
我国乳制品消费水平变动趋势集成预测
——基于ARMA、VAR和VEC模型
2018-08-20 06:05:34何忠伟栗卫清
中国畜牧杂志 2018年8期
何忠伟,栗卫清,刘 芳
(北京农学院经管学院,北京新农村建设研究基地,北京 102206)
乳制品产业在我国一直备受关注,它是现代农业和食品工业的重要组成部分,也是促进一二三产业融合发展的战略性产业。但目前我国乳制品消费局面不容乐观,2014年我国乳制品人均消费量增速为8.1%,但之后基本处于停滞状态。乳制品消费水平滞后与国民经济发展不协调说明我国乳制品消费方面还存在一些问题。因此,本研究在收集2000—2016年乳制品消费数据的基础上,采用ARMA、VAR和VEC模型对我国未来3年内的消费水平进行了实证分析,并通过综合集成模型有效提高预测的准确度,为完善奶业振兴计划和乳制品供给侧结构性改革提供参考。
1 文献综述与概念说明
目前消费预测的文献很多,聂迎利[1]采用灰色关联与时间序列预测模型对2008—2020年我国城乡居民乳制品消费需求和供给情况进行预测,得出原料奶供给大于需求。刘强等[2]采用指数平滑模型和灰色模型对我国奶类消费需求量的内部因素及相互关系进行研究,指出我国奶业消费需求保持高速增长,2015年人均消费量将增加至82.83 kg。许世卫[3]采用收入和消费之间关系模型Holt-Winters-No seasonal法预测未来我国城乡奶类消费量会呈现快速增加的趋势,并预测2015年我国城乡居民人均奶类年消费量将会达到31 kg,2020年前后将会达到38 kg,2030年前后会达到52 kg。翟世贤[4]总结了232个收入弹性和160个收入弹性,采用荟萃回归方法估计了牛奶需求与收入、城市化、历史时期的关系,得出随着收入增加除酸奶外的乳制品均会下降,基本符合实际情况,但对乳制品的需求弹性分析在不同研究间存在分歧。
尽管研究乳制品消费预测具有十分重要的意义,但很少有文献能够准确预测未来具体的消费数据。同时,实际生活中经常会出现很多突发状况,预测误差难以避免,但这并不影响预测对现实的指导作用,也不影响预测对未来消费趋势的把握。ARMA、VAR、VEC模型具有较好的预测作用,被大量应用于社会学和经济学研究领域。近年来,以上3个模型在其他畜产品的预测应用中也逐渐增多,但在乳制品的消费研究中却几乎未被采用。因此,本研究采用ARMA、VAR、VEC模型对我国乳制品消费水平变动趋势进行分析预测。为进一步减少单个模型的预测误差和不稳定性,本文采用综合集成预测的方法对3个模型进行汇总分析。
需要说明的是,当前不同研究对奶业相关统计口径存在较大差异。例如,《我国奶业发展规划2016-2020》指出,2015年我国乳制品人均消费量折合生鲜乳达到36.1 kg,而统计年鉴中2015年我国乳制品人均消费量为12.1 kg。为避免折合成生鲜乳的标准不统一造成数据出入较大,本文研究数据统一采用不折合生鲜乳的中国统计年鉴数据。乳制品消费水平的概念有广义和狭义之分,狭义的消费水平指消费量或消费支出金额,广义的消费水平指包括消费量、消费支出、消费质量、消费环境等反应乳制品消费状况的整体指标体系。以往的研究文献中,乳制品消费水平基本都采用狭义的消费概念,因此本文也基于狭义概念展开研究。
2 模型简介
2.1 ARMA模型 ARMA是预测分析中经常使用的平稳时间序列模型,由Box和Jenkins发明,也称B-J法。该模型最大的优点是对一组时间数据进行规律性分析,从数据结构和数据特征方面寻找其内在变化趋势,样本越大,效果越好,是一种精度较高的短期预测方向[5]。模型的一般形式如下:
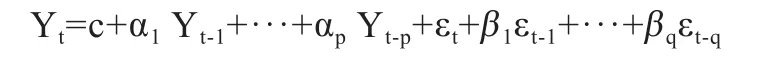
ARMA模型的建模过程需要综合3个次级模型的运行,分别是AR自回归模型、MA移动平均模型和ARMA自回归移动平均模型。建模前提是判断数据特征是否属于平稳序列,对不同模型选择不同的参数,进行对比分析选择最优解。模型具体的操作步骤:第一,采用自相关和偏自相关的方法对时间和差分后序列性质进行分析,包括数据的随机性、平稳性和季节性检验,一般需要对数据进行差分处理,消除序列的非平稳性。第二,模型的识别、建立与检验。对差分后的时间序列,观察其自相关和偏相关图像和系数,并依据图像性质对模型定阶,确定阶数后进行参数估计,并对确定阶数的不同模型进行参数对比分析,选择出效果好的。参数确定后分析,进行运行效果适合性检验。检验主要是观察残差序列是否随机,残差序列样本自相关系数是否近似为0。 第三,模型预测。若模型适合,则可以进行短期检验。判断预测结果是否符合经济学意义。
2.2 VAR模型 向量自回归模型(VAR)是一种非结构模型,即通过数据内在关系对其变动趋势进行分析。模型是对多变量时间序列预测,一定程度是对B-J模型的简化,需要多个时间序列间有相关性。由于模型参数相对较少,因此更加实用。模型关系式为:

模型也要求序列是平稳的,基本步骤:第一,平稳性检验。平稳性检验可以在模型参数估计前对每一个序列进行单位根检验,也可以在参数估计后对系统进行检验。模型平稳,即脉冲响应冲击是收敛的。一般使用单位根检验对不平稳的序列使用取对数处理。第二,确定最大滞后阶数。在Eviews 8软件中滞后期确定给出了5个对比结果,分别是LR检验系统量、最终预测误差FPE和AIC、SC、HQ 3个信息准则。对滞后阶数进行对比,选择出每个检验都认可的最优滞后期,保证所有残差都不存在自相关性。第三,格兰杰因果检验,对多序列中的两两序列的制约关系进行判断。第四,预测,检查预测结果,判断预测结果是否符合经济学意义。
2.3 VEC模型 向量误差修正模型(VEC)是含有协整约束的模型,不同的是数据应具有非平稳性。对于时间序列是否具有非平稳的特性,一般都要观察它的协整关系,并对协整关系的类型进行确定[6]。VEC模型表达式如下:

式中,Xt是m维非平稳序列,Xt是d维确定性变量,最后是新息变量,经过变形可以改写为:
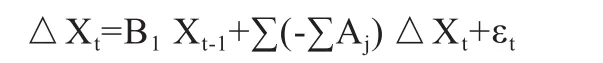
VEC模型的最大长处在于可以同时对长期静态和短期动态关系进行分析。步骤如下:第一,多重协整和JOHANSEN协整检验。对一组数据对数化处理后进行2种检验,2种检验的结果可能不一致,这就需要根据具体问题进行选择。由于要求数据是非平稳的,一般是采用单位根检验。具体来说,JOHANSEN协整检验对于10维以内的序列都是有效的,因此应用也较多。第二,确定最优滞后阶数,建立VEC模型。需要注意的是对滞后阶数为1的协整性检验,在lag intervals for D的操作中应选择0与0。第三,预测,判断预测结果是否符合经济学意义。
2.4 综合集成预测 综合集成预测是应用型模型,主要是针对几个相关模型在同一事件计算中产生结果不一致时,通过运算取得良好的实践效果。它既能发挥各模型的长处,又能有效规避其带来的误差。具体来说,有2种方法。
1)简单平均法。即对各个模型结果相加,然后按照个数进行平均。这种方法操作简便,有时效果也很显著,可以避免由于单个模型的误差过大带来结果的偏差较大,但该模型没有赋予每个模型预测值的权重,不能更好展示预测效果较好模型的优势。
2)加权平均法。加权平均法指各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数,即根据每个模型的权重进行加权平均。这种方法有效弥补了简单平均法的不足。具体操作:将预测值与以往真实值之间作误差分析,计算出每个模型的预测结果与真实值之间的误差数,并依据这个误差数给出不同的权重。权重的计算是取每个模型的误差值的倒数,然后进行归一化处理,详见下文。加权平均法能够更好地发挥拟合较好的模型优势,同时又全面地纳入了所有模型的预测结果。
3 数据描述与实证分析
3.1 数据描述 研究需要的相关数据均来自于中国统计年鉴和中国奶业年鉴(二者统计口径一致)。由于2012年以前2个统计年鉴中均未给出全国乳制品消费量的指标,仅给出城乡不同的消费量,因此全国乳制品消费量的计算数据是两者数据的平均数,经过对比发现能很好地反映实际情况(图1)。同时,由于2000年以前城乡乳制品消费与鸡蛋消费合计在一起,因此数据从2000年开始统计。由图1可以看出,2000—2007年我国乳制品消费处于快速发展期,乳制品消费增速为历史最高;2008—2012年我国乳制品消费处于危机应对期,消费趋缓;2013—2016年我国乳制品消费处于信心重振时期,乳制品消费增长缓慢,尤其近两年甚至出现停滞和倒退的趋势。
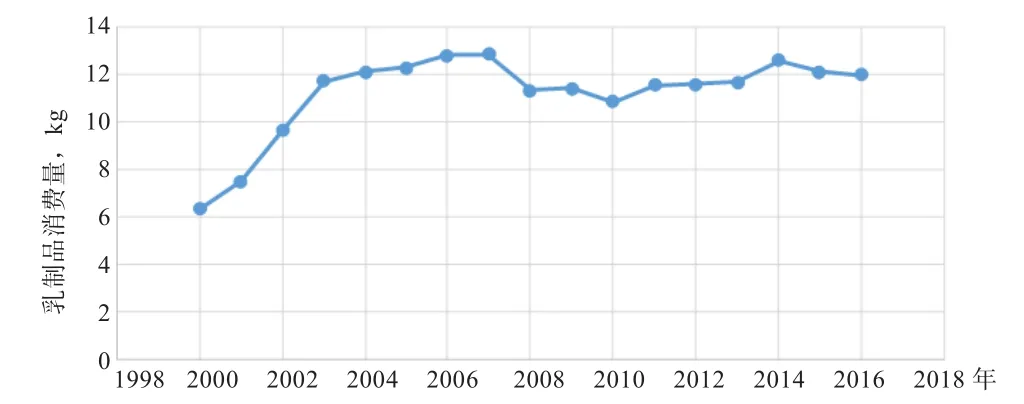
图1 2000—2016年我国居民乳制品消费量
3.2 基于ARMA模型的消费趋势预测 在Eviews 8中导入2000—2016年的全国乳制品消费量数据,通过绘制数据折线图发现序列具有明显的增长趋势,序列属于非平稳。因此,需要对数据进行差分处理,之后再通过自和偏相关性检验进行模型检验(图2),通过观察,差分后的时间序列自相关系数很快趋于0,数据平稳。然后,通过图形进行模型的识别和定阶。在偏自相关的分析图中,k=1后已显著为0,可以认为序列的偏自相关函数具有截尾性。因此,对序列可建立AR(p)模型。因此取p=1。所以,初选AR(2)模型。同样,观察自相关序列,自相关系数在1或2后表现为截尾,可以建立MA(q)模型,而取q=1,或q=2。
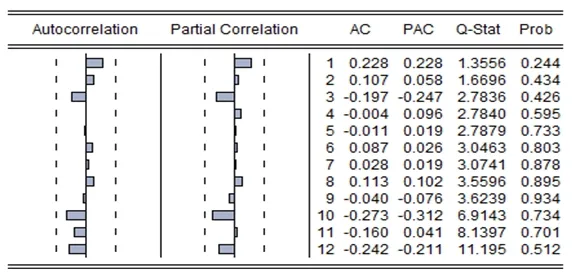
图2 ARMA模型中新序列ilx1序列自相关与偏相关图
经过以上模型的识别所确定的阶数,初步确立ARMA(1,1)和ARMA(1,2)模型。在主窗口中选择quick/estimate equation 对话框,输入 iilx1 ar(1)ma(1) ma(1) 和 iilx1 ar(1)ma(1) ma(2), 对输出结果进行对比。从预测R2和AIS/SC值可以看出,ARMA(1,2)模型更适合,预测R2为0.61,模型具有较好的解释力。随后对模型进行检验,具体步骤:View/Residual/Correlogram-Q-Statistics,发现当 m<13时,残差序列自相关系数都落入随机区间,AC的系数取正值后几乎全小于0.09,表明残差序列是随机的,检验通过。最后,通过扩展样本期进行样本预测,输入expand 2000 2020,则样本序列长度就变成2000—2020区间。在方程估计窗口点击Forecast,选择动态预测方法(Dynamic Forecast),根据所选择的一定的估计区间,进行多步向前预测,预测拟合效果如图3所示。由图形可以看出拟合效果较好。
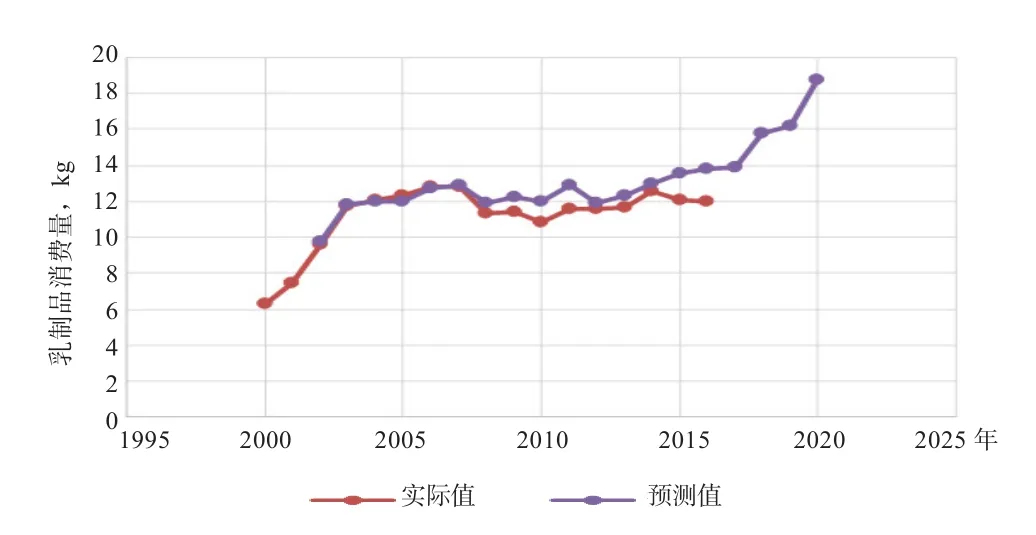
图3 ARMA模型建模预测拟合效果图
3.3 基于VAR模型的消费趋势预测 VAR非结构模型需要至少2种相关性序列,因此将全国总消费量、城市消费量和农村消费量一起导入到Eviews 8软件中。对序列分别记为y1、y2和y3。为避免数据的波动,先对各序列进行对数化处理。首先,确定最大滞后阶数,在VAR估计结果窗口点击确定按钮后选择View/lag structure/lag length criteria在出现的对话框中输入所要考察的最大滞后阶数(例如3),得到结果(表1)。由结果可知,“*”标记的依据相应规则选择出来的滞后阶数大多在3阶的位置,可以将模型的滞后阶数定在3阶。之后,进行参数估计,具体步骤为new object/Var,观察检验结果,估计参数R2为0.79,说明效果较好。之后,将输出结果保存,系统自动命名为var01。
接下来,进行平稳性检验,结果显示AR特征多项式系数均小于1。通过观察graph形式的特征多项式根,其倒数只有1个未在单位圆之内。表明VAR模型满足平稳性条件。同时,通过格兰杰因果检验表明3个序列相关适合建立向量自回归模型。为进行预测,在模型结果中选择proc/make model,并对数据进行扩展,得到预测结果如图4所示。

图4 VAR模型建模预测拟合效果图
3.4 基于VEC模型的消费趋势预测 VEC和VAR模型关系非常相近,区别在于VEC是在VAR模型的基础上加上协整约束条件。同时,VEC模型需要非平稳序列,而本次使用的时间序列,其本身就具有非平稳性的性质。但为减少波动,需要对3个序列进行取对数处理后做单位根检验,得到的统计值均在95%的置信度下拒绝原假设。故3个对数化的产出序列满足协整检验的条件。在VAR模型var01模型运算的基础上,在Estimate工具栏中选择VEC模型,在cointegration和VEC Restrictions处选择软件的默认设置即可。扩展数据为2000-2020,得到最后VEC模型检验结果R2为0.89,因此模型具有很好的拟合效果。由图5也可以看出,模型的实际值和预测值之间具有很强的一致性。
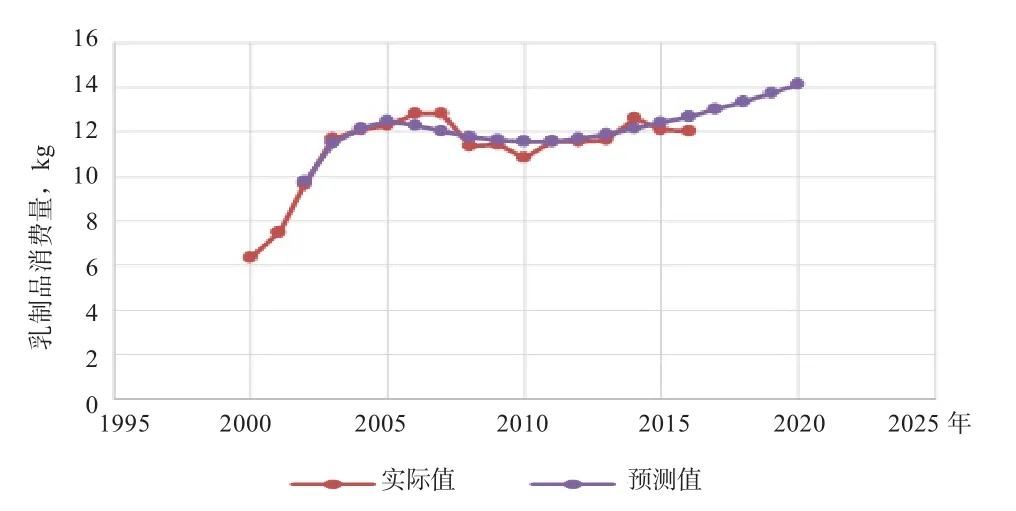
图5 VEC模型建模预测拟合效果图
3.5 3种模型的综合集成预测 经过以上3种模型进行分别预测后,各模型的预测值及相对预测误差率如表2所示,ARMA模型最大的误差为2016年,误差为9%,其余误差为1.97%、2.3%和7.52%,平均总误差为5.19%。VAR模型最大误差为2016年的12.6%,其余误差为3.68%、4.04%和8.01%,平均总误差为7.08%。VEC模型最大误差为2016年,为5.8%,其余误差为1.97%、2.14%和2.47%,平均总误差为2.09%。从总误差比较可以得出,VEC模型预测结果最优。整体而言,3种模型的预测趋势基本相同,2016—2020年我国乳制品消费量基本处于缓慢上升趋势,这与当前经济定位和理论分析基本相符。

表1 VAR模型滞后阶数判断结果

表2 3种模型下乳制品消费量预测值及误差率比较 kg
为减少模型过高和过低预测的可能性,进行综合集成预测。综合集成方法是根据加权公式,将3个模型的总误差值取倒数,然后归一化处理得到各自的权重。集成结果为:ARMA模型的权重为24%,VAR模型的权重为17%,VEC模型的权重为51%。
通过权重计算之后,最终得到在各权重下集成预测结果(表3)。从表中可以看到综合集成预测之后的结果更加稳定,很好避免了单个模型预测的局限性。由图6可以看出,2011—2014年我国乳制品消费水平增长缓慢,2014—2016年,我国乳制品处于微弱的下降状态。从集成预测值的增速上看,2017—2020年每年增速位于6%以下。由此可见,今后一段时期内我国乳制品消费增长缓慢。
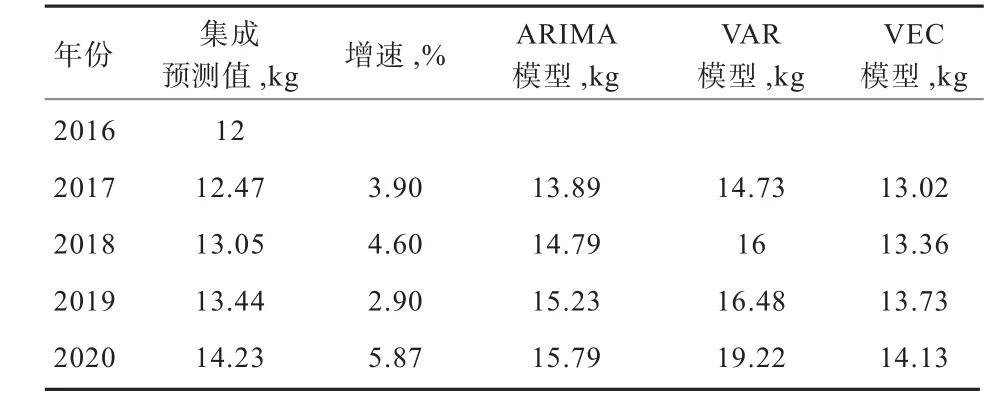
表3 我国乳制品消费水平集成权重结果
为更好分析我国乳制品消费水平变动趋势缓慢的原因,需要研究城乡居民不同消费水平的变动趋势,结果见表4,2016—2020年我国城市居民乳制品消费水平增速基本处于3%以下,表明城市居民乳制品消费水平基本处于停滞期,即不再增长或有一定程度下降。而农村居民乳制品消费水平正处于缓慢增长期,增长速度逐渐增加。

图6 2000—2020我国乳制品变动趋势集成预测
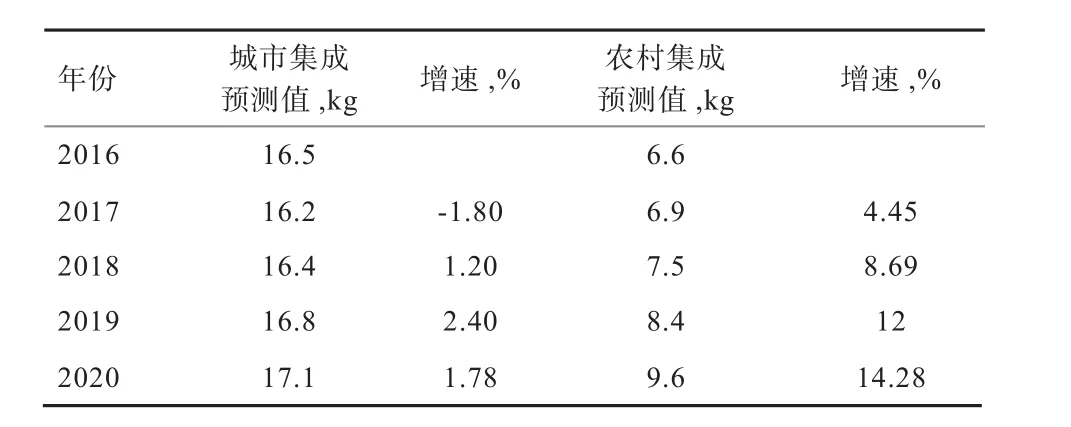
表4 城乡居民乳制品消费水平集成预测结果
4 结论与建议
通过分析并对比发达国家乳制品消费历程[7],得出如下结论:
1)城市居民对常温奶消费趋向饱和,正处于扩大低温酸奶的消费阶段,尚未形成高端乳制品的消费习惯,如奶酪、巴氏奶等,这是我国乳制品消费水平一直较低的重要原因。由于2种乳制品特点不同,低温酸奶的消费量往往低于常温奶。因此,城市居民总消费量会呈现略微的下降趋势。
2)农村居民乳制品的需求不断增加,但由于过去逢年过节购买乳制品送礼的习惯正在被打破,农村居民乳制品消费量不会快速增加。
3)由于城乡居民乳制品消费结构正发生变化,乳制品消费必然要经历一段时期的缓慢增长,这是正常现象。
因此,应加强奶业振兴和供给侧结构性改革战略,更好实现乳制品的供需匹配;加强乳制品宣传和引领作用,提高居民消费意识和对高端乳制品的消费追求;扩大零售终端网络建设,尤其是中小城市和广大农村,拓宽消费者对不同结构乳制品的消费渠道;建立乳制品监管的长效机制,只有具备过硬的乳制品质量安全保障措施,居民对乳制品的消费信心才会快速恢复。
猜你喜欢
西安体育学院学报(2023年5期)2023-04-29 17:48:37
今日农业(2022年15期)2022-09-20 06:54:16
大学数学(2021年5期)2021-10-30 09:01:04
华东师范大学学报(自然科学版)(2021年3期)2021-06-03 09:30:10
——基于指数增长模型
商业经济研究(2020年17期)2020-09-16 08:04:00
新课程(中学)(2018年9期)2018-11-20 02:32:22
上海金属(2016年4期)2016-04-07 16:43:41
世界热带农业信息(2015年7期)2015-05-30 10:48:04
中国有色冶金(2015年5期)2015-01-28 02:30:12
电讯技术(2014年1期)2014-09-28 12:25:26
