酒精度定量分析模型时会通过谱图分析选择建模变量,这对光谱分析能力有较高的要求。但如果直接使用全光谱区域建模,往往会包括一些与样品无关的信息,导致模型的稳定性和预测性下降,并且对于大数据量的样本,使用全光谱建模会影响建模及检测效率。因此,选择合适的算法对变量进行筛选是很有必要的,不仅能够简化模型,还能提高建模和检测效率。最常用的变量选择方法有模拟退火(SA)[11]、遗传算法(GAs)[12]、人工神经网络(ANN)[13]、无信息变量消除法(UVE)[14]和连续投影算法(SPA)[15]。本研究主要基于GA和MC-UVE算法选择最有效的特征波长,进一步进行因子分析(FA)建立回归模型,并与PLS回归模型进行比较,探究葡萄酒酒精度定量模型的优化方法。
2 实 验
2.1 样品
试验的样品均来自张家港出入境检验检疫局,117个样品分别产自西班牙(n=11)、智利(n=38)、澳大利亚(n=16)、法国(n=42)、阿根廷(n=4)、美国(n=3)、意大利(n=3),密封保存在4 ℃的冰箱中。
2.2 近红外光谱采集
使用FT-NIR光谱仪(Thermo Fisher,USA)采集近红外光谱,每次实验前开机预热1 h。光谱采集范围为4 000~10 000 cm-1,扫描次数16次,分辨率8 cm-1。在透射模式下采集每个样品的光谱信息。将样品在20 ℃下放置1 h,然后将样品置于光程1 mm的矩形石英比色皿中,使用RUSULT软件采集光谱数据,光谱数据输出格式为吸光度。每个样品扫描10次,得到平均光谱作为最终谱图。
2.3 参考值的测定
酒精度含量测定采用酒精计法,按照GB/T 15038-2006测定。
2.4 因子分析方法(FA)
因子分析是基于概率回归模型框架下进行的[16],与传统的回归分析模型相比,概率模型具有以下几个优势[17]:(1)在概率建模框架下,能够将有效的最大期望(EM)化算法纳入到参数学习中;(2)可以有原则的方式制定概率模型的混合形式;(3)可以通过概率模型解决数据遗漏问题;(4)可以对概率模型进行进一步的贝叶斯(Bayes)处理,用于自动确定潜变量模型的维度。但是,PCA和PCR的概率模型都有一个限制假设:不同的过程变量使用相同的噪声方差。为了解决这个问题,将因子分析引入概率模型中。
传统的FA模型集中在高斯分布的潜变量t上,而原始测量变量x被视为t和噪声e的线性组合,其目的是找到最可能的参数集[18]。传统的FA模型只集中在一个无监督的数据集上,而监督的FA分析试图在一对数据集X和Y之间建立模型,X=[x1,x2,…,xn]T∈Rn×m,Y=[y1,y2,…,yn]T∈Rn×r,其中m代表X的测量变量的数量,r代表Y的测量变量的数量,监督FA模型的结构如下述方程式所示:
x=Axt+ex,
(1)
y=Ayt+ey,
(2)
其中Ax∈Rm×k,Ay∈Rr×k,分别是X和Y的因子载荷矩阵。t∈Rk×1,是潜在因子向量,而ex∈Rm×1、ey∈Rr×1分别是x和y的测量噪声。在本实验中,x代表波长,y代表酒精度。
2.5 蒙特卡罗无信息变量消除法(MC-UVE)
UVE可以消除无用的信息变量,通常使用稳定性来评估每个变量的可靠程度。在UVE算法中,使用leave-one-out(LOO)交叉验证,而对于MC-UVE来说,是使用MC交叉验证来获得稳定性的值,这两者的区别在于,LOO交叉验证一次只留一个样本用于验证,而MC交叉验证一次筛选出大部分样品以进行验证。这增强了验证对建模的影响,提高了选出最佳模型的可能性[19]。通过MC算法,从训练集中随机选择一定量的样本作为用于构建PLS子模型的训练子集,并且该过程重复M次。然后,计算PLS回归系数b(M×p)的矩阵,通过下式计算每个变量j的稳定性:
(3)
其中mean(bj)和std(bj)是变量j的回归系数的平均值和标准偏差。稳定性Sj的绝对值越大,相应变量越重要。
2.6 遗传算法(GA)
遗传算法是基于自然遗传和自然选择过程建立的一种优化方法,主要包括五个基本步骤:(1)变量编码;(2)初始化群体;(3)计算适应度值;(4)复制;(5)变异。不断重复步骤(3)~(5),直到达到终止条件[20]。应用遗传算法对近红外建模波长进行优化选择是基于该算法能够不断地对模型进行简化以及对有利于提高建模效果的波段或者波长点进行优化组合,从而达到最佳的预测效果[21]。
2.7 模型的评估
3 结果与讨论
3.1 葡萄酒近红外光谱
图1显示了不同产地葡萄酒样品的近红外透射光谱图,从图中可以看出,不同产地的葡萄酒具有相似的近红外吸收峰。其中,在4 996 cm-1处的吸收峰,其吸光度接近3,说明此时透过样品的近红外光很微弱,极易受到噪声等外界环境的影响,因此在分析时应把其剔除。同时 5 200 cm-1附近的吸收峰已经饱和,也应将其剔除。6 862 cm-1处较强的吸收峰与葡萄酒中碳水化合物和水的—OH基团的一级倍频吸收相关,4 300~4 500 cm-1波段内的小峰主要与样品中各组分的C—H键的合频吸收有关,而5 250~6 000 cm-1的峰则是与C—H键的二倍频吸收有关[23]。
从以上分析可以看出,近红外光谱吸收弱,大多与O—H、C—H、S—H和N—H等含氢基团的分子振动有关,并且谱带宽、重叠现象严重,很难对单一谱带进行精确归属。因此基于近红外光谱建立定量模型时,对建模特征变量的选取是有一定难度的,而光谱区域的选择又会直接影响模型的效果。

图1 葡萄酒样本近红外透射光谱图
3.2 样品的酒精度含量
葡萄酒样品中酒精度含量较为集中,符合用于建模的组分含量应尽量均匀分布的原则,因此可直接用于建模。参考国标法测定的葡萄酒样品中酒精度含量,作为建模时的标准数据,产自7个产地的共117个葡萄酒样品酒精度参考值如表1所示,将117个样品分为78个训练集样品和39个预测集样本。

表1 葡萄酒样品酒精度参考值
3.3 使用全谱结合PLS分析方法建立的酒精度回归模型
使用全谱范围进行PLS分析,建立回归模型。从表2可以看出,原始光谱建立的模型R2和RMSECV分别为0.891和0.301,表明基于近红外光谱建立葡萄酒酒精度PLS回归模型具有可行性,但是由于未对建模变量进行筛选,导致红外光谱数据中包含较多的噪声和无关信息,使得模型的预测能力不高。利用预测集样本对该模型进行验证,预测结果见表3。
表2训练集样本酒精度PLS模型参数
Tab.2 Main parameters in PLS models of alcohol content of training samples

PretreatmentCalibrationCross-validationRMSECR2RMSECVR2Full0.2380.9330.3010.891

表3 不同模型的酒精度预测集
3.4 基于MC-UVE方法的变量选择


图2 使用MC-UVE算法对酒精度预测的变量的稳定性分布
Fig.2 Stability distribution of variables for prediction of the alcohol content by MC-UVE method
3.5 基于GA算法的变量选择
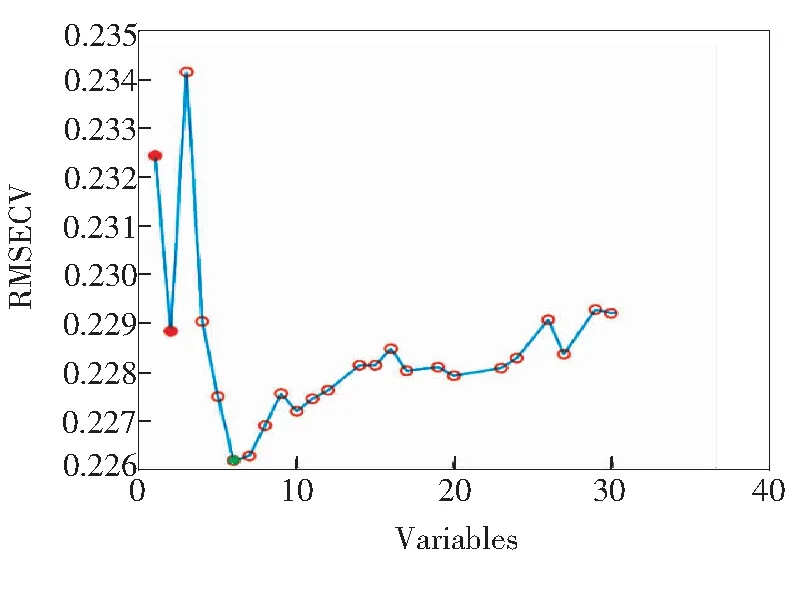
图3 RMSECV与所选变量数量的变化关系
Fig.3 Variation of RMSECV with the number of selected variables
3.6 因子分析
图4为两个模型的预测结果的相关性,从图中可以看出,采用MC-UVE-GA-FAR模型的实测值和预测值的相关性明显高于使用全光谱所建模型,说明MC-UVE、GA算法和FA分析能显著提高模型的性能。并且MC-UVE和GA算法是对变量进行自动选择,不需要有较强的红外光谱分析能力;用于建模的变量数仅为6个,有效地提高了建模及检测效率,更加适合于实际生产应用。

图4 预测集酒精度实测值与预测值散点图。 (a)全光谱PLS模型结果;(b)MC-UVE-GA-FAR模型结果。
Fig.4 Scatter plot of measuredversuspredicted alcohol content of the prediction set. (a)Results of full spectra-PLS model. (b)Results of MC-UVE-GA-FAR.
4 结 论
本实验是基于葡萄酒酒精度快速无损检测要求的优化研究。对117个葡萄酒样本进行近红外光谱采集,以采集到的光谱数据的平均值为基础,利用MC-UVE和GA算法以选择最佳变量,同时建立PLS回归模型和FA回归模型。结果表明,MC-UVE-GA-FAR模型的效果最佳,预测集R2为0.946,RMSEP为0.215,均优于MC-UVE-GA-PLS模型,说明FA分析能够提高模型的预测能力。并且所需的建模变量数仅为6个,简化了模型,提高了预测效率。本实验证明MC-UVE和GA算法是变量选择的有效方法,结合FA分析能够实现模型的简化及优化,满足实际生产应用的要求,实现葡萄酒酒精度在线快速无损检测。
猜你喜欢
酿酒科技(2024年2期)2024-04-02 01:46:18
北京航空航天大学学报(2022年8期)2022-08-31 08:58:58
基层中医药(2021年3期)2021-11-22 08:08:04
食品与发酵工业(2019年1期)2019-01-29 10:26:02
收藏界(2018年3期)2018-10-10 05:34:08
中国商界(2017年4期)2017-05-17 04:36:48
中国光学(2015年5期)2015-12-09 09:00:28
食品工程(2015年3期)2015-12-07 10:20:53
食品工业科技(2014年23期)2014-03-11 18:18:54
无机化学学报(2014年1期)2014-02-28 17:30:08
