
基于循环神经网络的藏语语音识别声学模型
2018-06-14 07:38黄晓辉
中文信息学报 2018年5期
黄晓辉,李 京
(1. 中国科学技术大学 计算机科学与技术学院,安徽 合肥 230027;2. 解放军外国语学院 河南 洛阳 471003)
0 引言
藏语属于汉藏语系的藏缅语族藏语支,存在历史悠久,使用人口众多[1-2],广泛分布于我国西藏、青海、甘肃、四川,以及尼泊尔、印度、巴基斯坦等藏族聚集地区[3]。藏语语音识别技术的发展,可有效解决藏区与其他地区之间的语言沟通障碍,促进民族间交流,增进相互了解,支援藏区经济、科技、文化等领域的发展。与汉语、英语等大语种相比,藏语不仅使用人数少,且大多分布于经济欠发达地区,科教水平相对落后,因此在语音处理技术方面要滞后很多,直到 2005 年才有研究者开始关注藏语语音识别技术的研究[4]。目前,针对藏语语音识别的研究也取得了一些成果,如杨阳蕊等借鉴汉语连续语音语料库构建方法,分别建立了基于半音节和三音素模型的藏语连续语音语料库,为藏语语音识别提供了基础数据支撑[5];李冠宇、孟猛基于隐马尔可夫模型(hidden markov model,HMM)构建藏语单音子和三音子模型,分别以音素和声韵母作为识别基元进行了实验,验证了基于GMM-HMM的声学模型应用于藏语大词表连续语音识别的可行性[6]。近年来,深层神经网络的应用使语音识别的各项指标得到了明显提升,在英语、汉语等大语种的某些应用领域已进入实用阶段。深度神经网络相较传统GMM-HMM模型的优势已经在实验室环境下和实际应用中得到了验证[7]。目前,在藏语语音识别方面也有基于深度神经网络的研究成果,如王辉、赵悦等利用深度神经网络进行特征学习,将学习到的特征输入HMM模型,在藏语音素识别和孤立词识别上取得了明显优于GMM-HMM模型的性能[8];袁胜龙、郭武等基于迁移学习的思想,先在大规模汉语语料上训练深度神经网络模型,再将网络隐含层共享,在小规模藏语语料上进行训练调优,一定程度上解决了藏语语料资源匮乏导致的模型训练不充分问题[9]。从目前来看,将深层神经网络应用于藏语语音识别已经成为藏语语音处理技术发展的必然趋势。
随着计算设备性能的提升和数据量的快速增长,各种神经网络模型不断涌现。如Alex Graves等基于深度循环神经网络(recurrent neural network,RNN)模型和连接时序分类(connectionist temporal classification,CTC)算法分别在TIMIT语料库和WSJ语料库上取得了目前最优的音素和单词识别率[10-11];William Song等基于深度卷积神经网络(convolutional neural network,CNN)模型和CTC算法构建声学模型,其训练效率相较Alex的RNN-CTC模型有大幅提升,而在TIMIT上取得的音素识别率仅略低于Alex的模型[12]。在工业界,百度、科大讯飞等知名IT企业相继报道了各自基于RNN和CTC模型构建的中文语音识别系统框架。以上成果说明,深度RNN模型和CTC算法在英文和中文语音处理技术上的卓越性能已经在学术界和工业界得到验证。然而受制于藏语语料资源匮乏及研究基础薄弱等问题,深度RNN模型在藏语语音识别上的应用尚未得到深入探索,目前也未见到相关的公开报道。因此,本文结合藏语语音的特点,研究将RNN应用于藏语语音识别声学建模的方法,结合RNN和CTC构建端到端的声学模型以验证RNN模型应用于藏语语音识别的可行性。同时本文根据藏语语音识别声学模型的特点,引入时域卷积方法对网络结构进行优化,在识别性能相当的情况下有效提高了模型的训练和解码速度,这也是本文最主要的创新点。实验结果显示,基于RNN和CTC的端到端声学模型在藏语拉萨话音素识别任务上的性能要优于传统的GMM-HMM模型,而引入时域卷积约简优化的声学模型在具有同等识别性能的条件下,还具有更高的训练速度和解码效率。
1 基于RNN的端到端声学模型
1.1 循环神经网络模型
RNN是一种隐含层具有自连接关系的深层神经网络,隐含层的自连接特性使其对序列数据上下文依赖关系具有天然的描述能力,是建模序列数据的有效方法[13],其基本架构如图1所示。

图1 RNN的结构特点
RNN输入层表示样本的输入特征,输入层神经元个数即输入数据特征维数。输入特征经加权求和后进入中间的隐含层;隐含层具有自连接特性,其输入由输入层和上一时刻该隐含层的输出共同构成,经激活函数激活后进入输出层及下一时刻的隐含层。如果将多个隐含层进行堆叠,即可构成深层的RNN模型。RNN的输出层是一个分类层,其中的每个神经元代表一个类别,每个神经元的输出值表示输入样本属于该类别的后验条件概率。不难看出,RNN实际上是一个包含特征、空间及时间的三维网络,其中时间维度上的展开步数等于输入序列的长度,但任意时刻网络的权值是恒定的。数据进入RNN隐含层的计算过程如式(1)~(2)所示。
其中xt为t时刻的网络输入,H为隐含层激活函数(通常为非线性函数,如sigmoid函数),O代表输出层分类函数(如softmax函数),yt为t时刻网络的输出值。权值Wxh、Whh、Who及偏置项bh、bo是需要通过训练来优化的网络参数。
RNN通常采用基于梯度的训练方法,由于时域展开步数较长,梯度在回传过程中通常存在逐渐消失问题,因而在实际应用中普通RNN无法捕获时序数据内部的长距离依赖关系[14]。长短时记忆单元(long-Short term memory,LSTM)是RNN的一种变体,其在神经元内部加入三个门函数和一个存储单元,从而能够有效地控制神经元的输入、存储及输出[15],其内部结构如图2所示。

图2 LSTM的结构特点
LSTM神经元的输入与输出关系可以通过式(3)~(7)表示。
其中σ为激活函数,i、f、o及c分别对应输入门、忘记门、输出门及存储单元。由于门函数和存储元的存在,LSTM网络能够实现对输入信息流的控制,缓解训练过程中的梯度消失问题。另外,传统RNN是单向展开,因此只能利用历史信息,而语音识别是对整个序列的转写,当前语音帧后面的上下文信息对当前帧也有影响,因此双向RNN(Bi-RNN,Bidirectional RNN)通过两个独立的隐含层来处理前向和后向数据,之后同时进入输出层,可有效解决该问题。双向RNN隐含层的网络结构如图3所示。

图3 双向RNN隐含层的网络结构
双向RNN隐含层的计算过程如式(8)所示。
(8)
将双向RNN与LSTM单元相结合就构双向LSTM网络(Bi-LSTM,Bidirectional-LSTM),再堆叠多个Bi-LSTM层即可构成深层的Bi-LSTM网络,从而充分利用上下文时序信息进行语音识别建模。
1.2 CTC训练与解码
CTC通过对目标序列和输入序列的对齐分布进行建模[16],免去了人工实现的单个声学基元与语音学目标基元的对齐操作,从而实现端到端的声学模型训练。CTC基于softmax分类层实现,该分类层包含所有的类别节点和一个空节点,其中空节点对应空格输出。对于一个长度为T的输入序列x,网络在t时刻输出目标类别k(含空节点输出)的概率值可表示为式(9)。
(9)

(10)
对于目标序列y,可以有多个CTC输出序列π与之对应。例如,当输入序列长度为6而对应目标序列为(a,b,c)时,相应的CTC输出序列可以是(a,_,b,c,c,_)或(_,a,a,_b,c)等。因此有式(11)的对应关系。
(11)
其中β是从π到y的映射,该映射先合并相邻重复出现的类,再去除空类。上式可通过动态规划算法计算并且求导。在给定输入序列x及对应目标序列y*的情况下,CTC训练的最终目标是让网络输出y*的概率最大化,也即概率的负对数值最小化,因此设定目标函数如式(12)所示。
CTC(x)=-logPr(y*|x)
(12)
经过训练之后的网络即可应用于语音样本的预测,CTC最终输出一个T行N列的概率矩阵,其中T为输入序列长度,N为分类器的类别数,该矩阵可采用定向搜索算法来找出概率最大的音素序列。
2 引入时域卷积的RNN声学模型
RNN模型的复杂度主要由网络隐含层神经元个数、纵向深度和横向展开步数决定,其中纵向深度就是堆叠的隐含层个数。隐含层的神经元个数及堆叠的隐含层数决定了模型对输入数据高层特征的抽象能力,神经元个数越多,堆叠层数越多,特征提取能力越强,这已经在实验中得到广泛的验证。隐含层的横向展开步数是网络训练与解码的重要影响因素。传统RNN-CTC模型,各隐含层横向展开步数等于输入序列的长度,最终的CTC输出序列也与输入序列等长。这种结构理论上完整保留了序列的上下文依赖关系,却也带来了网络训练时梯度回传慢、梯度易消失等问题。同时针对CTC输出通常使用定向搜索算法进行解码,其搜索空间大小与输出序列的长度呈指数增长关系,因此网络输出序列长度也是影响语音解码效率的重要因素。从藏语语音识别的声学模型来看,输入的语音帧与其目标序列中所对应的语音学基元(如音素)是多对一的关系,即多个连续语音帧对应着同一个藏语音素,因此本文提出引入时域卷积的循环神经网络模型RNN-TimeConv-CTC,即在循环神经网络隐含层的输出序列之上进行时域的卷积操作,以期在不影响识别率的前提下,逐层减少网络隐含层的时域展开步数,从而简化网络结构,加速网络训练与解码,其结构如图4所示。

图4 引入时域卷积的RNN隐含层
图中h1为多层RNN中的一个隐含层,h2为相邻的下一个隐含层,对应的下标为时域的展开步。相邻两个隐含层的计算过程如式(13)所示。
(13)
其中win为时域卷积的窗口宽度(图4中值为3),stride为相邻两个卷积操作的时间跨度(图4中值为2),Wi为时域共享的权值,是需要训练的参数。引入时域卷积的RNN,其相邻隐含层的时域展开步数将不再相同,而是存在一定的比例关系,该比例关系由stride的大小决定。假设l层的时域展开步数为Tl,则相邻的l+1层时域展开步数如式(14)所示。
(14)
3 实验和结果分析
为验证基于RNN-CTC的藏语语音识别声学模型的可行性和优越性,本文设置GMM-HMM模型作为基准参考模型,采用已经在TIMIT语料库上得到验证的深层Bi-LSTM-CTC模型作为测试模型,同时基于该模型设置时域卷积层,构建RNN-TimeConv-CTC模型以验证引入时域卷积的深层RNN模型在藏语语音识别上的高效性。测试模型的整体架构如图5所示。
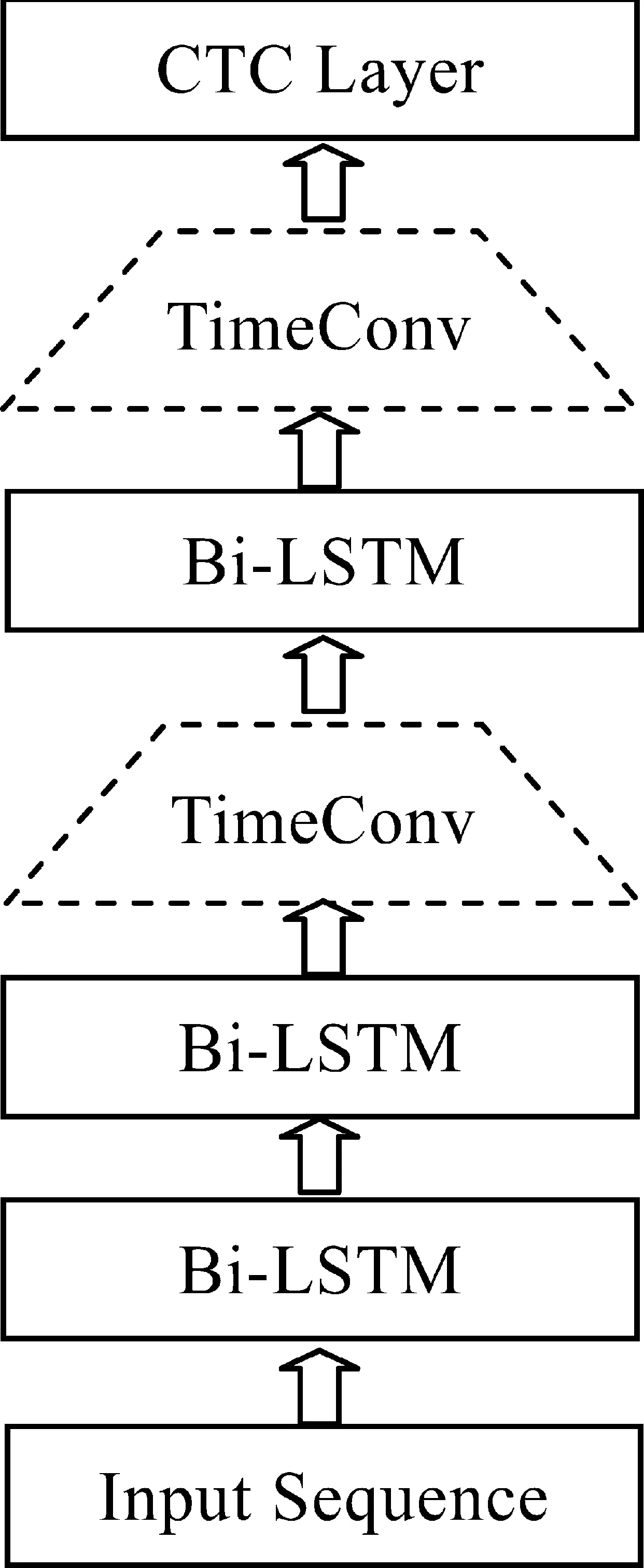
图5 藏语语音识别声学模型架构
为保证所有模型训练环境的一致性,本文所有实验全部在安装Linux操作系统的同一台高性能服务器上完成,并基于Google开源深度学习库Tensorflow构建神经网络模型进行训练与测试,同时配置NVIDIA的GPU卡进行加速。
3.1 语音语料库
实验所用藏语语音库为解放军外国语学院自建的藏语拉萨话语音语料库,其中语音数据采用单通道16kHz采样,16位PCM量化,存储为wav格式,共计49.6h语音数据。所选语料来源于藏语教学过程中使用的录音广播、阅读教材、新闻摘要及口语练习材料,共包含3 160个音素覆盖平衡的藏文语句。录音文件由16名说话者分别朗读产生。由于藏语为音素拼音型语言,即由音素组合构成声母和韵母形成半音节,再由声韵母组合加上音调构成一个音节。因此,音素是藏语语音学上的最小发音基元,基于藏语音素进行声学建模是目前典型的建模方法。根据对藏语语音学的深入研究和统计分析,本文所用语料库共设置了41个音素标注基元,其中辅音音素28个,元音音素13个,所有音素的拉丁转写和国际音标如表1所示。

表1 拉萨话语音语料库音素单元集
基于以上语音库,实验首先对所有语音序列进行预处理操作,包括预加重、分帧(帧长25 ms、帧移10 ms)及加窗(汉明窗),进而对每帧语音数据提取12维MFCC加对数能量,以及对应的一阶、二阶差分,共39维特征参数。实验过程中,本文选取部分录音文件作为验证集和测试集,其余作为训练集,其中验证集和测试集对所有的音素都有均衡的覆盖。最终产生的验证集包含3.4h的语音数据,测试集包含2.5h的语音数据。
3.2 RNN-CTC模型
实验设置GMM-HMM模型作为基准参考模型,对41个藏语音素、静音段及停顿进行建模,其中音素和静音段采用三状态HMM,停顿采用单状态HMM。HMM中的每个状态都使用25个独立的高斯分量,基于最大似然估计法进行训练。RNN-CTC模型采用深度Bi-LSTM-CTC模型(架构如图5实线矩形框所示),采用三个双向隐含层堆叠,每个隐含层两个方向各包含512个节点,最后一个隐含层两个方向同一时刻的输出通过加权求和转换为一个512维输出向量,进入CTC分类层。CTC分类层包含42个类别节点,分别对应41个音素和一个空输出。隐含层神经元设置为Sigmoid型,采用随机梯度下降算法训练网络,训练时样本序列Minibatch设为512,学习率设为0.001,以CTC解码序列和目标序列的Levenshtein编辑距离作为差异度量,并将其与真实音素序列长度的比值作为衡量识别准确度的指标,记为PER(phone error rate)。显然,PER越小则识别结果越准确,模型越好,反之则识别结果越差,模型越不好。表2列出了GMM-HMM和Bi-LSTM-CTC模型的性能对比。

表2 不同模型的识别性能对比
可以看出,相较GMM-HMM模型35.24%的音素错误率,Bi-LSTM-CTC模型的性能有显著提高,PER下降到了26.31%,证明了Bi-LSTM-CTC模型在藏语语音识别声学建模上的优越性能。通过分析不难发现,之所以有如此显著的性能提升,主要得益于深层RNN对语音序列时序依赖关系的建模,以及CTC算法对序列学习过程的建模。RNN隐含层的自连接关系可以建模藏语语音的时序关联关系,而Bi-RNN使未来的时序信息也能得到利用,从而实现语音序列上下文关系的完整建模。同时,LSTM单元能够缓解模型训练过程中的梯度消失问题,从而使整个网络模型能够最大程度的利用藏语语音序列的上下文信息对当前输入进行分类。相比之下,GMM-HMM基于一阶隐马尔可夫假设对语音信号进行建模,只能利用极其有限的历史信息,并且对未来信息没有任何考虑,因此对语音序列上下文信息的捕捉能力很弱,其识别性能自然较差。另外,基于GMM-HMM的建模方法要求输入序列中的每个特征向量都有一个对应的目标类,即要为训练集中的每个语音帧标注一个语音学音素状态,该过程通常需人工辨听切分才能完成。然而由于真实藏语语音序列的时变特性及音素协同发音现象的普遍存在,语音帧与音素的对齐关系具有较大的不确定性,人工标记方法必然会引入噪声,因而在真实应用中单个语音帧识别精度的提高并没有带来整个语音序列识别率同等程度的提高。CTC通过对目标序列与输入序列的对齐关系分布进行建模,直接从序列到序列进行训练,有效避免了人工对齐可能引入的标记噪声,从而实现端到端的识别,更加符合语音识别的真实过程,因而能够带来整个音素序列识别率的提升。
3.3 RNN-TimeConv-CTC模型
引入时域卷积的RNN-TimeConv-CTC模型以3.2节中的Bi-LSTM-CTC模型为基准模型(记做Bi-LSTM-TC-CTC),在其第二和第三隐含层的输出序列(同一时刻两个方向加权求和得到)上进行时域卷积操作(如图5虚线梯型框所示),卷积窗口宽度win设为5,卷积时间跨度stride设为2,网络初始权重、训练方法、Minibatch大小、学习率等训练参数都与基准模型的训练参数相同,最终的训练和测试结果如表3所示。

表3 不同模型的训练和测试性能对比
从实验结果可以看出,引入时域卷积的Bi-LSTM-TC-CTC模型,在模型收敛时的迭代次数较基准模型Bi-LSTM-CTC下降了近100次,其训练速度得到明显提升,而两者在验证集和测试集上的识别性能并无明显差别,说明两者对训练数据的拟合能力是相当的。
通过分析实验结果和网络结构的不同不难发现,Bi-LSTM-TC-CTC模型训练效率的提升主要归因于时域卷积操作的引入。时域卷积操作使Bi-LSTM网络第三个隐含层的时域展开步数和输出序列的长度分别约简到原始网络模型的1/2 和1/4,大大减少了网络训练过程中梯度计算的回传距离,从而有效加快了训练速度。回传距离的减少,还使梯度消失问题得以缓解,从而使每轮迭代产生的参数更新更加有效,因而使用较少的迭代次数就能使模型达到最优的状态。同时,由于时域卷积操作针对连续的五个输入向量进行特征抽象,能够捕获近距离内的时序关联关系,从而弥补了隐含层因跨步展开可能带来的时序建模能力下降问题,因而在降低网络复杂度的同时仍然能够保证模型总体识别性能的稳定。另外,在本实验中,CTC输出序列的长度也约简到了普通网络输出序列长度的四分之一,对于音素识别解码时所用的定向搜索解码算法来讲,其搜索空间的复杂度从搜索宽度的T次方下降到了T/4次方,整个模型的解码速度自然也会得到明显提升。
时域卷积时间跨度值stride是RNN-TC-CTC模型区别与传统RNN模型的重要参数,为了验证stride设置对模型训练以及测试性能的影响,本文以表3中的三层Bi-LSTM-TC-CTC模型为基准,以网络第3个隐含层的时域卷积stride值为变量,分别考查了6种stride值下的模型训练迭代次数Iterations和测试集上的PER值,如图6所示。

图6 卷积跨度stride对模型的影响
可以看出,当stride值小于等于3时,训练迭代次数下降明显,但测试集PER值相对稳定,与基准Bi-LSTM-CTC模型基本相当;而当stride大于3时,训练迭代次数开始稳定,但测试集PER值却急剧上升。
以上现象主要是由输入藏语语音特征与目标音素之间的多对一映射关系所导致的。就藏语语音的发音来讲,通常一个藏语音素的声学发音会包含6~10个语音帧,也就是说输入网络的几个连续语音帧通常可能对应着同一个音素。传统基于深层RNN的网络模型,其每个隐含层的时域展开步数都等于输入序列的长度,最终的输出序列长度也等于输入序列长度。实际上是为每个输入特征预测了一个类别,其中同一个类别会连续出现多次,而在解码时这些连续出现的相同类别会被合并为一个预测基元。经过时域卷积之后,上层的网络时域展开步数会减少,而减少的比例正是由stride值决定的。因此在相同的初始条件下,stride值越大,网络约简越多,模型越简单,在网络初始参数相同的情况下,训练过程中的收敛速度就可能越快。但是约简的比例不能过高(如图6中stride为3时,约简的比例已达到6∶1),否则可能因映射关系过度简化而造成网络模型拟合数据分布能力不足,识别性能就会出现下降。因此合理的设置stride值才能保证在模型识别性能不变的情况,加速网络的训练和解码。
综合理论分析和实验结果可以看出,对于藏语语音识别声学建模任务来讲,基于深度Bi-LSTM-CTC的声学模型要优于传统基于GMM-HMM的模型,而引入时域卷积操作的Bi-LSTM-TC-CTC模型,只要合理的设置stride值,就能够在保持相同识别性能的前提下获得更高的训练和解码效率。
4 总结与展望
本文研究了基于深度RNN的藏语语音识别声学建模问题,验证了Bi-LSTM-CTC模型应用于藏语语音声学建模的可行性,并与传统基于GMM-HMM的声学模型进行了对比,验证了其高效性。同时,针对深度RNN-CTC模型训练和解码时受时域展开步长影响较大的问题,提出引入时域卷积操作的RNN-TimeConv-CTC模型,在保证原有识别率的前提下,有效约简了网络的时域展开步长,提高了模型的训练和解码效率。需要说明的是,本文所做实验是在自录数据集上的初步结果,所选藏文音素标注基元的稳定性还有待进一步的验证。另外,本文只是验证了基于深层RNN的藏语语音识别声学模型,如何基于该模型构建完整的藏语语音识别系统也是本文后续研究工作的重点。
[1] 于洪志,高璐,李永宏,等.藏语机读音标SAMPA_ST的设计[J].中文信息学报,2012,26(4): 65-72.
[2] 陈小莹,艾金勇,于洪志.藏语拉萨话单音节噪音声学参数分析[J].中文信息学报,2015,29(3): 184-189.
[3] 德庆卓玛.藏语语音识别研究综述[J].西藏大学学报, 2010, 25(S1): 192-195.
[4] 姚徐,李永宏,单广荣.藏语孤立词语音识别系统研究[J].西北民族大学学报(自然科学版),2009,30(1): 29-36,50.
[5] 杨阳蕊,李永宏,于宏志.基于半音节的藏语连续语音语料库设计[C]. 第十届全国人机语音通讯学术会议暨国际语音语言处理研讨会. 乌鲁木齐: 新疆师范大学出版社,2009: 380-383.
[6] 李冠宇,孟猛.藏语拉萨话大词表连续语音识别声学模型研究[J].计算机工程,2012,38(5): 189-191.
[7] 戴礼荣,张仕良.深度语音信号与信息处理: 研究进展与展望[J].数据采集与处理,2014,29(2): 171-178.
[8] 王辉,赵悦,刘晓凤.基于深度特征学习的藏语语音识别[J].东北师大学报(自然科学版),2015,47(4): 69-73.
[9] 袁胜龙,郭武,戴礼荣.基于深层神经网络的藏语识别[J].模式识别与人工智能,2015,28(3): 209-213.
[10] Graves A, Mohamed A,Hinton G. Speech recognition with deep recurrent neural networks[C]//Proceedings of ICASSP, 2013: 6645-6649.
[11] Alex Graves,Navdeep Jaitly. Towards end-to-end speech recognition with recurrent neural networks[C]//Proceedings of the 31st International Conference on Machine Learning(ICML-14),2014: 1764-1772.
[12] Song W, Cai J. End-to-end deep neural network for automatic speech recognition[R]. Technical Report CS224D, University of Stanford, 2015.
[13] Hochreiter Sepp, Schmidhuber Jurgen. Long short-term memory[J]. Neural Computation.1997, 9(8): 1735-1780.
[14] Yoshua Bengio, Patrice Simard, Paolo Frasconi. Learning long-term dependencies with gradient descent is difficult[J]. IEEE Transactions on Neural Networks.1994,5(2): 157-166.
[15] Sak H,Vinyals O,Heigold G. Sequence discriminative distributed training of long short-term memory recurrent neural networks[C]//Proceedings of the Interspeech.2014: 1209-1213.
[16] Alex Graves, Santiago Ferna′ndez, Jurgen Schmidhuber. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks[C]//Proceedings of the 23rd International Conference on Machine Learning,ACM,2006: 369-376.
猜你喜欢
客联(2022年2期)2022-04-29
西藏研究(2021年1期)2021-06-09
北京教育·普教版(2020年9期)2020-10-09
家庭影院技术(2020年6期)2020-07-27
校园英语·中旬(2019年11期)2019-11-26
广西教育·D版(2019年6期)2019-07-11
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年10期)2018-11-02
速读·中旬(2018年8期)2018-10-23
