
基于神经网络的网上商店商品排版分析
2018-06-13 07:52陈国凯
现代计算机 2018年13期
陈国凯
(重庆大学计算机学院,重庆 400044)
0 引言
随着互联网的高速发展,人们的生活越来越依赖于网络,人们最基本的衣食住行都已经与网络紧密关联。基于此,网上购物越来越主流化,网商也越来越盛行,并逐渐成为新兴产业的中坚力量。但商品种类的多样化,使得网商的推荐信息变得越来越重要,导致推荐系统的研究逐渐成为一类研究课题。
至今,各种各样的推荐系统层出不穷,包括基于内容的推荐原理,关联推荐、协同过滤算法、混合推荐等,这一类的商品推荐系统一般是站在用户的角度,通过用户的浏览记录或者是商品的浏览量等,以用户的体验等,来推荐更能够让用户满意的商品,但鲜有站在网商的角度来分析的。
本文致力于通过对往届销售数据的分析,站在网商的角度,通过获利的情况,来实现对商品价值的预测分析,以及对商品的推荐功能。通常情况下,一种商品的实际获利,不仅仅是出价、进价还有销售数量的简单运算,可能还有其他的一些因素的干扰。而一件商品的属性值有很多种,不可能都拿过来作为模型的输入来分析,并且很多属性是完全对利润没有影响的,还有一些属性对利润的影响很小,小到可以忽略不计,故而需要对属性进行约简。
粗糙集理论是一种刻画不完整性、不确定性的数学分析工具。影响利润的因素有很多,利用粗糙集理论对影响的因素进行约简,得到相对重要的一些因素。但是,传统的聚类,只有聚类,没有关于各个因素的重要性的因子。而实际上,不同的因素,造成的影响不同,应该赋予不同的权值系数。
基于此,本文提出了如下方法:利用粗糙集对影响商品的多种因素进行属性约简,得到优化后的数据,以及其相关的权值系数,其次采用基于属性重要性的加权欧氏距离对数据分析,建立各个聚类的预测模型,并提取相似性较高的数据作为训练样本,然后对测试数据进行聚类。实验结果表明,该方法具有一定的参考价值。
1 网络信息排名的相关研究
现如今,各种各样的商品信息充斥着人们的眼球,但是如何能够更有效地吸引来自网络上形形色色的消费者,一直是各类人士的一个研究课题。各种各样的推荐系统层出不穷,但是说到为什么要做推荐呢?答案是,信息的展示形式一定程度上影响着人们的决策过程。
Kleinmuntz和Schkade在1993年通过研究发现,信息的展示方式,整体表现出如下三个基本特征:信息表现出来的形式、信息组织形成一个整体的方式以及信息的相关排列顺序。本研究中的商品排版就是根据商品利润的获益大小来进行的商品信息排列。
在如今的大数据背景之下,庞大的商品信息展示在人们的眼前,相较于传统的购物方式,网上购物需求变得更加的迫切。不仅仅是消除了时间和地域的限制,更重要的是消费者从被动的信息接收者变成了主动地信息搜索者。而在信息的浏览过程中,基于用户的固有习惯,对商品的浏览一般是遵循自上而下的顺序,这种展示方式很大程度上影响了用户的行为操作。
很多人和机构针对这个方向进行过一些研究,通过实实在在的数据来说明排名的先后是否对用户的行为有影响。如Russo和Hogarth等人曾先后通过对数据的研究,发现用户的信息处理过程一定程度上受到了排列顺序的影响。而随后,Hogue和Lohse的研究表示,相较于纸质目录,电子目录的排名情况更能引起消费者的关注。
2001年,Infospace曾做过一个统计,根据针对网络用户的调查报告显示,89.8%的用户只记得浏览过的网页首页的内容,而对其他的印象不深。
而Granka曾在2004年针对搜索结果页做过一些相关的实验,其结果表示,人们视线在结果也上停留的时间与搜索结果页的排名呈现正向相关的联系,即相关搜索的排序显示越靠前,得到的搜索者的关注力度则会显得越高。
Baye等人在2008年通过对赞助商列表的研究,发现其中商家链接的排列位置对点击率有着很大的影响。商家链接的位置排名每下降一位,与其相关的点击率便会跟着降低17.5%。
综上所述,我们认为,信息的呈现影响着用户的行为。人们习惯于浏览信息时自上而下,商品排版越靠前,消费者的关注度会越高。
2 粗糙集理论
2.1 粗糙集理论简介
粗糙集理论作为一种处理模糊的不确定知识的数学工具,是在1982年,由著名的波兰数学家Z.Pawlak
所创立。它创建的目的就是直接进行数据的分析处理,找到数据背后隐藏的知识和规律。得益于成熟的数学基础和易用性,并且不需要先验知识,使得粗糙集理论成为了处理各种不完备信息的有效工具。整个理论的核心就在于通过等价关系,对对象集合进行划分。在属性约简方面,它可以揭示条件属性对决策属性的重要性,并删除不必要或者不重要的属性。
2.2 QuickReduct约简算法
属性约简,就是通过删除条件属性之中,没有必要或者重要性不高的属性。而具体的评判,就是根据属性的依赖度增量来进行的。本文采用的就是属性约简的一种经典算法,QuickReduct算法。如图1所示,表示的就是该算法的伪代码。主要的一个思路就是通过增加属性,来看依赖度的变化情况,通过依赖度的变化,决定属性的约简与否。
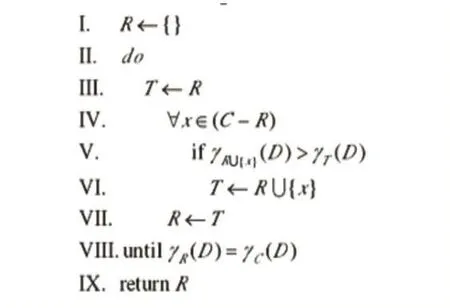
图1 QuickReduct算法伪代码
3 基于属性重要性的加权欧氏距离聚类方法
在研究事物的某些属性时,一般是采用聚类方法将具有较高相似性的进行聚类,来研究其中存在的规律。同样的道理,在分析商品的获利情况时,也可以通过聚类的方式,依据商品利润对商品进行分类处理。而分类的依据,就是不同对象之间的差异性,如何去评价和计算这个差异性,很多前辈为此做出过不少的贡献。一般可用的度量方式有明考斯基距离、欧几里德距离、曼哈顿距离函数等。而最常用的度量则采用的欧氏距离函数,其相关的表达式为:

式中:d(i,j)为对象xi、xj间的欧氏距离;xik、xjk(k=1,2,…,n)分别为对象 xi、xj第k个属性值。
在传统聚类方法中,属性之间,不存在所谓的差异性,都会被看做具有相同的重要性。但相较于实际的生活和应用,很多情况下,这个想法显然是不合适的,现实情况下,不同的对象,表现是不同的,重要性也会有差异。若仍然通过传统的方式来处理,则会出现莫名的问题。对此,我们引入权值系数这一概念来表示属性的重要性指标,来解决重要性不均等的问题。此时,我们用加权的欧氏距离公式来取代传统的欧氏距离,相关表达式如下:

式中wk(k=1,2,…,n)为对象第k个属性的权重。
由公式(2),可以清晰的看到对象的属性所起到的作用。但该方法需要知道各个属性的权重。故而选用了粗糙集的理论来解决这个问题。基于粗糙集的特性,在不知道先验知识的条件下,通过历史数据,能够比较轻松地得到各个属性的权值系数。
4 基于粗糙集与改进聚类的商品排版分析模型
影响商品利润的因素是多方面的,一种商品的实际获利,不仅仅是商品出价、商品进价还有销售数量的简单运算,还有其他的一些因素的干扰。而一件商品的属性值有很多种,不可能都拿过来作为模型的输入来分析,并且很多属性是完全对利润没有影响的,还有一些属性对利润的影响很小,小到可以忽略不计,引入粗糙集利润,对影响因素进行约简,删除一下没有必要或者不重要的因素,其中基于粗糙集的约简算法的步骤如下:
(1)根据以往的商品数据作为模型输入,决策因素为商品利润,其他条件属性有进价、出价、销售数量、销售日期等。
(2)利用QuickReduct算法并结合模糊粗糙集相关理论对可能影响决策利润的属性进行约简,然后计算约简之后,各个条件属性相较于决策属性的重要性。
采用粗糙集对影响商品利润的多种因素进行约简,得到优化后的数据,然后利用基于加权欧氏距离的改进聚类方法对训练样本进行实验,相关的步骤如下:
(1)利用基于属性重要性的加权欧氏距离聚类方法,对数据进行处理和聚类分析,并将其分成k类,使得每一类都具有较高的相似度,并提取其中的簇中心Ci(i表示聚类,取值为 1到 k);
(2)对于上面的k个聚类,分别建立一个神经网络预测模型,然后针对每一类模型,根据各类的历史数据进行训练;
(3)通过计算当前商品与各类簇中心之间的加权欧氏距离,对商品进行分类。
5 案例实验
由于无法拿到网上商店的一些具体数据,本文以某小超市的供销存数据为例,该数据中保留的商品数据包含大类、中类、小类的编码及名称,销售日期、销售数量、商品单价等信息,包含的是2015年1月到4月的商品销售数据。
通过数据进行实验,不同类别的商品,销售情况可能有区别,故而商品的大类编码、中类编码、小类编码都应该作为影响因素。商品的利润可能和时间有关,具体的销售日期和销售月份也应该列为影响因素。然后就是商品的类型,不同的类型,可能对销售利润有影响。其次,对于商品利润来说,影响因素还应该包括表示具体卖出了多少的销售数量,总共卖出了多少钱的销售金额,单件商品的商品单价、商品进价。以商品的销售利润为决策属性,选择上面的10个可能影响商品利润的因素作为条件属性,这样就确定了初始决策表的输入数据。由于拿到的不是实际的网上销售数据,条件属性不是很完全,但该方法,后续可以通过补充的形式来更新决策表。
首先,由于实际拿到的数据很乱,有很多数据表示重复了,需要先进行一下数据的清理工作,例如,商品编码和小类编码,都表示的是同一个意思,没有必要同时存在。然后提取其中的部分数据来进行试验,利用QuickReduct算法,并结合模糊粗糙集的相关知识,对上面的条件属性进行约简。为了克服某些没必要的或者是不太重要的属性的影响,故而,设定了一个依赖度增量阈值θ=0.01来进行筛选,计算各个条件属性对应的依赖度增量,只有当其大于θ时,才可以将该条件属性列入约简属性列表之中。如下表1则是显示了约简之后,各个条件属性对决策属性的重要性的统计表。
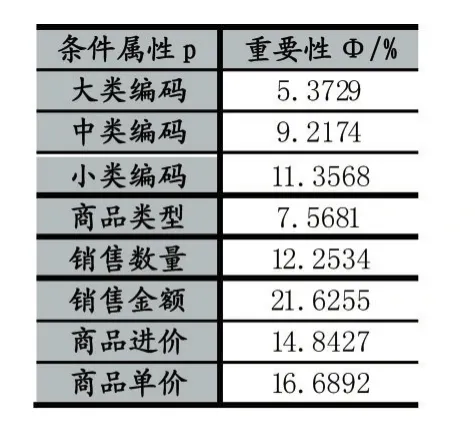
表1 约简后各个条件属性的重要性
在实验样例中,由于销售利润对销售时间的依赖度过小,在θ之下,故而对销售日期、销售月份进行了属性的约简。由表1可以看出,销售金额对销售利润的影响最高,其次分别为商品的单价和商品的进价以及商品销售数量。根据上表得出的数据,然后赋予加权欧氏距离不同的权值系数。接着对选取的数据进行聚类分析,并最终选取300组历史数据为训练样本训练k类神经网络预测模型。在该案例中,当k取值为6时,效果相对明显。并在此次的案例中,熟牛肉的销售利润最高,其次为干货虾蟹贝和猪肉。
6 结语
本文针对网上商店利润的问题,站在网商的角度,提出了基于粗糙集和改进聚类的方法,来对获利更高的商品进行推荐排版。以网商为出发点,来使得商家获得的收益最大化,同时通过采用粗糙集的理论,对商品属性进行约简,反映出不同的属性对商品利润的重要性,并且通过引用神经网络来建立预测模型,更加系统地分析数据。但是由于数据来源的问题,并不一定能完全地表现网商的收益情况,仍然需要继续去优化,此外,关于如何选择更加合适的样本,如何去选择更加优化的模型也是本课题需要进一步研究的内容。
[1]孙涛.个性化商品推荐系统的设计与实现[D].吉林:吉林大学硕士学位论文,2015.
[2]罗俊.粗糙集理论约简算法及其应用研究[D].武汉:武汉理工大学工学硕士学位论文,2009.
[3]吴雅轩.基于大数据的网络商品推荐信息对消费者购买行为影响的实证研究[D].辽宁:辽宁大学硕士学位论文,2015.
[4]胡新明.基于商品属性的电子商务推荐系统研究[D].武汉:华中科技大学博士学位论文,2012.
[5]时瑞.基于数据挖掘的商品推荐系统研究和实现[D].上海:上海交通大学工程硕士专业学位论文,2013.
[6]刘兴杰,芩添云.基于模糊粗糙集与改进聚类的神经网络风速预测[J].北京:中国电机工程学报,2014.
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
聊城大学学报(自然科学版)(2022年5期)2022-10-29
闽南师范大学学报(自然科学版)(2022年1期)2022-03-28
大连民族大学学报(2021年3期)2021-10-15
计算机应用(2021年4期)2021-04-20
小型微型计算机系统(2019年10期)2019-11-11
小型微型计算机系统(2019年9期)2019-09-09
计算机与数字工程(2019年8期)2019-09-03
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
