
基于MapReduce的改进CHI文本特征选择机制
2018-09-07 01:33:12陶永才
小型微型计算机系统 2018年8期
石 磊,巴 阳,陶永才,卫 琳
1(郑州大学 信息工程学院,郑州 450001) 2(郑州大学 软件技术学院,郑州 450002) E-mail:ieyctao@zzu.edu.cn
1 引 言
文本分类是数据挖掘和机器学习领域的研究热点之一,特征选择作为文本分类的核心主要目的是降维[1].特征选择的好坏将会直接影响文本分类的准确率.CHI统计法(chi-square test)又称卡方统计法,是数理统计中检验两个变量独立性的方法.CHI 统计法是最常用的文本特征选择方法之一[2].
MapReduce[3]是Google公司处理大规模数据而提出的基于分布式并行计算的编程模型,MapReduce的核心策略是分而治之,将大的任务分解成若干个小任务进行处理[4].通过对数据的拆分与组合不仅有效地提高了数据并行处理能力也极大地改善了系统性能.
传统CHI统计法只关注文档频率,一些文档频率低但特征词频率高的特征词将不会被选为特征项;同时,放大了在指定类别中出现很少但在其他类别中出现较多的特征词在该类中的权重.
为解决上述问题,本文提出一种基于MapReduce的CHI文本特征选择机制,主要贡献如下:
1)对传统CHI统计法公式进行改进,引入类内频数解决忽略高频特征词的问题,同时引入类间方差解决放大外围特征词权重的问题,从而提高CHI统计法的特征选择准确度,从根本上提高文本分类的精度;
2)提出基于MapReduce的CHI文本特征选择模型,将文本处理分为独立可并行的两个阶段:文本训练阶段和文本分类阶段,充分利用MapReduce模型处理海量数据的优势,优化文本训练和分类的模式,从而提升文本分类的效率.
2 相关工作
传统CHI统计法优点是实现简单,算法复杂度低,但是也存在明显不足,众多研究者对其做出改进.文献[5]在实际文本数据和CHI特征选择算法的基础上,提出了一种特征选择算法.对于分布不均匀的特征数据集,该算法适当地提高了集中在少数文档中的词的权重;文献[6]提出了一种基于 CHI 统计和信息熵的改进型 TFIDF 特征加权方法,提高了特征项权重计算的准确性;文献[7]提出一种基于概率的CHI特征选择方法,结合特征词概率和文档概率来衡量文档频度,在不均衡数据集上有良好表现.上述研究在多个方面不同程度地弥补了传统CHI统计法的不足,提高了特征词的质量与文本分类的精度.但是,忽略了大量文本文件对文本分类执行速率的影响.
文献[8]利用MapReduce强大的并行处理能力对分类器进行训练和预测,设计并实现了并行分类训练和预测算法,提高了大型数据多类问题的准确性和效率;文献[9]则提出了基于MapReduce的并行K-means文本聚类算法,采用优良的初始质心选择策略来提高K-means聚类效果,然后设计出适用于MapReduce平台的文本并行聚类模型.从上述研究可以发现MapReduce技术的成熟应用为各种文本分类方法在大规模数据的处理上开辟新的道路.本文提出的基于MapReduce的CHI文本特征选择机制,在改进传统CHI方法的同时采用MapReduce框架对文本分类进行并行处理,不仅有效地提高了文本分类的精度,同时也还提升了文本分类的效率.
3 研究背景
CHI统计方法是分类效果较好的文本特征选择方法之一[6].CHI统计方法通过观察实际值与理论值的偏差来确定理论的正确与否[10].在实际应用中,经常先假设指定的两个变量相互独立,然后比较观测值和理论值的偏差程度,若偏差在预先给定的偏差阈值之内,则可认为造成的误差是由于测量不精确或小概率事件发生,此时判定原假设成立,即两个变量相互独立;若偏差超过预先给定的偏差阈值,则可认为两个变量存在相关性,此时判定原假设不成立,即两个变量相互关联.若用DI表示偏差程度,E表示理论值,xi表示x所有可能的观测值(x1,…,xn),则通过计算得到的DI与偏差阈值对比,从而判断原假设是否成立.计算公式如式(1)所示.
(1)
将CHI运用到特征选择方法中会有一定差异,因为在实际情况中无法给定一个合适的偏差阈值与DI进行对比.假设特征词ti与类别Cj不相关,那么特征选择的过程变成为每个特征词ti计算与类别Cj的DI值,而后降序排列,取规定的前k个.假设有N篇文档,其中M篇是有关类别Cj的,若考察特征词ti与类别Cj之间的相关性,则有如下定义:
1)A表示包含词ti且属于类别Cj的文档数;
2)B表示包含词ti但不属于类别Cj的文档数;
3)C表示不包含词ti但属于类别Cj的文档数;
4)D表示不包含词ti也不属于类别Cj的文档数.
为了更直观地解释字母的含义,引入情形分析表,如表1所示.
因此,对于给定的特征词ti与类别Cj之间的相关性的CHI特征选择计算如式(2)所示.
(2)
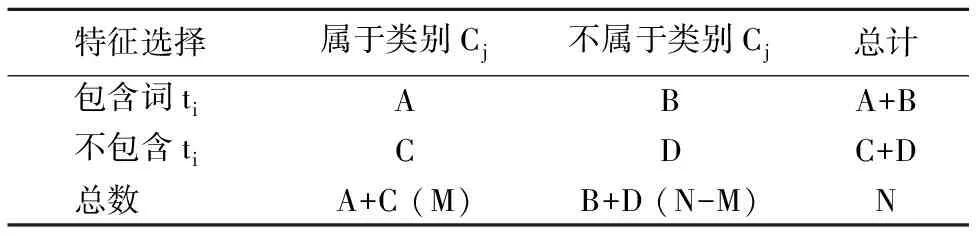
表1 情形分析表Table 1 Contingency table
传统CHI方法虽然效果出色,但仍存在明显的不足,由公式(2)可发现:
1)传统CHI方法倾向选择文档频数高的特征词,即只关注文档频数,而忽略了特征词频数,导致那些只在某类文档中出现频率高的特征词被忽略掉,反而选择了在多数类别的多数文档中偶尔出现的特征词.
2)放大了在指定类别中出现频率较低,而在其他类中出现频率较高的特征词对该类DI值的影响,在公式(2)中体现为A、D值很小,B、C值很大,此时有(AD-BC)2很大,则这样的特征词也会被挑选出来,实际上,却并不需要这一类特征词.
4 基于MapReduce的CHI文本特征选择
4.1 改进的CHI方法
本文在原有CHI方法的基础上进行改进,通过引入类内频数和类间方差两个参数,有效地解决了传统CHI方法忽略高频特征词和放大外围特征词权重的问题.
类内频数是指特征词在某类别所有文档中频数的最大值,由于传统CHI方法只专注于文档频率,导致那些文档频率低,但类内频率高的特征词被过滤掉.本文用Itfij表示特征词ti对于类别Cj的类内频数,计算公式如式(3)所示.
(3)
其中,tfiju为特征词ti在类别Cj下的文档du中出现的次数,M为类别Cj的文档数(同表1中的M).由式(3)可知,tfiju越大,说明特征词ti在类别Cj下的文档du中出现的频数越大,则将此特征词作为这个类别的候选特征词的可能性越大.
类内频数可以有效解决忽略高频特征词的问题,而引入类间方差则可以消除传统CHI方法放大外围特征词权重的影响.外围特征词是指:在指定类别中出现次数很少,而在其他类别中出现次数很多的一类特征词.显然这类特征词的分类能力较弱.类间方差用来衡量特征词ti在类别Cj中出现的频数与特征词ti在所有类别文档中出现的频数均值的偏差程度.记作D(ti),计算公式如式(4)所示.
D(ti)=[dfj(ti)-Vdfj(ti)][dfj(ti)-Vdfj(ti)]2
(4)
其中,dfj( ti)表示特征词ti在类别Cj中出现的频数,Vdfj( ti)表示特征词ti在所有类别文档中出现的频数均值,计算公式如式(5)所示,式中m表示类别数.
(5)
在式(4)中,若dfj( ti)-Vdfj( ti)>0,且D(ti)值很大时,说明特征词ti在类别Cj中出现频数比特征词ti在所有类别文档中出现的频数均值大,且大得很多,这样的特征词有更好的分类能力,是期望得到的目标特征词;若dfj( ti)-Vdfj(ti)<0,但D(ti)的绝对值很大时,说明特征词ti在类别Cj中出现频数比特征词ti在所有类别文档中出现的频数均值小,且小很多,这样的特征词的分类能力较差,是需要被淘汰掉的特征词.
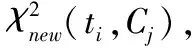
(6)
4.2 基于MapReduce的CHI文本特征选择机制
基于MapReduce的CHI文本特征选择机制流程图如图1所示.

图1 机制流程图Fig.1 Mechanical flow chart
从图1中可以看出基于MapReduce的CHI文本特征选择模型分为两部分:文本训练阶段和文本分类阶段.
4.2.1 文本训练阶段
图2是基于MapReduce的CHI文本训练模型.对于给出的训练文本集,首先进行预处理,包括分词断句、去停用词等,其中,经过预处理后的文本集合为一阶训练集,然后将一阶训练集输入到第(1)个MapReduce过程中.
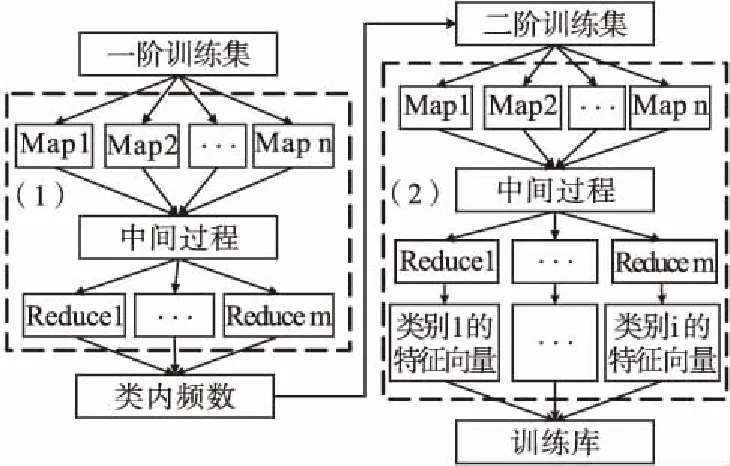
图2 基于MapReduce的CHI文本训练模型Fig.2 CHI text training model based on MapReduce
第(1)个MapReduce过程的作用是计算特征词的类内频数,一阶训练集按块划分入不同的节点执行Map函数,公式(3)为Map函数的核心,得到基于<特征词,<类别,tfiju>>的键值对
将第(1)个MapReduce过程的结果记为二阶训练集,然后输入到第(2)个MapReduce过程.第(2)个MapReduce过程的作用是得到每个类别的特征向量.二阶训练集同样按块划分为不同的节点执行Map函数,Map函数计算各个参数,根据公式(4)计算出类间方差,进而得到卡方值,公式(6)为Map函数的核心,得到基于<特征词,<类别,卡方值>>的键值对
算法1.文本训练算法
输入:一阶训练集;类别C;文档d;特征词t;
输出:各个类别特征向量;
1 Map1
2 {
3 //计算一阶训练集中特征词的类内频数
4foreach du∈Cjdo
7 输出中间键值对
8endfor
9endfor
10 }
11 Reduce1
12 {
13 输入中间键值对
14foreach termIDdo
16 输出键值对
17endfor
18 }
19 Map2
20 {
21 //获取类别的特征向量
22 输入键值对
23foreach termIDdo
25 计算卡方值CHIValue;
26 输出中间键值对
27endfor
28 }
29 Reduce2
30 {
31 输入中间键值对
32foreach classIDdo
33 CHIValue倒序排列,并取前k个;
34 输出类别特征向量;
35endfor
36 }
4.2.2 文本分类阶段
图3是基于MapReduce的CHI文本分类模型.分类模型的输入数据集是经过预处理后的测试文本集,记作一阶测试集,然后用维向量表示一阶测试集,输入到第(3)个MapReduce过程.文本分类算法如算法2所示.
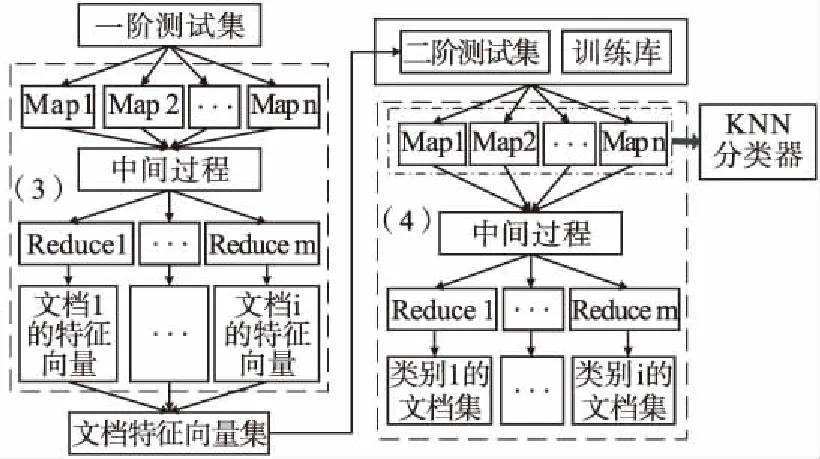
图3 基于MapReduce的CHI文本分类模型Fig.3 CHI text classification model based on MapReduce
算法2.文本分类算法
输入:一阶测试集;文档d,特征词t;
输出:类别文档集;
1 Map3{
2foreach ti∈ dudo
4 输出中间键值对<
5endfor
6 }
7 Reduce3{
8foreach docIDdo
10 输出文档特征向量;
11endfor
12 }
13 Map4{
14 输入二阶测试集;
15foreach dudo
17 输出中间键值对
18endfor
19 }
20 Reduce4{
21foreach classIDdo
23 输出类别文档集;
24endfor
25 }
第(3)个MapReduce过程的作用是计算特征词ti在测试文档du中出现的次数,然后生成文档特征向量集.需要说明的是本部分过程只关注某特征词在某篇文档中出现的次数,而不关心文档类别,但这里可以用tfiu表示特征词ti在测试文档du中出现的次数.一阶测试集按块划分入不同的节点执行Map函数,Map函数的作用是计算特征词的tfiu,得到基于<特征词,文档,tfiu>的键值对<
将第(3)个MapReduce过程的结果归档集合,并记为二阶测试集,和文本训练阶段生成的训练库一并输入到第(4)个MapReduce过程.第(4)个MapReduce过程的作用是用KNN分类器[11]分类二阶测试集.经过KNN分类后得到基于<类别,文档>的键值对
5 性能评估
5.1 实验数据
本文采用复旦大学自然语言处理小组整理收集的文本分类语料库*语料库查载于自然语言处理与信息检索共享平台[EB/OL].2017-1-15,http://www.nlpir.org/?action-viewnews-itemid-103.作为训练集和测试集,从中选取六种类别的部分文档作为训练集文档和测试集文档.选取情况如表2所示.

表2 测试集和训练集文档选取情况Table 2 Testing set and training set document selection
5.2 实验设置
本文实验设置情况如下:
1)可行性验证实验.用来检验本文MapReduce机制对改进CHI方法是否有不良影响.实验对象设置为:本文提出的改进CHI方法分别运行在普通PC机上和Hadoop单节点上.
2)性能对比实验.用来检验本文提出的改进CHI方法的性能.对比实验对象设置为:传统CHI统计法、论文[12]提出的改进CHI方法(用CHI-F表示)、本文提出的改进CHI方法.
3)效率测试实验.用来测试本文提出的改进CHI方法在Hadoop平台上的效率.
实验设备具体配置如下:CPU为Intel Xeon E5620 2.66 GHz,8G内存,2TB硬盘,操作系统为Ubuntu 14.04,Hadoop版本1.2.1,Java版本1.7.0.实验中特征向量的维度为1000,分类方法KNN中的K取值为20.
5.3 评价指标
1)查准率用来反映文本分类的健全性,即分类结果的准确性[13],用P表示查准率,其计算公式如式(7)所示.
(7)
2)召回率用来反映正确分类的能力,用R表示召回率,其计算公式如式(8)所示.
(8)
3)F1值是综合以上两种评价标准对文本分类进行整体评价,其计算公式如式(9)所示.
(9)
4)加速比用来衡量程序并行化的性能[14],用Ts表示加速比,其计算公式如式(10)所示.
(10)
5.4 性能评估
可行性验证实验结果如表3所示.
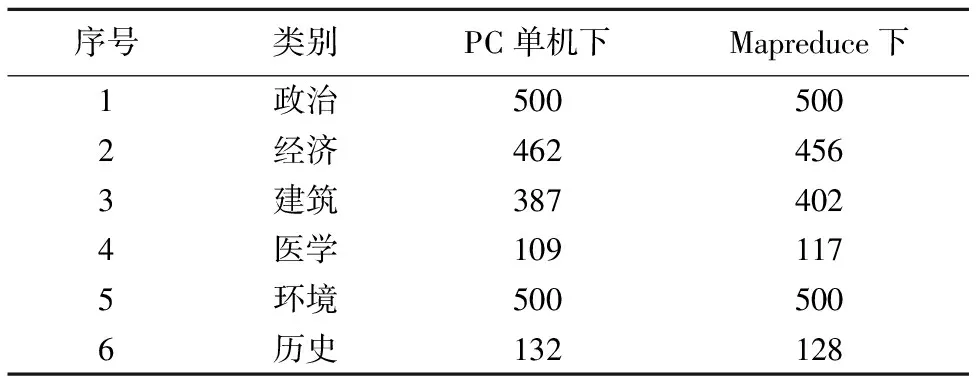
表3 PC单机和MapReduce下文本的向量维度Table 3 Vector dimension in PC and mapreduce
分别将改进的CHI方法运行在Hadoop单节点平台和一台普通PC机上.通过表3中的实验数据可以发现,两种环境下最终生成的文本向量维数差异很小.综上所述,MapReduce
技术的引入并未对CHI方法在文本向量维度产生不良影响.
性能对比实验结果如表4所示.
从表4中得到的三种CHI方法查准率和召回率,根据式(9)可以计算出各个方法的F1值,F1值对比结果如图4所示.

表4 实验结果及对比Table 4 Experimental results and comparison
由实验数据可以看出:传统CHI方法在本实验数据集上的F1值最高也只达到62.56%,对于样本较少的“医学”、“历史”小类预料,其F1值更低;CHI-F方法在本套数据集上的测试结果已有明显改善,F1值较高时能达到79.38%,对于样本较少的“医学”、“历史”,其F1值也有显著提升;本文提出的CHI方法,F1值比其他两种方法的F1值明显提升,最高值几乎能达到90%.结合表4发现传统CHI方法中小类预料集F1值偏小是因为“医学”和“历史”的训练集相对于整个训练集的比重较小,在没有过滤算法处理的情况下,将会选中训练集中大量外围特征词,导致分类效果不佳;CHI-F方法在一定程度上改善了小类预料集F1值偏低的现象;本文提出的CHI方法通过类内频数和类间方差的共轭修正,在小类预料集查准率、召回率、F1值上,均比CHI-F方法有进一步的提高.

图5 系统加速比Fig.5 System speedup
效率测试实验用来检验Hadoop集群中DataNode节点数目的增加是否对模型的性能产生影响.实验观察基于MapReduce的CHI文本特征选择机制的实验运行时间和加速比.其中,多节点Hadoop集群分别由3、6、9、12、15个DataNode节点组成.实验结果如表5所示.
表5中的实验运行时间是经过多组实验得出的平均值,根据式(10)计算出系统加速比,实验结果如图5所示.
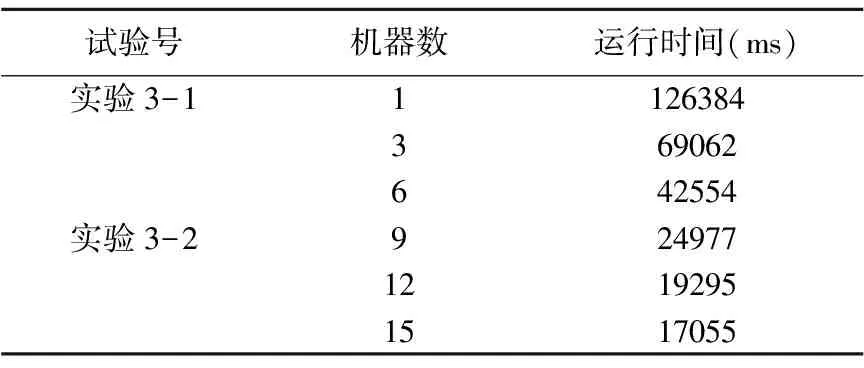
表5 实验运行时间Table 5 Experimental running time
由图5可知,在初始阶段当Hadoop节点数较少时,本文提出的基于MapReduce的CHI文本特征选择机制加速比提升不明显,当Hadoop节点数增加至9台,加速比已有显著提升,综合来看,本文提出的优化机制的加速比随着DataNode节点的增加有显著增长.
6 总结与展望
传统的CHI方法虽然广泛使用于文本分类中,但是算法忽略高频特征词和放大外围特征词权重的问题使得算法在实际的应用中分类精确度偏低.本文针对上述问题,在改进传统CHI方法的同时结合MapReduce技术,提出一种基于MapReduce的CHI文本特征选择机制.实验结果表明,本机制不仅能有效提高文本分类精度,也提升了文本分类的效率.
本文提出的基于MapReduce的CHI文本特征选择机制对小类预料集的分类精度虽然提高很多,但还有上升空间,未来考虑针对小类预料集以及含大量噪声词的预料集进行专门研究;同时,MapReduce技术是当前大数据应用的核心,能否将本文MapReduce模型适配到其它算法中也是未来研究的另一个方向.
猜你喜欢
电脑爱好者(2020年18期)2020-09-26 14:53:01
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
电脑爱好者(2017年9期)2017-06-01 21:38:08
电子制作(2017年23期)2017-02-02 07:17:06
西北工业大学学报(2015年4期)2016-01-19 03:31:47
中文信息学报(2015年4期)2015-04-21 08:29:12
振动工程学报(2014年4期)2014-03-01 01:15:41
计算机工程(2014年6期)2014-02-28 01:26:36
武陵学刊(2011年5期)2011-03-20 20:59:04
