
基于深度学习的人脸表情特征分析
2018-06-13 07:52余锐
现代计算机 2018年13期
余锐
(重庆大学计算机学院,重庆 400044)
0 引言
人脸表情(Facial Expression)承载着人与人之间信息交流据。心里学家A.Mehrabian[1]的研究发现,在人类日常生活中,人脸表情所传递的信息量约战整个信息总量的55%,因此,近些年来对于人脸表情图像识别的研究也是比较热门,尤其是对人脸表情特征分析进行归类的人脸表情识别成为人机交互、计算情感、智能控制、机器视觉、图像处理及设计模式等领域的重要研究课题。
我们已熟知的传统人脸表情识别算法很大一部分集中在基于传统的图像处理相关技术,主要基于三步进行实现,特征提取、特征选择、分类器构建来完成识别,可参考朱健翔的基于Gabor特征与AdaBoost人脸表情识别[2],其中特征提取阶段主要目的是能够提取出能够更好地进行面部表情分析的特征,目前比较成熟的技术包括Gabor小波特征[3-4]和AAM[5],而特征选择主要集中在高纬度特征向量下降低维度数,可以很大降低存储量与计算量,其中包括PCA降维和AdaBoost算法。最后分类器构建则有着相对多的方法,其中主要运用到了模式识别中相关技术,包括了基于概率模型的方法,基于支持向量机SVM、基于神经网络的方法模型传统人脸表情识别流程如图1所示。
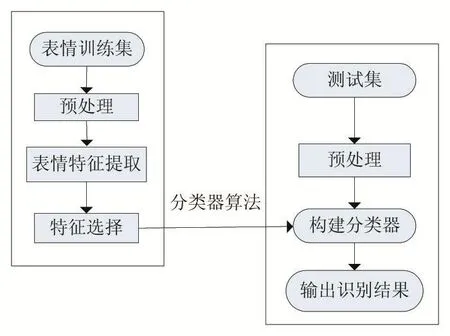
图1 传统表情识别流程图
本文所采用的是深度学习技术来进行分脸表情特征分析,有别于之前的神经网络作为分类器算法,神经网络可划归浅层的网络分类器模型中,而深度学习在图像识别分类这一块主要是让机器自动从大量数据的样本中通过深层次的网络多通道维度学习,使得其能够在训练好的模型中体现出泛化表征性。
1 深度学习和图像识别
深度学习是一门综合性的研究领域,其基础融合线性代数、微积分、概率论统计等学科,同样也是机器学习非监督学习领域下的一个分支,由于其在包括图像识别语音识别及机器翻译等多方面表现出卓越的效果而流行起来,2006年,神经网络之父Hinton和他学生在顶尖学术刊物Science发表了一篇使用深层结构的神经网络模型实现数据降维的论文[6],主要通过无监督预训练对权值初始化和有监督训练微调来解决了深层网络训练中梯度消失问题,由此开启了深度学习在学术界和工业界的浪潮。在图像识别领域一项大赛ImageNet中,广泛的图像识别技术通常采用了图像处理与模式识别相关方法,必须借助SIFT、HoG等算法提取出良好区分性的特征,再结合SVM等机器学习算法进行图像识别。
深度学习有别于普通神经网络模型,其实质就是对具有深层次结构进行建模的方法统称。深层结构主要针对浅层网络而言(隐藏层数大于2),目前常见的模型与架构包括CNN、DBN、RNN、自动编码器、GAN等,而其中CNN在图像识别问题上表现出其强劲的性能。
2 数据集选择和模型设计
2.1 数据集选择
人脸表情特征分析技术已经发展了近30年,而数据集也随着研究的进行不断推进着,起初日本人脸表情数据集JAFFE是一个样本量不大而又经典的数据集,在前期的人脸表情识别的研究大多数采用了该数据集,整个数据库共213张图像、共10人,全部是女性,每个人对应表情分为 7种:sad、angry、disgust、fear、neutral;而后面的CK+人脸表情数据集合是在Cohn-Kanade Dataset[7]的基础上扩充来的,发布于2010年,该数据集比JAFFE数据集要大很多,其中包含了表情的label和Action units的label,在后期很多人脸表情分析相关的研究都是在该数据下进行,而在作为机器学习竞赛Kaggle用到的数据集FER2013(Facial Expression Recognition 2013)在后期的科研中也多次被运用。
主要是其满足了两大实验基本要求,首先,图片数据集中已经最好保留下了人脸正中的位置,而无需在进行人脸部门的赛选,其次拥有者足够的样本量够模型的训练,而本文中所用的数据集是基于JAFFE人脸表情数据集的扩充集Jaffe+来更加丰富网路训练模型。JAFFE+数据库如图2所示。

图2 JAFFE+人脸表情数据库
2.2 模型设计
本文之前也描述CNN网络模型的基本结构,这里针对本文的实验来作出更详细的分析。CNN是一种采用反向传播算法的前馈式的神经网络,其基本由下面几个层组成:卷积层、池化层、全连接层、Softmax层。
卷积层即做卷积操作,这一层也是整个CNN模型中至关重要的一步操作,卷积层主要是将网络里的划分的更小块来进行深入分析而得到抽象程度更高的图像特性[8]。卷积层的操作的三个关键特点就是局部感知、参数共享以及多核卷积,局部感知就是避免传统神经网络中每个神经元都与图像中每个像素点连接,而采用卷积核中大小,避免造成权重数量巨大;参数共享保证图像中不同位置相同目标他们的特征是一致的;多核卷积能是每个卷积核学习不同特征从而提取出原始图中的特征。卷积层的计算公式可表示为:
其中x[m ,n]表示输入信号,h[m ,n]表示卷积核函数,在通过卷积运算后会进行激活函数运算q(∙),相比于之前通常采用的sigmoid或tanh,后更多采用能展示稀疏性的 ReLU(Rectified Linear Units)函数[9]。ReLU函数表示为:
θ(x)=max(0,x)
相关实验表明ReLU函数不仅展现出性能上的稀疏特性,而且能够消除神经网络反向传播优化参数方面可能出现的梯度消失问题。
下采样pooling层(池化层)的主要作用就是降低经过卷积处理后图像的高维度问题,如果直接将多层卷积后的特征去进行分类器训练,必然会造成维度灾难的问题[11],同时也能够有效避免过拟合情况的发生。池化层主要由两种方式:MaxPooling与Mean Pooling,通常一般没特殊注明情况下就采用MaxPooling即获取窗口内的最大值保留下来,同时也能够去除一些哨声信息的目的。以Tensorflow为例,其中该操作如下:
max_pooling2d(inputs,pool_size,strides,padding='valid',data_format='channels_last',name=None)
其中参数inputs表示tensor张量,pooli_size滑动窗口尺寸,stride代表补偿,padding表示以何种方式处理图像边缘区域,通常选择填充0的方式,name代表这一层的名称。
全连接层是将对后池化层每个特征图从二维数组转化成一维,作为全连接层的输入。每个神经元的输出为:
tw,b(x)=θ(wTx+b)
tw,b(x)表示神经元的输出值;wT表示权值特征向量的转置;x表示输入特征向量;b表示偏置;同样θ代表激活函数这里同样采用了ReLU函数。最后的Softmax即分类层,这里采用的概率投票竞争的方式,最后的每个输出神经元输出会在0~1范围间表示各自输出的概率,最后会选取输出概率最大的作为最后的分类。
网络模型训练阶段,这里参考Lenet-5模型,后期大部分网络模型都集中在网络层深度的增加,具体训练的网络模型结构如下,输入为由原始的255×255的图像经过图像压缩成32×32维度更小也同样汇聚了原始特征的图像,这些人脸表情图像包含了0~6种人脸表情特征,集对应于7种表情类别;输出即为0~6种的一种表情类别;C1层选取了32个filter即具有不同卷积核的过滤器,其中窗口大小为二维的5×5,步长采用了1,padding方式采用了same使得图像卷积后输出的大小保持不变,尽可能维持原始尺寸,针对这步操作需要在外围补2圈零操,在没特殊说明的情况下都是采用ReLU作为激活函数;polling下采样层采用filter为2×2,strides为2的操作MaxPooling操作;针对第二层卷积增加了一倍数量的filter64个,而后的pooling操作同上一步一样,最后做扁平化flatten操作,后面全连接,全连接层激活了1024个神经元,最后采用Softmax作为分类器函数。在数据样本不足的情况下通常会出现overfitting(过拟合)情况出现,之前的data augmentation操作就防止了过拟合,同样CNN实验中采用了dropout策略[10]来解决过拟合问题。
3 实验
本次实验中所采用的数据集来自Jaffe表情数据库中,总共213张图像,其中一共包含了10个人,每个人对应着由7种表情,每个人特种表情下有4张图像,针对样本数据量少的情况下符合传统的图像分类模式,显然基于深度学习模式下的样本数据量不足,这里在实验前期对原始的样本数据量基础上进行了data augmentation(数据增强),数据增强有着较多的方式,在深度学习中AG Howard曾在论文[11]对数据增强对深度学习整个模型训练的好处做出详细论述。这里结合到之前的一些方法采用了以下方式来实现:旋转、裁剪平移、仿射变换以及加入一些高斯噪点,将之前的总共213张图片扩充到了5323张,具体做法是针对仿射变换扩增了5倍样本量,对图像旋转平移也分别扩增了5倍,针对于噪点共扩充了10倍(分别采用了随机白噪声点、加性零均值高斯噪声),扩充后的数据集称为Jaffe+。
同样由于Jaffe数据集中是在特定的实验环境中进行的数据采集,不同光照条件下可能会对特定的人脸特征产生干扰,Jaffe+也同样受影响,于是光照归一化处理对于人脸表情特征分析中也是不可缺少的一步,这里主要就集中在采用何种光照归一化的处理算法上。相关研究中也提供了各式的方法,例如基于二次多项式模型的人脸归一化[12],基于形态学商图像的光照归一化,基于小波变换的人脸归一化等,各式的算法运用的场景也有着特定的环境,而针对于Jaffe数据集,经过实验发现采用均值方差归一化的处理就能达到目的。以下就是采用了均值方差归一化消除光照处理后的对比,如图3所示。
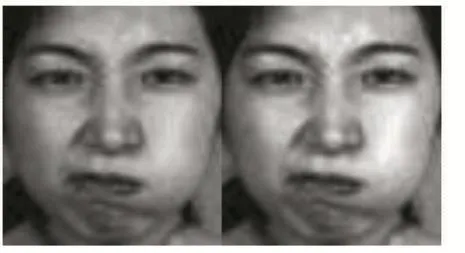
图3 消除光照影响前后对比
经过了前期的对Jaffe+数据集的图像进行预处理后,数据集测试集、训练集比例1:6,参考上一章节训练好的网络模型进行实验,在对比实验中我们采用了基于Gabor特征提取,随后进行PCA降维处理,再进行SVM分类器来实现人脸表情识别别,其中Gabor滤波器组采用包含4个尺度,6个方向的滤波器组,SVM采用了“one-vs-one”的策略[13],内核函数采用 RBF核,同样实验也对基于KNN分类器、MLP(多层神经网络)进行了实验比较,实验结果如表1所示。
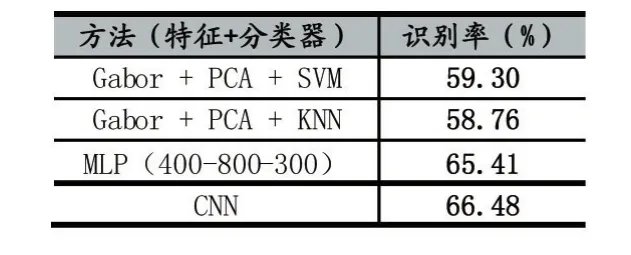
表1 不同算法在Jaffe+上的识别准确率对比
由实验结果知CNN相比于之前的传统用于识别的策略相比,在整体数据集上识别率提高了8%,传统模型中所采用的方式相对复杂,而CNN将之前的特征提取以及降维处理都集中在一起。结合CNN在人脸表情7分类识别过程中的混淆矩阵,可以看出多种类表情易被误识别成惊讶,对整个厌恶和中性表情的识别率较低,结果所表2所示。
4 结语
本文提出了基于深度学习下的人脸表情特征分析,该方式相比于传统的人脸表情识别有所改进。主要是减少了前期对图像的预处理以及人工的进行降维处理,相比于人脸表情识别不是如手写体数字识别那么准确率高,主要是其图像包含着更复杂纹理信息,其中主要体现在各个面部器官之间的复杂关系以及人脸表情在特定环境下采集的与实验环境相关的误差,实验结果也显示出该方法有着较高的识别率和泛化的特性,后期工作中还会对整个CNN网络层与层之间的关系进行深入研究分析,包括可能从分类器入手或者采取更优的策略才优化整个CNN网络结构,从而进一步来提高整个数据集下人脸表情的识别率。

表2 CNN识别混淆矩阵
[1]Mehrabian A,Russell J A.An Approach to Environmental Psychology[M].Cambridge:MITPress,1974.
[2]朱健翔,苏光大,李迎春.结合Gabor特征与Adaboost的人脸表情识别[J].光电子·激光,2006,17(8):993-998.
[3]Lyons M,Akamatsu S,Kamachi M,et al.Coding Facial Expressions with Gabor Wavelets[C].Automatic Face and Gesture Recognition,1998.Proceedings.Third IEEE International Conference on.IEEE,1998:200-205.
[4]Lyons M J,Budynek J,Akamatsu S.Automatic Classifica2tion of Single Facial Images[J].IEEE Transactions on Pat2 tern Analysis and Machine Intelligence,1999,21(12):135721362.
[5]王李冬,王玉槐.基于AAM模型和RS-SVM的人脸识别研究[J].计算机工程与应用.
[6]Hinton G E,Salakhutdinov R R.Reducing the Dimensionality of Data with Neural Networks[J].Science,2006,313(5786):504-507.
[7]Lucey P,Cohn J F,Kanade T,et al.The Extended Cohn-Kanade Dataset(CK+):A Complete Dataset for Action Unit and Emotion-Specified Expression[C].Computer Vision and Pattern Recognition Workshops(CVPRW),2010 IEEE Computer Society Conference on.IEEE,2010:94-101.
[8]Simonyan K,Zisserman A.Very Deep Convolutional Networks for Large-Scale Image Recognition[J].arXiv Preprint arXiv:1409.1556,2014.
[9]Nair V,Hinton G E.Rectified Linear Units Improve Restricted Boltzmann Machines[C].Proceedings of the 27th International Conference on Machine Learning(ICML-10),2010:807-814.
[10]Srivastava N,Hinton G,Krizhevsky A,et al.Dropout:A Simple Way to Prevent Neural Networks from Overfitting[J].The Journal of Machine Learning Research,2014,15(1):1929-1958.
[11]Howard A G.Some Improvements on Deep Convolutional Neural Network Based Image Classification[J].Computer Science,2013.
[12]谢晓华,赖剑煌,郑伟诗.基于二次多项式模型的人脸光照归一化[J].电子学报,2010,38(8):1791-1797.
[13]Duan K B,Keerthi S S.Which is the Best Multiclass SVM Method?An Empirical Study[C].International Workshop on Multiple Classifier Systems.Springer,Berlin,Heidelberg,2005:278-285.
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
中国交通信息化(2022年2期)2022-04-26
电子产品世界(2022年4期)2022-04-21
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
计算机系统应用(2021年2期)2021-02-23
电子制作(2019年16期)2019-09-27
计算机测量与控制(2019年4期)2019-05-08
中国信息技术教育(2016年21期)2016-12-05
