
基于CEEMDAN和多尺度排列熵的球磨机负荷识别方法
2018-06-25 02:41胡显能蔡改贫罗小燕
噪声与振动控制 2018年3期
胡显能,蔡改贫,罗小燕,宗 路
(江西理工大学 机电工程学院,江西 赣州 341000)
球磨机负荷是磨矿过程的重要参数,直接影响到磨矿的效果以及生产效率[1]。由于球磨机内部工作环境复杂多变,难以保证稳定的的工作状态,给球磨机负荷识别带来极大阻碍。因此,实现球磨机内部负荷的有效识别,充分发挥球磨机的实际效能,提高磨矿效率是当前急需解决的问题。目前,常用的方法是利用检测仪器采集球磨机筒体或轴承等部位的振动信号,采用小波变换技术对振动信号进行处理分析,发掘球磨机内部负荷与信号特征之间的关系,根据信号特征的变化来识别球磨机的负荷状态。由于球磨机磨矿是筒体内的介质对矿料不断冲击研磨而使矿料粒度逐渐减小的一个随机过程,因此其产生的信号具有非线性、非平稳性的特点。尽管传统的小波变换技术在处理非稳定信号具有一定的优势,但是在处理具有非线性的球磨机振动信号方面仍然存在一定的缺陷。
集成经验模态分解(Ensemble Empirical Mode Decomposition,EEMD)是近些年来处理非线性和非平稳性信号的有效方法之一,由Huang和Wu提出[2]。虽然EEMD处理非线性和非平稳性信号具有一定的优势,但是仍然存在着重构信号中有残留噪声以及计算量大的问题。具有自适应白噪声的完整集成经验模态分解(Complete Ensemble Empirical Mode Decomposition with Adaptive Noise,CEEMDAN)是在EEMD基础上的一种改进方法由Torres等提出,该方法不仅弥补了EEMD方法的不足,还改善了分解的完备性[3]。
排列熵(Permutation Entropy,PE)是一种检测离散时间序列复杂度的指标,具有计算简单、运算速度快以及抗干扰能力强的优点,在脑电信号、机械信号等不同类型信号中得到了广泛的应用[4]。多尺度排列熵(Multi-scale Permutation Entropy,MPE)由Aziz等提出,相比于排列熵具有更好的抗干扰能力和适应性[5]。任静波等将多尺度排列熵应用于铣削颤振检测中,通过实验验证,所提出的方法能够有效地检测铣削颤振[6]。郑近德等将多尺度排列熵应用于滚动轴承故障特征提取,并与支持向量机相结合,有效地实现了轴承的故障诊断[7]。尽管国内的一些学者将多尺度排列熵应用到机械故障诊断中取得了不错的成果,但是将其应用于球磨机负荷识别的研究却非常少。
本文将多尺度排列熵引入到球磨机负荷识别中,结合CEEMDAN和多尺度排列熵的优点,提出一种基于CEEMDAN和多尺度排列熵的球磨机负荷识别方法。考虑到排列熵值随尺度变化的趋势,采用多尺度排列熵偏均值作为球磨机负荷识别的特征值[8]。通过对实测的球磨机振动信号处理分析,表明该方法能够有效地识别出不同负荷类型,并具有一定的稳定性。
1 基本原理
1.1 CEEMDAN方法
CEEMDAN方法的提出是对EEMD方法的重要改进。在EEMD的基础上,CEEMDAN通过添加自适应的白噪声以及计算唯一的余量信号获取IMF,能实现在较少的实验平均次数下,对信号进行完美的重构,克服了EEMD方法在此类实验情况下重构误差较大的缺点。
定义操作符EK(·)为通过EMD方法所产生的第k个模态分量,CEEMDAN所产生第k个模态分量记为k(t),vi为满足标准正态分布的高斯白噪声,ε为高斯白噪声的标准差,则CEEMDAN具体算法由以下几个步骤组成[9]:
(1)针对信号x(t)+ε0vi(t)进行I次实验,通过EMD方法获取第一个模态分量
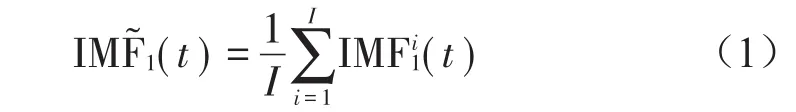
(2)在第1阶段(k=1),计算第一个唯一的余量信号

(3)进行第i次实验(i=1,…,I),每次实验中,对信号ri(t)=ε1E1(vi(t))进行分解,并直到得到第1个模态分量为止,开始计算第2个模态分量
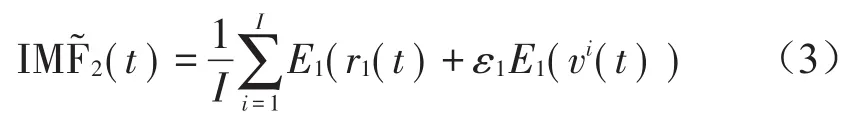
(4)对其余各个阶段,即k=2,…K,与步骤3的计算过程一致,首先计算第k个余量信号,再计算第k+1个模态分量,即有
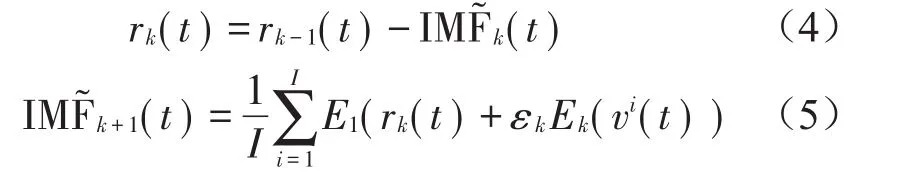
(5)重复执行步骤4,直至所获得的余量信号不能进行分解时(余量信号的的极点个数少于两个),算法结束停止分解。此时,所有模态函数的数量为k。最终的余量满足
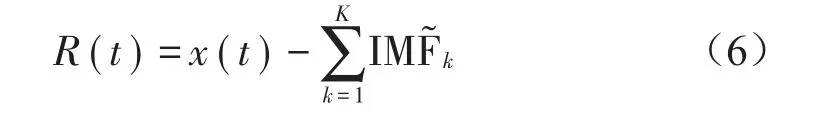
因此,原始信号序列x(t)被分解为
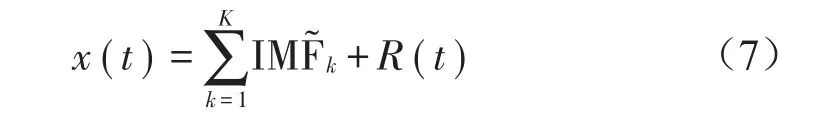
1.2 多尺度排列熵算法及多尺度排列熵均偏值
多尺度排列熵定义为序列进行多尺度粒化后的排列熵,其过程是对原始时间序列进行粗粒化处理,构造出多尺度时间序列,然后计算各尺度下的排列熵值。对于某一时间序列,其具体步骤如下:
(1)对时间序列进行粗粒化处理得到处理后的粗粒化序列
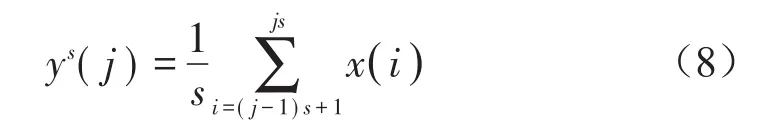
式中:s为尺度因子,ys(j)为不同尺度因子下的时间序列。
(2)对ys(j)进行时间重构

其中:m为嵌入维数,τ为延迟时间。
(3)计算尺度因子s下,该时间序列的排列熵
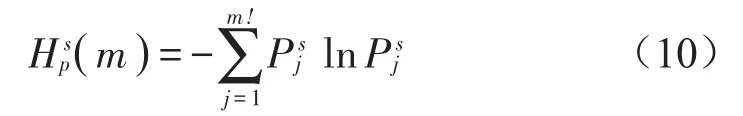
式中:pj为第j次符号序列出现的概率。
(4)将多尺度下的排列熵进行归一化处理
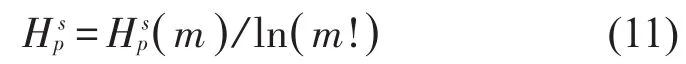
多尺度排列熵偏均值(PMMPE)是建立在多尺度排列熵(Multi-scale Permutation Entropy,MPE)基础上的一种反映信号排列熵值随尺度变化的趋势以及时间序列在多个尺度上的非线性信息的特征值,由王余奎[8]等提出来。对于某一时间序列,具体计算步骤如下:
① 确定多尺度排列熵的的最大尺度因子s;
② 计算该时间序列下所有尺度的排列熵值;
③ 计算该时间序列的偏斜度Ske

式中:Hmmp、Hcmp和Hdmp分别表示多尺度排列熵Hmp的均值、中位数和标准差。
④ 时间序列x(i)的多尺度排列熵偏均值为
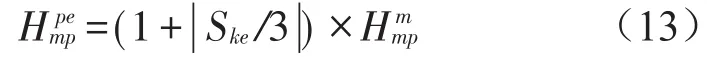
在参数确定的情况下,采用多尺度排列熵算法对不同负荷状态的振动信号处理会得到不同的熵值,多尺度排列熵偏均值也会存在一定的差异,因此,以多尺度排列熵偏均值作为特征值对球磨机负荷状态进行识别具有一定的可行性。
2 信号采集及实验分析
2.1 振动信号采集
实验采用型号为φ330 mm×330 mm的小型实验球磨机,其电机功率为0.75 kw。选用DH131加速度传感器与球磨机轴承进行刚性连接,通过分析球磨机负荷与轴承的受力情况,选取轴承座偏离垂直方向15°处作为振动测点位置。使用DH5922N动态数据采集仪进行振动信号的采集。分别采集正常、欠负荷和过负荷3种负荷状态下球磨机轴承的振动信号。实验中传感器的采样频率为20 kHz,每种负荷状态采集10组数据,每组数据采样点数为80000。取信号特征根据信号特征的差异来准确的识别球磨机的负荷状态。
3种负荷状态下球磨机轴承振动信号波形如图1、图2以及图3所示。
由图1的振动信号的波形图可得,正常负荷状态下筒体内的钢球与矿料都正常,钢球冲击能量主要用于矿料的研磨,因此振动信号的幅值相较于其他两种负荷状态的幅值适中。
由图2的振动信号的波形图可得,欠负荷状态下筒体内的钢球对筒壁冲击剧烈,振动信号的幅值最大。
由图3的振动信号的波形图可得,过负荷状态下筒体内的矿料较多,钢球对筒壁的冲击较小,振动信号的幅值最小。虽然不同负荷状态下振动信号的幅值存在一定的差异,但是仅仅依靠波形图中振幅的差异难以准确的识别球磨机的负荷状态,需要提
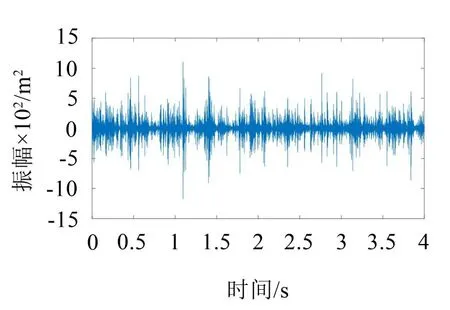
图1 正常负荷状态下球磨机轴承振动信号
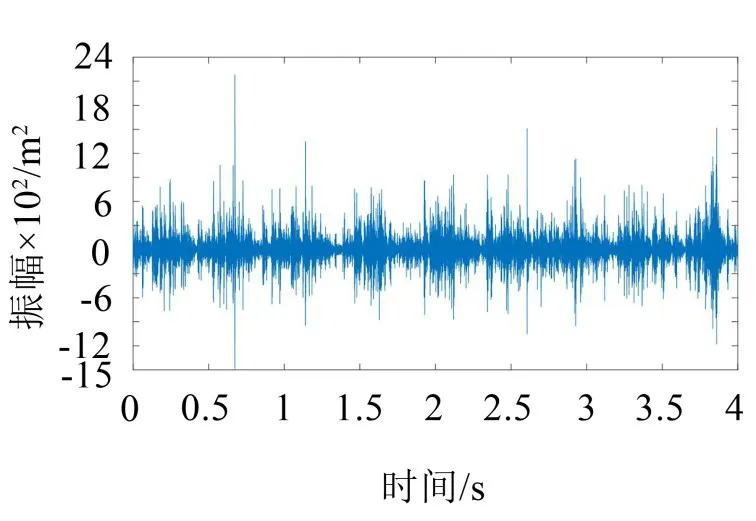
图2 欠负荷状态下球磨机轴承振动信号
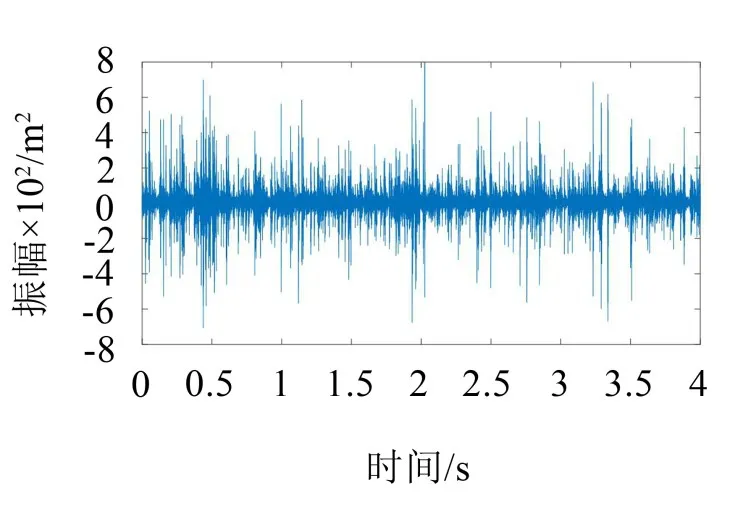
图3 过负荷状态下球磨机轴承振动信号
2.2 基于CEEMDAN的振动信号的分解与重构
球磨机正常负荷、欠负荷以及过负荷3种状态的振动信号经CEEMDAN算法分解得到IMF分量和余量r。本文,仅对正常负荷中的某一组振动信号进行处理,该信号分解的波形如图4所示。
CEEMDAN算法的总体平均次数设为200次,加入白噪声的标准差为0.2。
由于重构后的振动信号不仅要能够携带原始信号所包含的特征,还要排除信号中存在的虚假分量。因此,需要对CEEMDAN分解的IMF分量进行严格筛选,选取与原始信号相关性较好的敏感分量进行重构信号。本文采用相关系数法确定敏感的IMF分量,首先计算各阶IMF分量与原始信号的相关系数,其次根据公式计算相关系数阈值,最后比较相关系数与相关系数阈值的大小,将大于相关系数阈值的IMF分量作为敏感分量对信号进行重构。具体计算公式如(14)所示,3种负荷状态下振动信号的相关系数和相关系数阈值的结果如图5所示。
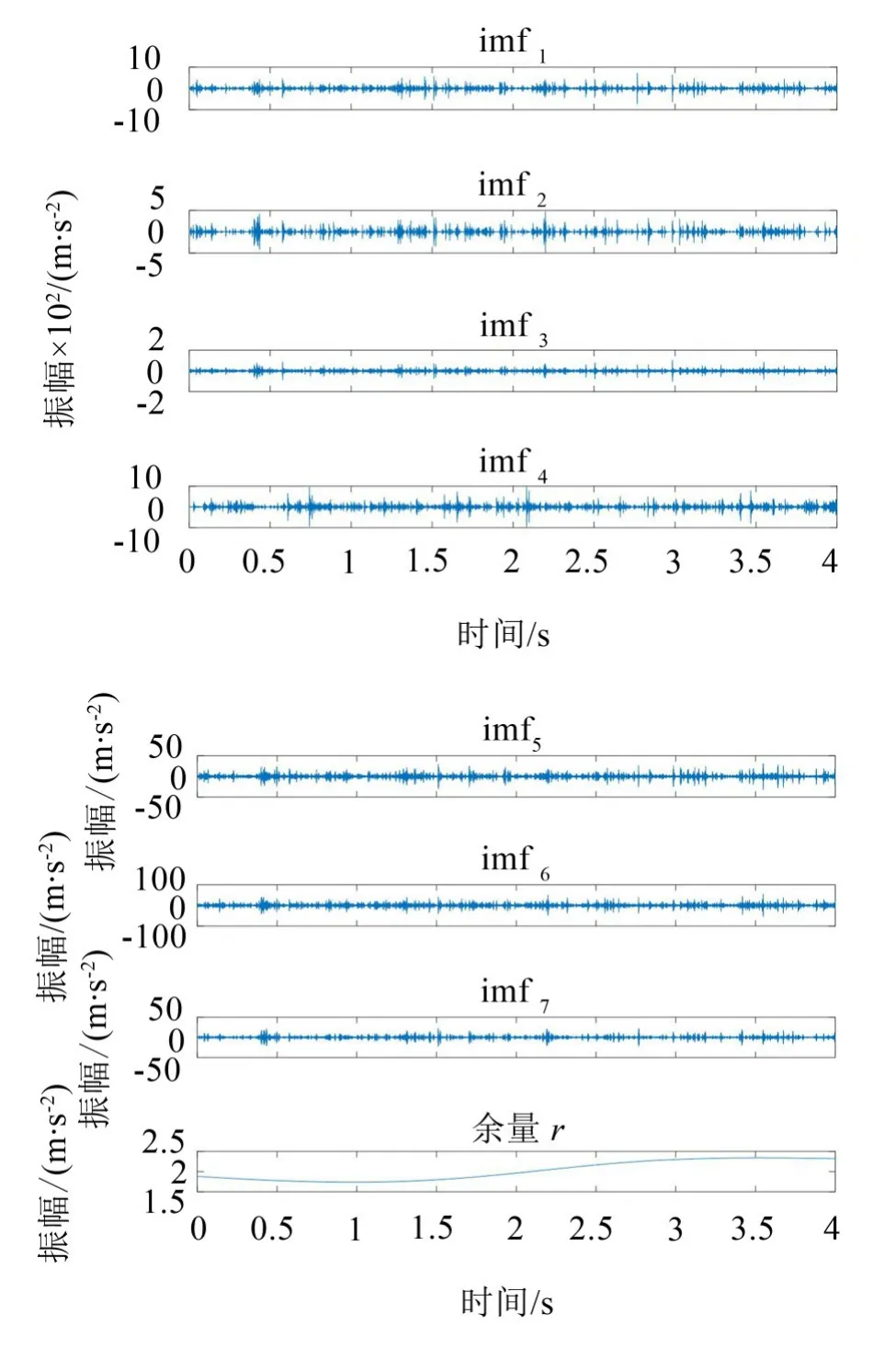
图4 正常负荷振动信号的CEEMDAN分解结果(前7个分量以及余量)
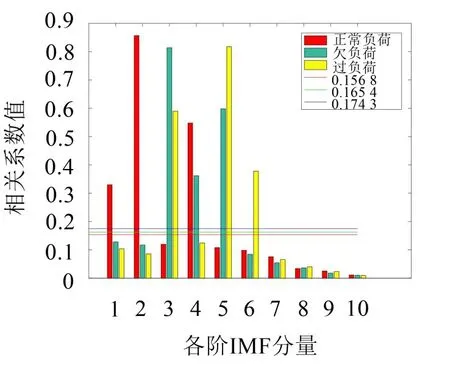
图5 不同状态下IMF分量与原始信号的相关系数
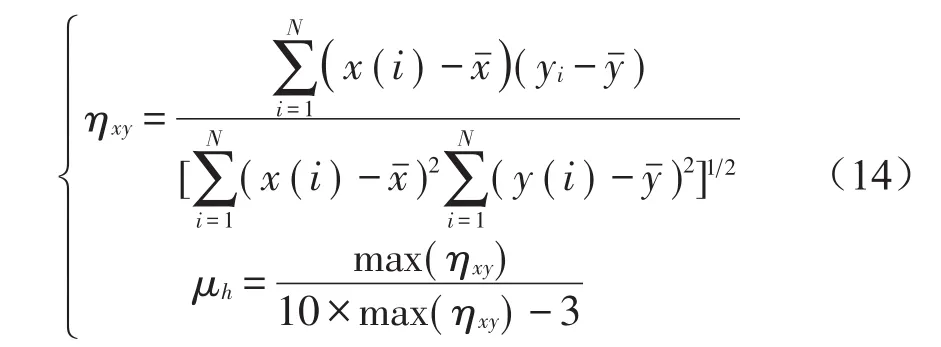
式中:N表示原始信号的长度,x(i)为原始信号,y(i)为IMF分量,ηxy为各IMF分量与原始信号之间的相关系数,μh为相关系数阈值,max(ηxy)为最大相关系数值。
根据公式(14)得出正常负荷、欠负荷以及过负荷3种状态的IMF分量与原始信号的相关系数阈值,它们分别为0.1568、0.1743和0.1654。由图5可得,不同负荷状态下各阶IMF分量的相关系数值存在一定的差异,每种负荷状态下都有3阶IMF分量(正常负荷 IMF1、IMF2、IMF4,欠负荷 IMF3、IMF4、IMF5,过负荷 IMF3、IMF5、IMF6)的相关系数较大而且都远大于相关系数阈值,因此可以说明这3阶IMF分量都是能够反映原始信号特征的敏感分量;而其他阶IMF分量的相关系数值都小于相关系数阈值,表明它们与原始信号的相关性较差,可以视作虚假分量丢弃。将所选取的敏感IMF分量进行求和,分别得到3种负荷状态的重构信号,时域波形如图6、图7以及图8所示。
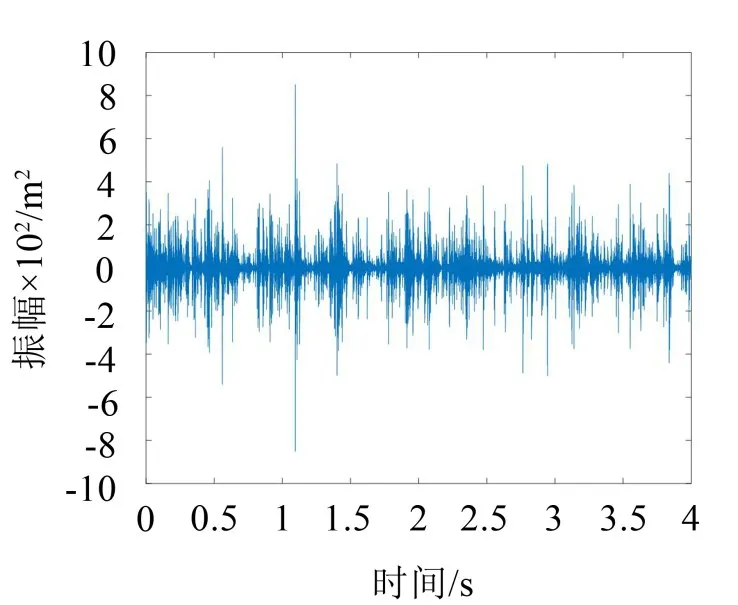
图6 重构的正常负荷振动信号
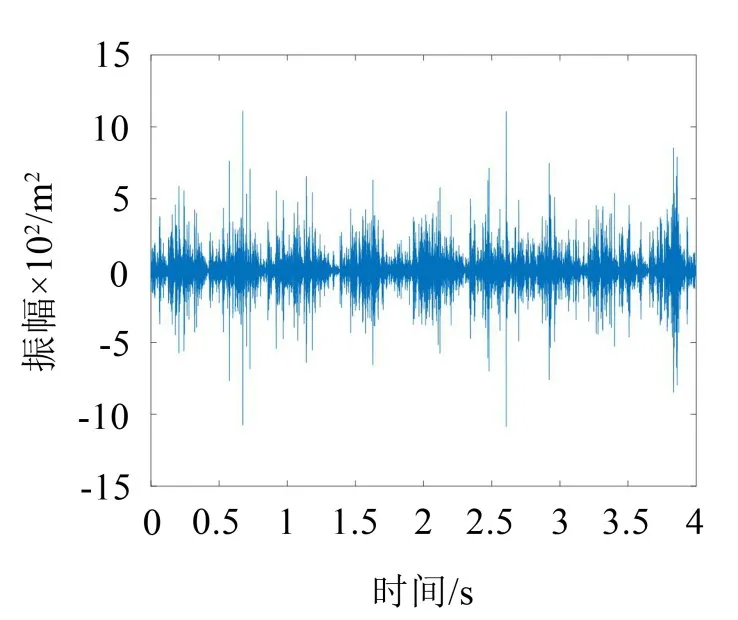
图7 重构的欠负荷振动信号
对比原始信号和重构信号的波形图可知,重构信号与原始信号波形整体趋势相似,但重构信号的幅值明显小于原始信号的幅值,表明重构信号在保存原始信号特征的同时有效去除了原始信号的某些干扰分量。
2.3 多尺度排列熵参数的优选
在计算多尺度排列熵时,需要选取合适的嵌入维数m、延迟时间r以及尺度因子s。如果嵌入维数m取值太小,重构信号中包含原始信号的特征较少,算法失效;如果嵌入维数m取值太大,得出排列熵值之间的差异不明显,掩盖了信号的细微变化不易于区分信号的变化情况,同时还会增加计算量。尺度因子s取值太小,算法得出的排列熵值无法反映原始信号的特征;尺度因子s太大,信号之间复杂度的差异会被掩盖。如果延迟时间r选取得太小,则重构信号失去意义;如果延迟时间r选取得太大,则不利于有效的统计信号中的特征信息。因此,为了识别效果更加显著,本文采用互信息法和伪近邻法[10]对延时时间r以及嵌入维数m进行优选。由于振动信号分析具有一定的周期性,根据实际建模分析得出本实验球磨机振动信号分析周期为2 s[11]。因此,本文分别对3种不同负荷情况下的某一组信号,采用互信息法确定延迟时间r,求得不同负荷情况下互信息随时延时间的变化曲线,如图9所示。
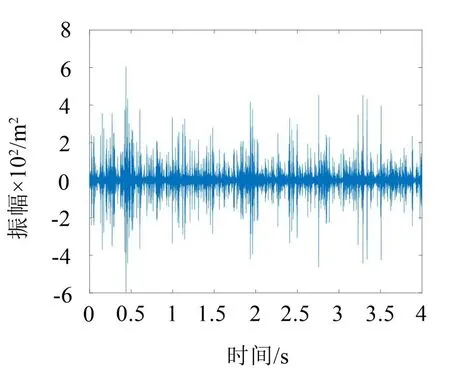
图8 重构的过负荷振动信号
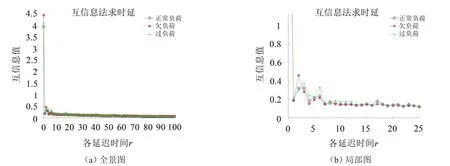
图9 互信息法求延迟时间r
由图9可知,在同一延迟时间下不同负荷状态的互信息值存在一定的差异,但整体的变化趋势一致。当延时时间r=1时,3种负荷状态下信号的互信息值都骤降至0.5以下,且随着延迟时间r的增加互信息值逐渐减小,最终趋于平缓。因此,根据互信息法求延迟时间的准则可得,延迟时间r=1时是该序列的最佳延迟时间。在确定最佳延时时间的基础上,采用伪近邻法选取3种负荷状态下振动信号的最佳嵌入维数m,将伪近邻法中最大嵌入维数设置为8,判据1的阈值设置为20,判据2的阈值设置为2,3种负荷状态下振动信号的伪近邻率随着嵌入维数的变化曲线如图10所示。
图10中圆圈连线是判据1与判据2的联合判据曲线。对比不同负荷状态下的判据曲线可得,虽然同一维数下不同负荷状态的伪近邻率不同,但随着嵌入维数的增加3种负荷状态下判据1和联合判据的伪近邻率都逐渐减小,且在嵌入维数为5处3种判据的伪近邻率都不再随着嵌入维数的增加而减少。因此,根据伪近邻法求嵌入维数的准则可得,3种负荷状态下振动信号的最佳嵌入维数都是m=5。基于选取的延迟时间和嵌入维数,通过对比不同尺度的处理效果,取最大尺度因子为12。
2.4 基于多尺度排列熵偏均值的球磨机负荷特征的提取
选取合适的延迟时间、嵌入维数以及最大尺度因子后,根据多尺度排列熵算法以及多尺度排列熵偏均值计算公式分别计算各组实测振动信号的多尺度排列熵偏均值,计算结果如图11所示。
由图11可知,不同负荷状态下多尺度排列熵偏均值的分布区间存在明显的差异,欠负荷状态下振动信号的偏均值最小、过负荷状态下振动信号的偏均值最大,而且同类负荷状态下偏均值的差异较小,不同负荷状态下偏均值的差异较大。欠负荷状态下球磨机筒体内的钢球和矿料较少,磨矿过程中钢球和矿料在摩擦力的作用随筒体运动到一定高度下落,下落过程中与其他钢球、矿料以及筒壁的碰撞频率较高,能量主要消耗在钢球与筒壁以及钢球与钢球之间的碰撞,因此产生的振动信号较复杂、信号的随机性大;反之,过负荷状态下筒体内部钢球和矿料较多,使得磨矿过程中钢球与矿料仅仅作蠕动作用,因此产生信号的复杂程度较低、随机性较小;正常负荷状态下,能量主要用于矿量的研磨,钢球与钢球之间的碰撞几率大大降低,因此产生信号的复杂程度相对适中。根据图中3种负荷状态下多尺度排列熵偏均值曲线分布区间的差异就能明显的区分出球磨机的3种负荷状态,因此证明了以多尺度排列熵偏均值作为球磨机负荷识别特征指标的有效性。
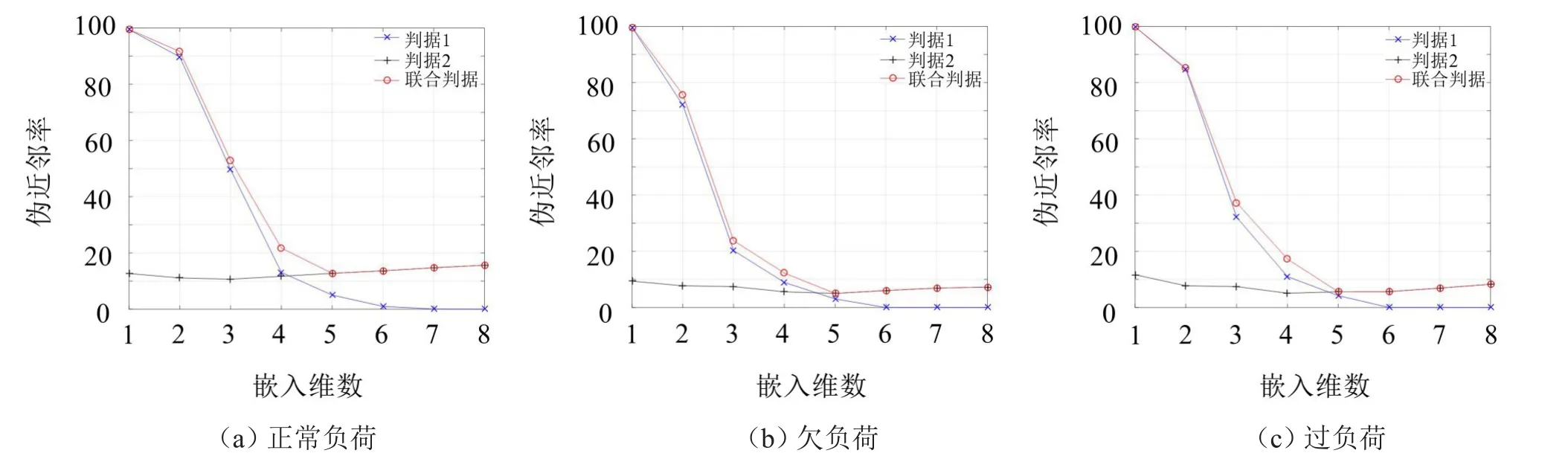
图10 伪近邻法求嵌入维数m
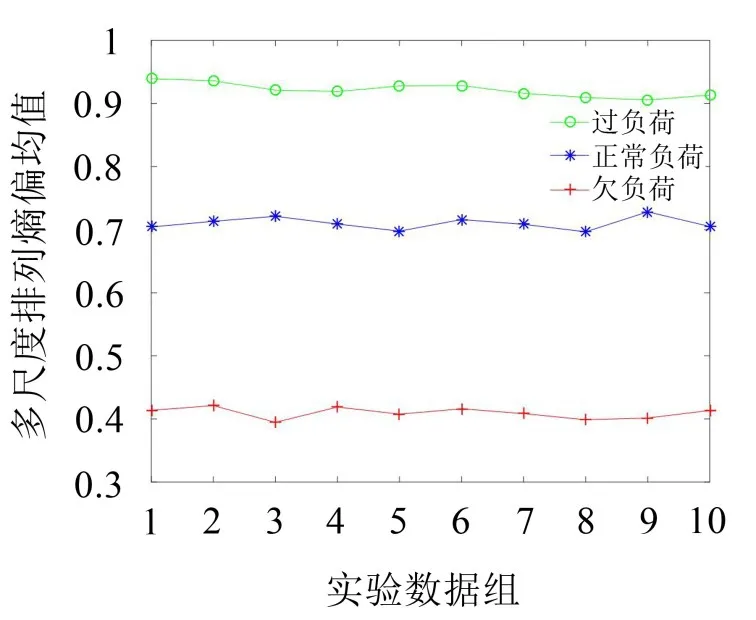
图11 重构信号的多尺度排列熵偏均值
3 结语
本文提出一种基于CEEMDAN与多尺度排列熵相结合的球磨机负荷识别方法。针对球磨机振动信号的非线性、非平稳性,采用CEEMDAN对信号进行处理,与小波分析方法相比,它克服了依赖于主观经验影响的缺点,有利于进一步提高负荷识别的准确度。同时,将多尺度排列熵引入到球磨机负荷识别当中,利用多尺度排列熵对信号微弱变化具有很高的敏感性的特点,来对处理后的信号进行分析。最后根据得出的多尺度排列熵值计算排列熵偏均值,以多尺度排列熵偏均值作为特征值来对球磨机负荷进行识别。通过对实测振动信号进行验证,结果表明不同负荷状态下偏均值的分布区间存在明显的差异,欠负荷状态下振动信号的偏均值最小、过负荷状态下振动信号的偏均值最大,而且同类负荷状态下偏均值的差异较小,不同负荷状态下偏均值的差异较大。验证了本文方法的可行性,具有一定的应用价值,为球磨机负荷识别研究提供了一种新的途径。
[1]谭仁鹏.球磨机振动信号采集与无线传输装置的设计与开发[D].沈阳:东北大学,2009.
[2]WU Z H,HUANG N E.Ensemble empirical mode decomposition:A noise enhanced data analysis method[J].Advances inAdaptive DataAnalysis,2009(1):1-41.
[3]TORRES M E,COLOMINAS M A,SCHLOTTHAUER G,etal.A complete ensemble empiricalmode decomposition with adaptive noise[C].2011 IEEE International Conference on Speech and Signal Processing(ICASSP),May,22-27,2011,Prague,Czech.2011:4144-4147.
[4]LI DUAN,LI XIAOLI,LIANG ZHCNHU,et al.Multiscale permutation entropy analysis of eeg recordings during sevoflurance anesthesia[J].Journal of Neural Engineering,2010,7C:1088-1093.
[5]BANDT C,POMPE B.Permutation entropy:a natural complexity measure for time series[J].Physical Review Letters,the American Physiological Society,2002,88(17):1741021-1741024.
[6]任静波,孙根正,陈冰,等.基于多尺度排列熵的铣削颤振在线监测方法[J].机械工程学报,2015,51(9):206-212.
[7]郑近德,程军圣,杨宇.多尺度排列熵及其在滚动轴承故障诊断中的应用[J].中国机械工程,2013,24(19):2641-2646.
[8]王余奎,李洪儒,叶鹏.基于多尺度排列熵的液压泵故障识别[J/OL].中国机械工程,2015,26(04):518-523.
[9]李军,李大超.基于CEEMDAN-FE-KELM方法的短期风电功率预测[J].信息与控制,2016,45(02):135-141.
[10]饶国强,冯辅周,司爱威,等.排列熵算法参数的优化确定方法研究[J].振动与冲击,2014,33(1):188-193.
[11]熊洋.基于振动特征提取的球磨机负荷预测研究[D].赣州:江西理工大学,2016.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
防爆电机(2022年2期)2022-04-26
商品与质量(2021年10期)2021-11-24
电子制作(2019年20期)2019-12-04
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
自动化学报(2018年2期)2018-04-12
佛山陶瓷(2016年2期)2016-02-05
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
郑州大学学报(理学版)(2014年4期)2014-03-01
