
反刍动物粪尿氮排泄预测模型的研究进展
2018-08-20 06:05:16董瑞兰于光辉
中国畜牧杂志 2018年8期
董瑞兰,于光辉
(青岛农业大学动物科技学院,山东青岛 266109)
畜牧养殖业带来大量的氮素排泄,尤其是大型规模化奶牛和肉牛养殖场,是农业面源氨(NH3)排放的重要来源[1-2]。反刍动物摄入的氮素主要以粪便和尿液的形式排泄到陆地和水体系统中储存或降解[3]。粪氮(FN)主要包括日粮源或内源性蛋白质,不易快速降解[4];而尿氮(UN)主要以尿素氮的形式存在,易被脲酶催化和水解成NH3挥发[5-6]。氮素排泄导致的污染不仅影响气候变暖(如N2O)[7-8],还对臭氧水平[9]、生物多样性[10]和人体健康(PM2.5)[11]等多方面产生严重影响。氮素的排泄量受饲料粗蛋白质(CP)水平和消化率的影响[12]。当反刍动物日粮CP水平较高时,多余的氮素则通过UN和FN排泄[13-14],例如奶牛摄入的氮素仅少部分用于产奶和满足营养需要,其余70%~80%排泄到环境中[15],其中尿中的尿素氮则转化为NH3挥发损失,对环境造成了严重污染[16]。
通过建模对反刍动物氮素排泄进行准确定量是评估环境影响的有效措施[17],而准确预测UN也是预测NH3排放的基础[18-19]。尿氮随日粮蛋白质含量和日粮组成及消化率不同而发生变化[20-21]。因此,预测氮素排泄的路径(尿液和粪便)意义重大[22]。准确预测反刍动物氮素排泄是评估反刍动物对全球大气环境的影响,同时也是制定调控及减排策略的有效方法。
1 反刍动物氮摄入与氮排泄
反刍动物摄入的氮素主要来自饲料,分为瘤胃降解蛋白质(RDP)和非降解蛋白质(UDP)[23]。RDP在瘤胃微生物(如瘤胃细菌、原虫等)的作用下转变成多肽和氨基酸,最终降解为NH3。生成的多肽有2种代谢途径:一是通过代谢合成微生物蛋白(MP),多肽比氨基酸更容易代谢合成MP,特别是饲喂低蛋白日粮时;二是直接被瘤胃和瓣胃吸收。氨基酸的主要去向一是被微生物吸收,二是通过氨基酸(以缬氨酸和亮氨酸为例)的脱氨基作用形成挥发性脂肪酸:
缬氨酸→CO2+氨+异丁酸
亮氨酸→CO2+氨+异戊酸
生成的NH3主要有3个去向:一是通过瘤胃壁吸收;二是形成MP(20%核酸蛋白质)[24],是微生物利用氮素的主要形式;三是参与瘤胃内氮素循环。组织和瘤胃壁吸收的NH3经过血液循环到达肝脏,在肝脏合成尿素,生成的尿素一部分经尿素再循环随血液和唾液回到瘤胃,继续参与MP合成;另一部分到达肾脏随尿液排出,形成UN。合成的MP和瘤胃UDP,以及一些脱落的内源性蛋白进入小肠后,在小肠酶的作用下,被分解为氨基酸供组织利用。未被消化的MP、内源分泌物,包括肠道脱落的上皮细胞和消化酶等非蛋白含氮物经大肠随粪便排出,形成FN。
由于反刍动物瘤胃微生物利用CP的能力有限,如果饲喂动物富含高水平CP的日粮,摄入的多余CP会损失掉。因此,有必要从动物摄入饲料氮的源头分析,通过对氮素排泄进行准确预测,促进氮素的有效利用和环境的可持续发展。
2 预测氮素排泄的相关模型
目前,关于肉牛养殖氮素排泄的预测模型研究较少,都是用日粮化学组成和动物特征变量建立的总氮(TN)预测模型,只有Dong等[22]和Waldrip等[25]对肉牛的UN和FN分别进行了预测。奶牛的氮素排泄预测研究较早,预测的准确性顺序为TN>FN>UN[26]。
2.1 肉牛氮素排泄预测模型
2.1.1 基于氮平衡建立的预测模型 Guo等[27]基于氮平衡理论Nexcretion=Ndiet-Ngain提出了生长育肥型肉牛氮素排泄的预测模型:

式中,Nexcretion为肉牛氮排泄量(kg/d),Ndiet为肉牛氮需要量(kg/d),Nintake指肉牛氮摄入量(kg/d),EBW1指在某阶段开始时(t1)的空腹体重(kg),EBW2(kg)指该时期结束时(t2)的空腹体重。Ngain=0.0376(EBW2–EBW1)+0.0000208(EBW22–EBW1
2)表示机体在空腹基础上增加的氮素。
此模型的优点是仅使用了2个变量(Nintake和某个阶段的体重差),可准确预测氮素排泄的最小阈值,也可用于确定某一区域生长育肥牛的最大承载数量。此外,该模型可有效预测不同品种、体尺和性别的育肥牛。其不足之处是不能准确预测不同阶段的肉牛(如犊牛和繁殖母牛),而且在田间条件下的应用还需要通过程序模拟计算,因此在中国的推广应用受限。
2.1.2 计算机模型 Guo等[28]用STELLA®软件建立了育肥肉牛氮素排泄的计算机模型(2)。根据(美国)国家科学委员会(NRC)[29]标准,肉牛育肥阶段Ndiet为维持(MPm,用于维持的代谢蛋白需要量,g/d)和生长(MPg,用于体重增加的代谢蛋白需要量,g/d)需要之和,计算过程:


式中,Nexcretion为肉牛氮排泄量(kg/d),SBW为宰前活体重(kg),MPg为增加体重需要的代谢蛋白量(g/d),当空腹体重当量(EQEBW)≤300 kg时,MPg=NPg/(0.834–0.891×SBW×(SRW/FSBW)×0.00114),NPg为净蛋白需要量(g/d),SWG为宰前活体增加重量(kg/d),SRW为不同终末体重组成的标准参考重量(SRW为478 kg时,用于体脂肪为28%的小型大理石花纹的后备小母牛和种公牛;SRW为462 kg时,用于体脂肪为27%的轻微大理石花纹的育肥牛;SRW为435 kg时,用于体脂肪为25%的微量大理石花纹的育肥牛);FSBW为分别用于达到体脂终点的公牛或后备小母牛、成熟的小母牛或种公牛(为最终的成熟体重×0.6)的实际宰前活体重;当空腹体重当量(EQEBW)>300 kg时,MPg=NPg/0.492;其中NPg=SWG×{268–29.4×4.18×106×[0.0635×(0.891×SBW×(SRW/FSBW))0.75×(0.956×SWG)1.097]/SWG}。
结果表明,模型(2)对模型(1)的算法及系数进行改进。因此,其同样适用于阉牛和种公牛的氮素排泄预测,但是模型(2)是基于STELLA®软件开发的计算机模型,在动物生产中的应用并不常见,同样不适合用于犊牛和繁殖母牛的氮素排泄预测。
2.1.3 经验模型 Yan等[30]用286头肉牛的消化试验研究了日粮和动物因素对肉牛氮素排泄的影响,发现TN(UN、FN)的排泄与肉牛的体重(BW)、干物质采食量(DMI)、Nintakee和代谢能采食量(MEI)呈正相关关系,而与日粮粗饲料的比例(FP)呈负相关关系,并且基于多元线性回归分析建立了预测TN排泄的模型:
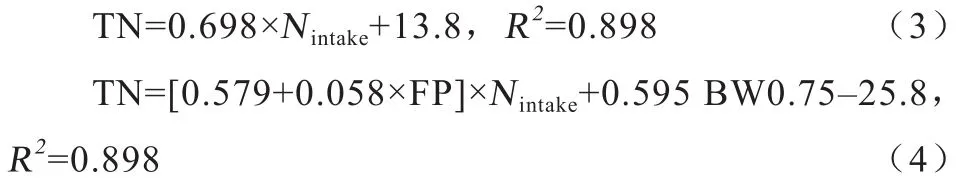
Waldrip等[25]将TN中UN和FN区分,建立了分别预测UN和FN以及UN/TN模型:

式中,UN/TN指尿氮占总氮排泄的比例,Nintake指肉牛氮摄入量(g/d)。
Dong等[22]用49个已发表研究的数据对肉牛UN和FN的排泄量进行了预测,同时对Waldrip等[25]的模型进行改进,数据库涵盖了869个动物和180种日粮,包括了肉牛BW、DMI、CP、Nintake、氮全消化道表观消化率(TTND)以及UN和FN等变量。并基于回归分析分别建立了UN(模型(9))和FN(模型(10))以及UN/TN(模型(11))的预测模型:

式中, TTND指肉牛氮全消化道表观消化率(%)。
以上模型(3)至(11)均为肉牛氮素排泄预测的经验模型,考虑的变量因子主要是Nintake,可分别对UN和FN进行预测,但Dong等[22]的模型与Waldrip等[25]的相比,涵盖了不同的肉牛品种和不同国家的肉牛饲料,对中国也同样适用。而且模型(9)和(10)均已被编入加拿大第3次环境会议的报告中,用于氮素排泄预测的减排决策。
2.1.4 肉牛氮素排泄预测模型的精度和误差 肉牛氮排泄预测模型的适用性、适用条件、误差比较见表1。在Guo等[27]提出的模型(1)中,肉牛品种、性别和体尺等因素对Ngain均有影响,应用时需额外计算校正因子。Guo等[28]的模型(2)中,Ndiet在试验条件下易获得(Ndiet=DMI×CP×16%),而在田间条件下需通过育肥牛的蛋白质需要来估算,但其预测的是特定阶段起始和结束时的空腹体重最低值,且为育肥牛实际采食营养需要的最小值,造成模型(2)预测的氮素排泄量偏低。Yan等[30]在模型(3)中用Nintake预测TN排泄,决定系数(R2)较高,同时误差较小,标准误(SE)为12.3 g/d,当模型(4)添加了BW和FP 2个附加预测因子时,仅使预测的误差略微下降,SE为11.2 g/d。模型(3)和(4)的R2值均较高,适合准确预测欧洲国家肉牛的氮素排泄。
Waldrip等[25]提出的预测模型(5)至(8)适合预测精饲料较高的肉牛。模型的测试结果显示,UN、FN的预测值和实测值之间的R2值分别为0.82和0.61,模型(7)和(8)的预测值和实测值之间R2值均较低,分别为0.45和0.44,原因可能与建立的数据库不够完善或使用的变量不合适有关[22]。
Dong等[22]通过建立大数据库改进了Waldrip等[25]的肉牛模型,降低了UN(21.18 vs14.12)和FN(24.28 vs15.82)模型的常数项值。考虑到UN在TN中占较大的比例,Dong等[22]研究预测UN/TN时,模型(11)比Waldrip等[25]的模型(7)和(8)预测效果好,其预测值和实际观察值一致[R2=0.68,符合指数(IA)=0.87]。所以,在实际中推荐用TTND预测UN/TN。
2.2 奶牛氮素排泄预测模型 奶牛干奶期的氮素排泄预测模型与肉牛相似,而泌乳奶牛摄入的氮素在分配过程中除包括UN和FN以外,还包括乳中的氮。由此可知,预测泌乳奶牛氮素排泄可考虑产奶量或乳成分等变量[31-32]。
2.2.1 基于饲料组分建立的预测模型 1)基于CNCPS(Cornell Net Carbohyd Rate and Protein System)组分建立的预测模型 Fox等[33]用康奈尔净碳水化合物和蛋白质体系(CNCPS)饲料组分来预测奶牛氮素的排泄,建立奶牛UN和FN排泄的预测模型:
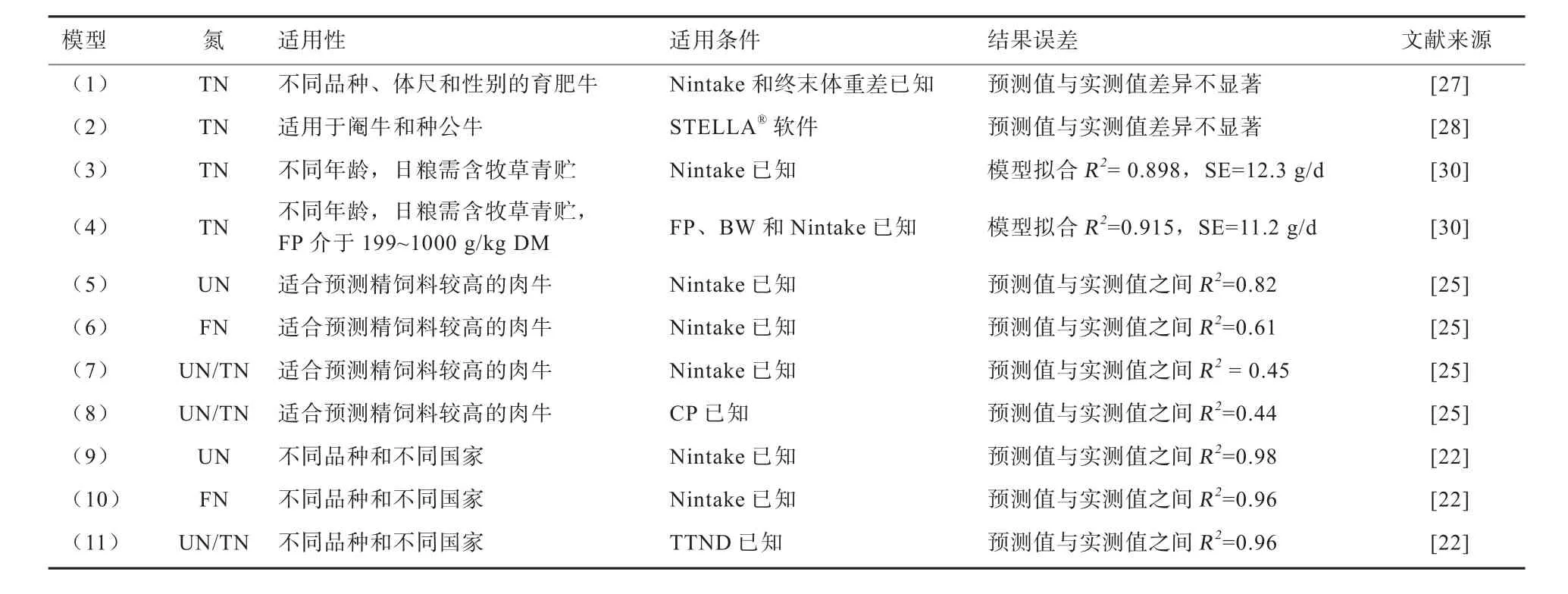
表1 不同肉牛氮排泄预测模型适用性、适用条件和误差比较

式中,PA为每种饲料的蛋白组分A;PB1为每种饲料的蛋白组分B1(%);PB2为每种饲料的蛋白组分B2;PB3为每种饲料的蛋白组分B3;PC为每种饲料的蛋白组分C,单位均为%;FEPB3为粪便中的蛋白组分B3(g/d);FEPC为粪便中的蛋白组分C(g/d);FEBCP为粪便中的菌体蛋白含量(g/d);IDM为不可消化的饲料干物质(g/d);SPA为皮屑净蛋白需要量(g/d);Milk为产奶量(kg/d);Milk CP为乳蛋白(%);MPpReg为用于妊娠期代谢蛋白质的需要量(g/d);MPg为用于体重增加的代谢蛋白质需要量(g/d)。
用CNCPS日粮变量预测奶牛氮素排泄有如下优势:一方面,模型的输入变量在大多数农场易获得;另一方面,获取输入变量的过程中,不会对奶牛场造成重大的经济风险,也不会给奶牛的生产性能带来不利影响。其不足之处是模型涉及的输入变量数量多,因此限制了在生产中的广泛应用。目前,用该模型预测奶牛的TN排泄量是被认可的,但是预测UN和FN还需改进。
2)一元一次线性模型(即y=a+bx) Nennich等[34]研究发现,可用RDP预测奶牛UN的排泄,并基于回归关系建立了一元一次线性模型:

式中,RDP指瘤胃降解蛋白质(g/d)。
Yan等[35]发现可用Nintake(g/d)预测排泄的TN:

式中,Nintake指奶牛氮摄入量(g/d)。
上述2个模型均属于简单的线性模型,而且都使用单一日粮变量(如RDP和Nintake)对奶牛的UN和TN分别预测,生产中易获得,便于实际应用。日粮的CP含量被证实可影响UN的排泄[36],RDP对日粮CP的可降解特性进行了有效描述,但是其需要量要预先用NRC[37]模型计算获得。Nintake是日粮变量中与TN相关性较强的变量,因此Yan等[35]用Nintake实现了TN的准确预测。同样地,Nintake用于中国荷斯坦奶牛的TN预测时,建议用中国的生产数据校正变量的系数。
3)二元一次线性模型(即y=a+b1x1+b2x2) Hutanen等[38]研究发现,用Nintake和DMI可以准确预测FN的排泄:

式中,FN指奶牛粪氮排泄量(g/d)。研究发现,奶牛FN排泄量随Nintake的增加而增加[39]。Hutanen等[38]研究表明,可用DMI预测FN,而且同时用DMI和Nintake比单独用Nintake预测的效果好。该二元模型的优势是更好地考虑了初始FN损失,因FN损失主要来自未被消化的饲料氮、未被消化的微生物氮以及内源性氮素,代谢性和内源性的氮素是粪氮排泄的主要贡献源,与DMI紧密相关,而未被消化的饲料氮则与Nintake相关。不足之处是此二元模型的常数项系数为负数,这从奶牛的消化代谢角度无法解释,也间接说明DMI和内源性粪氮之间可能呈曲线回归的关系。
2.2.2 基于饲料成分和动物的特征变量建立的经验模型Nennich等[40]研究发现,当Nintake未知而CP已知时则可用模型(17)来预测TN:
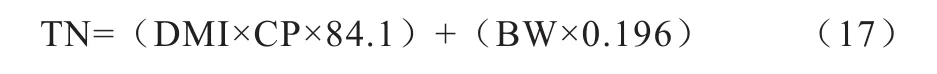
该模型的日粮范围代表了更广泛的地理区域,且包含了产奶量大于40 kg/d的奶牛数据,由于考虑了奶牛BW,所以用此模型可以同时预测犊牛、母牛、奶牛干奶期和泌乳期的TN排泄,尤其当Nintake缺乏时,可用CP摄入量预测TN(SE为51.4 g/d),因此也适用中国奶牛的氮素排泄预测。
2.2.3 基于产奶量或乳成分建立的一元一次线性(y=a+bx)模型 乳中尿素氮(MUN,mg/100 mL)是一个可以快速获得且不会对奶牛造成损伤的指标,也可预测奶牛UN排泄量。Jonker等[41]用3个独立的饲养试验研究泌乳奶牛氮的利用率,同时用变量MUN建立了荷斯坦奶牛UN和FN的预测模型(18)和(19)。模型的MUN介于9.7~29.6 mg/100 mL,平均值为18.46 mg/100 mL。

模型(19)中,Nintake=(UN+Nmilk+97)/0.83, Nmilk指乳中氮的含量(g/d)。
随着研究的深入,有研究发现模型(18)预测的变量有偏差[42]。Kauffman等[43]对用MUN预测UN的排泄进行了校正:

Nennich等[40]发现,泌乳奶牛TN与产奶量(MY)之间呈现显著的正相关关系:

Zhai等[44]通过饲喂中国荷斯坦奶牛4种CP水平的日粮(分别为13.2%、14.1%、15.0%、16.2%),发现MUN与UN之间存在极显著的线性关系,并据此建立了用MUN来预测UN排泄的线性模型:

上述模型(18)、(20)和(22)表明,MUN与UN存在显著的线性关系。模型(22)是基于中国荷斯坦奶牛数据建立的,所以更适合预测中国奶牛的UN排泄,但其日粮CP范围较窄(13%~16%),不能准确预测蛋白质低于13%或者高于16%时的情况。泌乳奶牛TN的排泄量随产奶量的增加而显著地增加,模型(21)的准确性低于模型(17)(其SE值51.4 vs 70.9 g/d),因此,尽管该变量在生产中易获得,但考虑到模型预测的准确性,故不推荐在生产中使用。
2.2.4 基于饲料组成和乳成分建立的预测模型 基于饲料组成和乳成分建立的预测模型见表2。
最早开始对奶牛TN进行预测的是模型(23),使用多个参数使测定过程更复杂,限制了其在生产中的应用。模型(26)仅使用了3个变量,参数获得较为方便,更适合预测中国奶牛的实际生产。预测FN时,相比于模型(24)的多个参数,Higgs等[46]的模型(29)和Marini等[47]建立的方程更实用,但二者的准确性需用中国荷斯坦奶牛的数据验证。在UN预测模型(25)、(27)、(28)及(30)和(31)中,基于变量获取的方便性和模型的应用考虑,模型(27)更适合预测中国奶牛的尿氮排泄。
2.2.5 基于尿常规指标建立的模型 Burgos等[49]研究发现,将尿比重(USG,mg/100 mL)作为预测尿中尿素氮排泄的方法在空气质量方面有重要调控意义,并描述了尿比重、血浆尿素氮(PUN,mg/100 mL)、MUN(mg/100 mL)与尿中尿素氮(UUN,mg/100 mL)或总UN的多变量统计模型,结果发现USG是唯一与UUN或UN显著相关的变量:

Burgos等[49]研究证实,USG是预测农场奶牛个体和群体UUN的有效工具,也是预测NH3排泄的方法,但USG携带的信息量较少,其与UN和UUN的关系还需进一步研究。
2.2.6 基于饲料成分和能量摄入建立的经验模型 饲料成分和能量摄入建立的奶牛氮排泄经验模型见表3。能量类型对奶牛的氮排泄模式有潜在的影响,模型(34)和(35)在Nintake的基础上增加日粮的能量或者品质作为预测的协变量[50-51],避免了动物可利用氮的过高估计。模型(36)应用范围较广,更适合预测中国泌乳奶牛TN的排泄量。其不足之处是不能分别预测FN和UN。Reed等[52]用1990—1995年美国农业部的数据测试了模型(37)、(38)和(39),发现在Nintake和 DMI以及Nintake的基础上增加5个预测变量,UN、FN和TN的预测误差分别降低2.1%、1.6%和0.14%。鉴于改进幅度较小,建议用简单变量进行预测。

表2 基于饲料组成和乳成分建立的奶牛氮排泄预测模型
2.2.7 奶牛氮素排泄预测模型的精度和误差 奶牛氮排泄预测模型的适用性、适用条件、误差比较见表4。
Wilkerson等[45]研究表明,预测模型TN(模型(23)的R2值为0.646)的准确性高于FN(模型(24)的R2值为0.553)。Kebreab等[50]研究显示,预测模型FN(模型(35)的SE为0.29 g/d)的准确性高于UN模型(模型(34)的SE为0.38 g/d)。UN预测模型(12)和FN模型(13)使用了FEPB3、FEPC、FEBCP等多个变量,生产中不常用也不易获得,限制了模型的应用。Reed等[52]发现,采食的能量与UN模型(37)呈正相关,而与FN模型(38)或总氮模型(39)呈负相关,不同变量之间存在共线性,如代谢能摄入量与Nintake之间还存在高度相关(皮尔森系数R=0.92),因此还有待继续改进。Burgos等[49]研究显示,MUN和UUN的相关关系较低(R2=0.11),故不支持用MUN来预测商业奶牛场的UN或UUN排泄。
1)尿氮预测模型 Nennich等[34]用RDP预测奶牛UN的排泄,模型(14)预测的误差为42.8 g/d。Kauffman等[43]提出了模型(20)的回归系数比JonkeR等[41]的模型(18)高40%。Zhai等[44]提出的预测模型(22)的R2值为0.82,仅使用少数日粮,未经验证准确性不确定。模型(25)的误差(38.6 g/d)低于模型(14)的误差(42.8 g/d),但预测尿氮的准确性没有显著改善,原因与多元回归关系中每个变量产生的误差有关,导致整体预测的准确性降低了。Hutanen等[38]研究发现,UN的排泄量随Nintake的增加而增加,但随DMI的增加而降低,将ME或产奶量作为模型(27)的第3个输入变量时,产奶量比ME效果更好。预测模型(28)将Fox等[33]模型(12)的一致关联系数(CCC)从0.84改进到0.9,并获得较高的决定系数值(R2=0.86),均方根误差(RMSE=12.73 g/d)也较低。Spek等[48]研究发现,用全收尿法测定UN能提高预测的准确性(如模型(30)和(31)),R2值为0.93。
2)粪氮预测模型 Hutanen等[38]研究发现,与Nintake相比,DMI与FN排泄紧密相关,模型(16)同时使用DMI和Nintake改善了预测效果。FN模型(29)的R2值为0.73,CCC为0.83,RMSE值为10.38 g/d。将Marini等[47]和Hutanen等[38]的FN预测模型与模型(29)相比,分别低估了20%和17%[44]。
3)总氮预测模型 Yan等[35]的模型(15)用Nintake预测TN排泄量,获得R2值为0.901,误差为30.6 g/d。Nennich等[40]提出的模型(17)预测误差(51.4 g/d)比模型(21)的误差(70.9 g/d)低19.5%,说明用CP、DMI和BW预测TN比产奶量更准确。Yan等[35]发现,模型(26)在Nintake预测的基础上增加活体重和产奶量,可使R2值从0.901提高到0.910,标准误差由30.6 g/d降低到29.3 g/d。模型(36)和(39)的均方根预测误差(RMSPE分别为15%和8%[52],表明模型(39)比(36)更准确。

表3 基于饲料成分和能量摄入建立的奶牛氮排泄经验模型
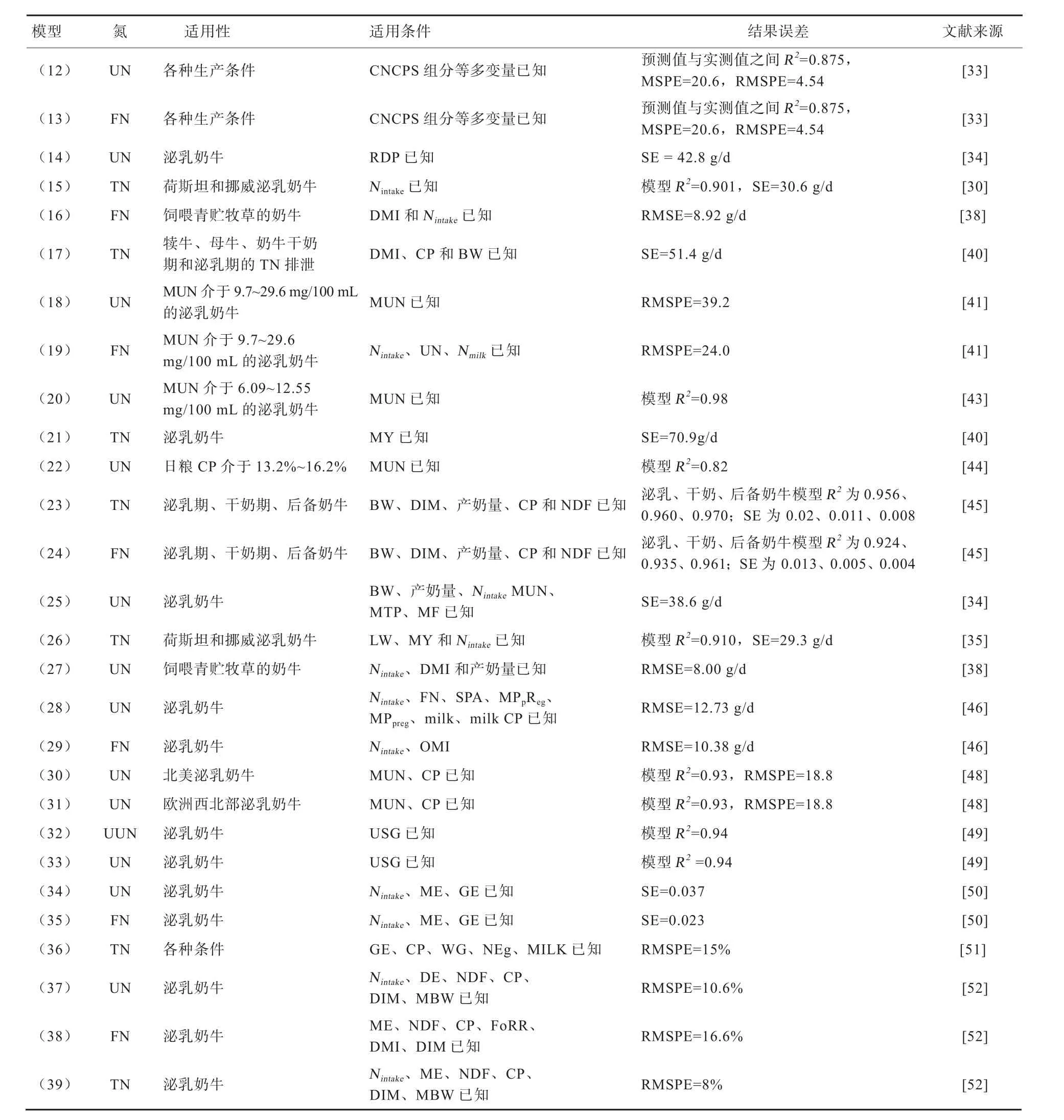
表4 不同奶牛氮排泄预测模型适用性、适用条件和误差比较
2.3 山羊氮素排泄预测模型
2.3.1 一元一次线性模型(即y=a+bx) Luo等[53]用总氮采食量(TNI,g/kg BW0.75)和表观消化氮采食量(DNI,g/kg BW0.75)分别对干奶期山羊的内源性尿氮(EUN,g/kg BW0.75)进行预测,建立了以下回归方程(n=79;R2=0.59):

EUN包括尿素、肌酸酐、胆红素、尿囊素、马尿酸、尿酸和氨基酸等[54],是不可避免的最少氮素损失,当饲喂动物含氮水平非常低但能量和其他营养足够的日粮时,EUN等同于UN的总排泄量。泌乳奶山羊的EUN预测方程与用DNI预测的干奶期山羊的预测方程较为相似,而用TNI(R2=0.65)预测时准确性较用DNI(R2=0.72)低:

Luo等[53]提出的模型(40)和(41)适合预测干奶期山羊EUN的排泄,但二者预测的准确性不高。模型(41)仅适合预测干奶期山羊的氮平衡≥0且采食量高于维持需要的情况,其优势是可用于求和方程中氮需要量的预测,而且不需要额外的校正因子。模型(40)预测的干奶期山羊EUN比泌乳山羊高10%,而模型(41)用变量DNI预测的干奶期山羊的EUN稍低于泌乳山羊。当用TNI和DNI预测泌乳山羊的EUN时,2个变量的预测差异不显著。
Rapetti等[55]研究发现,山羊UN与乳尿素水平(MUL, mg/100 mL)呈正相关关系,并基于MUL建立了如下模型:

Schuba等[56]用17篇文献数据对山羊的FN进行了预测:

式中,FN指山羊的粪氮排泄量(g/d),Nintake指氮摄入量(g/d),AIC为阿凯克信息论准则(AIC)。
2.3.2 二元一次线性模型(即y=a+b1x1+b2x2) Moore等[57]用146篇发表文献对山羊的FN进行了预测(模型(44)),FN为粪便代谢蛋白(MFCP,g/d)和未消化的日粮蛋白的总和,模型中MFCP用0.0267×DMintake(g/d)计算,未消化的CP排泄量(g/d)计算为(100–0.88)×CPintake。
FN=[0.0267×DMintake+(100–0.88)×CPintake]×16% (46)式中,FN指山羊的粪氮排泄量(g/d),DMintake指干物质摄入量(g/d),CPintake指日粮粗蛋白质摄入量(g/d)。该模型的优势是使用范围较广,涵盖了许多不同品种山羊和日粮类型,而且考虑了不同国家、体重、粗饲料比例等因素,数据全面,有代表性;其不足之处是使用的文献数据为处理均数观察值,而不是单位动物的实测数据,未消除不同研究的影响。鉴于DM和CP采食量均为生产常见变量,可推荐用于中国山羊粪氮排泄的预测。
2.3.3 一元二次非线性模型(即y=a+b1x1+b2x22)Schuba等[56]通过17篇文献数据研究发现,山羊的UN与Nintake之间呈二次非线性关系:

式中,UN指山羊的尿氮排泄量(g/d),Nintake指氮摄入量(g/d)。AIC分析表明,山羊UN(模型(47))比FN(模型(45))预测得更准确。
2.4 绵羊氮素排泄预测模型 Schuba等[56]用27篇文献数据对绵羊的UN和FN分别进行了预测(见模型(48)和(49)):

式中,UN指绵羊的尿氮排泄量(g/d),FN指绵羊的粪氮排泄量(g/d),Nintake指氮摄入量(g/d)。AIC分析表明,绵羊UN(模型(48))比FN(模型(49))预测得更准确。
3 前景与展望
从中国目前主要的肉牛(鲁西黄牛、利木赞牛、西门塔尔牛、夏洛莱牛、三元杂交牛、黑牛等)、奶牛(中国荷斯坦奶牛、三河牛、草原红牛、新疆褐牛等)和奶山羊(西农奶山羊、关中奶山羊、崂山奶山羊、成都麻羊等)品种来看,现有文献报道的肉牛(海福特牛、安格斯牛、海福特×安格斯杂交牛、三元杂交牛、英国无角白牛、夏洛莱牛、比利时蓝/白牛、内洛尔牛)、奶牛(荷斯坦奶牛、娟姗牛、更赛牛、艾尔夏牛)和奶山羊(萨能奶山羊、阿尔卑斯山羊、安哥拉山羊、努比亚山羊等)品种与中国相比,有些品种被中国引入饲养。预测模型反映的是氮素输入与输出之间的规律,但也因国内外品种的不同而导致预测结果有所差异。因此,在实际生产中应用时,最好用中国的氮排泄量数据库校准现有模型中变量的系数。若校准条件不具备,也可直接使用现有的氮排泄预测模型。
纵观现有的氮素排泄模型,未来可从以下方面改进:
1)统一方法、减少误差。建模所需的数据推荐用全收粪尿法测定,比指示剂法(如三氧化二铬(Cr2O3)等)估测的更加准确,能提高氮素排泄预测的准确性,降低由测定方法造成的误差。
2)选择合适的模型输入变量。尽管动物或日粮的特征输入变量与氮排泄紧密相关,但是筛选出强相关的最佳变量可提高预测的准确性。选择的变量应反映动物氮排泄的内在规律。此外,预测变量应尽可能方便获得,如果预测的准确性很高,但是变量获取难度大,对模型的应用也会造成很大影响。
3)开发科学、高效的计算机软件模型。与传统的经验回归模型相比,新型的人工智能模型可能更准确反映输入与输出变量的复杂关系,便于在生产中推广使用。
4)收集有代表性的数据。建模数据要实时更新,用过时的数据预测当前的动物氮排泄量,误差较大。
综上所述,现有模型适合预测欧美发达国家反刍动物的氮素排泄,急需建立适合中国反刍动物养殖模式的氮素排泄预测模型,进而为中国反刍动物氮素和NH3的减排策略提供相应的数据支持。
猜你喜欢
中华骨与关节外科杂志(2023年10期)2023-12-04 09:44:54
中国全科医学(2024年6期)2023-11-17 01:04:02
今日农业(2021年15期)2021-11-26 03:30:27
科技风(2018年23期)2018-05-14 11:37:44
作文周刊·小学一年级版(2017年46期)2018-01-16 21:55:21
小天使·一年级语数英综合(2017年4期)2017-04-18 18:09:55
动物营养学报(2012年12期)2012-09-20 00:32:40
植物营养与肥料学报(2011年5期)2011-11-06 07:30:52
植物营养与肥料学报(2011年2期)2011-10-26 03:52:10
植物营养与肥料学报(2011年3期)2011-10-24 06:15:00
