
基于概率神经网络的手写体数字特征提取
2018-08-02 07:23李慧莹胡西川
现代计算机 2018年15期
李慧莹,胡西川
(上海海事大学信息工程学院,上海201306)
0 引言
在模式识别领域中,印刷体字符识别已经取得了令人满意的效果,但是对于手写体字符的识别效果仍然不是很理想。由于手写体字符的样本由不同人所写时,笔迹往往存在巨大差异,造成样本类别繁多,特征提取困难,导致识别效果无法令人满意。
脱机识别相较于联机识别,由于存在噪声与字符分割的问题,并且无法获知笔划顺序,会导致识别率大幅降低。对于数字字符识别而言,虽然只有10个类别,但是阿拉伯数字具有世界通用性,不同国家和地域的人在书写数字时存在很大笔迹上的差异,并且脱机手写体数字识别多数应用在银行票据、邮政编码等准确率要求非常高的领域[1],所以对于脱机手写体数字识别仍然需要不断加快识别速度和提高识别准确率。
近年来,脱机手写体数字识别领域提出了多种不同的分类方法,其中卷积神经网络在图像识别上取得了巨大的进步。另外还有部分学者提出的不同改进方法,有陈军胜提出的基于组合结构特征的方法[2]、任美丽等提出的基于原型生成技术的方法[3]、方向等提出的基于概率测度支持向量机的方法[4]等。
本文重点阐述手写体数字识别领域中,应用于结构特征提取阶段的一种改进方法,利用脱机手写体数字识别的识别率作为评价指标,与传统结构特征提取方法进行数据上的对比,来衡量改进程度。
1 结构特征提取算法
1.1 MNIST手写数据库
MNIST数据库是一个公认的手写数字数据库[5],由来自柯朗研究所的Yann LeCun、谷歌实验室的Corin⁃na Cortes以及微软研究所的Christopher J.C.Burges共同建立。其中包含60000个训练样本和10000个测试样本,由大约250名作家书写,并且保证训练集和测试集是来自不同的作家。MNIST手写数据库被公认的一个原因是该数据库中的数字形态复杂多样,有些甚至连人眼也很难识别,因此,该数据库几乎可以涵盖每一种手写情况,使训练和测试更为可信。该数据库中每个数字的维度为28×28像素,部分训练样本和测试样本如图1所示。
1.2 传统的结构特征提取方法
本文采用的对比对象是由宋昌统等所发表的《基于概率神经网络的手写体数字识别[6]》论文中提出的结构特征提取算法。由于MNIST数据库中的数字已经完成了字符分割等前期预处理工作,所以本文只从二值化开始讨论。本文在对MNIST数据库中的样本进行二值化时,选取的阈值统一为0.4×255。在二值化结束之后,MNIST数据库中的数字字符并没有对齐边缘,上下左右皆留有黑色空余位置,所以在二值化之后必须要进行字符的填充放大,使字符上下或者左右对齐边缘。《基于概率神经网络的手写体数字识别》[6]中给出的方案是使字符在保持纵横比的前提下,进行字符放大,使上下或者左右对齐边缘,如图2所示。

图1 部分训练样本和测试样本数字
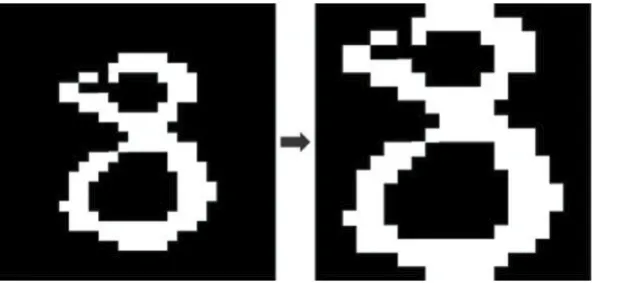
图2 字符放大示意
该论文的特征值由8个结构特征值和6个统计特征值组成。8个结构特征分别由3个纵向特征、3个横向特征和2个对角线特征组成,其中3个纵向特征值分别选取竖直1/4处、1/2处和3/4处白像素个数总和,3个横向特征值分别选取水平1/3处、1/2处和2/3处白像素个数总和,2个对角线特征值分别为主对角线和次对角线白像素个数总和,位置示意如图3所示。

图3 结构特征取值位置示意
6个统计特征选取区域分别是4个14×14像素区域、1个9×28像素区域和1个28×9像素区域,4个14×14像素区域分别位于左上、右上、左下和右下四个角,9×28像素区域位于水平方向1/3到2/3的位置,28×9像素区域位于垂直方向1/3到2/3的位置,分别统计这些区域内白像素个数之和的0.1倍作为特征值,统计特征选取位置示意如图4所示。

图4 统计特征位置选取示意
1.3 改进的结构特征提取方法
本文对结构特征的提取方法进行了改进,并相应地对字符放大过程进行了调整,先介绍调整后的字符放大方法。
传统的字符放大方式如1.2节中所描述,其前提在于保持纵横比不变,将字符统一到一致的尺寸上。显然,这种方法对于“高瘦”的字符,会将上下边缘对齐,如图2所示;而对于“矮胖”的字符,会将左右边缘对齐,如图5所示。

图5 “矮胖”字符放大示意
本文所提出的字符放大方法的区别在于始终保持字符的宽度不变,单方向地对字符进行纵向拉伸,不论宽度是怎样的字符都一律只使上下边缘进行对齐,左右方向不做调整。这种调整方式一方面是配合了改进的结构特征提取方法,另一方面又可在一定程度上抵消字符由于“高矮”所产生的差异。调整过后的方法对于“矮胖”字符处理示意图如图6所示,算法的MAT⁃LAB代码描述如下:
[x,y]=find(data==1)
data=data(min(x):max(x),:)
data=imresize(data,[28 28])
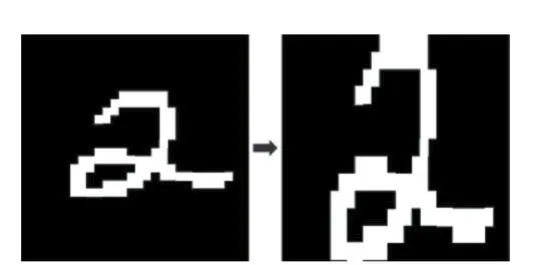
图6 调整过后的“矮胖”字符放大示意
在结构特征提取阶段,本文将传统的统计白像素个数总量的方法调整为统计在这一列或这一行中白线条出现的次数,即不区分白线条的粗细,在传统方法中如果白线条在一列或一行中由多个像素构成时,会累加这每一个像素的值,而改进的方法不论线条的粗细,每出现1次都是视为1,从而规避了线条粗细的影响。如图7所示,使用改进后的方法提取图中线条所在列的特征值为4,而传统的方法提取的特征值为7。

图7 改进的结构特征取值示意
由于二值化图像边缘有时会出现“凹口”,在使用改进的提取方法时会出现不必要的计算值,为了避免这种情况,在计算时,如果出现白线条被一个黑像素阻断的情况,处理方法是特征值不进行加1,而是继续保持原值,示意图如图8所示,图中线条所在列的特征值记为3,而不是4。本文提出的结构特征提取方法不进行对角线的特征提取,经部分测试,提取了对角线特征之后,识别率反而降低。改进的结构特征提取方法的MATLAB代码描述如下:

图8 被阻断的线条处理方式示意图
number=14
f(1:number)=0

2 实验数据
2.1 提取方案对比
MNIST数据库包含60000个训练样本和10000个测试样本,数据量庞大,为了加快测试速度,分别只选取其中1/10的样本量做测试,所得识别率仅作测试阶段的对比使用,而在最后的数据对比中使用的是全样本数据。
在字符放大方法中分为“保持纵横比放大法”和“单方面纵向拉伸法”,结构特征提取方法分为“传统特征提取法”和“改进特征提取法”[8],经排列组合,共有4种不同的提取方案。在保持其他条件均相同的情况下,对比这4种不同的提取方案。在识别阶段使用概率神经网络[7]作为分类方法,分别对每一种方案寻找各自最佳的扩散速度,记录4种不同方案的识别率,对比得出最佳方案。实验数据如表1所示。
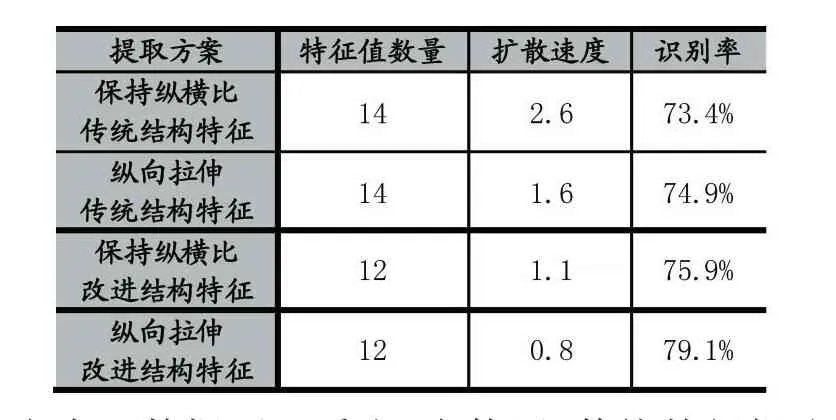
表1 4种提取方案识别率对比
由表1数据可以看出,在使用“传统特征提取法”时,改变字符放大方法不能显著使识别率得到提升;对于“改进特征提取法”,无论使用哪种字符放大方法,其识别率都比“传统特征提取法”有较明显提升;另外还可看出,在使用“改进特征提取法”时,配合单方面纵向拉伸的字符放大法,可以使识别率得到较明显的提升。
2.2 特征提取数量和位置的选取
在使用“单方面纵向拉伸法”和“改进特征提取法”的方案中,为了进一步测试得到更优的特征值数量和选取位置,本节使用MNIST数据库中1/10的样本数量,不断调整结构特征和统计特征的数量和选取位置,另外再将统计特征从计算区域内白像素个数之和的0.1倍调整为0.05倍,分别计算出每种不同选取方案下的最佳扩散速度和识别率,本节实验数据如表2所示。
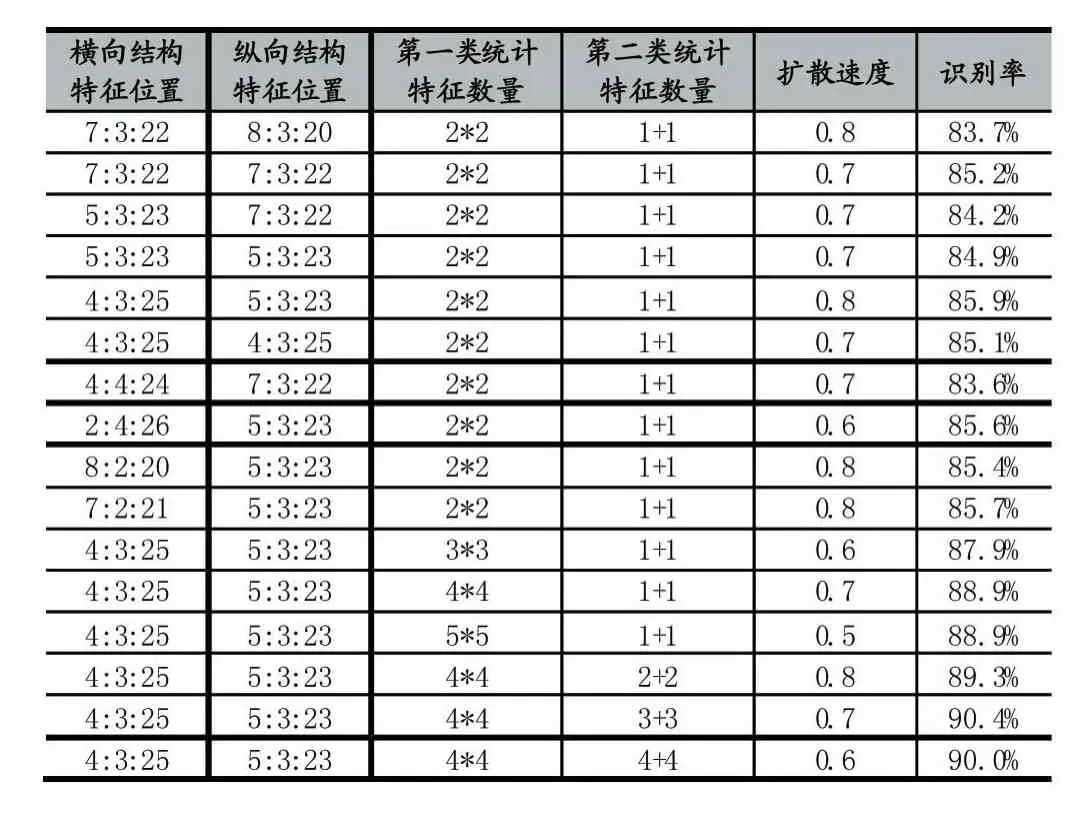
表2 不同特征值数量和位置选取识别率对比
由表2数据可知,针对于MNIST数据库的前1/10样本,横向结构特征位置选取[4 7 10 13 16 19 22 25]行较佳,纵向结构特征位置选取[5 8 11 14 17 20 23]列较佳,共15个结构特征值。第一类统计特征选取4*4个,每个大小为7×7像素,依次铺满整个28×28像素区域,每个7×7的小区域都不重叠。第二类统计特征选取3+3个,前3个大小为9×28像素,平均分布在第4到25行中,后三个大小为28×9像素,平均分布在第5到23列中,此6个统计特征选取位置互相有重叠。以上选取位置的示意图如图9所示。
2.3 三种选取方案对比
由于上述所有实验均是使用MNIST数据库的1/10样本,对于概率神经网络的训练并没有达到最佳效果,为了得到更为可靠的识别率,本节使用MNIST数据库中的全部样本来做训练与测试,并记录总体识别率和针对于每个数字的识别率[9]。共进行3次实验,分别是使用“保持纵横比放大法”和“传统特征提取法”,提取8个结构特征值和6个统计特征值,记为“方法一”;使用“单方面纵向拉伸法”和“改进特征提取法”,提取6个结构特征值和6个统计特征值,记为“方法二”;使用“单方面纵向拉伸法”和“改进特征提取法”,并且采用2.2节中得到的特征值数量和选取位置,提取15个结构特征值和22个统计特征值,记为“方法三”。分别计算出三种方法的最佳扩散速度,比较三种方法的识别率,如表3所示。

图9 特征选取位置示意
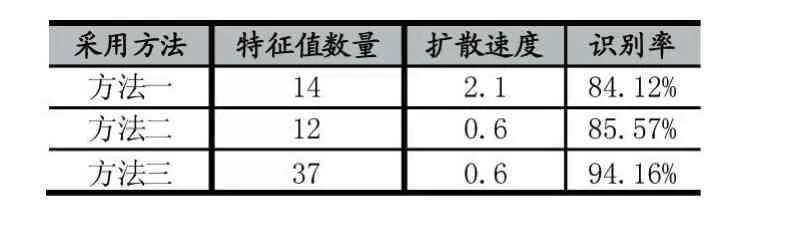
表3 全样本识别率对比
由于“方法三”的识别率在三种方法中最高,故只详细记录“方法三”的单个数字识别率,并标出MNIST数据库中该字符在测试集中的数量,如表4所示。
由表4数据可以看出,对于字符“5”和字符“3”的识别率较低,原因之一是在MNIST数据库中这两个字符由不同人所书写时差异很大,有些甚至连人眼也无法识别,而由于字符“1”的结构特征较明显,所以对该字符的识别率最高。
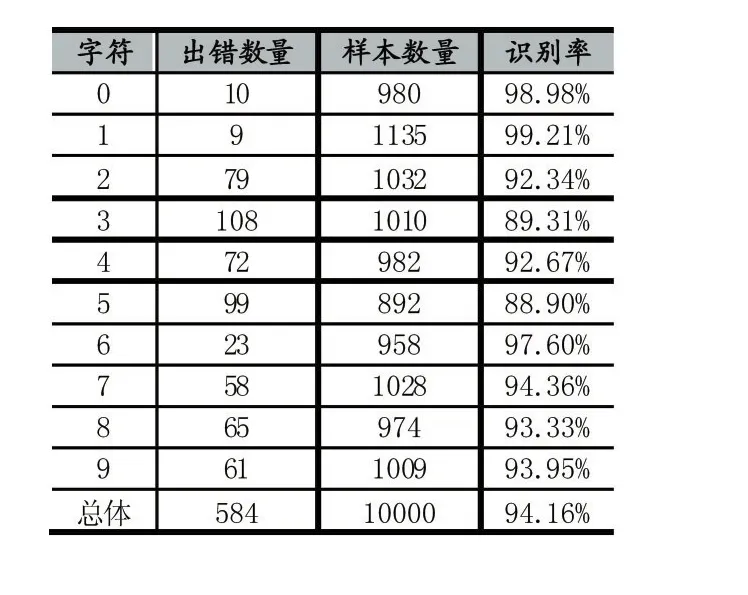
表4 单个字符识别率
3 算法评价
本文所提出的结构特征改进算法,相较于传统算法可以使识别率得到提升,而单方向纵向拉伸的字符放大法仅在搭配本文提供的改进方法时才可起到明显作用。该算法思想还可推广使用到英文字母等其他字符识别的结构特征提取环节中,相较于传统结构特征提取方法来说具有一定优势。
对该提取方案分别添加椒盐噪声和高斯噪声进行噪声测试[10],经实验,得出数据,表明不论添加哪种噪声,都会使识别率有所降低,说明该方法对噪声的规避能力稍有不足。所以如果图像有噪声干扰,需在预处理阶段提前对噪声进行有效清除,才能更好地利用该特征提取方案。
[1]王亚威.手写体数字识别系统的设计与实现[D].河北科技大学,2015.
[2]陈军胜.组合结构特征的自由手写体数字识别算法研究[J].计算机工程与应用,2013,49(5):179-184.
[3]任美丽,孟亮.基于原型生成技术的手写体数字识别[J].计算机工程与设计,2015(8):2211-2216.
[4]方向,陈思佳,贾颖.基于概率测度支持向量机的静态手写数字识别方法[J].微电子学与计算机,2015(4):107-110.
[5]陈明.MATLAB神经网络原理与实例精解[M].北京:清华大学出版社,2013.
[6]宋昌统,黄力明,王辉.基于概率神经网络的手写体数字识别[J].微型电脑应用,2016,32(10):14-15.
[7]Parberry I.Probabilistic Neural Networks[J].Neural Networks,1994,3(1):109-118.
[8]C Dan,U Meier.Multi-Column Deep Neural Networks for Offline Handwritten Chinese Character Classification[J].International Joint Conference on Neural Networks,2015:1-6.
[9]XY Zhang,Y Bengio,CL Liu.Online and Offline Handwritten Chinese Character Recognition:A Comprehensive Study and New Benchmark[J].Pattern Recognition,2016,61(61):348-360.
[10]Wang Liang,Leckie C,KotagiriR,eta1.Approximate Pair-wise Clustering for Large Data Sets Via Sampling Plus Extension[J].Pattern Recognition,2011,44(2):222-235 .
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
汉字汉语研究(2020年2期)2020-08-13
烟台大学学报(自然科学与工程版)(2020年1期)2020-02-08
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
中国高新技术企业(2017年5期)2017-05-05
课程教育研究·新教师教学(2016年18期)2017-04-12
软件(2016年6期)2017-02-06
