
融合交互信息和能量特征的三维复杂人体行为识别
2018-09-07 01:33:14王永雄张孙杰
小型微型计算机系统 2018年8期
王永雄,曾 艳,李 璇,尹 钟,张孙杰,刘 丽
(上海理工大学 光电信息与计算机工程学院,上海 200093) E-mail:wyxiong@usst.edu.cn
1 引 言
识别和理解人的行为是智能服务机器人和智能辅助系统的主要任务之一,也是人机共融技术的主要难点和瓶颈.近年来,随着3D设备(例如RGB-D摄像头) 的普及,由于3D视觉具有较大优势和表达能力,基于3D视觉的行为识别也得到了较大的发展.
首先,特征提取是基于图像的行为识别最先考虑的问题.常见的特征主要有尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)[1]、方向梯度直方图特征HOG[2](Histogram of Oriented Gradient)和人体姿态关节角等2D静态特征[3],人体运动的速度、轨迹等3D动态特征[4]以及时空兴趣点特征(Space-Time Interest Points,STIP[5])和改进密集轨迹特征(improved dense trajectories,IDT[6,7])等基于兴趣点的特征.一般情况下,随着特征维数的增加,识别准确率随之提高,但是计算量随之变大,而且难以从高层语义上进行理解,因此需要对特征数据进行降维,生成有利于识别的高层语义特征.Li FeiFei等人[8]提出了一种新的局部特征方法,通过使用局部的高层语义信息建立局部特征矩阵,然后使用聚类的方法建立BOW特征,实现了多种特征数据的融合和降维.近年来随着深度学习理论的发展,将其应用于人体行为识别中,也取得了很好的效果[9,10].Ji等[11]将传统卷积神经网络扩展到具有时间信息的3DCNN,在视频数据的时间维度和空间维度上进行特征计算.Ng等[12]使用长短时记忆型RNN对视频进行建模,将底层CNN的输出连接起来作为下一时刻的输入,在UCF101数据库上获得了82.6%的识别率.从视觉显著性和生物学观点看,人总是关注人体运动的肢体和含有信息量的姿态.田国会等人[13]在三维关节点数据基础上提取了向量角度与向量模的比值作为特征表征人体姿态,采用动态时间规整 (Dynamic Time Warping,DTW) 进行模板匹配,实现人体行为识别.我们认为:人体动作的差异不仅表现在位置信息上,还表现在肢体的基于能量特征表示的信息上.因此本文提取人体运动产生的关节点动能和姿态势能作为全局运动特征[14],在此基础上再加入描述性的局部特征,用于表示运动的形态变化,例如关节点关节角、关节点方向变化等,并采用BOW算法对特征降维,生成有利于识别的高层语义特征.
上述方法考虑了人体姿态的静态和动态特征,但复杂的人体行为往往和物体、环境有交互作用.如果没有融合人与物、人与环境、甚至人与人之间的交互信息,则无法消除或减少类似动作和复杂行为识别的不确定性和歧义性.例如奔跑和踢足球、喝水和打电话、手持刀和手持杯子等动作,人体姿态和运动过程相似,孤立地研究人的行为,而忽略了与人交互的物体或者场景信息,这无疑大大降低了推理的准确性.因此利用人与物、人与环境之间的交互信息,可以提高人体行为的识别率,减少行为识别的歧义性[15].常规的思路有两个:一是分别识别人的行为和物体再融合;二是分别提取人的行为和物体的特征,组成组合特征再识别.Gupta和Davis提出了采用概率图模型对人与物的交互作用进行建模,通过贝叶斯网络同时对物体和行为进行分类和识别[16].Koppula等人[17]结合物品的“可操作性(affordances,例如杯子具有可移动性和可盛物性)”,采用结构化SVM方法进行复杂行为识别.Moore等人利用物体识别的结果提升行为识别的性能[18],或者利用行为识别的结果提升物体识别性能,然而上述的行为识别准确率依赖于物体分类的准确性.当物体分类出现错误时,其结果对行为识别往往有负面作用.在实际中,各式各样的物体识别本身就很复杂,由于光线、角度,特别是手部的局部遮挡等原因,物体的准确定位、分割和识别都比较困难[19].因此本文提出了融合物体信息和能量特征的3D行为识别,具体步骤如下:在提取人体骨架特征的基础上,采用Harris[20]算子检测算法快速定位与人交互物体的关键点,然后在3D深度图上利用区域生长法对物体进行分割,实现了从复杂背景中自动分割出待识别的物体,然后组合人体动能、势能、其他局部特征和物体特征等多种特征,实现了融合人物交互信息的复杂行为识别.
本文的创新包括:
从能量的角度提取人体骨架动能、姿态势能、关节点位置等特征构建局部特征矩阵,可以定量地表示人体行为的能量信息,并采用BOW算法对特征降维,生成有利于识别的高层语义特征.
在深度云图中,采用Harris算子自动获取区域生长法的种子,自动分割出与人体交互的手持物体,并提取交互物体的Hu矩特征融入最终的组合特征.
通过融合与人体产生交互的物体、环境信息,大幅度地提高类似动作或复杂行为的识别率.
2 特征提取和行为识别方法
3D人体行为常使用空间三维坐标、深度信息以及关节点角度等特征描述[21].本文使用Kinect获得深度图像和与之相对应的彩色图像,利用Kinect SDK获取人体三维骨架模型.本文采用的人体骨架模型由15个关节点组成,具体顺序和编号如表1所示.

表1 关节点编号Table 1 Joint numbers
2.1 基于BOW特征的人体行为表示
根据人体生理学和运动学,我们首先提取关节点空间三维坐标、方向变化、关节点动能、姿态势能和关节角等特征构建人体空间特征矩阵.Kinect可以识别15个关节点,因此每一帧图像包含了一百多维特征数据.为了有效组合各种特征数据,降低特征向量维度,本文采用BOW模型构建特征向量.BOW构建过程如图1.
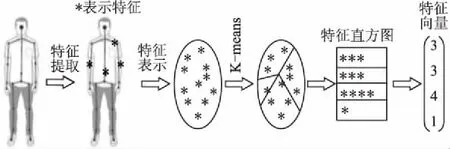
图1 Bag Of Word构建过程Fig.1 Building process of Bag Of Word
根据提取的空间三维坐标、方向变化特征、关节点动能特征和人体姿态势能特征等4类特征组成第Ft帧的特征矩阵Yt,它的每行对应一个关节点(n=15),按列依次存放以上4类特征,如(1)所示:
(1)
其中:Pn,t表示第n个关节点在Ft帧中的空间坐标.
φn,t=(xn,t-xn,t-1,yn,t-yn,t -1,zn,t-zn,t-1)
(2)
φn,t表示Ft帧中第n个关节点相对于Ft-1帧中第n个关节点的运动方向矢量.

(3)
Ekn,t表示Ft帧中第n个关节点的动能,kn为第n个关节点的动能参数(为了简单,实验中kn取1),Δt表示相邻两帧之间的时间间隔,Ekn,t可以定量地表示人体骨架关节点的运动能量信息.
(4)
En,t表示人体姿态势能,能够定量地反映人体的姿态信息,L是势能参数(实验中选1),Pi,t为Ft帧中第i个关节点位置,P1,t表示Ft帧头部关节点,即我们选定的零势能参照点.
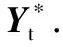
(5)
k-means中k值根据实验选择5为最佳,聚类迭代次数为100,n为15.聚类后得到5个聚类中心Ci(i=1,…,5),然后将所有特征向量映射到这5个聚类中心,得到第Ft帧的BOWt特征如下
BOWt=[bin1,…,bink]
(6)
BOW特征构建过程描述如下:
i.初始化:BOWt=[0,0,0,0,0],
ii.即bink=0(k=1,2,3,4,5)
iii.1)令
Yt=[vector1,vector2,vector3,…,vector15]T
(7)
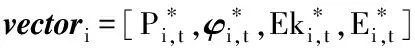
2)利用K-means算法对vectori(i=1,2,…,15)聚类后得到5个聚类中C1、C2、C3、C4、C5即Ck(k=1,2,3,4,5)。
3)fori:15,
fork:5,
根据公式(8)计算所有vector与Ck的欧氏距离
Dk=‖vectori-Ck‖
(8)
end
如果D[index]是D中的最小值
binindex=binindex+1
end
关节角是人体骨架表示中常用的特征,在不同动作下,关节角的变化规律是不同的,例如刷牙洗脸时往往仅有上肢关节角变化幅度明显,且呈现出有规律的变化,而人跑步或者行走时,四肢关节角都会发生明显变化.因此四肢关节角作为一种识别特征是非常直观有效的.我们根据人体运动学规律定义6个最具代表性的人体关节角,如图2所示.

图2 人体关节角示意图Fig.2 Human joint angle
其中θ1和θ2表示左右手大臂与小臂形成的夹角,θ3和θ4分别表示左右腿大腿与小腿的夹角,θ5和θ6分别表示左右手大臂与躯干形成的夹角.然后对提取的6个关节角θi(i=1,2,…,6)归一化处理,如下式,
(9)
由于本文提取的关节角特征个数较少不利于降维处理而且比较重要,因此关节角与BOWt一起构建特征向量,即构建一个k+6维的特征向量AFt(Activity Feature),
(10)
2.2 交互物体的检测和分割
正确检测与分割与人体产生交互的物体是有效提高人体行为识别的前提条件.一般来说手持物体是与人交互作用最多的物体,因此,我们这里只考虑人与物交互的手持物体.在复杂背景下,由于手持物体的大小不一、手对物体可能发生遮挡,手持物体的检测和分割是比较困难.Harris算子就是一种局部特征提取算法,该算法可以获得稳定、重复性高的角点,无论在哪个角度这些角点都可以很好地勾勒出物体的大致轮廓,基本不受手部遮挡的影响.
为了分割手持物体,Lv Xiong等人直接选取手部坐标作为区域生长法的生长种子点[22],该方法在实际应用中有一定局限性,例如很多时候手部中心位置 (关节点) 会稍微离开交互的物体区域,此时若以手部关节点为区域生长种子分割结果常常是不正确的.为了解决这个问题,降低误分割率,本文提出了一种改进的区域生长种子定位方法,首先提取图像中的Har-ris角点,将角点坐标(x,y)与对应深度图的深度值depth构成Harris角点的三维坐标(x,y,depth),然后选取距离手部关节点最近的N个Harris角点,计算这N个点的中心作为区域生长种子(这里N=4,并确保种子与手部关节之间的距离小于阈值),具体流程如图3.确定区域生长种子后,利用区域生长算法在深度图像中实现复杂背景下手持物体的准确分割.
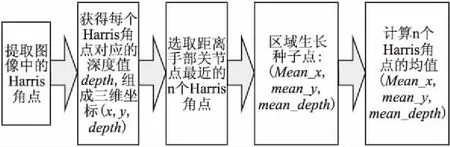
图3 区域生长种子定位流程图Fig.3 Flow chart of region growing seed location
2.3 融合交互物体特征的人体行为表示
几何不变矩(Invariant Moments)是一种高效的图像特征,具有平移、灰度、尺度、旋转不变性.Hu提出把一副M*N的灰度分布图像表示为函数f(x,y),(x,y)为图像平面坐标,其p+q阶几何矩mqp和中心矩μqp定义如式(11)和式(12):
mpq=∬xpyqf(x,y)
(11)
μpq=∬(x-x0)p(y-y0)qf(x,y)
(12)
这里p,q=0,1,…;x0=m10/m00,y0=m01/m00,m10,m00,m01分别是p=1,q=0时的1阶几何矩、p=0,q=0时的0阶几何矩和p=0,q=1时的1阶几何矩.为了保证图像特征具有平移不变性以及尺度不变性,如下公式定义归一化中心不变矩.根据Hu的理论,利用归一化中心矩作为特征能保证上述两种不变性.
(13)
为了提高人体行为的识别率,减少行为识别的歧义性,通过加入物体特征信息可以有效避免因姿态相同而导致的误识别,本文选择Hu矩特征作为与人体产生交互物体的特征.Hu矩特征向量由7个矩特征组成,通常第一矩I1、和第二矩I2对识别贡献较大,因此本文中只选取了I1和I2.
I1=y20+y02
(14)
(15)
融合物体特征的特征向量CFt(CombinedFeaturet)如下式
CFt=[AFtOFt]
(16)
2.4 分类方法介绍
基于核的SVM算法具有良好的泛化能力,且结构化风险小[23].其关键问题之一是选取合适的核函数和获得最优的参数,选择合适的核函数可使SVM发挥最好的分类能力,常用的核函数有线性核函数、多项式核函数、径向基内核(Radial Basis Function,RBF Kernel)、sigmoid核函数.因为RBF核函数具有良好的性能且调节参数较少[24],本文采用基于RBF核函数的SVM分类器(RBF-SVM),RBF核函数公式如公式(17)所示:
(17)
其中xc为核函数中心,c为函数的宽度参数γ,为核参数.实验发现RBF-SVM在实际分类问题中表现出了良好的性能由于实验中涉及16组实验动作的对比,而SVM算法最初是为二值分类问题设计的,当处理多类问题时,就需要构造合适的多类分类器.本实验应用一对一法构建SVM多类分类器,其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k-1)/2个SVM.
3 实验结果与分析
3.1 数据库
为了验证算法的有效性,本文分别在微软公司的MSR Daily Activity 3D 数据库[25,26]和康奈尔大学的CAD-60数据库[27]进行实验.这两个数据库都在计算机视觉领域尤其是人体行为识别领域应用非常广泛.
MSR Daily Activity 3D数据库包含了16个日常行为的短视频:喝水、吃东西、阅读书籍、打电话、写字、使用笔记本、使用吸尘器、欢呼庆祝、站立不动、抛纸张、玩游戏、躺在沙发上、来回踱步、弹吉他、起来、坐下,如图4.共有10位实验者依次完成这16个动作,每个动作大概有120帧.
CAD-60数据库包含了4个人12个日常行为的数据,具有较好的代表性.这12个动作分别为:漱口,刷牙,戴隐形眼镜,打电话,喝水,打开药盒,烹饪(切碎),烹饪(搅拌),在沙发上休息,黑板上写字,用电脑工作,4 人中包含两男两女,男女中各有一个左撇子.每一位参与者在 5个不同的场景下:办公室、厨房、卧室、洗漱间、客厅进行这12个日常动作.在本文实验中为了验证手持物体对行为识别的影响,只选取了打电话、黑板上写字、喝水、刷牙、打开药盒、用电脑工作这六个动作.

图4 MSR Daily Activity 3D数据库Fig.4 Date base of MSR Daily Activity 3D
这两个数据库都是由Kinect完成采集,其中包含深度图像 (*.bin文件),人体关节点在三位空间中的坐标 (x,y,z)(*.txt文本)、关节点相对图像的三维坐标(u,v,depth),其中u和v均做归一化处理,depth表示对应像素点的深度值,以及RGB彩色视频(*.avi文件).由于数据库中绝大部分行为(动作)都包含了人—物交互关系,因此行为识别的难度比较大.
3.2 SVM分类器训练
通过RBF-SVM训练获得分类器的两个重要的参数:惩罚因子c和核参数γ[28],本实验中采用的是台湾大学林智仁教授开发的在matlab上的SVM工具包,其中包含交叉验证方法的libsvm程序实现SVM算法,其中-c对应c,-g对应γ.参数训练结果如图5所示,图中曲线表示识别率的等高线,标注的数值表示对应的识别率.通过反复交叉验证选择了一组最优参数c=32、g=24,星号标注的点为最优参数点.
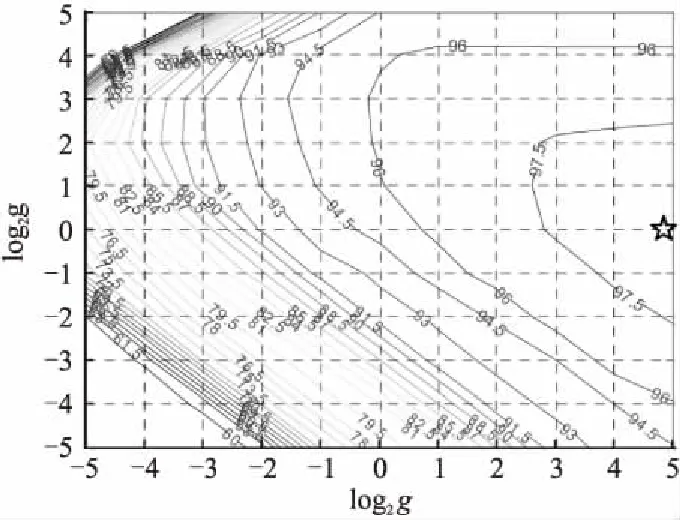
图5 RBF-SVM参数c和g表示的识别率的等高线图Fig.5 RBF-SVM recognition rate counter map of parameter c and g
3.3 实验结果与分析
为了验证物体自动分割效果和融合交互物体特征的复杂行为识别效果,分别进行了基于Harris角点检测的物体自动分割实验、基于人体特征AFt的行为识别和基于融合交互物体特征与人体行为特征CFt的行为识别实验.
3.3.1 基于Harris算子的自动物体分割实验
Harris算子可以有效地检测出图像中稳定、重复性高的角点,无论在哪个角度这些角点都可以很好地勾勒出物体的大致轮廓,并不受手部遮挡、光照变化的影响.因此我们选择Harris角点自动提取区域生长算法的种子,然后在对应的深度图像中,利用区域生长算法实现复杂背景下手持物体的自动分割,最后把分割出的物体结合原来的彩色图显现出来.
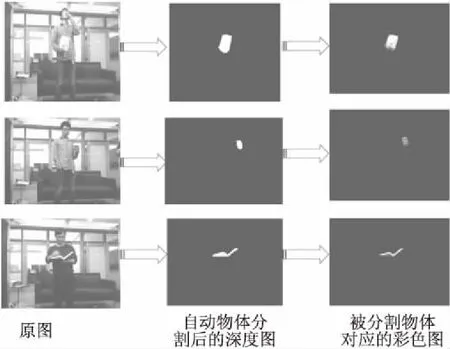
图6 区域生长法自动物体分割图Fig.6 Segmenting object automatically by region growing seed method
这里列出了“吃东西”,“喝水”,“看书”三个典型的具有手持物体的动作分割结果,实验效果如图6.从图6第一列的彩色图中可以看出第一个动作“吃东西”,其手持物体体积较大且正对镜头;第二个动作“喝水”,其手持物体“水杯”的体积较小且部分被手部遮挡;第三个动作“看书”,其手持物体“书本”没有正对镜头只能看到侧面.图6的第2列是自动分割物体后的深度图,可以看出实验中3个动作中的物体没有受到角度和大小的影响,都达到了很好的分割效果.图6第3列是分割出的物体的对应彩色图.
实验结果显示,基于Harris角点的区域生长法能够较好地自动分割手持物体.
3.3.2 只采用人体特征AFt的行为识别实验
我们分别在MSR Daily Activity 3D和CAD-60数据库进行了实验.实验中,随机提取该数据库中每个动作的80%数据作为SVM的训练集,将余下20%的数据作为测试集.重复实验5次后,将实验结果的平均值作为最终的实验结果.
MSR Daily Activity 3D数据库中每个动作的都存在手持物体,且许多动作之间有着较高的相似性.当只采用AFt作为特征而不考虑交互物体特征时,由姿态相同而导致的误识别比较大,因此非常适合做对比实验.图7显示了只采用AFt作为特征进行行为识别时MSR Daily Activity 3D数据库中16个动作的混淆矩阵结果,从图中可以看出实验平均准确率仅为58.8%,如“喝水”、“吃东西”、“看书”、“打游戏”、“躺在沙发上”等动作的误识别情况比较严重.
CAD-60数据库数据量比较大,我们只选取了手持物体比较明显的动作进行识别.从图8中可以看出这六个动作的平均识别率已经高达88.0%,这说明这六个动作的人体姿态存在较大差异,应用人体特征识别可以取得比较满意的识别效果.
3.3.3 基于组合交互物体特征与人体行为特征CFt的行为识别实验
为了验证交互物体信息对行为识别的有效性,这里采用组合的新特征CFt进行行为识别,其他的条件都与上一组实验相同,行为识别的混淆矩阵如图8、图9.

图7 只采用AFt特征在MSR数据库上行为识别混淆矩阵Fig.7 Confusion matrix of activity recognition in MSR database based on AFt features

图8 只采用AFt特征在CAD-60数据库上的行为识别混淆矩阵Fig.8 Confusion matrix of activity recognition in CAD-60 database based on AFt features

图9 基于CFt特征在MSR数据库上的行为识别混淆矩阵Fig.9 Confusion matrix of activity recognitionin MSR database based on CFt features
从图中可以看出融合手持物体特征之后,MSR Daily Activity 3D数据库中的16个动作的准确率都有所提高,平均准确率从58.8%提高至82.9%.如“喝水”、“吃东西”、“看书”、“打电话”、“写字”、“打游戏”、“扔纸团”、“弹吉他”等动作的识别率都很高,原因是这些动作中,准确地分割出了手持物体,准确地提取到物体特征,因此识别率得到大幅提升.CAD-60数据库中6个动作的平均准确率也从88.0%提高至94.0%,可见这六个动作仅使用人体特征已经取得比较满意的识别效果,加入物体特征后识别也更加准确了.
另外,从图8中可以看出融合手持物体特征之后,“躺在沙发上” 、“站着不动”、“站立”、“走路”和“坐下”这5个动作的误识率没有明显提高,主要原因是这五个行为中没有手持物体.没有手持物体的行为识别率偏低可能需要构建更复杂特征,针对这个问题,我们将做进一步研究.

图10 基于CFt特征在MSR数据库上的行为识别混淆矩阵Fig.10 Confusion matrix of activity recognition in MSR database based on CFt features
在CAD-60数据库上的实验结果和MSR Daily Activity 3D数据库中类似,对比图8和图10,我们可以看出6个动作的准确率都有了一定的提高平均准确率也从88.0%提高至94.0%,尤其是“打开药盒”这个动作的准确率高达100%,可见这六个动作仅使用人体特征已经取得比较满意的识别效果,加入物体特征后识别也更加准确了.
同时,为了验证我们方法的总体性能,表2列举了我们的方法和目前多种最新方法的实验结果对比.

表2 不同特征和分类方法的对比结果Table 2 Comparison experiment results based on different features and methods
从表2中可以看出全部MSR Daily Activity 3D数据库中16个行为的总的平均识别准确率为82.9%,处在中间水平,但我们的特征维数很低,只有13维,和别的方法相比计算量明显减小.对比图7和图9,可以清楚地看出其中11个具有手持物体的复杂行为的识别率有明显提高,比如喝水的识别率从69%提高到92%,其中喝水和吃东西的误识别率从13%降到0,喝水和看书的误识别率从7%降到0,这是由于喝水时的手持物体“杯子”与另两个动作中的 “食物”、“书本”进行了有效的区分.特别地,如果去除没有手持物体的5个行为,剩下的有手持物体的11个行为的平均识别率高达89.1%,超过其他所有方法的识别率.在CAD-60数据库上的实验结果显示我们6个动作的准确率高达94.0%,在现有的方法上有了较大的提高.
因此,在两个数据库的实验有效地验证了融合手持物体特征可以大幅提高复杂行为的识别率,交互信息的引入对识别有很大的促进作用.
4 结束语
考虑到与人交互物体对人体行为识别的重要作用,本文提出了一种对交互物体信息和人体动作特征联合建模的三维人体识别方法,该方法提取了人体骨架动能、关节点位置、姿态势能等多种特征聚类为高层语义BOW特征,其中人体骨架动能和姿态势能特征能够定量地表示视频中人体动作,区域生长法能够较好地自动分割手持物体,融合交互物体的Hu矩特征对易混淆的人体行为有很好的补充作用,可以大幅度减少行为识别的歧义性,针对人与物体交互等复杂的人体行为识别率有较大的提高.在特征提取方面,例如与IDT方法结合是我们今后的研究方向之一,同时将考虑人体行为特征和交互物体的信息,进一步提高行为识别的准确性和适用性.
猜你喜欢
科学技术创新(2021年19期)2021-07-16 10:07:04
沈阳航空航天大学学报(2020年6期)2021-01-27 02:11:30
计算机工程(2020年3期)2020-03-19 12:24:50
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
中国交通信息化(2018年3期)2018-06-13 03:27:58
军营文化天地(2017年6期)2017-06-28 11:30:19
中国交通信息化(2016年2期)2016-06-06 07:28:02
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
