
基于句法语义特征的实体关系抽取技术*
2018-09-03 09:53姚春华高弘毅鄢秋霞
通信技术 2018年8期
姚春华,刘 潇,高弘毅,鄢秋霞
(1.中国电子科技集团公司第三十研究所,四川 成都 610041;2. 解放军驻西安邮电大学选培办,陕西 西安 710061;3.中国电子科技网络信息安全有限公司,四川 成都 610041)
0 引 言
随着 计算机的普及和互联网的迅猛发展,大量信息以电子文本的形式出现在人们面前。为了应对信息爆炸带来的挑战,迫切需要一些自动化的工具帮助人们在海量信息源中迅速找到真正需要的信息。信息抽取研究,正是在这种背景下产生的。信息抽取的主要目的是将无结构的文本转化为结构化或半结构化的信息,并以数据库的形式存储,供用户查询以及进一步分析利用。信息抽取系统的主要功能是从文本中抽取出特定的事实信息,称之为实体,如时间、组织机构以及人物等。
然而,在大多数应用中,不但要识别文本中的实体,还要确定这些实体之间的关系,称其为实体关系抽取。与实体抽取类似,实体关系的类型也是预先定义的,如地理位置关系(PHYS)、雇佣关系(EMP-ORG)等。信息抽取的主要功能是自动将文本转化为数据表格,实体抽取确定了表格中的各个元素,实体关系抽取则是确定这些元素在表格中的相对位置。可见,实体关系抽取是信息抽取中的重要环节。
通常,人们将关系抽取问题转化为一个分类问题,即首先识别一个句子中所有的二元实体对,然后使用一个分类器决定哪些是真正需要的关系。
和分类问题通常的解决办法一样,人们最初使用知识库的方法来解决该问题。但是,方法需要专家构建大规模的知识库,不但需要有专业技能的专家,还需要付出大量劳动。
为了克服知识库方法的缺点,人们使用机器学习的方法来解决此问题。该方法不需要有专业技能的专家书写知识库,只需要有一定专业知识的人对任意两个实体之间的关系做出是与不是需要判定的关系即可,然后以此为训练数据,使用各种学习方法构造分类器。
通常的机器学习算法需要构造特征向量形式的训练数据,然后使用各种机器学习算法,如支持向量机(SVM)、Window、逻辑回归Logistic等作为学习构造分类器。这种方法被称作基于特征向量的机器学习算法。因此,本文采用词法、句法语义特征,以基于特征向量的机器学习算法作为实体关系抽取的方法,采用的机器学习算法是Logistic回归算法。
1 研究现状
CNKI统计显示,自2007年以来,实体关系抽取研究的关注度一直呈上升趋势,说明实体关系抽取得到了越来越多的重视。目前,ACE会议也将关系抽取作为评测内容之一。
实体关系抽取的研究思路主要有基于语言规则模板的方法、基于词典驱动的方法、基于Ontology的方法、基于机器学习的方法和基于深度学习的方法等。近几年的研究趋势表明,机器学习、深度学习成为主流。
英文的实体关系抽取已经有非常成熟的技术。在非监督算法领域,通常会用到上下文特征。
1954年,Harris在Distributional hypothesis theory指出,如果两个词经常出现在同一个上下文环境中,在语义上极有可能近似,进而以此作为理论基础来判定此二元实体对是否包含同样的实体关系[1]。
2004年,Hasegawa通过采用分等级聚类方法来聚类实体的上下文,简单选择上下文中最常用的词作为特征来表示实体之间的关系[2]。
而在监督算法领域,实体关系抽取通常是一个多分类问题,传统的机器学习通常会构造复杂的特征来增强模型的性能。
Kambhatla于2004年采用词汇、句法和语义特征来构建特征向量,再与最大熵模型相结合来提取实体关系[3]。
Suchanek等人于2006年结合语言和统计分析来构建特征向量,从网络文本中提取实体关系[4]。
2011年,Phillippe Thomas等人提出了一种利用集成学习(Ensemble Learning)抽取药物之间的相互作用的方法。该方法基于不同语言特征空间构建多种机器学习方法,选出了实验效果最好的方法[5]。
2012年,Mihai Surdeanu等人采用多实例多标记学习引入到关系抽取中,形成了一种新的方法。它利用带有潜在变量的图模型,将文本中实体对及其标记融合在一起,一定程度上克服了远距离监督学习的缺陷。实验表明,它在两类不同领域的文本中性能表现良好[6]。
2013年,Haiguang Li、Gongqing Wu等 在Applied intelligence提出了一种基于位置语义特征的命名实体关系抽取方法。它利用位置特征的可计算性和可操作性、语义特征的可理解性和可实现性,整合了词语位置的信息增益与基于HowNet的语义计算结果,最终明显提升了关系抽取效果[7]。
近几年,随着深度学习的推广,它广泛应用于自然语言处理领域。深度学习并不依赖于所设计的特征,可以自动学习到高阶特征。
2014年,zeng等人使用深度卷积神经网络来提取实体关系,但CNN无法学习到长距离的语义信息[8]。
于是,2015年Zhang和Wang使用了BiRNN来进行实体关系抽取,能够克服长距离语义信息,并且可以学习到过去和未来的特征,但是会产生上下文梯度消失的问题[9]。
中文实体关系抽取的研究也取得了丰硕成果。
何婷婷等人于2006年提出了一种基于种子自扩展的命名实体关系抽取方法,能够从大量文本集合中自动抽取命名实体间关系。具体地,人工选取少量具有抽取关系的命名实体对作为初始关系的种子集合,通过自学习不断扩展关系种子集合,再通过计算命名实体对和关系种子之间的上下文相似度来得到所要抽取的命名实体对[10]。
2007年,陈火旺等人通过使用一系列特征,包括词、词性标注、实体和出现信息、包含关系和知网提供的概念信息等,来构建实体关系抽取的特征向量,并使用SVM方法实现中文实体关系抽取[11]。
2013年,陈鹏等人提出一种基于凸组合核函数的中文领域实体关系抽取方法。首先选取实体上下文的词、词性等信息,短语句法数信息及依存信息作为特征,然后通过以径向基核函数、Sigmoid核函数及多项式核函数组成的不同组合比例的凸组合核函数,将特征矩阵映射成为不同的高维矩阵,然后利用支持向量机训练这些高维矩阵构建不同分类模型后测试抽取性能,以确定最优组合比例的凸组合核函数[12]。
由于中文语言结构的独特性和语义的复杂性,中文实体关系抽取研究整体上与国外的研究还存在一定差距。一方面常用的基于浅层语法分析获取特征、构建特征向量、进行机器学习的方法已经达到瓶颈,另一方面中文实体关系抽取开源的语料库特别少,如果采用监督学习的方法需要克服语料缺少的情况。
本文针对人与人之间的六种关系——父母、子女、夫妻、兄弟姐妹、同事、其他,采用百度百科的语料库构建五个类别(父母、子女、夫妻、兄弟姐妹、同事)的关系指示词词典,再根据关系指示词词典来判定实体对关系类型。采用上述方法,结合人工标定来扩充五个类别(父母、子女、夫妻、兄弟姐妹、同事)语料库,根据中文的语法特点,设计了一系列特征,包括实体本身的词、词性标注和实体上下文环境的词、词性特征。另外,融入了实体的依存句法关系值、实体与核心谓词距离的特征,采用logistic进行训练和测试。此外,针对文本中含有多对二元实体对,通过统计文本中关系指示词典的个数,使得句子中二元实体对不超过关系指示词典的个数。
2 基于句法语义特征的实体关系抽取方法
2.1 基于关系指示词词典扩充实体关系语料
针对中文人与人关系语料库缺少的情况,本文提出了基于关系指示词词典扩充实体关系语料。首先人工选出人与人五种关系的种子词,再利用种子词和《同义词词林(扩展版)》资源扩展形成关系指示词词典。根据人与人关系在中文语法句式结构的特点,可以总结出以下四条规则:
(1)根据实际经验统计,两个实体之间的词数目小于等于5的实体关系三元组数目占总的实体关系三元组数目的74.57%。因此,在生成候选实体关系三元组时,两个实体之间的词数目不能超过maxDistance(设置为7)。若两个实体之间含有标点符号,则标点符号与第二个实体之间的词数目不能超过maxDistance。
(2)两个实体之间其他实体数目小于或等于4的实体关系实例数目占实体关系三元组数目的98.55%,所以设定实体之间其他实体数量不能超过maxEntityDistance(设置为4)。
(3)通过统计发现,关系指示词一般为名词和动词。
(4)关系指示词通常与二元实体对之间有比较明显的位置关系。关系指示词一般位于第一个实体左边的leftWordNumber(设置为3)个名词和动词、第二个实体右边rightWordNumber(设置为3)个名词和动词和第一个实体与第二个实体之间。
为了处理句子中含有多对实体关系对,结合关系指示词与二元实体对不同位置设置不同的权重。若关系指示词位于第一个实体左边为w1(设置为0.4),关系指示词位于第二个实体右边为w2(设置为0.3),关系指示词位于两个实体中间为w3(设置为0.2),分别计算关系指示词与二元实体对之间的距离与其相应位置的权重乘积所得的分数,选出分数最低的为所识别关系三元组。
扩充实体关系语料库的具体流程如图1所示。首先,人工选出人与人五种关系的种子词,利用种子词和《同义词词林(扩展版)》资源扩展形成关系指示词词典;其次,结合人与人关系在中文语法句式结构的特点总结出的四条规则从百度百科文本中抽取满足人与人五种关系的三元组;最后,加以人工辅助标定所识别的人与人的关系三元组(人名1,人名2,关系)来丰富语料库,从而可以用于后续的Logistic机器学习算法。

图1 基于关系指示词词典扩充实体关系语料库
2.2 Logistic机器学习算法概述
Logistic是应用非常广泛的一个分类机器学习算法。它将数据拟合到一个logit函数(或者叫做logistic函数)中,从而能够完成对事件发生概率的预测。
Logistic算法主要用于分类,属于一种线性的分类器,适用于类别少、特征多的分类器,且对每一个类别的判定能给出一个概率值。模型相对比较简单,训练速度较快,在模型预测时计算量相对较小,模型的预测效率高,存储资源低,适用大规模数据量训练。
本文要解决人与人六种关系(父母、子女、夫妻、兄弟姐妹、同事、其他)六分类模型。另外,由于‘其他’这个类别比(父母、子女、夫妻、兄弟姐妹、同事)五个类别总的语料需求大,容易导致‘其他’特征较多,出现过拟合现象。所以,本文选取Logistic回归模型,能够预测每一个类别的概率。若五个类别(父母、子女、夫妻、兄弟姐妹、同事)概率小于预先设定的阈值(设置为0.5),则判为其他。
模型表达式:

其中z=θTX ,可以看作是一个线性回归模型,θ为特征系数。可以通过最大似然估计来学习样本的后验概率,在学习过程中可以给模型参数添加L1或者L2正则来简化模型,使得模型效率更高。
模型预测表达式:
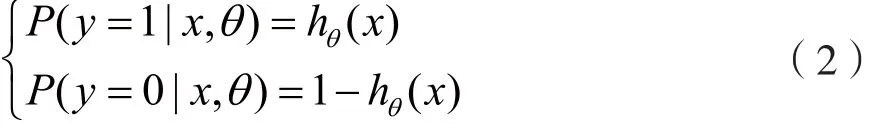
模 型 参 数 估 计。 假 设 P(y=1|x)=π(x),P(y=0|x)=1-π(x),似然函数为:

对数似然函数为:
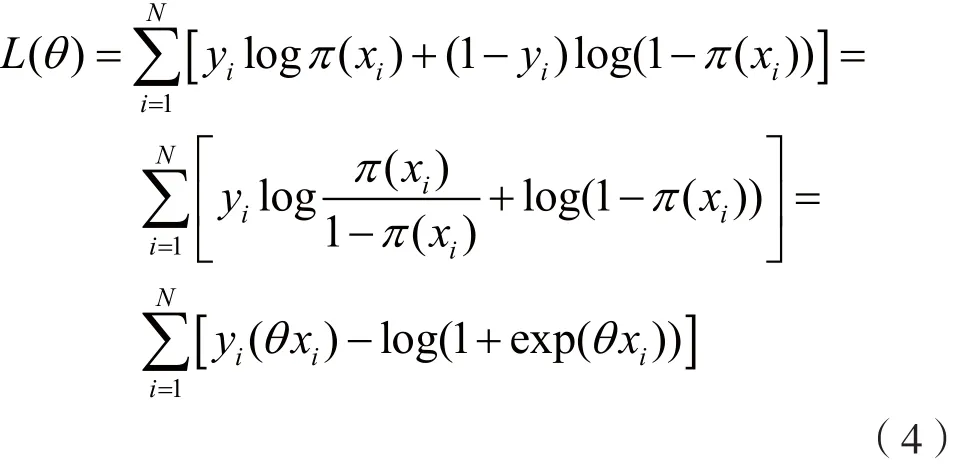
对L(θ)求极大值,得到θ的估计值。这样问题就变成了以对数似然函数为目标函数的最优化问题。Logistic学习中,通常采用的方法是梯度下降法和拟牛顿法。
假设θ的极大似然估计值是θ^,那么学到的Logistic模型为:
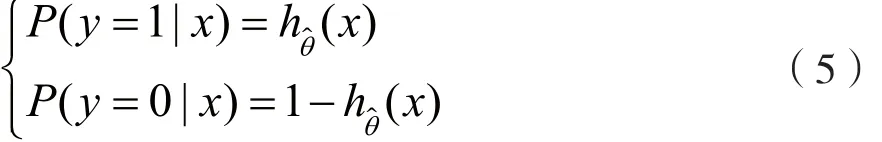
多分类的Logistic模型。上述Logistic模型是二项分类模型,用于二类分类。可以将其推广为多项Logistic模型,用于多类分类。假设离散型随机变量y的取值集合是{1,2,…,K},则多项Logistic回归模型为:

同理,二项Logistic的参数估计方法也可以推广到多项Logistic回归。
2.3 实体关系抽取中的特征向量构造
基于特征向量的机器学习算法是对给定的一组训练数据(x1,y1),(x2,y2),…(xn,yn),其中对于二元分类问题yi∈{0,±1},学习一个分类函数f,使得对于给定新的特征向量x',f能够将其正确分类,即f(x')=y'。
对于自然语言处理问题,如何构造特征向量成为使用基于特征向量学习算法的一个重要环节。例如,在文本分类任务中,通常使用一个词作为特征向量,而向量中元素的值可以是二元的1或0,代表某个词出现与否,或者是该词在一篇文档中出现的次数。目前,使用词的tf×idf值作为元素值,取得了较好的分类效果。在其他一些自然语言处理问题中,向量的每个元素表示的是一些预先定义的特征在实例中出现与否,即根据特征函数fi∶H×T→{0,1}决定第i维向量元素的值。其中,H是实例上下文的集合,T是实例所属类别的集合,则特征向量的第i维向量元素xi=fi(h,t)。于是,构造了一个维数巨大的特征向量。此特征向量即可作为某一机器学习算法的输入数据进行学习和预测。
常规的实体关系特征主要从词法分析结果来获取,以往的研究已经表明了这些特征的有效性。面向句子中所有实体组成的二元实体对,本文结合词法特征和句法语义特征,分析其选择的实体关系特征。
(1)二元实体的长度。根据命名实体结果的标识信息中获取多词实体的边界和其首尾词的位置来计算实体长度。
(2)二元实体的种类。目前,使用的LTPCloud工具能够识别的实体种类有人名、地名、组织机构名,所以实体种类只选择这三种。
(3)二元实体的内容。
(4)二元实体中各词的词性标注。
(5)二元实体的上下文环境。通常,实体周围的w个词也是较好的特征,如实体前后w个词的内容以及词性标注信息,这里w可以取2或者3。因为一般情况下,距离较远的词对词性标注不起重要作用,且如果w的选择过大,会增加计算量。
(6)二元实体的句法依存关系。依存句法能够有效分析句子中各词语之间的依存关系,通过对其这一功能的应用,可以作为实体关系抽取一项特征。通过Ltp-Cloud对句子进行句法语义分析,获取实体对中每一个实体在原句中所属的句法依存关系值,其中包括每一个实体依赖的父节点的词、词性标注和每一个实体依赖的子节点的词、词性标注。
(7)二元实体与核心谓词的距离。对句法分析的结果进行大量实验后发现,在所有谓词中,核心谓词对获取实体边界、承接实体关系起着关键作用。句子中命名实体与核心谓词的平均距离和命名实体与普通谓词的平均距离有明显差异,所以实体与核心谓词的距离也是实体之间的一种隐含关系特征。根据实体首词在句中的位置和核心谓词的距离,计算每一个实体与核心谓词的距离。
2.4 Logistic模型训练基本流程
如图2所示,本文利用基于关系指示词词典扩充实体关系语料库,得到人与人关系三元组(人名1,人名2,关系)语料库,再利用哈尔滨工业大学LTP-Cloud平台对语料进行初步处理。以LTPCloud对语料的词法、句法分析结果为基础生成二元实体对,并采集所有二元实体对利用2.3章节的7条特征生成训练文本,并交由logistic进行训练。
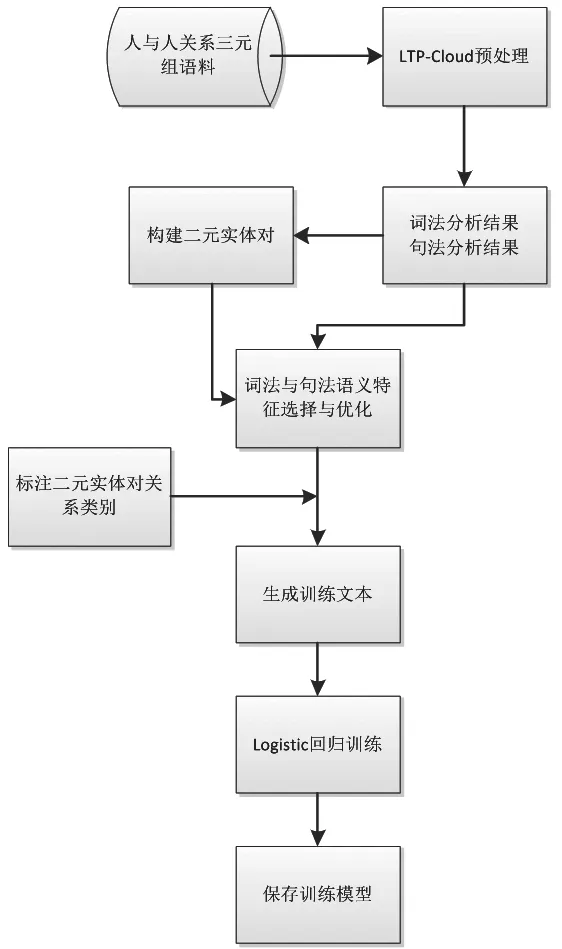
图2 二元实体对关系抽取的Logistic模型训练流程
3 实验结果
本文设定了五种人与人之间的实体关系类型,分别是父母、子女、夫妻、兄弟姐妹、同事。由于本文将实体关系抽取过程看作是分类过程,这里采用准确率、召回率和F1值作为评价方式。
准确率:

本文采用百度百科数据,人工标定的父母、子女、夫妻、兄弟姐妹、同事、其他的语料。其中,90%作为训练语料,10%作为测试语料,具体数据如表1所示。然后,利用哈尔滨工业大学Ltp-Cloud分析每一对二元实体对所在句子中词法、句法语义特征数据,并人工添加实体关系分类标注,最终形成训练语料。采用scikit-learn中的DictVectorizer将特征数据进行特征向量化,采用scikit-learn中的LogisticRegression训练模型。其中,DictVectorizer使用默认的参数设置,LogisticRegression函数的参数设置为penalty='l2',dual=False,tol=0.0001 solver='newton-cg',multi_class='multinomial'。

表1 人与人六种关系训练和测试语料分布情况表
本文先针对人与人五种关系(父母、子女、夫妻、兄弟姐妹、同事)语料库进行Logistic训练和测试,表2分别为五种类别的精确率和召回率。

表2 去除实体识别错误,父母、子女、夫妻、兄弟姐妹、同事各个类别的准确率与召回率
另外,二元实体对之间的关系可能是无关系或者不在上述五类中,将这一类定义为“其他”类别。“其他”类别数据过于繁杂,将易导致“其他”如果将“其他”和父母、子女、夫妻、兄弟姐妹、同事五类一起训练出现“其他”这个类别特征数远大于语料数而发生过拟合现象,最后导致模型预测出现误差。由于本文收集的‘其他’这个类别语料库远远小于实际需要的语料库,为解决上述问题,将父母、子女、夫妻、兄弟姐妹、同事和其他六类训练一个Logistic模型。对于一个二元实体对,构建其相应的特征向量,通过Logistic模型判定,若其判为这五个类别(父母、子女、夫妻、兄弟姐妹、同事)概率的最大值小于某个阈值(设置为0.5),则将其判为“其他”类别;若大于某个阈值,则将其判为既已判定的类别。另外,针对文本中含有多对二元实体对,通过统计文本中关系指示词典的个数,使得句子中二元实体对不超过关系指示词的个数。计算概率前n个二元实体对,其中n=min{句子中二元实体对个数,句子中关系指示词的个数},具体流程图如图3所示。

图3 采用Logistic模型识别实体关系抽取流程
4 结 语
本文提出了一种基于句法语义特征的实体关系抽取方法。与以往的实体关系抽取方法相比,本文新增了句法分析结果和语义分析结果作为实体关系抽取的特征,然后采用Logistic分类器进行训练模型。句子中含有多对二元实体对,通过统计文本中关系指示词的个数,需构建句子中实际含有的二元实体对,解决多判和漏判的二元关系实体对。针对采用Logistic分类训练模型但缺乏样本的情况,本文又提出了一种基于关系指示词词典扩充人与人关系语料。具体地,采用百度百科的语料库构建五个类别(父母、子女、夫妻、兄弟姐妹、同事)的关系指示词词典,根据关系指示词词典判定实体对关系类型,采用上述方法,结合人工标定来扩充五个类别(父母、子女、夫妻、兄弟姐妹、同事)语料库。本文是以句子为处理单位,缺少篇章处理的视野,未考虑实体的指代消解问题,未来,将在上述方面继续做深入研究。另外,本文采用监督学习的方法,对样本扩充有一定人工标定量,未来将在语料自动扩充做一些深入研究。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
通信技术(2021年12期)2022-01-25
文化创新比较研究(2020年13期)2021-01-14
天津外国语大学学报(2020年1期)2020-03-25
数学大世界(2019年7期)2019-05-28
计算机应用与软件(2018年9期)2018-09-26
中华建设(2017年1期)2017-06-07
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
外语教学理论与实践(2014年2期)2014-06-21
