
基于潜在兴趣和地理因素的个性化兴趣点推荐研究
2018-08-02 07:23王亚男
现代计算机 2018年15期
王亚男
(重庆大学计算机学院,重庆 400030)
0 引言
近年来,随着定位技术的民用化,基于位置的社交网络服务迅速发展,兴趣点呈爆炸式增长,所以一个旨在帮助用户过滤兴趣点,减少其抉择时间的推荐系统成为了迫切需要的服务。目前存在很多关于兴趣点推荐的研究。举个例子,Zheng等[1]首次运用基于用户的协同过滤方法进行兴趣点推荐。Hu等[2]对包含签到兴趣点和未签到兴趣点两类数据的矩阵进行矩阵分解。Cheng等人[3]把用户在位置上的签到概率模型模拟为多中心高斯模型来捕获地理因素,继而把社交信息和地理信息融入到一个广义的矩阵分解模型中。Ye等人[4]综合基于用户的协同过滤、基于好友的协同过滤和基于地理信息的推荐方法提出混合协同过滤算法,大大提高了推荐精度。
目前存在的关于兴趣点的推荐(如Ye[4]、Cheng[5]、Gao[6])几乎全部采用传统的基于内存或基于模型的协同过滤技术。但是,由于用户数据的稀疏性,这些技术都遭受严重的冷启动问题。
为了应对兴趣点推荐中的冷启动,本文对现存的兴趣点推荐算法进行研究,发现用户的签到行为在很大程度上受到相关用户的影响。例如,Gao等[7]表示社交好友、签到行为相似的用户均会影响用户的签到行为;Li等[8]对Foursquare中的数据进行了分析,发现“两个用户的活动中心越接近,签到兴趣点重合度越高,即和用户在地理位置上相近的用户(例如邻居)的行为会影响到用户的签到行为。因此,本文提出了一个能够利用相关用户的推荐框架,关于相关用户会在下文给出详细的定义。
1 相关用户
给定用户i,为该用户定义了三类相关用户:地理相关用户、社交相关用户、签到相似相关用户。
定义1(地理相关用户):根据用户i的历史签到数据,计算出用户i的“活动中心”,地理相关用户是和用户i的“活动中心”距离最小的f个用户,表示为 f(Fig),关于用户的“活动中心”,在用户历史数据集上应用聚类算法来获得。需要注意的是,在应用聚类算法之前,需要去掉那些明显偏离的兴趣点。
定义2(社交相关用户):用户i的社交相关用户是数据集中直接给出的,表示为
定义3(签到行为相似的相关用户):计算用户i和其余用户的签到相似度,在计算用户签到相似度时把时间因素融合到算法中,签到行为相似相关用户是f个和目标用户i签到相似度(合并时间因素)最高的用户,表示为在下文中,将会给出如何把时间因素融入到相似度的计算中。
2 PC-Geo推荐模型
2.1 相关用户建模
用户的签到行为容易受到相关联用户的影响,本文为每个用户选取了三类相关用户,并使用这些相关用户来学习目标用户的潜在兴趣。前面已经获得了社交相关用户和地理相关用户,现在还需获得签到相似(合并时间因素)相关用户。
时间因素在兴趣点推荐中起着重要的作用,因为用户倾向于在一天的不同时段访问不同的兴趣点。例如,用户习惯上午9点左右去上班,中午11点吃午饭,晚上十点左右和朋友去酒吧,人类的签到活动表现出了明显的时间性。因此,在计算签到相似度时把时间作为一个影响因素考虑进去能更好地了解人类的移动行为,设计精确度更高的推荐系统。
为了证明时间因素确实会影响用户的签到行为,实验时,从Foursquare中随机选择多个用户,对其签到行为随时间的变化进行了统计分析,图1显示了其中一个用户的签到频率随时间的变化,从图中可以看出,该用户发生的大部分签到行为集中在少数的时间段内,很多时段基本没有签到行为,其余的用户也呈现类似的趋势。因此,用户的签到行为呈现出很明显的时间模式。
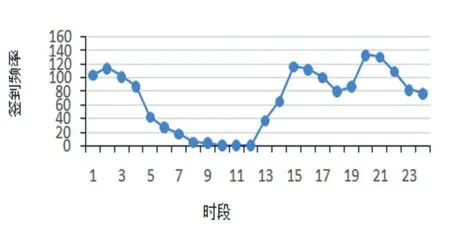
图1 签到频率在每个时间状态上的分布
从上面的分析来看,时间因素确实是影响用户签到行为的一个重要因素,因此,本文在考虑用户签到的相似度的时候增加了时间因素,采用把时间离散化的手段进行研究。首先,把一天分为多个离散时间段,定义为T。然后,把原始的用户-兴趣点矩阵按照签到时间分成24个时段-用户-兴趣点矩阵。基于时段-用户-兴趣点矩阵,两个用户基于时间的相似性表示为:
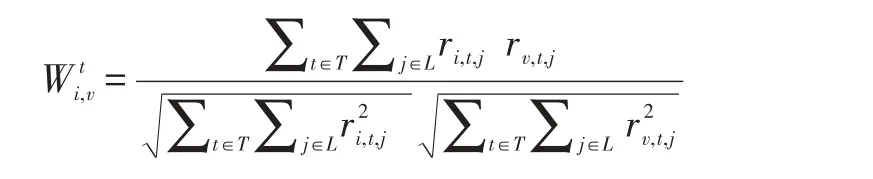
然而,原始的用户-兴趣点矩阵就是一个稀疏矩阵,经过时间处理之后得到的时段-用户-兴趣点矩阵更加稀疏。因此,不能直接使用时段-用户-兴趣点矩阵去计算两个用户之间的相似度。可以先利用Yuan等[9]中的方式对矩阵平移,然后在进行相似度的计算。平移过程如下所示:
给定目标用户i,用户i在t∈T的签到向量为:ri,t={ri,t,1,..ri,t,L}。计算该用户在任意两个时段的签到向量的相似性,取数据集中所有用户在这两个时段的相似值的平均值作为这两个时段相似度,表示如下:
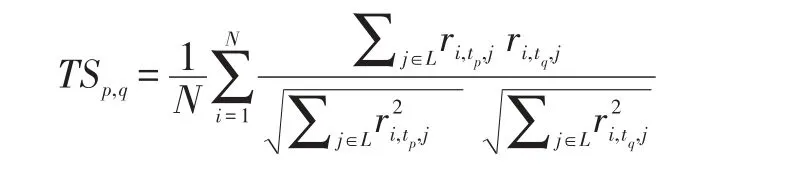
利用时段签到相似矩阵TS来对时间-用户-兴趣点矩阵进行平移,具体平移公式如下:
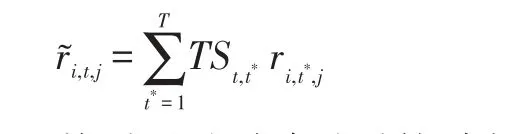
然后通过平移过后的时段-用户-兴趣点矩阵就可以进行用户签到相似度的计算了。
最后,把f个签到相似相关用户和f个地理相关用户和社交相关用户求并集作为目标用户的相关用户。
2.2 地理信息建模
不同于传统的非空间物品的推荐,在LBSN中,每个兴趣点都有独特的地理位置,用户在在消费产品或者享受服务的同时需要和兴趣点有位置上的交互,地理因素是影响用户签到行为的一个重要的内容。
现存的兴趣点推荐的研究中,设计到基于地理信息的兴趣点推荐大多只是简单地利用用户的历史位置和待访问的兴趣点之间在距离上呈现的反比关系进行推荐,或者将同一用户签到过的任意两个兴趣点间的距离视为幂率分布或多中心的高斯分布进行推荐。但这些方法均存在很多局限。首先,用户访问兴趣点的概率不是距离上的单调,因为访问的概率不仅受距离的影响还受位置固有属性的影响。其次,每个用户的签到行为是独特的,采用通用的分布函数不能体现用户的个性化特征。本文采用核密度估计捕获地理模型,通过该算法可以为每个用户学习到独特的概率密度函数,体现出用户的个性化。
采用核密度估计捕获地理模型方法简述如下:首先,对于目标用户i,其历史签到数据表示为Li={l1,l2,……ln}。用户i对兴趣点j的偏好度表示为Wi={w1,w2,……wn}。兴趣点的位置表示为lj:(xj,yj)。论文使用高斯分布作为核密度估计中的中心函数,最终本文的核密估计函数如下:
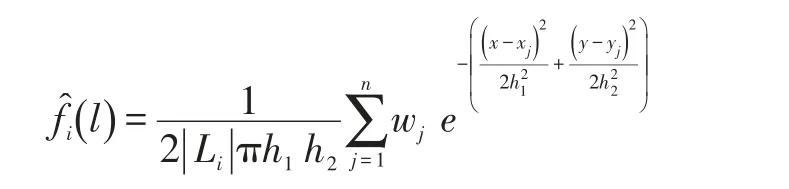
其中,h1,h2是固定带宽,h是根据用户i的历史签到数据的标准差σ得到的。
但是,只有固定的带宽并不能反映这样一个事实:密集的城市地区有较高的签到密度,人口稀少的农村地区将会有较低的签到密度,所以可以增加一个可调节的局部带宽,这个局部带宽hj的计算方式如下:

其中,α∈[0,1]是一个灵敏度参数,g是几何平均数,因此,最终的核密度公式如下:
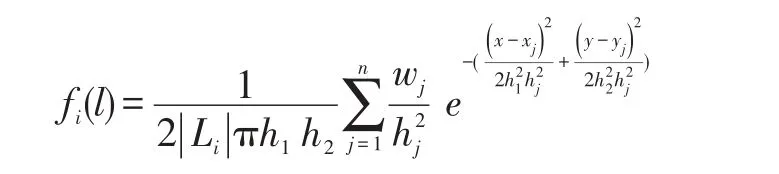
至此,完成了通过核密度估计算法为每个用户学习到独特的概率密度函数,通过学习到的概率密度函数,可以捕捉地理信息对于用户签到的影响。
2.3 用户的潜在兴趣选择策略
在获得用户的相关用户之后,把相关用户签到过但用户并未签到过的部分兴趣点作为用户的潜在兴趣。但是由于待选择的兴趣点太多,本文采用线性合并用户兴趣和地理因素的算法去衡量用户对兴趣点的偏好:
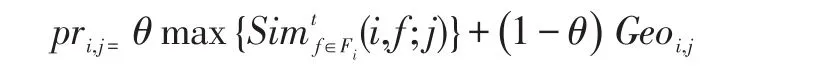
θ是控制用户偏好和地理因素比例的调和参数。是用户i和其相关用户就兴趣点j偏好的相似性。Geoi,j是地理对用户签到行为的影响,使用fi(l)进行计算。最终,选择s个 pri,j值最大的兴趣点作为用户i的潜在兴趣点。
2.4 矩阵分解和地理因素的融合
矩阵分解是一种在推荐算法中被广泛使用的技术,不同于原始的矩阵分解,本文需要先把用户潜在兴趣点合并到用户-兴趣点矩阵中,缓解矩阵的稀疏性之后,在通过矩阵分解技术[10]构建推荐模型。对于每个用户i,把兴趣点分为三类:Li是用户签到过的兴趣点集合。Pi是用户潜在兴趣点集合。Ui是用户没有签到过且非潜在兴趣点的集合,新的用户-兴趣点矩阵和权重矩阵如下所示:
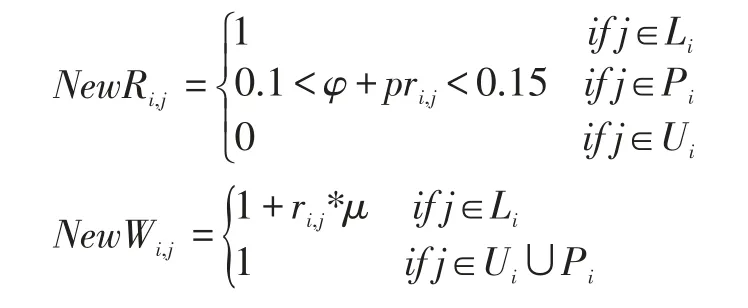
φ,μ∈[0,1]都属于调节参数。φ+pri,j是潜在兴趣点的概率,设置的过小,和未签到兴趣点的区别就不明显了,设置的过大,会造成噪声,所以设置它的值在0.1到0.15之间。最后本文的矩阵分解模型如下:
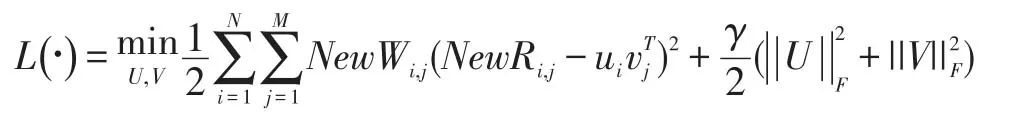
为了最小化损失函数,并且保证比快速收敛,本文采用随机梯度下降算法,算法如表1所示:

表1 梯度下降算法
最后,本文合并地理因素对用户签到影响到矩阵分解中,获得推荐模型如下所示:
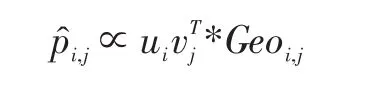
3 实验设计
3.1 数据集

表2 Foursquare数据集统计信息
本文采用真实的数据集Foursquare,该数据集共包含两个文件,一个是关于用户的社交关系,表示为:〈用户ID,好友用户ID〉;一个是用户的签到日志表示为:〈签到序号,用户ID,签到时间戳,兴趣点ID(经度,纬度,区域),主题〉。数据集中所有的兴趣点都在加利福尼亚范围内,表2给出了数据集的详细信息。
从表2可以看到,用户-兴趣点矩阵的签到稀疏度为5.34×10-4,是一个非常低的值。该矩阵的稀疏导致大多数主流的兴趣点推荐算法的精度普遍不高。所以,基于比较低的用户-兴趣点矩阵密度,最终得到普遍偏低的预测准确率和召回率是合理的。
本文从签到记录中随机抽取80%作为训练集,训练隐兴趣矩阵U和V,利用剩余的20%作测试集来验证PC-Geo模型的推荐性能。为了提高实验的可靠性,实验采取交叉验证的策略。
3.2 评价标准
本文采用推荐系统中常使用的评价标准准确率和召回率作为评价指标,具定义如下:
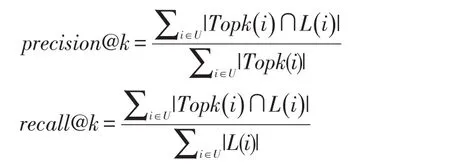
其中,L(i)表示用户签到过的位置集合,Topk(i)表示向用户推荐的位置集合。实验中,k值设置为5,10。隐式空间的维度设置为10,相关用户的个数f设置为10,用户潜在兴趣点s设置为300,重构矩阵的调节参数φ为0.1μ为0.3。在梯度下降中,学习速率设置为0.002,用户和兴趣点的权重设置为相同的0.02。
3.3 不同推荐算法的对比
本文选定三个优秀的推荐算法进行对比。
BaseMF:对原始的用户-兴趣点矩阵进行矩阵分解[11]。DRW:基于动态随机游走模型,融合用户社会关系、类别信息和流行度信息进行推荐[12]。LRT:把用户签到的时序模式合并到矩阵分解中进行推荐[6]。
3.4 实验结果
图2表示模型PC-Geo与上述三种推荐模型在准确率和召回率的对比结果。
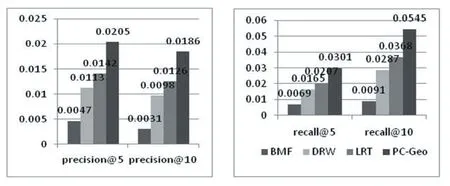
图2 PC-Geo和其他推荐算法对比
BMF:这种方法已经被广泛的应用在推荐系统中了,通常会通过最小化目标函数来获得局部最优解。然而,由于用户签到矩阵的稀疏性,这种直接矩阵分解的方法会导致最后的推荐精度很低。
DRW:这种方法采用动态的随机游走模型,融合了用户的社交关系、相关类别信息以及流行度信息,但是,该方法没有考虑地理位置因素对于用户签到行为的影响。因此,它最终体现出较差的推荐效果。
LRT:这种方法引入了用户签到行为的两个时间特性:1非统一性,即用户在一天内的不同时间段展现出不同的签到偏好;2连续性,即用户在一天内连续时间段上的签到偏好比非连续时间段上的偏好更加相似。LRT是在矩阵分解的基础上加入了用户社会行为的时模式,在模型中反映出签到偏好随时间状态的迁移。但是,这种方法仅仅考虑了时间因素对用户签到行为的影响,并没有考虑到其他的情景因素(地理,社交)用户签到行为的影响,因此,它的推荐精度也较差。
PC-Geo:该模型在精度和召回率上都取得了最好效果,原因总结如下:
(1)充分利用相关用户会对用户的签到行为产生影响这一事实,利用相关用户学习目标用户的潜在兴趣,这能在一定程度上缓解冷启动问题。
(2)使用核密度估计方法捕获地理因素对用户签到行为的影响,为每个用户获得独特的密度函数。
(3)一个额外的优势是容易把时间因素融入到推荐模型中,用户的签到行为具有时间模式,因此融入时间因素,也可以在一定程度上提高推荐模型的质量。
图3展示了PC模型(只合并了潜在兴趣到用户-兴趣点矩阵中,并没有合并最后的地理因素对用户签到行为的影响)和PC-Geo模型准确率和召回率的对比。结果表示在基于社交网络的兴趣点推荐中考虑地理因素对用户签到行为的影响是必要的。
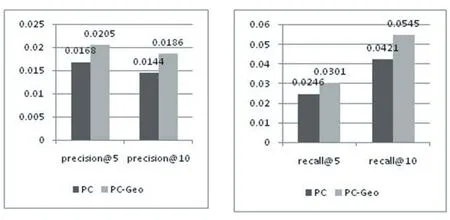
图3 PC-Geo和PC的对比
3 结语
本文提出了一个对于兴趣点的推荐框架:首先,使用情境信息(空间信息、时间信息、社交信息)来为目标用户定义相关用户;其次,设计一个结合用户兴趣和地理信息的算法,利用相关用户的历史签到数据,使用该算法学习目标用户的潜在兴趣,缓解签到矩阵的稀疏性。接着,把地理信息和矩阵分解的结果融合,最后完成对用户的推荐。在未来的工作中,希望能把用户的评论添加到框架中,以提高推荐效率。
[1]Zheng Y,Zhang L,Ma Z,et al.Recommending Friends and Locations Based on Individual Location History[J].ACM Transactions on the Web,2011,5(1):5.
[2]Hu Y,Koren Y,Volinsky C.Collaborative Filtering for Implicit Feedback Datasets[C].Eighth IEEE International Conference on Data Mining.IEEE,2009:263-272.
[3]Cheng C,Yang H,King I,et al.Fused Matrix Factorization with Geographical and Social Influence in Location-Based Social Networks[C].AAAI Conference on Artificial Intelligence,2012.
[4]Ye M,Yin P,Lee W C,et al.Exploiting Geographical Influence for Collaborative Point-of-Interest Recommendation[C].ACM,2011:325-334.
[5]Cheng C,Yang H,Lyu M R,et al.Where You Like to Go Next:Successive Point-of-Interest Recommendation[C].International Joint Conference on Artificial Intelligence.AAAI Press,2013.
[6]Gao H,Tang J,Hu X,et al.Exploring Temporal Effects for Location Recommendation on Location-based Social Networks[C].ACM Conference on Recommender Systems.ACM,2013:93-100.
[7]Gao H,Liu H.Data Analysis on Location-Based Social Networks[J].2014:165-194.
[8]Li H,Ge Y,Zhu H,et al.Point-of-Interest Recommendations:Learning Potential Check-ins from Friends[C].ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2016:975-984.
[9]Yuan Q,Cong G,Ma Z,et al.Time-aware Point-of-Interest Recommendation[C].International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,2013:363-372.
[10]Koren Y,Bell R,Volinsky C.Matrix Factorization Techniques for Recommender Systems[J].Computer,2009,42(8):30-37.
[11]Salakhutdinov R,Mnih A.Bayesian Probabilistic Matrix Factorization using Markov Chain Monte Carlo[C].International Conference on Machine Learning.ACM,2008:880-887.
[12]Ying J C,Kuo W N,Tseng V S,et al.Mining User Check-In Behavior with a Random Walk for Urban Point-of-Interest Recommendations[J].ACM Transactions on Intelligent Systems&Technology,2014,5(3):1-26.
猜你喜欢
中老年保健(2022年5期)2022-08-24
意林彩版(2022年2期)2022-05-03
今日农业(2021年17期)2021-11-26
好日子(2021年8期)2021-11-04
第一财经(2020年4期)2020-04-14
文苑(2018年17期)2018-11-09
读与写·教育教学版(2017年10期)2017-11-10
冰雪运动(2016年4期)2016-04-16
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
