
多视角判别分析的情感识别
2018-07-26 02:38赵文萍赵子平
信号处理 2018年8期
李 超 赵文萍 赵子平
(天津师范大学,天津 300387)
1 引言
随着计算机和信息技术的发展,具有识别人类情感能力的机器能够显著提高人机交互的用户体验,为人机交互提供一个平滑自然的接口[1]。早期的研究工作主要关注表情、语音、姿势、行为等外在生理指标的情感识别,也取得了令人振奋的成果[2-3]。但受社会面具等情况的影响,人们很容易通过表情、语音等掩饰自己的真实情感,因此,使用外在生理指标进行情感识别仍存在一定的限制。Rani等人[4]指出即使一个人没有通过语音、姿势或面部表情来表达自己内在的情绪,用户在情感表达过程中生理模式上的变化仍然不可避免地能够被检测到。自主神经系统活动的客观性决定了用户很难对其情感表达进行有意识的控制,生理反应能够较为真实和客观地反映用户内心的情感状态。同时,随着无线通信技术和可穿戴式设备的发展,只要用户佩戴可穿戴式设备,用户的生理信号就能够被连续的获取和分析,能够有效避免数据缺失对情感识别造成的影响。基于此,本文主要关注基于生理信号(脑电信号和外周生理信号)的情感识别。
人类在情感表达上是多种多样的,多模态信息的互补性表明各个模态都具有其他模态不具有的信息[5]。有研究表明,由于来自不同方面的情感数据的互补性和冗余性能够提高情感识别系统的鲁棒性。Scherer和Ellgring[6]结合表情、声音和姿势信息来判别14个情感种类。对于分别使用表情和声音的单一模态的情感识别准确率仅能达到52.2%和52.5%。而使用多模态信息融合的方法能取得79% 的情感识别准确率。但当选取多模态中10 个最具判别性的特征进行情感分类时,其准确率会下降到54%,这说明,由于单一模态的特征数与多模态的特征数不相等,相较于单一模态的情感识别,我们很难说明结合多模态信息的情感识别是否能带来系统的性能提升。Maaoui等人[7]研究了结合生理信号和表情信息融合的情感识别系统。该系统使用IAPS诱导10名被试在不同时间范围内的积极和消极情绪,并通过采集被试的脉搏、肌电、皮电、皮肤温度和呼吸等生理信号,结合被试的面部表情,利用特征级融合和决策级融合技术来估计个体的情感状态。实验结果显示,在单模态用户依赖模型下,基于表情的情感识别率可达到58.56%,基于生理信号的情感识别率可达到85.62%;而在双模态融合情况下,用户依赖模型能够取得86.80%的情感识别率。在用户独立模型下,特征级融合取得了70%的最高情感识别率。虽然特征级融合的多模态情感识别取得了一定的效果,但由于不同模态之间的情感信息存在着巨大的差异性,来自不同模态的样本数据可能位于完全不同的空间,若将其简单地直接匹配或连接进行情感识别,就不能保证情感识别的精度。
现实世界中,我们可以通过一个对象所展现出的不同视角来观察和分析同一对象。近年来,越来越多的研究者使用多视角的方法来解决各自领域内的研究课题。Kan[8]等人针对物体识别领域多视角学习存在的问题,通过联合学习多个视角的特定线性变换,找到具有判别性的多视角图像公共空间,在可见光图像与近红外图像人脸识别等方面取得了很好的效果。Cao[9]等人针对不同模态下多视角嵌入存在的非线性问题,通过使用图嵌入框架,提出了一个广义多视角嵌入方法,解决了多视角学习框架下非线性数据的分类问题,并在物体识别和跨模态图像检索方面取得了较好的识别效果。多视角学习的优势在于利用了不同视角数据表示下的一致性原则和互补性原则[10]。一致性主要体现在对同一研究对象的多个视角建立了本质性的联系,可以通过利用多视角之间对于表达上的一致性降低每个视角优化目标的搜索空间;而互补性主要体现在每个视角可能具有其他视角不具备的信息,通过多视角学习,就能够将各个视角的数据综合利用,形成对研究对象更为准确地描述和表达,从而提高学习性能。
基于此,本文通过情绪表达的不同视角来观察和分析人类的情感状态,提出使用基于多视角判别分析的情感识别。将每个模态信息看做情感表达的一个独立视角,通过利用情感标签的监督信息,最大化多个不同模态情感数据之间的一致性,抽取不同模态下最具有判别性的情感特征,将多模态情感样本投影到一个具有判别性的通用空间中,提高情感特征的判别性。
本文的主要贡献可总结为如下两点:1)由于各个模态的情感数据在空间中的分布不同,简单地将各个模态的情感特征连接为一个向量进行情感识别,并不能保证情感识别的准确性。本文使用的多视角判别分析方法,充分挖掘了各个模态对于情感识别的贡献度,抽取了情感表达的一致性和互补性信息。2)相较于无监督的多模态融合方法,多视角判别分析方法充分利用标签的监督信息,将多模态情感数据映射到情感判别的通用空间,使得映射后的情感数据同类样本之间距离最小,异类样本之间距离最大,为情感识别提供了有效的情感判别特征。
本文其余部分安排如下:第二章回顾了与本文有关的相关工作。第三章介绍了多视角判别分析方法及其在多模态情感识别上的应用。第四章展示了本文提出的方法在情感公开数据集DEAP dataset上的结果,并与现有方法进行了比较和分析。第五章总结了本文的工作并指出了未来的工作方向。
2 相关工作
(1)单视角学习与多视角学习
在机器学习领域,某些研究对象只需通过一个特征集来表示,利用单一特征集进行机器学习即称为单视角学习。而多视角学习研究的目标对象是由多个特征集或视角表示的,每个视角都具有与其他视角相一致性的信息和其他视角不具备的信息,多视角学习问题主要研究如何利用不同特征集或视角提供的信息进行充分有效的学习[5]。
传统方法处理多视角数据时,往往将多个视角的数据拼接为一个单一视角的数据,而后再采用单视角数据方法对数据进行处理。然而,由于每个视角的数据都具有独特的统计特性,因此,可能造成在小样本数据上的过拟合或是缺乏合理的物理解释。因此,需要更好的多视角融合方式以取得较优的学习性能。基于此,本文采用多视角学习方法进行多模态情感数据的特征提取,充分利用多视角情感数据在情感表达上的一致性与互补性,建立有效的学习器。
(2)情感模型
选择适合的情感模型是情感识别研究工作的基础。Cowie[11]等人在2001 年总结了大量的在情感识别领域中使用的情感模型。目前,在情感识别领域经常使用的模型可分为离散型的情感模型和维度型的情感模型。离散型情感认为情感由有限个基本情感组成。目前,最常使用的离散型情感是Ekman 等人[12]提出的六大基本情感(“Big Six”),即悲伤、恐惧、惊奇、厌恶、愤怒、高兴6种基本情感。
离散型情感模型符合人们认知的常识,也便于在情感识别问题中的建模。然而,随着情感识别问题研究的深入,学者们发现离散型情感不能反映情感在表达和传递过程中的复杂性和丰富性。因此,维度型情感逐渐受到研究者的关注。目前,最常用的维度型情感是Arousal-Valence模型[13],它将情感定义在两个维度上,横坐标表示情感状态的兴奋程度,从低兴奋度逐渐过渡到高兴奋度,纵坐标表示情感状态的愉悦程度,从不喜欢逐渐过渡到喜欢,这使得人们的情感状态可以在情感维度模型中表达出来。本文关注于维度型情感的分析与识别。
(3)情感计算模型
目前,在情感识别上的计算模型主要有用户依赖模型(User-dependent model)和用户独立模型(User-independent model)。早期的情感识别主要关注于用户依赖模型的建立,即对单一用户建立定制化的模型[14]。而用户独立模型希望根据人类情感表达的共性,建立情感识别的泛化模型。在用户依赖模型中,训练数据和测试数据均来自于同一用户;而在用户独立模型中,训练数据和测试数据分别来自不同的多个用户。在实际的应用场景中,我们很难做到收集每个用户的数据并建立相应的用户依赖模型。因此,近期的情感识别系统开始从用户依赖场景过渡到用户独立场景。然而,由于被试在情感反应上的个体差异性的存在,用户独立模型的准确率仍有待提高。本文中,我们通过建立用户依赖模型和用户独立模型来考察本文所使用的方法。
3 多视角判别分析
多模态信息的互补性表明各个模态都具有其他模态不具有的信息。之前的研究也表明采用多模态信号能够增强情感识别系统[3,15]。传统的多模态情感识别算法简单地将不同模态的特征数据连接起来后进行情感识别,由于各个模态之间的量纲不同,很难有效地挖掘情感表达的一致性和潜在的情感判别空间,其识别结果虽然较单一模态的情感识别较好,但仍然不能令人满意。因此,如何使用多模态生理情感数据挖掘情感表达的一致性与互补性,学习出多模态信号对情感表达的通用判别空间是多模态情感识别的关键问题。
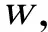
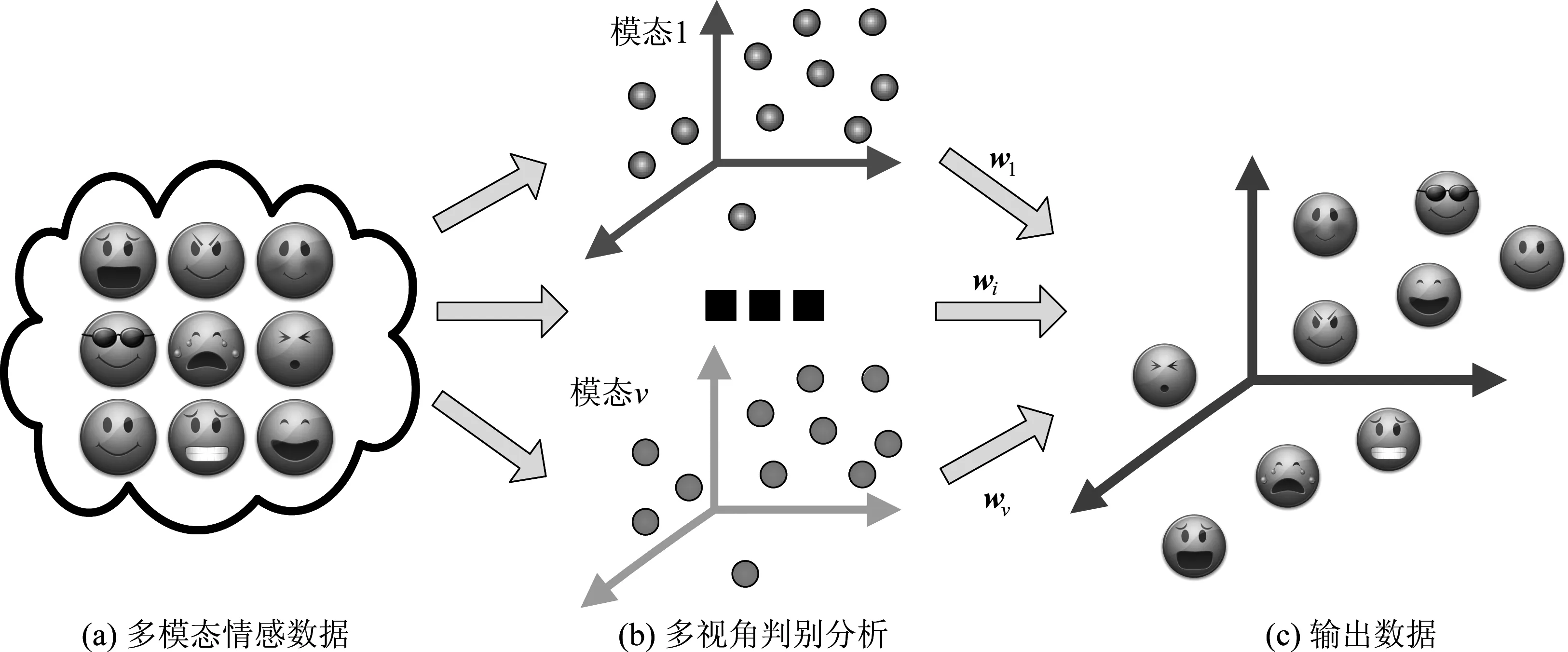
图1 基于多视角判别分析的情感特征提取过程Fig.1 Emotional feature extraction based on multi-view discriminant analysis
考虑来自于多个模态的情感生理数据X={xijk∈Rdj|i=1,…,c;j=1,…,ν;k=1,…,nij},其中,xijk表示第i个类别第j个模态下的第k个样本,ν为多模态个数,c为情感标签类别数,nij为第i个类别第j个模态下的样本个数,dj为第j个模态下的数据维度。

(1)
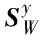
(2)
(3)

(4)

(5)
Sjr的具体求解过程如下所示:

(6)
(7)
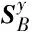
(8)
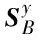
(9)
因此,公式(1)能够被重写为如下形式:
(10)
根据文献[13],公式(10)能够重写为如下形式:
(11)

利用上述投影矩阵W,我们可以将多模态情感生理数据投影到情感表达的通用判别空间,从而获得具有判别性的多模态情感识别特征。
算法1给出了基于多视角判别分析的情感特征提取过程。

算法1 基于多视角判别分析的情感特征提取Input:多模态情感数据:X={xijk∈Rdji=1,…,c;j=1,…,ν;k=1,…,nij},其中xijk表示第i个类别第j个模态下的第k个样本,ν为多模态个数,c为情感标签类别数,nij为第i个类别第j个模态下的样本个数,dj为第j个模态下的数据维度。Output:多模态数据投影矩阵:W=[w∗1,…,w∗ν]T投影后的情感数据:Y={yijk=wTjxijki=1,…,c;j=1,…,ν;k=1,…,nij}1.计算SyW=[wT1,…,wTν]S11…S1ν︙⋱︙Sν1…Sνν()w1︙wνéëêêêùûúúú=WTSW中的所有模态情感数据的类内散度矩阵S,Sjr=∑ci=1(∑nijk=1xiikxTijk-nijnijniμ(x)ijμ(x)ijT),j=r-∑ci=1nijnirniμ(x)ijμ(x)irT,otherwiseìîíïïïïï2.计算SyB=[wT1,…,wTν]D11…D1ν︙⋱︙Dν1…Dνν()w1︙wνéëêêêùûúúú=WTDW中的所有模态情感数据的类间散度矩阵D,

Djr=(∑ci=1nijnirniμ(x)ijμ(x)Tir)-1n(∑ci=1nijμ(x)ij)(∑ci=1nirμ(x)ir)T3.根据公式(w∗1,…,w∗ν)=arg maxw1,…,wνTr(WTDWWTSW),通过求解广义特征值方法得到多模态数据投影矩阵W=[w∗1,…,w∗ν]T;4.计算投影后的情感数据Y={yijk=wTjxijki=1,…,c;j=1,…,ν;k=1,…,nij}。
4 实验
4.1 数据库
本文实验使用目前公开的多模态情感数据集DEAP数据集[16]来分析被试的情感状态,以验证本文所使用的方法。在DEAP数据集中,32导脑电信号(EEG)和6通道生理信号(包括眼电(EOG)、肌电(EMG)、皮电(GSR)、呼吸(RSP)、光电脉搏(PPG)和皮肤温度(ST))用于记录32名被试在观看视频片段(MV)时的情感生理反应。每名被试从120个情感诱导视频中选择性地观看40个视频片段。在观看情感诱导视频后需要对Arousal,Valence,Dominance和Liking四个维度的情感进行自我评价。原始的情感标签按1到9分为9个等级,本文通过设置阈值为5,将其映射为高水平和低水平。
4.2 脑电信号与生理信号的情感特征提取
本实验分别对DEAP数据集中32导全息脑电信号提取了128维相关的情感特征,包括每个电极记录的theta 波(4~8 Hz), alpha波(8~12 Hz), beta波(12~30 Hz)和gamma波(30+ Hz)的谱功率。同时,我们结合生理信号的底层描述符和统计特征,提取了118维外周生理信号相关的情感特征。表1介绍了依据DEAP数据集中生理信号提取的全部相关情感特征。
4.3 实验设置
为了验证多视角判别分析特征抽取的有效性,本文使用Accuracy(ACC)和macro-F1score(F1)作为情感识别性能的两个评估指标。
• ACC: 平均识别精度,即正确预测的比例,这是最常用的评价指标之一。
• F1: 基于查准率与查全率的调和平均。
为了验证多模态识别与单模态识别在情感分类中的性能差异,我们选择随机森林(RF)[17]、支持向量机(SVM)[18]和K近邻(KNN)[18]三种常用的分类算法作为对比;同时选取典型相关分析(CCA)[19]和偏最小二乘(PLS)[20]作为多模态识别的对比算法,以检验多视角判别分析(MDAM)的识别性能。对于多模态方法抽取的特征我们分别采用串行组合(PR1)和并行组合(PR2)方法来观察多模态方法的情感识别性能。上述实验分别在用户依赖模型和用户独立模型下展开,实验中使用的基线算法均已进行参数调整以达到较优的识别性能。
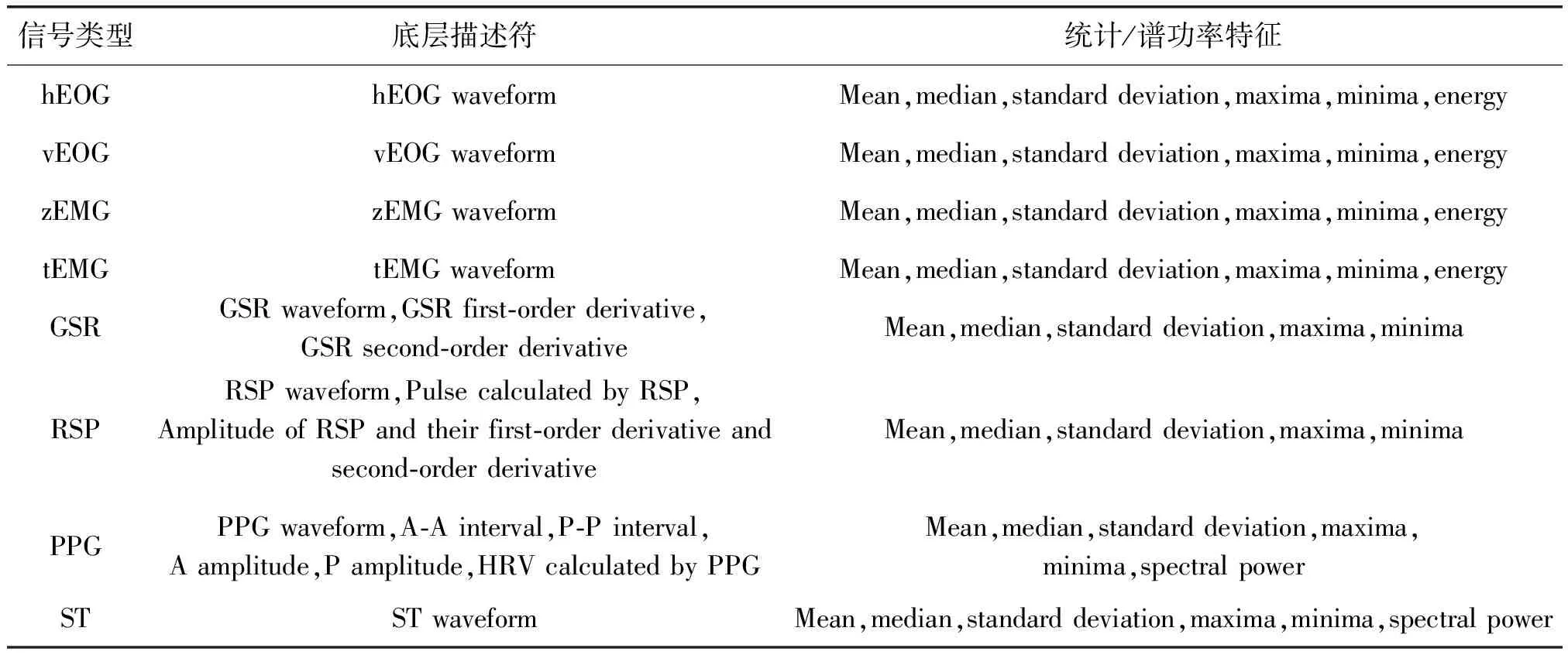
表1 DEAP数据库中基于外周生理信号提取的情感特征
4.4 实验结果与分析
4.4.1 用户依赖模型
表2与表3列出了DEAP数据集下基于脑电信号和外周生理信号单模态数据在用户依赖模型下的情感识别结果。从表2中可以看出,RF和KNN算法在四种情感维度的平均识别率上取得了最好的结果,其识别率为0.64;在四种情感的平均F1上,KNN取得了最好的性能,其F1为0.72。表3中,KNN在四种情感的平均识别率上取得了最佳的识别率,其识别精度为0.64;而在四种情感的平均F1上,RF算法取得了最好的性能,其F1为0.72。上述实验中,SVM在训练测试时,对时间空间上的消耗较大,RF在干扰信息较多的情况下会出现过拟合现象,而KNN相较于其他两种方法更加简单有效,训练的代价较小。综上考虑,本文后续实验使用KNN进行多模态情感识别。
对于用户依赖模型下的多模态情感识别方法,我们将CCA和PLS两种多模态特征抽取方法与本文使用的多视角判别分析方法进行比较。表4给出了用户依赖模型下,基于多模态方法的情感识别结果。为方便对比单模态情感识别和多模态情感识别,我们分别将表2和表3中最好的识别结果也列入表中。对于使用CCA、PLS和多视角判别分析方法抽取的多模态情感特征,我们分别采用串行组合(PR1)和并行组合(PR2)的方式进行特征融合,并观察其实验结果。

表2 用户依赖模型下基于脑电信号的情感识别结果

表3 用户依赖模型下基于生理信号的情感识别结果
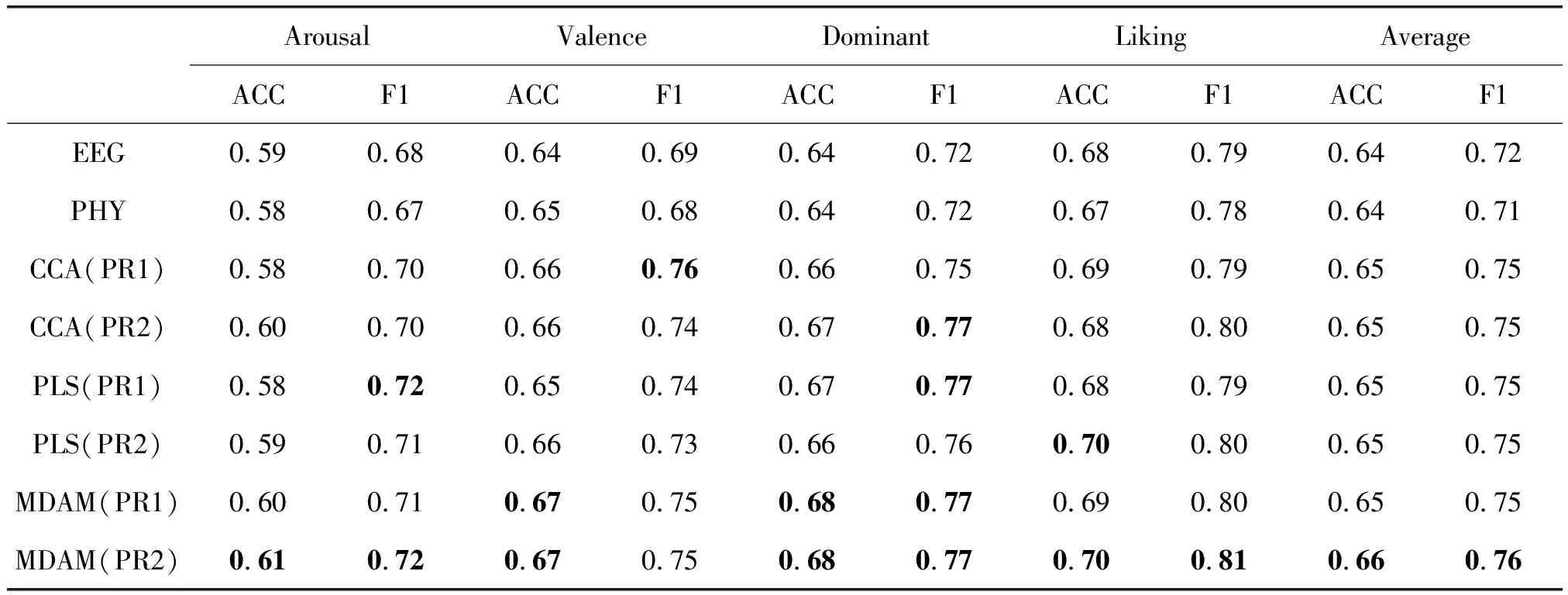
表4 用户依赖模型下基于多视角判别分析的情感识别结果
从表4中可以看出,三种多模态特征抽取方法结果明显优于单模态方法;在基于CCA的多模态情感识别中,特征串行组合方法在Valence情感维度下取得了最高的F1,其得分为0.76,而特征并行组合的方法在Dominant情感维度下的F1取得了最优结果,其得分为0.77;在基于PLS的多模态情感识别中,特征串行组合的方法分别在Arousal 和Dominant 情感维度下取得了最高的F1,其得分分别为0.72和0.77,而特征并行组合的方法在Liking情感维度下取得了最高的识别率,其识别精度为0.70;在基于多视角判别分析的情感识别中,特征串行组合方法在Valence和Dominant情感维度下取得了最好的识别精度,其识别率分别为0.67和0.68,在Dominant情感维度下取得了最好的F1,其得分为0.77,在特征并行组合的方法上,除Valence 情感维度下的F1 没有取得最优的性能,在其他所有情感维度及四种情感维度的平均识别性能上均取得了最优的性能。
4.4.2 用户独立模型
表5和表6列出了DEAP数据集上基于脑电信号和生理信号单模态数据在用户独立模型下的情感识别结果。从表5中可以看出,随机森林和KNN在四种情感维度的平均识别率上取得了最好的结果,其识别率均为0.63;在四种情感的平均F1 上,SVM算法和K近邻算法取得了最好的性能,其得分均为0.74。表6中,与基于脑电的情感识别结果类似,随机森林和KNN在四种情感维度的平均识别率上取得了最好的结果,其识别率均为0.63;而在四种情感的平均F1 上,SVM算法取得了最好的性能,其得分为0.75。综合表5和表6中的结果,在基于用户独立模型的多模态情感识别上,我们仍然使用KNN作为单模态算法的对比算法与多模态情感识别方法进行对比。
表7列出了DEAP数据集上基于多模态情感数据在用户独立模型下的识别结果。表中的前两行分别表5和表6 中两种单模态数据下最好的识别结果。从表7中可以看出,三种多模态识别方法结果明显优于单模态识别方法;其中,在基于PLS的多模态情感识别中,特征串行组合的方法分别在Liking情感维度下取得了最高的识别精度,其识别率为0.69,而特征并行组合的方法在Dominant情感维度下取得了最高的识别率和F1,其性能分别为0.67和0.78;在基于多视角判别分析的情感识别中,特征串行组合方法在Valence情感维度下识别精度上取得了最佳结果,在Dominant情感维度下的识别精度和F1取得了最好性能,而特征并行组合的方法在所有情感维度的识别性能下均取得了最好的识别结果。

表5 用户独立模型下基于脑电信号的情感识别结果

表6 用户独立模型下基于生理信号的情感识别结果
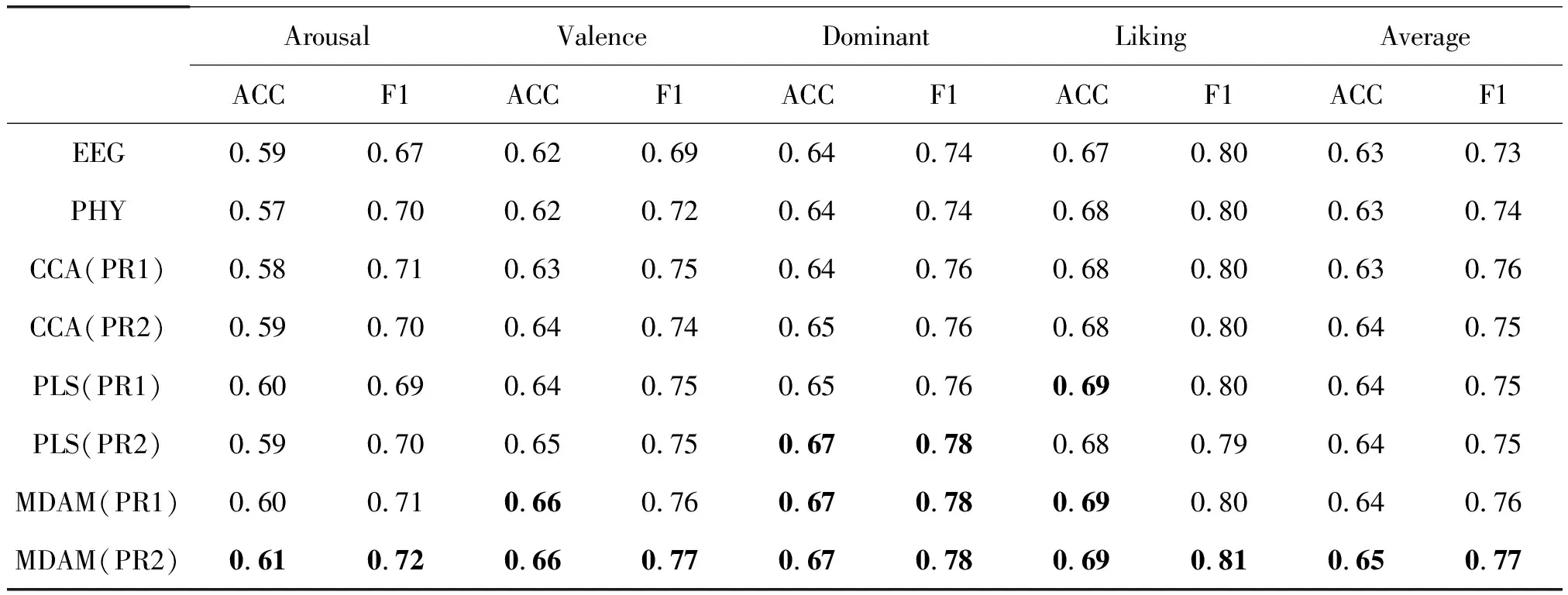
表7 用户独立模型下基于多视角判别分析的情感识别结果
总的来说,人类的情感通过多个模态表现出来,仅使用单一模态的情感数据进行情感识别,很难保证情感识别的精度。本文使用的多视角判别分析方法,抽取了情感数据在不同视角下的一致性和互补性,对多模态情感数据的多个视角建立了本质性的联系,通过利用多视角之间对于表达上的一致性降低每个视角优化目标的搜索空间,并且利用每个视角的独立信息,形成对情感表达更为准确地描述。从表4和表7中,我们可以看出,多模态情感识别方法明显优于单模态情感识别;而在多模态情感识别方法中,本文采用的方法也优于CCA和PLS等无监督的多模态方法,因为多视角判别分析方法充分考虑了情感标签的监督信息,利用情感数据的监督信息最大化多个视角间的类间散度矩阵与类内散度矩阵的比值,找到多个线性变换,将情感数据投影到通用的判别性空间,使得投影后的情感数据具有更强的判别性,为情感识别提供有效的判别特征。表4和表7的结果也证明了本文方法在用户依赖模型和用户独立模型下的有效性。
5 结论
本文从情绪表达的多模态出发,将情感表达的各个模态看作情感表现的不同视角,提出基于多视角判别分析的情感识别,通过使用情感标签的监督信息,抽取多模态数据在情感表达上的一致性和互补性,最大化所有模态情感数据的类内距离和类间距离,并寻找到多组投影,将多模态情感数据投影到一个具有判别性的空间中,为情感识别提供了有效的判别特征。实验结果表明,多视角判别分析方法优于传统的多模态识别方法。未来的工作中,在情感模型构建方面,将利用生理信号的时序性特点,探究时序性对情感识别准确性的影响,考虑将本文使用的多视角判别分析方法与时序模型相结合,进一步提高算法分析和处理情感数据的能力。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
昆明医科大学学报(2022年3期)2022-04-19
当代陕西(2022年4期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
当代陕西(2020年22期)2021-01-18
中华诗词(2019年7期)2019-11-25
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
中国交通信息化(2018年3期)2018-06-13
中国交通信息化(2016年2期)2016-06-06
