
基于论文关键词和篇章结构的自动文摘抽取方法
2018-06-13 07:52孙晓腾李学明
现代计算机 2018年13期
孙晓腾,李学明
(重庆大学计算机学院,重庆 400044)
0 引言
自动文摘技术是指利用计算机算法和程序对输入文档进行分析和提取,从而产出文章摘要的过程。该文章摘要一般通顺连贯并且可以高度概括文章主旨,当前自动文摘主要应用于新闻和论文领域[1]。
本文主要面向论文领域,通过论文关键词过滤掉相关性差的句子,精炼候选句子集,并通过对论文主题和结构的分析,制定了一些影响句子重要度的规则和方法,进而影响传统TextRank算法的权重,改进文本排序结果。改进后的重要度排名更能反映出与主题的关联性,提升了自动文摘的水准。
1 自动文摘研究概述
1.1 自动文摘生成方法
在当前NLP研究领域,自动文摘根据生成原理主要分为两大类[2],一种是抽取式的(extractive),即选取原文中的一些关键句,组合形成一篇摘要;另外一种是摘要式的(abstractive),即让计算机理解原文的内容和思想,并通过合理的语法生成新的概括句,生成文章摘要。现阶段相对成熟的是基于抽取的方法,这也是目前最主流、应用最广泛的方法。
除此之外自动文摘还有一种根据输入文档数量而定的分类方式,即单文档摘要和多文档摘要[3]。本文提出的方法是基于抽取式的单文档摘要的改进算法。
1.2 自动文摘评估方法
如何高效且合理地评价一篇文摘的质量也是该领域的研究重点。自动文摘的评估方法包括人工评价和自动评价两种[4]。由于人工评价耗时长,且因为人的主观性使得评价结果因人而异,所以人工评价不完全适用于自动文摘;自动评价方法因为其高效性、客观性,成为了众多学者研究的重点。
本文使用两种方式评估文摘的质量:一种是通过计算自动文摘与原文摘要的相似度,计算主旨契合度来评估文摘的质量;另一种是通过人工提取的方式生成标准文摘,计算自动文摘的准确率、召回率以及FMeasure[5]值。
2 句子的空间向量模型与关键词抽取
2.1 文本预处理和特征向量表示
将给定文本拆分为句子集合,对句子进行分词得到特征项。由于一般句子中包含许多无意义的停用词,直接分词不但会降低分词质量,还会导致维度过高从而降低算法效率。所以在分词时需要进行文本预处理,去除停用词和部分低频词[6],提升句子精度,降低特征的维度。
经过预处理及分词之后的句子通过词频表示为各自的特征词向量[7],然后利用相似度函数计算两个句子的相似度,同时作为TextRank图算法中两句子间边的权重。
对给定的句子集合P,若P包含n个句子,P={S1,…,Sn},其中Si(1≤i≤n)为原文本中按先后顺序出现的句子。对于P及各个Si有如下表示:
(1)将P的特征词记为swi(1≤i≤h),其中h=|Psw|为P中所有特征词的数量。
(2)对每一个句子Si,特征向量表示为Sih=[s w1:fi1,…,swj:fij,…,swh:fih](1≤j≤h),其中 fij为特征词swj在句子Si中出现的频数。如果特征词swj未在句子Si中出现,则 fij=0。
(3)所有的Sih构成一个用于图计算的矩阵:其中,每一行表示文本中相应的句子Si的特征向量Sih,每一列表示相应的特征词swi在各个句子中的频数。该矩阵也是用于后续TextRank图计算的高维稀疏矩阵。
2.2 关键词的抽取
关键词是能概括或表达论文的关键信息和主题的词汇,因此除了特征词的提取之外,关键词的抽取和处理也是十分重要的[8]。在本文的改进算法中,抽取出的关键词用于辨别句子与文章主题的契合度,从而达到优化候选句子集的目的。本文的关键词抽取采用TextRank算法[9],利用局部词间的共现关系进行图排序,选取权重排名靠前的若干词汇作为关键词。具体步骤如下:
(1)将文本P按照完整句子进行分割,得到句子集合 P={S1,…,Sn}。
(2)对于集合中的每个句子Si进行预处理,过滤掉停用词和低频词,然后进行分词和词性标注处理,只保留指定词性的单词(本文实验中只保留了名词、动词、形容词),进而得到句子Si的候选关键词集 Si={wi1,…,win}。
(3)构造候选关键词的图Gw=(V ,E ),其中V为节点集,由(2)生成的候选关键词组成。节点之间的边采用共现关系(co-occurrence)来构造,如果两个节点对应的词汇在长度为K的窗口中共现,则存在一条无向无权的边,若没有共现则不存在。其中K为设定的窗口大小,若句子 Si={wi1,…,win},则 {wi1,…,wik}、{wi2,…,wik+1}…都是一个窗口,即最多共现 K个关键词。
(4)基于(3)中的图,利用TextRank算法迭代计算出每个单词节点的权重作为该关键词的重要度。对所有节点重要度进行倒序排序,选取前t个词汇作为关键词。其中,t为选取关键词数量的阈值。
3 基于论文关键词和结构的改进TextRank算法
传统的TextRank算法仅考虑了两两句子间的相似度,虽然易于实现,但文摘的质量也会受影响。本文在传统的TextRank算法基础上,基于论文关键词和论文结构进行了两方面改进:一是利用关键词进行无关句的过滤,对候选句子集进行精简;二是分析论文结构,对不同位置的句子进行不同程度的权重增强,提升与主旨更贴切的句子的重要度,提高文摘的整体质量。
3.1 算法核心思想
(1)经典TextRank算法
TextRank算法是一种图排序算法,该算法将文本划分为若干单元,以此为结点构造图模型,利用投票机制对文本中的重要成分进行排序[10]。
设G=(V,E)是由文本单元组成的图结构,V为定点集合,E为边集合。WS(Vi)为顶点Vi的得分,迭代公式为:
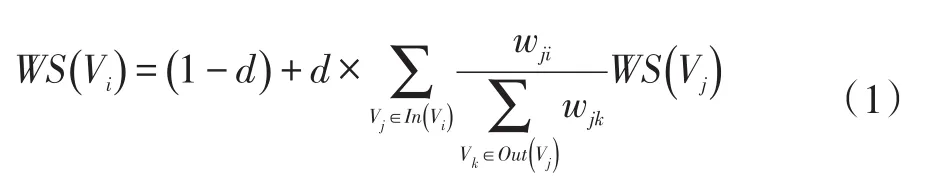
其中d为阻尼系数,一般取0.85;In(Vi)为指向节点Vi的所有节点集合;Out(Vj)为节点Vj指向的所有节点集合;wji为节点Vj到节点Vi的边的权重。
(2)候选句子集的精炼
通过句子分割和文本预处理得到的初始候选句子集包含了全文所有的句子,但有些句子与文章主题思想距离较远,关联度差,不适合被选为摘要的组成句,并且会提升计算的复杂度。而2.2中提取的关键词集却能很好地表达文章主旨,因此借助关键词集对候选句子集进行剪枝和精炼,提升候选句子集的精度和质量。具体过滤规则为:
设经过分词和预处理句子Si的分词集Wi={wi1,…,win},其中n表示句子 Si的分词数量,wij(1≤j≤n)表示Si中第 j个分词。设文本P的关键词集为Kwordsp={k ey1,…,keyt},其中t表示提取的关键词数量。则句子分词集Wi和文本关键词集Kwordsp的交集称为句子Si的相关词集RWi,即RWi=Wi∩Kwordsp;句子Si的相关度为:

当Ri<δkey时,认为句子Si与文章主题关联度很小,此时将Si从候选句子集中删除。
(3)候选句子权重的增强
对于一篇论文来说,文章结构代表了严谨的逻辑架构,往往是十分清晰的。所以本文基于论文结构从以下两个方面考虑其对句子重要度的影响:
①句子的内容是否契合该章节标题和文章总标题
标题是作者对于文章或章节内容的概括和总结,出现在各个标题中的词更是全文核心词汇。某个句子与标题的相似度越高,该句就越契合文章主题[11]。基于这一点,本文通过计算句子和所在章节标题以及总标题的相似度,对句子的重要度进行不同程度的放大。由 2.1可知,对每一个句子 Si,特征向量表示为Sih=[sw1:fi1,…,swj:fij,…,swh:fih],记总标题的特征词向量为S0h=[sw1:f01,…,swj:f0j,…,swh:f0h](1≤j≤h),Si所处章节标题的特征词向量为Si0h=[sw1:fi01,…,swj:fi0j,…,swh:fi0h](1≤j≤h)。重要度放大因子为:
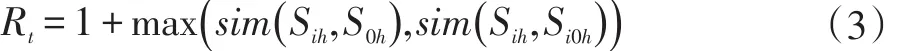
其中max函数为取最大值函数,sim函数为相似度函数,一般采用向量夹角的余弦值计算得出。另外,由于论文中许多章节标题过于通用和宽泛(如“引言”、“实验结果”、“结束语”等),无法体现与主题的相关性,故在计算过程中,相似度应取章节标题和文章总标题两者中较大的值。
②句子是否处在该章节和全文的关键位置
美国RE.Baxendale的研究结果[12]表明,人工摘要中,选取段首句和段尾句的概率十分高;另外康奈尔大学的G.Salton也指出[13],文章中的首尾段以及承上启下的段落也常被提取作为摘要使用。基于这一点,本文根据句子在所处章节中的位置,对重要度进行不同程度的放大。在预处理阶段,记录每个句子序号并标记对应的段落,最终通过判定该句是否为特殊位置句来决定是否叠加影响因子。对每个句子针对句子Si的基于位置的重要度放大因子为:

其中特殊位置包括五种:段首句、段尾句、章节首段句、章节末段句、独立成段句,flagi(1≤i≤5)为这五种特殊位置的判定标记,若判定成功,flagi=1,否则flagi=0;δi(1≤i≤5)为这五种特殊位置的影响因子。
3.2 算法实现和流程概述
算法整体的流程如图1所示:

图1 算法整体的流程图
结合图1,整体的计算过程如下:
(1)对输入文本T进行预处理,去除停用词和低频词,并对句子和所在段落进行标记,记录每一个章节的标题。
(2)进行分词,构造文本T的特征向量矩阵Dn×h。
(3)利用2.2的方法和步骤提取文章关键词。
(4)由式(2)计算句子相关度,去除相关性小的句子,得到精炼后的候选句子集。
(5)计算候选句子集中句子间的相似度,构造TextRank网络图G。
(6)由式(1)进行图G的迭代计算,不断更新权值,直到收敛。
(7)由式(3)、式(4),计算放大因子,对得到的重要度排名进行更新。
(8)取排名前t个句子,得到自动文摘的句子集Aa。
(9)按照原文出现的顺序输出Aa中的句子,得到最终的摘要。
3.3 实验结果及分析
为了对比基于关键词和结构改进的TextRank算法与传统TextRank算法的性能,本节设计了两个实验:实验一以原论文作者编写的摘要部分作为标准文摘,计算自动文摘与标准文摘的相似度,以此对比分析算法性能。实验二是从实验一的论文素材中选取一部分进行人工文摘的抽取,通过计算平均准确率、平均召回率和F-measure值对比分析算法性能。
(1)实验一:
由于研究面向论文领域,而论文的摘要则是作者人工编写所得,具有高度概括文章中心主旨的特点,十分利于评估自动文摘的质量。但由于摘要并未人工抽取而是重新编写,所以无法计算准确率和召回率,本实验通过计算两者的相似度来作对比。
首先通过网络下载包含生物、经济、文学、科技等多领域的论文50篇,按正文顺序筛选和标记各个标题、段落和句子。正文长度分布如图2所示。
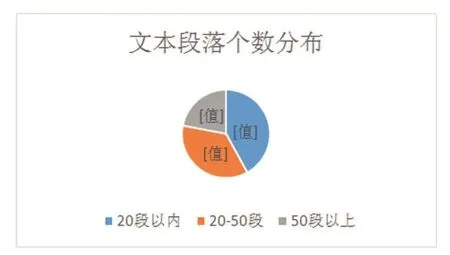
图2 文本段落个数分布图
设定生成文摘的句子数为原文摘的句子数t,原文摘Am={Sm1,Sm2,…,Smt},自动文摘 Aa={Sa1,Sa2,…,Sat} 。则自动文摘和原文摘的相似度为:算法和实验中的主要参数值设置如表1所示。


表1 实验参数表
相似度实验结果如表2所示:
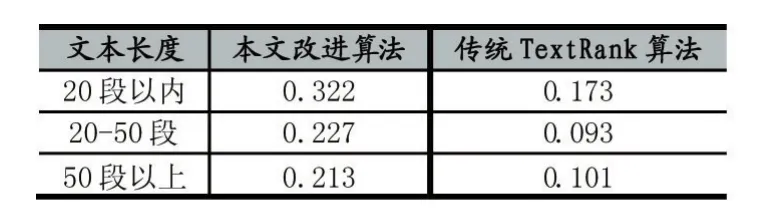
表2 实验一相似度结果对比
分析表2结果可知,本文改进的TextRank算法相对于传统TextRank算法更加有效,生成文摘的质量更高,能更好地概括文章主题思想。除此之外,两种算法的精确度随着文本长度的增加,会有不同程度的下降,但传统TextRank算法下降更加明显。通过对一些实验数据的人工观察发现,当文本长度增加时,候选句子数增多,通过关键字过滤掉相关性差的句子这一剪枝措施有较为明显的效果。
(2)实验二:
目前,将人工摘要作为标准摘要去计算准确率和召回率是自动文摘领域较为普遍的评价方法。由于本实验素材和语料中不含人工摘要,需要人工提取,而这个过程通常比较耗时。所以在实验二中,采用实验一的50篇论文素材,从中选取一小部分(15篇)来生成人工摘要,通过计算准确率(P)、召回率(R)和F-measure值对比分析文摘性能。设人工文摘句子集为Am={Sm1,Sm2,…,Smt},自 动 文 摘 句 子 集Aa={Sa1,Sa2,…,Sat}。具体计算公式如下:


表3 实验二结果对比
分析表3结果可知,本文改进后的算法相比传统的TextRank算法具有更高的准确率、召回率和F-Measure值,说明使用关键词精简候选句子集,并考虑标题契合度和句子位置进行权重提升之后,所生成的自动文摘更接近人工文摘的结果。这也是因为,本文所提出的规则和影响因素,正是从人为提取的角度去思考得出的经验性规则,而本实验也证明了这些规则是合理且有效的。
4 结语
在自动文摘研究领域,如何使句子抽取更加符合人工筛选的思维是研究的热点和重点。本文在传统TextRank算法的基础上,加入了候选句子集精炼和特殊句权重增强两个过程,利用关键词和文章标题结构等信息对算法进行了优化,使之更加符合人工生成摘要时的思路。实验结果也表明,算法改进后生成的文摘质量有了一定程度的提高。
本文也存在一些不足之处:本文以论文为研究对象,研究语料和素材有一定特殊性,由于论文往往具有结构的严谨性,所以得到了不错的实验效果。该方法能否在新闻、评论、文学作品等其他领域具有不错的普适性,还有待研究和确认,而这些也是下一步的工作和研究重点。
[1]郭燕慧,钟义信,马志勇,等.自动文摘综述[J].情报学报,2002,21(5):582-591.
[2]卫佳君,宋继华.自动文摘的方法研究[J].计算机技术与发展,2011,21(8):188-191.
[3]胡侠,林晔,王灿,等.自动文本摘要技术综述[J].情报杂志,2010,29(8):144-147.
[4]Jones K S.Automatic Summarising:Factors and Directions[C].Cambridge MA:MIT press:1998.
[5]张瑾,王小磊,许洪波.自动文摘评价方法综述[J].中文信息学报,2008,22(3):81-88.
[6]刘红芝.中文分词技术的研究[J].电脑开发与应用,2010,23(3):1-3.
[7]刘海燕,张钰,LIU Hai-yan,等.基于LexRank的中文单文档摘要方法[J].兵器装备工程学报,2017(6):85-89.
[8]蒋效宇.基于关键词抽取的自动文摘算法[J].计算机工程,2012,38(3):183-186.
[9]张莉婧,李业丽,曾庆涛,等.基于改进TextRank的关键词抽取算法[J].北京印刷学院学报,2016,24(4):51-55.
[10]Mihalcea R,Tarau P.TextRank:Bringing Order into Texts[J].Emnlp,2004:404-411.
[11]余珊珊,苏锦钿,李鹏飞.基于改进的TextRank的自动摘要提取方法[J].计算机科学,2016,43(6):240-247.
[12]Baxendale P B.Machine-Made Index for Technical Literature:an Experiment[M].IBM Corp.1958.
[13]Salton G,Wong A,Yang C S.A Vector Space Model for Automatic Indexing[J].Communications of the ACM,1974,18(11):613-620.
