
一种面向社区发现的高鲁棒性标签传播算法
2018-09-07 01:33:12郑少强赵中英冯慧子
小型微型计算机系统 2018年8期
郑少强,赵中英,2,3,冯慧子,李 超,2
1(山东科技大学 计算机科学与工程学院,山东 青岛 266590) 2(中国科学院 深圳先进技术研究院,广东 深圳 518055) 3(桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004) E-mail:zyzhao@sdust.edu.cn或 lichao@sdust.edu.cn
1 引 言
社会网络是指个体间交互形成相对稳定的社会关系,这种关系通常被形式化表示成图的形式,图中节点表示个体,边表示个体之间存在的某种联系.社区是社会网络最重要的组成单元结构,也是分析社会网络规律、性能等方面重要的参考依据.所谓社区发现,是指把网络中联系紧密或具有相似特征的节点划分为一个簇,即同一社区内部节点间链接稠密,不同社区之间的链接稀疏.研究网络的社区结构有助于揭示网络的组织结构、拓普信息等特性,具有十分重要的意义[1],因此,社会网络中的社区发现引起学术界与产业界学者的广泛关注[2-4].
目前,针对社区发现的研究方法层出不穷,依据采用的求解策略问题,可分为基于优化的社区发现方法和基于启发式的社区发现方法.基于优化的方法是通过设置目标函数来实现社区划分,代表性方法有谱方法和模块性最大化方法[5-7]等;基于启发式策略的方法是通过设置启发式规则寻找最优社区划分,代表性算法有GN算法[8]和WH算法[9]等.此外像基于层次聚类的社区发现方法也能有效划分社区结构,但这种方法一般具有较高的时间复杂度,不适用大规模网络挖掘.2007年,Raghavan等人[10]提出一种基于标签传播的快速社区发现算法LPA(Label Propagation Algorithm),该算法具有线性的时间复杂度,在处理大规模网络时具有较高的时间效率,并且不需要优化预定义的目标函数,预知社区数量等先验知识,因此得到学者的广泛关注.但LPA算法在更新节点标签过程中存在不确定性,导致结果准确性和稳定性常不能达到预期效果.目前不同学者对原始的LPA算法进行改进,其中LPAm[11]算法是一种带约束的标签传播算法,它将LPA等价为一个优化问题来发现社区结构;COPRA算法[12]可以通过标签传播发现重叠社区结构,COPRA算法为每个节点保留若干个社区标签,并进行标签传播最终节点得到多个标签节点信息;赵卓翔[13]等人对初始网络的部分节点进行分析处理,并且从部分节点进行标签传播,在LPA算法的基础上提高了社区发现质量,黄佳鑫[14]等人在节点重要性和影响力的基础上对其标签传播的过程进行优化,该方法虽然提高了社区发现的质量,但同时增加了算法运行时间.
本文主要工作是在标签传播算法基础上,融合考虑节点度数和聚集系数对网络节点的初始标签进行分配,从而减少初始节点标签分配数量,提高标签传播的稳定性和社区发现质量,在此基础上减少标签传播过程的迭代次数.
2 相关工作
2.1 聚集系数概念
复杂网络中,节点的聚集系数(Node Clustering Coefficient)是考虑节点的邻居节点间关系紧密程度的重要参考依据之一,节点的聚集系数可以表示为该节点的所有邻居节点间的实际连边数与所有可能存在连边数的比值.
一般地,假设在一个无向无权的复杂网络中节点i的度为ki,表示节点i有k个邻接点,而这些邻接点之间所有可能存在的连边数为k·(k-1)/2.如果节点i的邻接点之间的实际连边数为E(i),用CC(i)表示该节点的点聚集系数,则表示为:
(1)
显然,节点聚集系数反应了节点的邻居节点之间的关系.聚集系数越大,说明节点近邻之间的关系越密切,他们属于同一个社区的概率也就越大,反之聚集系数越小则它们联系越疏远,属于同一个社区的概率也越小.
2.2 标签传播基本思想
标签传播算法[10](Label Propagation Algorithm)是一种启发式的算法,其启发规则是不断在节点及近邻间传递标签信息,经过多次迭代,属于同一社区节点的标签将趋于一致.其核心思想是给所有的节点标记唯一标签,对每个节点,它的标签代表所属社区,对节点进行标签传播的过程,即是对每个节点的标签进行更新,其标签选择权主要取决于该节点的邻居节点的标签分布情况,选取邻居节点标签数最多的节点来更新自己节点的标签,依次迭代直到所有节点的标签不再发生变化,最终标签相同的节点属于同一个社区,从而达到划分社区目的.
2.3 标签传播步骤
1)网络初始化阶段,为网络中每个节点分配唯一的标签,表示该节点所属的社区编号;
2)对图中的所有节点以随机的顺序进行标签的迭代更新.在每次迭代过程中,每个节点的标签由其邻居节点的标签中数目最多的那个标签来决定,如果邻居节点中有数目相同的最多个标签存在,则在这些数量相同的标签中随机选取一个作为该节点的标签;
3)反复迭代,直到其所有节点都拥有邻居节点中数目最多的标签为止;
4)具有相同标签的节点就可以归在同一个社区中,完成社区划分,算法结束.
3 LPA_D_CC算法
在社会网络中,节点度被认为是重要的评价指标之一,它能够直观衡量节点在网络中的重要性,一般来说,节点度数越大,说明节点在网络中的重要性越明显,其相邻节点数越多,形成社区的概率越大.而在社会网络中节点的邻居节点之间的关系也同样重要,如果一个节点与它邻居节点之间可以形成稳定的三角关系这说明节点之间存在紧密的联系,且具有某种相同性质的可能性越大.
目前所做的工作中,大多数标签传播算法只考虑算法在标签更新阶段情况,未在网络初始化过程中对节点的标签进行处理,这种情况导致标签传播存在不稳定因素.本文针对这一问题在网络初始化阶段对节点标签赋值做一些改进措施,从而改善节点标签传播随机性问题,同时减少传播过程的迭代次数,提高社区划分的稳定性和划分质量.
3.1 主要思想及步骤
本文主要考虑标签传播初始阶段,结合节点度数和聚集系数两方面对初始化节点赋值进行处理.首先在给定网络中计算节点度数,并根据度数大小对节点进行排序.当节点度数相等时,分析节点的邻居节点之间的关系,即聚集系数大小,根据两个判定条件对网络所有节点做影响力排序.然后对影响力高的节点,访问该节点和它邻居节点并将它们构成一个集合,对没有访问过的节点,继续对影响力高的节点进行访问,将它和它没有被访问过的邻居节点构成集合,每个节点只能被访问一次,依次访问直到所有节点被访问过为止,这样构成若干个集合.对若干个集合内的节点赋相同标签,集合之间标签不同.根据网络中已赋予的标签节点进行标签传播,最终当所有节点标签都拥有邻居节点标签数最大的标签算法结束,标签相同的节点属于同一个社区.该方法主要分为两个阶段,第一阶段是网络节点赋标签的准备阶段;第二阶段是节点赋标签和标签传播过程.
3.2 网络节点准备阶段
第一阶段主要根据节点度数和聚集系数对网络中节点影响力进行排序,并对所有节点划分集合,为下一步的标签传播做准备.
算法1.基于度与聚集系数的节点影响力排序算法
输入:网络G(V,E)
输出:网络G的若干集合Si
1.网络初始化G(V,E);
2.计算V(G)度数D(V)并排序
3.如果D(V)相等,根据节点聚集系数CC(V)排序;
4.FOR V IN S:
IF V 没有被访问过;
将 V 加入集合S中;
标记节点V;
FOR U IN V的邻居节点:
IF U 没有被访问过:
将U加入集合S中;
标记加入过的节点U;
END
END
END
END
返回若干集合Si
3.3 社区划分阶段
第二阶段是对网络中所有节点赋标签,对于若干个集合的节点,我们认为集合内节点在某方面具有相同的特性,将这些集合中的节点赋予相同标签,利用标签传播原理根据每个节点邻居的标签数量决定自己标签,依次迭代直到所有节点的标签不再发生变化,完成社区划分.
算法2.基于LPA的社区发现算法
输入:若干个集合Si
输出:网络G的社区划分
1.针对若干个集合Si;
2.将这些集合Si赋予不同标签,集合中节点的标签相同;
3.根据标签传播理论,对节点标签进行传播;
4.反复迭代直到节点标签不再发生变化,算法结束;
5.标签相同的节点属于同一个社区.
4 实验结果与分析
4.1 实验数据及运行环境
本文选用社会网络中常用的四个数据集对算法进行分析验证,实验数据采取Mark Newman等人个人网页上提供的网络数据集,包括Karate club、Polbooks、Netscience和Power数据集.数据集详细描述如下:
1)Karate Club空手道俱乐部网络:Karate Club空手道俱乐部网络数据集是Zachary用三年时间观察了美国一所大学空手道俱乐部成员之间的关系构成的社会网络.网络中节点表示俱乐部成员,节点之间的连边表示成员之间的朋友关系.该网络包括34个节点、78条边.
2)Polbooks:该数据集是V.Krebs从Amazon上销售的美国政治相关书籍页面上建立的网络,网络中的节点表示在Amazon在线书店上销售的美国政治相关图书,边表示一定数量的读者同时购买了这两本书的情况.政治书籍网络包括105个节点、441条边.
3)Netscience:科学家共同作者网络描述的是在网络上科学家之间的合作关系,通过网络上科学家合作实验以及共同提出相关理论构成的关系网络.网络中节点表示网络上的科学家,边表示科学家之间的合作关系.该网络是由1589个节点和2742条边构成.
4)Power:美国西部地区电网拓扑数据集网络,该网络主要涉及美国西部地区发电设备之间的关系.网络中的节点表示发电器、变压器和变电站设备,网络中的边表示这些设备之间高压输电的关系.美国西部电网一共由4941个节点和6594条边构成.

表1 实验数据描述Table 1 Description of experimental data
所有实验均运行于配置为AMD A4-3300M APU with Radeon(tm)HD Graphics 1.90GHz、2核处理器且内存为4GB的Windows机器上.算法均在pycharm 4.5环境上,用python2.7编程语言实现.为避免实验过程中偶然性的发生,我们取实验运行100次的平均结果作为最终结果进行分析验证.
4.2 评价指标
本文根据模块度评价指标评价社区划分情况,模块度(Modularity)由Newman[15]等人提出,该度量是对于给定网络的任意社区划分都有一个评价值,以此判断社区发现算法的优劣.模块度定义为社区内实际连接数目与对应随机网络同等连接情况下社区期望连接数目之差,用来定量地刻画网络中社区结构的优劣,模块度的形式化定义如下:
Q=∑i[eii-(ai)2]
(2)
其中,eii是节点在社区i内部的边的权值所占的比例,ai表示与社区i中节点相关联的所有边的权值所占的比例,ai表示为:
(3)
其中,kv表示节点v的度,cv表示节点v所在的社区,m表示网络中总边数.模块度Q的取值在0和1之间,Q值越接近1说明社区结构越明显.
4.3 实验结果
我们对改进的LPA_D_CC算法和原始的LPA算法在四种数据集上进行对比实验,为验证算法划分质量和稳定性等,我们从模块度、迭代次数等方面进行分析与比较.
4.3.1 Karate数据集可视化效果
Karate数据集具有标准的社区划分,其中34个成员节点主要分成以主管(节点0)和校长(节点32)为中心的两个集合.我们将LPA算法和LPA_D_CC算法在Karate数据集上做可视化效果,如图1所示,原始的LPA算法在社区划分过程中并没有合理地将这两个主要节点作为影响力较大节点进行社区划分,并分成四个社区集合.LPA_D_CC算法可以稳定的将Karate数据集以节点0和32为中心划分为两个社区,图中不同颜色代表不同社区.

图1 Karate数据中的社区可视化Fig.1 Visualization of communities detected in Karate data
4.3.2 社区发现数量
为了验证社区划分的稳定性,我们从社区划分数量方面分析,如表2所示,原始LPA算法在社区划分数量方面起伏较大,并随着网络规模增大方差变大,稳定性效果差.LPA_D_CC算法社区划分数量方面比较稳定,社区数量变化浮动小,社区划分数量的随机性弱,表现出算法的稳定性.
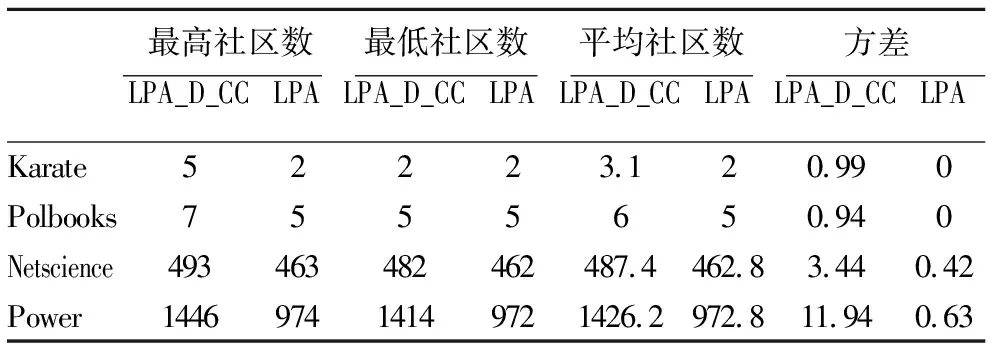
表2 社区数量对比Table 2 Quantitative comparison of communities
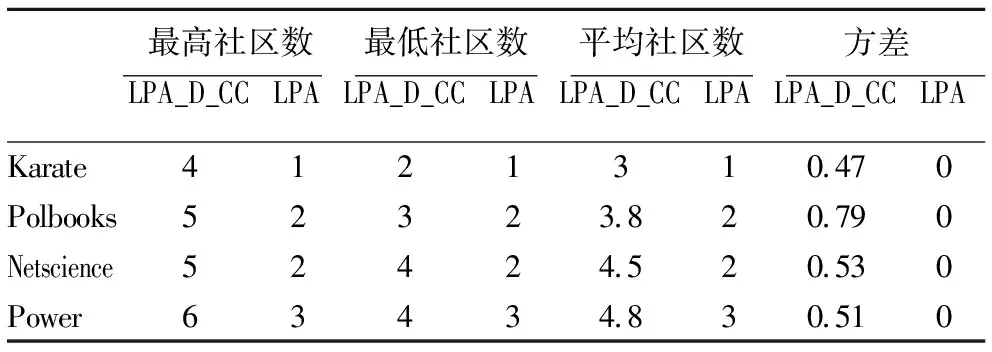
表3 迭代次数对比Table 3 Comparison of iterations
4.3.3 迭代次数
原始LPA算法在传播过程中,每次迭代都可能面临随机选择标签情况,这将导致社区划分结果不稳定,尽量减少迭代次数能有效降低社区随机性产生.原始LPA算法与本文提出的LPA_D_CC算法在社区划分过程中的迭代次数对比结果如表3所示.从表3可以看出,LPA_D_CC算法在任何情况下的迭代次数都小于LPA算法,并且迭代次数变化幅度小,远远优于原始LPA算法.
4.3.4 模块度评价
为了验证算法能够降低随机性造成模块度较低的影响,本次实验从模块度变化范围和平均模块度方面做了分析.从表4可以看出,LPA算法虽然在少数情况下模块度值要高于LPA_D_CC算法,但大部分时间LPA_D_CC算法模块度值优势明显.从平均模块度(图2)角度分析LPA_D_CC算法平均模块度值都高于LPA算法,并且LPA_D_CC算法方差小,具有较好的稳定性,显著提高了社区划分质量.

表4 模块度对比Table 4 Comparison of modularity values
5 总结与展望
目前在复杂网络中关于社区发现方面还有很多值得研究的问题,例如算法在大型数据集中社区发现质量和效率问题,社区本身的定义问题等等.传统的标签传播算法需要给每个节点赋予不同的初始标签,这导致传播过程中时常存在不稳定因素,影响社区划分质量.本文提出的算法分为两个阶段,第一阶段根据网络中节点的度数和聚集系数,对网络中节点做影响力排序,并将影响力高的节点和它邻居节点划分一个集合,重复此步骤直到网络被划分为若干个集合,此时可以对网络做一个粗划分.第二阶段对若干个集合赋标签,并依靠标签传播算法进行调整得到最终的社区结构.实验结果表明,本文提出的算法能有效减少迭代次数,同时保证社区划分的准确性和稳定性,并且生成的社区质量模块度指标优于LPA算法.总体而言,所提出的LPA_D_CC算法有效解决了传统LPA算法的鲁棒性差等问题.在将来的工作中,我们将尝试在异构网络中对同一个节点赋多个标签,旨在研究重叠社区发现等工作.

图2 平均模块度比较Fig.2 Comparison of the average modularity values
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
中学生数理化·七年级数学人教版(2018年11期)2019-01-31 02:39:26
娃娃乐园·综合智能(2018年23期)2018-12-26 09:10:20
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
娃娃乐园·综合智能(2018年3期)2018-03-22 06:13:46
中国照明(2016年6期)2016-06-15 20:30:14
公民与法治(2016年10期)2016-05-17 04:12:58
