
基于PCA和改进的KNN算法的船舶尾气识别算法
2018-08-02 07:23:32孙逸安博文朱昌明
现代计算机 2018年15期
孙逸,安博文,朱昌明
(上海海事大学信息工程学院,上海 201306)
0 引言
随着全世界物流的快速发展,我国的航运物流业也得到了迅速发展,繁忙的航运物流带来了大量的空气污染。在我国港口船舶码头,船舶尾气排放污染愈加严重,而大型港口大多集中在人口密集的发达城市和沿江城市,如长江三角洲,长江沿岸重庆和武汉等地区和城市。船舶排放的废气笼罩港口城市对人类带来巨大危害,加大航运污染治理刻不容缓[1]。近年来,虽然我国的海事局危管防污处、船舶安全检查处和各办事处加强了现场执法过程中的对燃油质量、供受油单证、记录文书等控制区相关要求内容的检查,并视情况进行燃油取样。但是,抽取燃油样品后送交第三方检验部门进行化验分析,以油样的相关指标参数(主要是SO2和NOx的浓度)作为船舶是否排放超标的依据,获得检查结果一般需要两天以上,检查目标比较随机,针对性不强,效率相对较低。所以海事执法部门为了快速检测油品,从船舶尾气作为切入点,采用搭载气体传感器的无人机检测船舶尾气中的硫化物和氮化物的浓度。因此,气体传感器对检测气体的准确率和速率尤为的重要。近靠单一的气体传感器对船舶尾气中含有的多种混合气体的选择性的效果是十分差的,为了解决这个困难,采用多传感器对气体信息进行模式识别处理,以此提高对船舶尾气中的污染气体的识别的准确性。
目前,用于气体的模式识别有很多种。主要有聚类分析法[2](Cluster Analysis,CA)、判别分析法[3](Dis⁃criminant Analysis,DA)、最 近领 域 法[3](K-Nearest Neighbour,KNN)以及人工神经网络[5]算法等。其最终的目标都是通过信息的处理来更加准确的对气体进行分类。但是通常传感器检测的数据纬度很高,数据量又很大。普通的KNN算法计算量很大,人工神经网络计算时间又很长,无法兼顾高效率和准确率。通过理论研究,本文提出利用主成分分析法(Principal Compo⁃nent Analysis,PAC)可以对气体数据先进行降维,然后对降维后的气体数据再进行C-均值聚类[4],减少训练样本的存储空间,再采用传统的KNN算法将待检测的船舶尾气进行识别。通过实验验证发现,该算法对船舶尾气的分类具有很好的准确性的同时,减少了算法的计算时间,提高了船舶尾气识别工作效率。
1 算法理论
1.1 KNN算法
KNN算法是基于统计的分类算法[7]。在气体传感器中也有广泛的应用。KNN算法基本思想:在样本中分为两类,其中一类为训练样本,另一类为测试样本。计算未知气体样本与已知气体样本之间的距离,得到K个近邻,根据已知气体样本所属的类别来判断测试气体样本所属的类别。产生两种结果:(1)K个近邻属于已经分类号的某个气体,那么待分类的气体属于那个气体类别[8];(2)气体分类结果属于多个气体类别,那么以K个近邻中占多数的气体类别作为带分类气体的类别,即少数服从多数原则。
对于船舶尾气中的SO2和NOx分类问题,使用KNN算法分类可分为以下几个步骤:
(1)带标签类别的样本训练集可以表示为:其中m表示属于m维空间,样本标签Yj∈{+1,-1}。对于无标签类别的未知气体样本可以表示为:
(2)一般参数设置为K,可根据试验结果反复调整至最优K值。
(3)计算训练气体样本和测试气体样本的距离,对于实际船舶尾气问题,可以采用欧氏距离,公式如下:
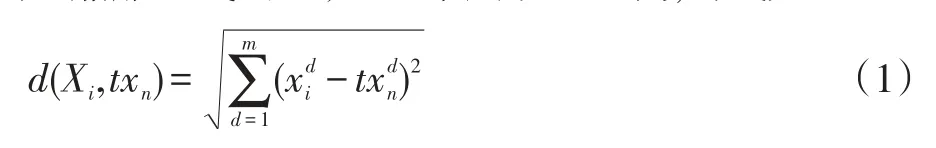
其中分别表示已知气体训练样本和未知气体样本的第d个属性值。
(4)计算训练气体样本与每个测试气体样本的欧氏距离dist,并计算得到K最近邻的最大距离maxdist。比较dist与maxdist大小,如果小于最大距离,则被判为K最近邻的类别。
(5)重复迭代,计算所有待测试气体样本。
(6)根据K个近邻的类别以及少数服从多数的原则,从未知气体样本txn中选择数量最多所在的类别作为测试气体所属类别。
KNN算法作为一种有监督的经典分类算法,理论成熟,较容易理解,在船舶尾气分类上有很好的效果和应用,且时间复杂度为O(n)。但KNN算法也有其缺点:当样本数量过大或者是分类高维度数据时,需要进行繁重的的距离计算量,相应的硬件内存需求变高,计算时间也变长,效率会变得很低下。
1.2 PCA 算法
主成分分析法(PCA)是一种最常用的数据降维算法[9]。主要对高维数据进行的加工处理、压缩,减少了原本复杂的数据的特征度,减少了原本数据中的噪音数据,提高了数据的信噪比,同时还减少过度拟合的可能性。其基本思想:将原本的数组进行重新组合,通过正交变换,将N维特征映射到M维上(N<M),产生全新的N维特征。这N维特征就是主成分。主成分之间是互补相关的,且是原始变量的线性组合[10]。
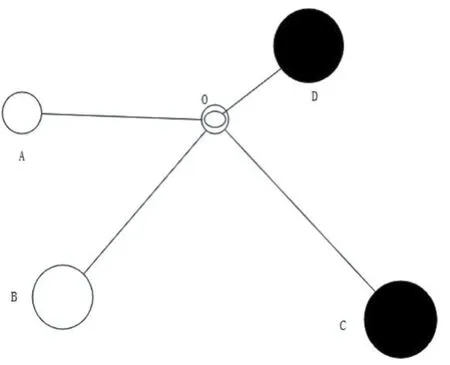
图1 待测样本O的最近邻
主成分分析法的计算步骤如下:
(1)获取样本特征矩阵X:

将式(2)转换为线性组合:
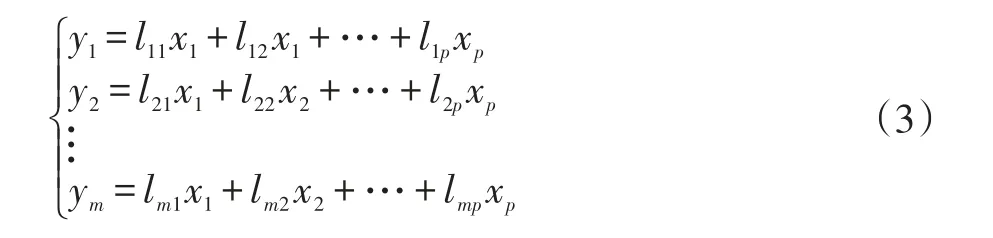
其中y1,y2,…,ym(m<p)是按从大到小线性变换后的互不相关的数值,且因此y1,y2,…,ym表示X中的主成分,lmp为主成分系数。
为了保持量纲一致性,可以采用式(3)原始化采集样本。

其中i表示第i个数据,E(Xi)表示样本的均值,D(Xi)表示样本的方差。
(2)计算Xi的协方差矩阵S。
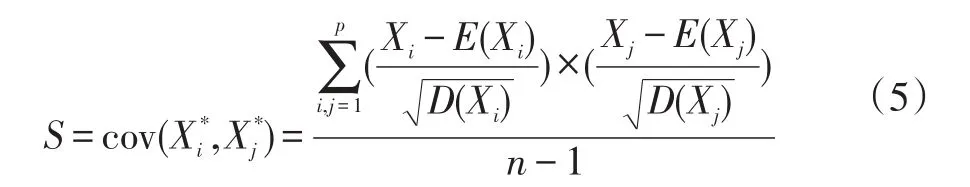
其相关系数矩阵R可表示为:

(3)计算R的特征值λ和特征向量e。
由特征方程(7)计算得到特征值λi(1,2,…p)。将特征值从大道小的顺利排列,将特征值代入(8)中,求解得到特征向量 ai(1,2,…p),将其单位化为 ei(1,2,…p)。

(4)选择主成分。
通过计算累计贡献率G(m)确定:

一般认为当G(m)大于85%时,就可以认为这M个主成分代替了原始样本的信息内容和结构[11]。
(5)得出主成分荷载

代入式(3)中,得到主成分Y=(y1,y2,…,ym)T。
1.3 基于PCA的KNN 算法改进
通过采用PCA算法对训练样本的数据降维,提高了样本数据的可计算性,减少了计算时间。但是样本数目巨大,传统的KNN算法需要大量的存储空间对训练样本进行存储,而且测试样本需要与每一个训练样本进行计算距离,通过排序找到前K个最近邻。本文针对传统KNN算法的不足,对进行过PCA降维的数据用C均值聚类算法(C-means),C均值聚类算法也被称为K-均值聚类方法[12]。C均值聚类算法的核心思想是,通过迭代寻找C个聚类的一种分类方案,用这C个聚类的均值来代表相应的各类样本,使样本的总体误差达到最小[13]。在大数据样本的情况下,就不用对所有气体样本都进行繁重的距离计算,缩短了计算量和减少了计算时间。
C均值聚类算法的基础是最小误差平方和准则[14]。如果Qi是第i个聚类Γi中的样本数量,得下式,

把Γi中的每个样本y和均值mi间的误差平方和与全部气体训练样本的类累加后,得到:

其中Je是误差平方和,Y是气体训练样本集,mi是样本的均值。
这里有一个把样本y划分到Γk中的聚类例子,以下是C均值聚类算法的步骤。
(1)开始可以把训练样本集Y划分为c个聚类,Γi,i=1,2,…c,代入式(11)和式(12)中。计算得到mi,i=1,2,…c和 Je;
(2)从训练样本集Y中任意取一样本 y,假设 y∈Γi;
(3)如果Qi=1则重新进行步骤(2),否则就进行下一步;
(4)计算 ρj
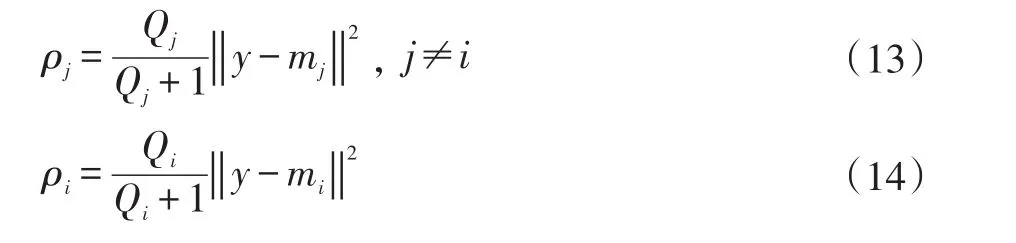
(5)计算得到样本中 ρmin,如果 ρmin<ρi,则将样本y从Γi合并到Γk中;
(6)重复计算 mi,i=1,2,…c和 Je直到 Je不在改变,就对训练样本完成了分类。
这里C均值聚类算法中的聚类数目C由(Je-C曲线)得到。图1给出了一个Je-C曲线的例子。曲线的拐点处对应的聚类数目C一般就是最优值[15]。
2 实验仿真
2.1 实验流程
对获得的训练样本数据预处理,然后进行PCA处理,然后将训练样本做C均值的聚类算法,减少训练样本所占用的空间。同样对测试样本进行数据预处理,进行PCA降维处理,在本文设计的分类器中将训练样本划分到气体所属类别。气体识别算法流程如图2所示。
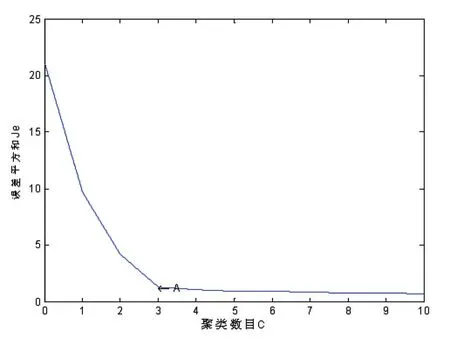
图2 确定聚类数目的Je-C曲线
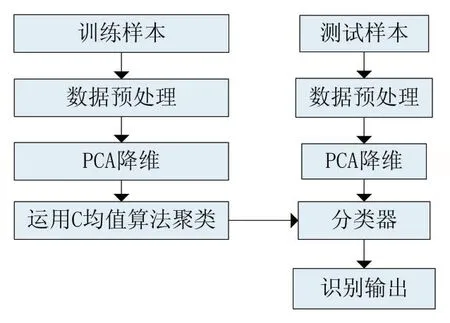
图3 气体识别流程
2.2 实验环境
实验平台:Intel Core i7 4470四核八线程;主频3.4GHz处理器;16GB内存;在软件MATLAB R2014a下进行仿真实验。
2.3 实验数据
实验中将气体传感阵列输出的稳态值作为气体的特征值,每进行一次气体采样都可以得到一个1×30的向量,对SO2和NOx两类气体进行重复采样,避免出现单次测量不准的情况。经过200次采样可以组成200×30的训练样本矩阵。同样进行1500次采样组成1500×30的测试样本矩阵。分别如式(15)和式(16)所示。

其中n等于200,m等于1500,维度 p等于30。
2.4 实验结果分析
在实验过程中,本文采用传统的KNN算法,经过PCA处理的KNN算法(简称PCA-KNN算法)以及经过PCA处理C均值聚类的KNN算法(PCA-CKNN算法)这三种不同的算法在不同维度下的分类时间,分类准确性进行比较。结果如表1和图所示。

表1 KNN,PCA-KNN与PCA-CKNN算法的分类时间
从三种不同的算法中发现本文提出的PCA-CKNN算法在分类时间上占明显的优势。
评价分类的性能指标还有准确率[16]:

结果如图4所示。
根据图4可以得到传统KNN算法的识别率最好,其他两种算法分类结果稍差些。
通过表1和图4综合分析可以得出,虽然在准确率上文本提出的PCA-CKNN算法不如传统的KNN算法,但是只相差1%值2%左右,但是分类速度提高了大约10倍左右。虽然PCA-KNN算法分类效果稍微好于PCA-CKNN,但是分类速度慢了一半不止。通过上述的实验可以得到一个结论:基于主成分分析和C均值聚类的改进K-近邻算法能够在保证识别船舶尾气准确的基础上,缩短了算法分类气体的时间。
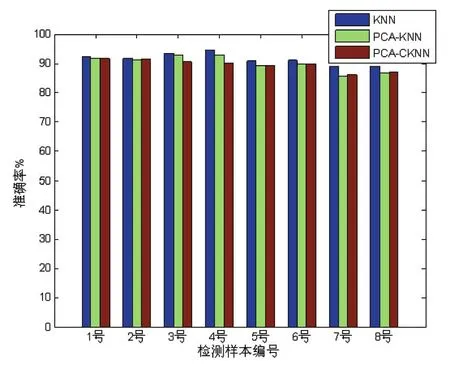
图4 三种算法准确率对比
3 结语
在海事执法部门采用搭载气体传感器的无人机检测船舶尾气对SO2和NOx进行识别,利用K近邻的分类思想,针对算法中计算量大、样本数较多,样本数据维度高等会使分类产生误判的情况,提出基于PCA降维和C均值聚类的KNN算法。最后对算法进行了实验验证,并与传统的KNN算法和只进行PCA降维的KNN算法进行了比较分析,本文所提出的算法在保证气体分类的准确性上,还缩短了分类的时间。研究表明,本文的算法在船舶尾气识别中比传统的KNN算法更加适用。但本文提出的算法也仍有一些可以改进的地方,如果聚类的效果提高,那么分类的准确率可以再提高,甚至超过传统的KNN算法。
[1]冯璐.王厚启船舶治污瓶颈待破除[N].中国水运报,2015.
[2]鹿文静.基于OTG协议的气体数据采集与识别算法的研究[D].上海应用技术大学,2016.
[3]尹洪涛,付平,沙学军.基于DCT和线性判别分析的人脸识别[J].电子学报,2009,37(10):2211-2214.
[4]Subhash Ajmani†,Kamalakar Jadhav A,Kulkarni S A.Three-Dimensional QSAR Using the k-Nearest Neighbor Method and Its Interpretation[J].Journal of Chemical Information&Modeling,2006,46(1):24.
[5]Subirats J L,Franco L,Jerez J M.C-Mantec:a Novel Constructive Neural Network Algorithm Incorporating Competition Between Neurons[J].Neural Networks,2012,26(2):130-140.
[6]关庆,邓赵红,王士同.改进的模糊C-均值聚类算法[J].计算机工程与应用,2011,47(10):27-29.
[7]王增民,王开珏.基于熵权的K最临近算法改进[J].计算机工程与应用,2009,45(30):129-131.
[8]陈佩.主成分分析法研究及其在特征提取中的应用[D].陕西师范大学,2014.
[9]史淼,刘锋.基于PCA和kNN混合算法的文本分类方法[J].电脑知识与技术,2015(4):169-171.
[10]李容.协同过滤推荐系统中稀疏性数据的算法研究[D].电子科技大学,2016.
[11]荀烨,龙绵伟,陈民.基于主成分分析法的军事物流基地中心仓库遴选[J].军事交通学院学报,2015,17(1):61-65.
[12]贾瑷玮.基于划分的聚类算法研究综述[J].电子设计工程,2014(23):38-41.
[13]柯尊海,刘勇,徐义春,等.基于改进K均值的运动目标检测算法研究[J].三峡大学学报(自然科学版),2012,34(6):98-102.
[14]王超,姜威.基于K近邻加权的混合C均值聚类算法[J].计算机工程与应用,2006,42(30):84-87.
[15]许崝,施泽生,蔡洪滨,等.一种基于多模板匹配的在线手写签名认证方法[J].计算机应用,2004,24(s1):165-167.
[16]刘龙海.基于成对约束的半监督文本聚类算法研究[D].重庆大学,2011.
猜你喜欢
科技创新与应用(2020年6期)2020-02-29 10:39:27
消费导刊(2018年10期)2018-08-20 02:56:30
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
新校长(2016年8期)2016-01-10 06:43:59
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:28
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
压缩机技术(2014年3期)2014-02-28 21:28:11
