
基于用户打分和评论的推荐算法研究
2018-06-15 04:34岳添骏杨大为
沈阳理工大学学报 2018年2期
祁 燕,岳添骏,杨大为
(沈阳理工大学 信息科学与工程学院,沈阳 110159)
随着电子设备和互联网技术的不断发展,人们逐渐从信息匮乏的时代走入了信息过载的时代。推荐系统[1]是一种解决信息过载问题的有效工具。简单的说,推荐系统是通过分析用户的历史行为记录从而得到推荐内容[2]。这些记录是用户对于一系列项目(例如:电影、歌曲、电子书等)所做行为的体现,这些行为可以是显性的,一般表现为打分行为;也可以是隐性[3]的,典型的隐性行为是用户操作所留下的痕迹,例如:听歌时间、下载记录等。通过分析这些记录为用户指引该用户不熟悉的新物品来解决信息过载的现象。在推荐领域中,协同过滤算法是较为重要的一类算法,可以分为两类[4]:基于近邻的方法和基于模型的方法。其中基于近邻的协同过滤算法包括基于用户的协同过滤算法和基于物品的协同过滤算法,推荐过程是在预测中直接使用已有的数据进行预测,算法的核心是在系统中被其他用户打分过的物品内容[5],主要思想是使用属性构建用户和物品之间的关联,其属性代表在系统中用户和物品的潜在特征,如用户对喜欢物品的打分以及物品的类别。基于用户的协同过滤算法的基本思想寻找与目标用户最相似的用户,然后将用户喜欢的而目标用户没看过的物品推荐给目标用户。基于物品的协同过滤算法类似,匹配与目标用户喜欢的物品相类似的物品来进行推荐。
但是,在传统的基于近邻的协同过滤算法中,数据来源只有用户对物品的打分数据,会出现数据稀疏性的问题,并且如有恶意评分的行为存在,也会影响用户和物品之间的相似度度量。已有学者针对这一问题提出了不同方法进行解决。例如:廉涛等[6]提出了一种混合协同过滤算法,使用LDA主题模型[7]发现用户和物品潜在的因素,在低维的空间内计算用户和物品的相似度,由于LDA主题模型可以有效地从评分矩阵中发现对计算相似度有用的用户和物品的特征,所以缓解了数据稀疏性的问题。彭敏等[8]提出了一种基于情感分析的推荐算法:SACF,该算法利用LDA主题模型挖掘出项目的K个属性,通过用户在各个属性上的情感偏好计算用户之间的相似度;但SACF算法只考虑到用户的情感,而忽略能体现用户兴趣的评分,没有考虑到评分与评论之间关系。
本文提出一种加权的基于LDA的协同过滤算法。算法分为2个部分联合进行相似度计算:(1)将用户对不同物品的评论文本集合在一起,组成用户评论集合,通过LDA主题模型对用户评论集合进行主题提取。(2)用户对物品打分高时所给予的评论相对积极,对于打分低的评论则相对消极(文中称为用户兴趣);针对用户的这一特性,通过LDA主题模型对用户的每一条评论进行兴趣主题提取,并通过打分数值作为主题向量的“奖惩”权重。最后联合进行相似度计算并进行推荐。
1 LDA主题模型
LDA主题模型是一种基于贝叶斯的概率生成模型,是一个以“主题-文档-字”为层次结构,同过加入Dirichlet先验分布来解决过拟合现象的三层贝叶斯概率模型,可以通过文字对其中隐含的主题进行建模,进而挖掘文本主题。LDA模型中的参数如表1所示,LDA图模型如图1所示。

表1 LDA模型参数描述

图1 LDA图模型
LDA模型在生成一篇文档过程中,其物理过程可以理解为投掷骰子,骰子每个面概率不一样,在生成第d篇文档的时候主要分为2步:
(1)从一个盒子中抽取一个文档-主题的骰子Θd,然后投掷这个骰子生成文档中第n个词的主题编号Zd,n;
(2)在另一个盒子中,都是主题-字的骰子,挑选标号t=Zd,n的骰子进行投掷,然后生成一个字Wd,n;
(3)重复1、2两步直至生成整篇文档。
LDA主题模型中,服从Dirichlet分布的超参数α和β需要通过抽样的方法进行估计,实验过程中通过使用吉布斯抽样方法进行抽样[9]。
2 加权的基于LDA的协同过滤算法
2.1 算法总体流程
通过对用户的打分和评论文本分析,提取出用户主题和用户兴趣,提出了加权的基于LDA的用户协同过滤算法。算法的流程图如图2所示。
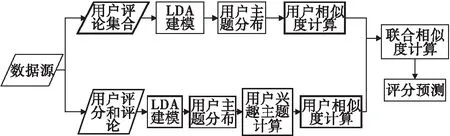
图2 算法流程图
首先对原始的数据源进行数据预处理,在原始数据中有用户ID,物品ID,用户对物品的打分,用户对物品的评论等数据。将每位用户对属于同一类别的不同物品的评论文本集合在一起,组成用户评论集合。利用LDA主题模型对每位用户评论集合进行主题提取,生成用户主题分布,通过相对熵的计算方法对用户之间的主题分布进行相似度计算并查找最近邻;然后,从原始数据源中提取出每位用户的打分和评论。利用LDA主题模型对每条评论进行主题提取,得到用户主题分布,使用用户对这件物品的打分数据作为权重对用户主题分布进行加权,得到用户兴趣主题,根据用户兴趣主题计算用户相似度。将两种相似度计算方法通过不同的比重结合在一起得到联合相似度,最后预测用户对未评过分的物品的评分。
2.2 相似度计算
对于用户主题,利用相对熵对用户主题进行相似度计算,如式(1),找出K个最相似的近邻。
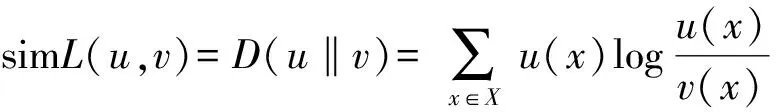
(1)
式中u(x)和v(x)表示在x取值下用户u的主题分布和用户v的主题分布。
对于用户兴趣主题,首先要用LDA主题模型对每条评论文本进行主题分析,产生K维的主题分布。这些主题分布表示用户u在这篇评论中对物品i在不同主题上的概率,用来描绘用户u对于物品i的个人兴趣点。计算如式(2)所示。
(2)
式中:Pu表示用户u在K维主题上的概率向量,向量分量表示每个主题出现的概率;Iu表示用户u有过评分和评论的物品集合;θui表示概率主题分布;Du表示用户u的评论集合。
伴随着用户u对每件物品i评论文本dui的是用户的打分数据rui,rui的分数越高,说明用户u对于物品i越满意,那么写下的评论文本内容会是用户满意和喜欢物品i的理由。如果rui的分数很低,那么写下的评论文本内容多是讨厌物品i的理由。为突出满足用户需求的特征,利用rui为从评论文本中提取出的概率主题分布进行加权,将重点放在用户感兴趣的主题上,将用户讨厌的主题尽可能的降低其计算相似度时的比重。对于评论文本dui,用户打分所占权重的计算式见式(3)。
(3)
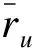
(4)
得到用户u的兴趣主题Pu,即可计算用户之间的相似度simP,见式(5)。
(5)
式中:k表示在提取用户每条评论主题时,提取k个主题;puj表示用户u在第j个主题上的概率值;pvj表示用户v在第j个主题上的概率值。根据式(5)可以计算出用户之间的相似度,在计算过程中,需要确定近邻的数目;根据文献[10],近邻的数目会直接影响到预测得分和推荐的准确性。
通过上述研究,可以各自算出用户之间的相似度,因此把二者结合起来,通过联合学习的方式来共同计算相似度,可以提高预测评分的准确性,用户相似度计算式见式(6)。
uni_sim(u,v)=λsimL(u,v)+(1-λ)simP(u,v)
(6)
式中参数λ是用来调节2种相似度所占的比重,需要在实验中获取。
类似地,在加权的基于LDA的物品协同过滤算法中,物品i和j之间的相似度可以通过类似的方法得到。
2.3 评分预测
对于加权的基于LDA的用户协同过滤算法,计算完用户相似度之后,利用评分预测式(7)来预测用户对于未打分物品可能的打分。
(7)
对于加权的基于LDA的物品协同过滤算法,利用式(8)来预测用户对未打分物品可能的打分。
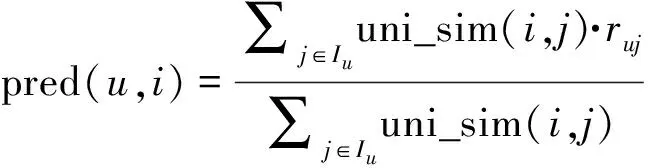
(8)
式中:Iu表示用户u有过打分行为的物品集合;ruj表示用户u对物品j的打分;uni_sim(i,j)表示联合物品主题和物品特征主题计算的相似值。
3 实验结果与分析
3.1 实验数据及评价指标
实验所使用的数据集来自社交网站Yelp公开提供的社交网络签到数据集。数据中记录了用户对于商户的各种历史行为,因此按照数据中商户所属的城市和商户的经营类别,提取部分数据用于实验。数据包括Charlotte城市中经营类别为Restaurant的商户。数据集中的每条记录都有用户ID、商户ID、打分数据、签到时间、评论文本等元素。表2显示了这些数据的一些基本信息。

表2 实验数据集
由表2可以看出,数据集中有大量的评论文本可以用作用户兴趣点和商户特征的建模,同时,数据非常稀疏,仅使用评分数据来进行用户评分的预测,准确度较低,而本文提出的方法在解决数据稀疏方面体现出一定的优势。
实验采用平均绝对误差MAE(Mean Absolute Error)作为评测推荐准确性的标准。MAE是推荐系统领域中普遍使用的一种评测标准。MAE的计算公式如式(9)所示。
(9)
式中:pred(u,i)表示用户u对商户i的预测评分;rui表示用户u对商户i的真实评分;Test表示数据的测试集。通过计算预测评分和用户实际评分的差值来衡量推荐算法的准确性,MAE的值越小,说明预测的越准确,推荐算法的准确性就越高,反之预测的准确性越低。
3.2 实验结果及分析
为验证提出算法的有效性,设计了2组实验进行对比验证。首先,在加权的基于LDA的用户协同过滤算法中,实验确定联合相似度计算中2个部分的参数,通过设置不同的主题数和近邻数来找到最佳的参数,然后和基于用户的协同过滤算法(UserCF)、LDA-CF在数据集上进行对比实验。其次,在另一组实验中,同样需要确定联合相似度计算中2个部分的参数,和基于物品的协同过滤算法(ItemCF)、LDA-CF在数据集上进行对比实验。其中LDA-CF算法是使用LDA主题模型,结合潜在因素和邻域方法的混合协同过滤算法。对于实验所用的数据集,根据数据中的时间属性,随机划分80%的数据作为训练集,20%的数据作为测试集,最后通过MAE的值来衡量推荐的准确性。
3.2.1 基于用户的本文算法结果分析
对于加权的基于LDA的用户协同过滤算法,由于用户主题是从评论文本集合中提取,文本字数比较多,因此需要先确定simL(u,v)中用户主题个数TL。将用户主题个数TL定为5、10、20、30,实验结果如图3所示。

图3 不同用户主题个数下的用户数量
由图3中可以看出,当用户主题个数TL=5时,和主题1相关的用户达到22500人,而与其他4个主题相关的人数远远少于这些人,当TL=10时,也出现了类似的情况。当大部分用户都倾向于某一个主题时,会造成用户之间相似度计算不准确的问题。当TL=20和30时,不同主题下的用户数量差距较小且分布相对分散。因此,在实验结果相近的情况下,为提高算法执行效率,将用户主题个数TL定为20。
在对用户提取兴趣主题时,由于是对每条评论文本提取主题,文本内容有限,因此主题个数TP不能定的过多,防止出现主题不突出的问题,实验中将TP的值定为5。对于加权的基于LDA的用户协同过滤算法,通过固定最近邻的大小K的值,来确定λ的值。令最近邻的数目K=20,调节参数λ。在测试集上的实验结果如图4所示。
从图4可以看出,当λ=0.3时,算法的MAE取得最小值。因此在加权的基于LDA的用户协同过滤算法中的参数λ为0.3。
通过重新调整最近邻K的参数,来观察在不同近邻下的执行效果,以及与UserCF和LDA-CF算法进行对比,实验结果如表3所示。
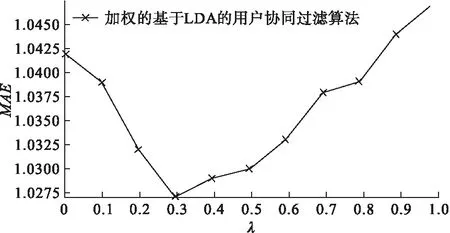
图4 MAE随参数λ的变化情况
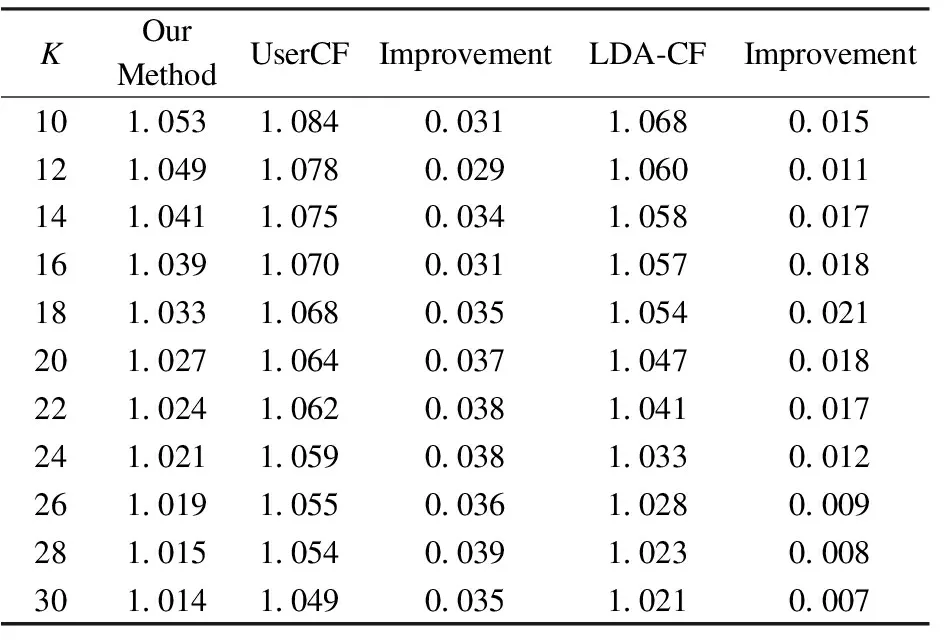
表3 不同近邻数K下的MAE
从表3中的Improvement列可以看出,本文提出的算法准确率明显优于UserCF算法和LDA-CF的准确率,且在不同的近邻K值的情况下,本文提出的算法的性能也都优于UserCF和LDA-CF;在近邻数较少的情况下,可以根据评论文本提取主题来弥补只有打分数据带来的数据稀疏性的问题,同时,对不同打分数据下的评论文本进行加权处理,相比LDA-CF的准确率也有所提升。图5展示了3种算法实验结果的折线曲线。
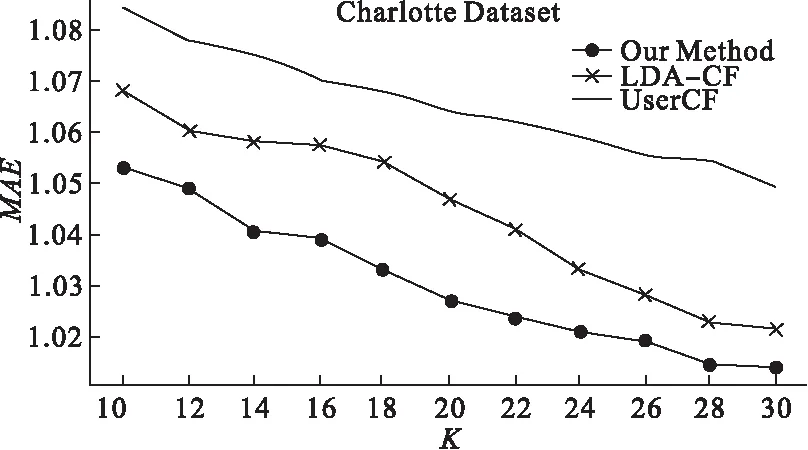
图5 不同近邻数K下的MAE
从图5可以看出,3种算法的MAE值都呈下降趋势,说明推荐的准确率越高。
3.2.2 基于物品的本文算法结果分析
在加权的基于LDA的物品协同过滤算法中,对于TL的取值仍沿用之前的实验结果,令TL=20。实验首先需要确定联合相似度计算过程中比重参数λ的值,由于商户收到的每条来自用户的文本评论内容有限,因此对于主题数TQ不能定过多,在文本内容较少的情况下,主题数量过多会造成特征主题不突出的结果,因此令TQ=5。实验中,通过固定最近邻K的值,观察MAE值的变化情况来确定λ的值。令最近邻的数目K=20,调节参数λ,在测试集上的实验结果如图6所示。
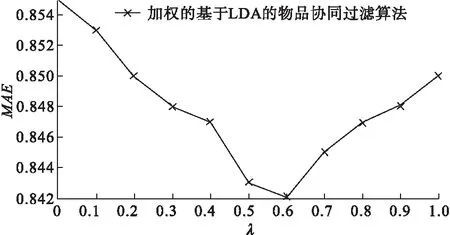
图6 MAE随参数λ的变化情况
从图6可以看出,当λ=0.6时,本算法的MAE取得最小值。因此取该算法参数λ为0.6。
在固定参数λ为0.6后,需要通过重新调整最近邻K的数值,进行对比实验。实验结果如表4所示。

表4 不同近邻数K下的MAE
从表4可以看出,本算法的准确率明显优于ItemCF算法和LDA-CF的准确率。从表4中Improvement列中可以看出,当近邻数少时,本算法在预测评分的准确率上优势更加明显,当用户数增加时,与ItemCF的差距在逐渐减小,这是因为当数据稀疏时,本算法可以根据评论文本提取商户特征主题来弥补只有打分数据带来的数据稀疏性的问题。当近邻数增多时,因为物品收到的打分数据远远多于用户对物品的打分数据,因此ItemCF算法的准确率随着近邻的增多而更准确。相比于LDA-CF算法,由于根据物品的打分数据对物品所收到的评论文本进行了加权处理,因此在预测准确度上本算法优于LDA-CF算法。实验结果通过折线图的方式展现出来,如图7所示。
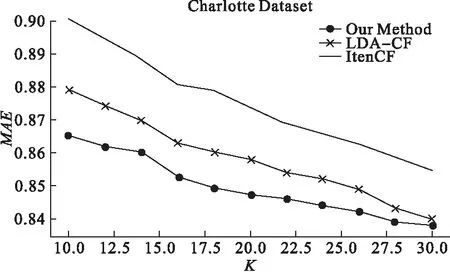
图7 不同近邻数K下的MAE
从图7可以看出,随着近邻数目的增加,3种算法的MAE值都呈下降趋势,说明随着近邻数的增加,预测的分数越准确,推荐的准确率就越高。
对比2组实验可以发现,总体上,本文提出的算法在数据集上的表现要优于LDA-CF、UserCF、ItemCF算法。
4 结束语
提出的加权的基于LDA的协同过滤算法考虑了用户评论文本集合的特点以及打分对于评论文本的影响,与UserCF、ItemCF算法和LDA-CF相比,实现了摆脱传统算法中单纯使用用户-物品打分矩阵的局限以及根据用户兴趣特征进行个性化推荐,有效的缓解了单纯使用打分数据带来的数据稀疏性问题,提高了预测的准确性。但仍然存在一些不足之处,如评论文本中存在的虚假评论情况,评论文本中感情因素对推荐的影响等。因此,将有待于研究更精准的算法来解决现阶段面临的挑战。
参考文献:
[1] Francedsco Ricci,Lior Rokach,Bracha Shapira,et al.推荐系统:技术、评估及高效算法[M].北京:机械工业出版社,2015:2-3.
[2] J Bobadilla,F Ortega,A Hernando.Recommender systems survey[J].Knowledge-Based Systems,2013,46(1):109-132.
[3] SK Lee,YH Cho,SH Kim.Collaborative filtering with ordinal scale-based implicit ratings for mobile music recommendations[J].Information Sciences,2010,180(11):2142-2155.
[4] G Adomavicius,A Tuzhilin.Toward the Next Generation of Recommender Systems:A Survey of the State-of-the-Art and Possible Extensions[J].Springer International Publishing,2013,17(6):734-749.
[5] Li D,Lv Q,Shang L,et al.Item-based top-N recommendation resilient to aggregated information revelation[J].Knowledge-Based Systems,2014,67(3):290-304.
[6] 廉涛,马军,王帅强,等.LDA-CF:一种混合协同过滤方法[J].中文信息学报,2014,28(2):129-135.
[7] Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003(3):993-1022.
[8] 彭敏,席俊杰,代心媛,等.基于情感分析和LDA主题模型的协同过滤推荐算法[J].中文信息学报,2017,31(2):194-203.
[9] Griffiths T L,Steyvers M.Finding scientific topics[J].Proceedings of the National Academy of Sciences of the United States of America,2004,101(Suppl 1):5228-5235.
[10] Herlocker J,Konstan J A,Riedl J.An Empirical Analysis of Design Choices in Neighborhood-Based Collaborative Filtering Algorithms[J].Information Retrieval,2002,5(4):287-310.
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
云南教育·小学教师(2022年4期)2022-05-17
新班主任(2022年4期)2022-04-27
疯狂英语·初中天地(2021年11期)2021-02-16
科学大众(2020年23期)2021-01-18
艺术评论(2020年3期)2020-02-06
制造技术与机床(2019年10期)2019-10-26
少年漫画(艺术创想)(2019年2期)2019-06-06
汽车观察(2019年2期)2019-03-15
电子制作(2018年18期)2018-11-14
